
Vous pouvez lire le billet sur le blog La Minute pour plus d'informations sur les RSS !
Canaux
2834 éléments (163 non lus) dans 55 canaux
 Dans la presse
(87 non lus)
Dans la presse
(87 non lus)
-
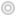 Décryptagéo, l'information géographique
Décryptagéo, l'information géographique
-
Cybergeo
(40 non lus)
-
Revue Internationale de Géomatique (RIG)
-
SIGMAG & SIGTV.FR - Un autre regard sur la géomatique
(7 non lus)
-
Mappemonde
(40 non lus)
Du côté des éditeurs
(13 non lus)
-
Imagerie Géospatiale
-
Toute l’actualité des Geoservices de l'IGN
(8 non lus)
-
arcOrama, un blog sur les SIG, ceux d ESRI en particulier (5 non lus)
-
arcOpole - Actualités du Programme
-
Géoclip, le générateur d'observatoires cartographiques
-
Blog GEOCONCEPT FR
Toile géomatique francophone
(53 non lus)
-
Géoblogs (GeoRezo.net)
-
Conseil national de l'information géolocalisée
(4 non lus)
-
 Geotribu
Geotribu
-
Les cafés géographiques
(7 non lus)
-
UrbaLine (le blog d'Aline sur l'urba, la géomatique, et l'habitat)
-
Icem7
(1 non lus)
-
Séries temporelles (CESBIO)
(3 non lus)
-
Datafoncier, données pour les territoires (Cerema)
-
Cartes et figures du monde
(2 non lus)
-
SIGEA: actualités des SIG pour l'enseignement agricole
-
Data and GIS tips
-
Neogeo Technologies
(4 non lus)
-
ReLucBlog
-
L'Atelier de Cartographie
-
My Geomatic
-
archeomatic (le blog d'un archéologue à l’INRAP)
-
Cartographies numériques
(17 non lus)
-
Veille cartographie
-
Makina Corpus (7 non lus)
-
Oslandia
(8 non lus)
-
Camptocamp
-
Carnet (neo)cartographique
-
Le blog de Geomatys
-
GEOMATIQUE
-
Geomatick
-
CartONG (actualités)

Toile géomatique francophone
-
sur Utilisation de la géomatique pour la gestion optimisée des chantiers de construction urbaine
Publié: 21 June 2023, 8:10am CEST par Gueye
Cet article Utilisation de la géomatique pour la gestion optimisée des chantiers de construction urbaine est apparu en premier sur Veille cartographique 2.0.
La gestion des chantiers de construction urbaine constitue un défi majeur dans les environnements urbains d’aujourd’hui. Pour répondre à ce défi, l’utilisation de la géomatique offre des possibilités prometteuses. En combinant les technologies géospatiales avancées avec les pratiques de construction traditionnelles, il est possible d’optimiser la planification, la mise en œuvre et la gestion des […]
Cet article Utilisation de la géomatique pour la gestion optimisée des chantiers de construction urbaine est apparu en premier sur Veille cartographique 2.0.
-
sur Reappearance of the Dnieper river after the destruction of Kakhovka dam
Publié: 19 June 2023, 5:14pm CEST par Simon Gascoin
The Kakhovka Reservoir was created in 1956. As the level of the reservoir drops at a staggering rate of two meters per day, it is now possible to see the ancient river reappear in satellite images.
I have georeferenced a 1943 German military map published by Defense Express in their article « 1943 Maps Show What Ukraine’s Kakhovka Reservoir Will Look Like When the Waters Settle Down » to verify if the Dnieper returns to its original state before the dam was constructed.
 German General Staff map issued in 1943 and Sentinel-2 image acquired on 18 June 2023
German General Staff map issued in 1943 and Sentinel-2 image acquired on 18 June 2023
 18 June 2023 vs 1943
18 June 2023 vs 1943
The former river is also visible near the Zaporizhzhia Nuclear Power Plant. According to the French Institute for Radiation Protection and Nuclear Safety the dikes of the cooling pond can withstand a Dnieper level of 10 m in the vicinity of the power plant. The level reached 11.8 m on June 9. It should be already well below 10 m by now but the cooling pond remains full.
Almost two weeks after the destruction of the dam this is how Lake Kakhovka looks… (June 18) pic.twitter.com/KQRvshMZEf
— Simon Gascoin (@sgascoin) June 19, 2023
The lake water level can be monitored by satellite altimetry in Theia’s HydroWeb website. However, the data are no longer updated due to the lack of water to reflect the signal emitted by the altimeter.

Update on June 21, with a new Sentinel-2 image acquired on June 20:
The magnitude of the hydrological disruption caused by the destruction of the #KakhovkaDam is mind-blowing. 2000 square kilometers (800 sq miles) restored to pre-1956 condition in two weeks. @CopernicusLand pic.twitter.com/wUWvwDAloH
— Simon Gascoin (@sgascoin) June 21, 2023
Top picture by Katerina Polyanska – Own work, CC BY-SA 3.0, [https:]


-
sur uMap, un logiciel open source qui permet de créer des cartes en ligne
Publié: 17 June 2023, 8:55pm CEST par Marinac
Cet article uMap, un logiciel open source qui permet de créer des cartes en ligne est apparu en premier sur Veille cartographique 2.0.
uMap a été développé sous le modèle de OpenStreetMap. Ce logiciel permet de créer des cartes en ligne à l’échelle du monde entier. En outre vous pouvez vous géolocaliser sur la carte, faire des mesures de distances à l’aide de différents points, ajouter des points (marqueurs), des lignes, des polygones en précisant le calque dans […]
Cet article uMap, un logiciel open source qui permet de créer des cartes en ligne est apparu en premier sur Veille cartographique 2.0.
-
sur Rivalités sino-américaines autour de la cartographie géologique de l’astre lunaire (partie 2/2)
Publié: 17 June 2023, 5:39pm CEST par Nicolas Le Maux
Cet article Rivalités sino-américaines autour de la cartographie géologique de l’astre lunaire (partie 2/2) est apparu en premier sur Veille cartographique 2.0.
Par NicoLX (Nicolas Le Maux) De la nouvelle carte géologique nippo-américaine de la Lune en 2020 à celle de la Chine en 2022 Après une longue rivalité avec l’URSS, les États-Unis ont longtemps été seuls à la pointe de la Sélénologie : l’étude du satellite lunaire, et plus parfois, plus particulièrement, l’étude géologique de […]
Cet article Rivalités sino-américaines autour de la cartographie géologique de l’astre lunaire (partie 2/2) est apparu en premier sur Veille cartographique 2.0.
-
sur Rivalités sino-américaines autours de la cartographie géologique de l’astre lunaire (partie ½)
Publié: 17 June 2023, 4:43pm CEST par Nicolas Le Maux
Cet article Rivalités sino-américaines autour de la cartographie géologique de l’astre lunaire (partie ½) est apparu en premier sur Veille cartographique 2.0.
Par NicolasLX (Nicolas Le Maux) Cartographie géologique lunaire américaine : des années 60 à 2020 Les premières cartes américaines géologiques de la lune datent toutes des missions Apollo de 1961 à 1972. Une numérisation des versions s’opère depuis 2013. Elles réunissent en 6 volets nommés cartes régionales, la totalité de la surface lunaire (Lunar 1:5M […]
Cet article Rivalités sino-américaines autour de la cartographie géologique de l’astre lunaire (partie ½) est apparu en premier sur Veille cartographique 2.0.
-
sur Prix du Livre de Géographie des Lycéens et Etudiants 2023
Publié: 17 June 2023, 1:04pm CEST par r.a.
Le prix du Livre de Géographie des Lycéens et Etudiants est une création récente (2020), destinée à faire découvrir et aimer la géographie à travers une sélection annuelle de cinq ouvrages reflétant la diversité de la discipline. Les deux premières éditions avaient récompensé en 2021 Sylvie Lasserre pour Voyage au pays des Ouïghours (Editions Hesse, 2020) et en 2022 Camille Schmoll pour Les damnées de la mer (La Découverte, 2020).
Cette année, le prix a été accordé à Monde enchanté, Chansons et imaginaires géographiques de Raphaël Pieroni et Jean-François Staszak (1). On comprend l’enthousiasme des jeunes gens qui l’ont choisi pour un ouvrage ludique et joyeux dont l’objet d’analyse est constitué de 36 chansons (2) écrites majoritairement en français et en anglais, des années 1930 à nos jours.
Jean-François Staszak a présenté, à la Société de géographie, son travail et celui de son collègue, comme une réalisation de géographie culturelle qui étudie le monde tel qu’on l’appréhende à travers les différents systèmes de représentation. Face aux critiques qui reprochent à cette discipline son caractère trop souvent élitiste et conceptuel, il se réjouit de présenter un travail portant sur des chansons, c’est-à dire des témoignages de la culture populaire empreints d’émotion.
Il a été demandé aux collègues genevois des auteurs de choisir une chanson connue comme enjeu géographique et de produire un texte court à destination du grand public. Ce choix peut être suggéré par le texte même de la chanson ou par les lieux où elle a été entendue. Certaines chansons ont participé à la construction de lieux. Il est ainsi plaisant de savoir qu’un Café Pouchkine a été inauguré en 1999 par Gilbert Bécaud sur la Place Rouge à Moscou, alors que sa chanson Nathalie date de 1964 ! (3)
Michèle Vignaux, juin 2023
1) Georg Editeur, 2021. Cet ouvrage a été suivi de Villes enchantées, en 2022. Il sera à son tour complété par Voyages enchantés en cours de réalisation. 2) Les trois ouvrages évoqueront 121 chansons dont 81 en français. 3) Le 22 septembre 2022, dans Géographie à la carte, France Culture a présenté le sujet des rapports entre la géographie et la chanson, en invitant notamment Jean-François Staszak. Parmi les principales questions abordées lors de l’émission, on retrouve bien sûr celles du livre qui vient d’être récompensé : comment les chansons racontent-elles les villes ? La culture populaire peut-elle matériellement transformer un territoire ? La puissance évocatrice de certaines villes dans les chansons a-t-elle un aspect géopolitique ? [https:]] -
sur Géopolitique de la Corée du Sud
Publié: 17 June 2023, 12:59pm CEST par r.a.
-
sur Cartographie des capteurs de vélo automatiques de la métropole de Bordeaux
Publié: 16 June 2023, 2:11pm CEST par Anouar Fakir
Cet article Cartographie des capteurs de vélo automatiques de la métropole de Bordeaux est apparu en premier sur Veille cartographique 2.0.
La métropole de Bordeaux s’engage pour la mobilité et les pratiques de mobilités douces notamment le vélo. Elle a récemment obtenu le statut de “Territoire vélo” qui reconnaît les actions favorisant toutes les pratiques cyclables à la fois en termes de loisirs, tourisme ou mobilités quotidienne. Pour obtenir ce statut, la métropole a su proposer […]
Cet article Cartographie des capteurs de vélo automatiques de la métropole de Bordeaux est apparu en premier sur Veille cartographique 2.0.
-
sur NEYOS, une passion pour la randonnée en montagne
Publié: 15 June 2023, 5:43pm CEST par DIALLO
Cet article NEYOS, une passion pour la randonnée en montagne est apparu en premier sur Veille cartographique 2.0.
Si vous êtes passionnés par la randonnée, ne serait-ce qu’un peu comme moi ou que vous soyez un véritable adepte de ce sport, et si par dessus le marché vous êtes un amoureux des cartes et des systèmes de positionnement, alors vous êtes bien tombés sur le bon article car celui-ci va vous parler des […]
Cet article NEYOS, une passion pour la randonnée en montagne est apparu en premier sur Veille cartographique 2.0.
-
sur La cartographie dans le domaine militaire
Publié: 15 June 2023, 4:50pm CEST par Sogner
Cet article La cartographie dans le domaine militaire est apparu en premier sur Veille cartographique 2.0.
Introduction La cartographie, en tant qu’outil de représentation géographique, joue un rôle essentiel dans le domaine militaire. En effet, depuis des siècles, les armées du monde entier ont utilisé des cartes pour comprendre le terrain, prendre des décisions stratégiques. Cet article explore l’utilisation de la cartographie dans le domaine militaire, mettant en évidence son importance […]
Cet article La cartographie dans le domaine militaire est apparu en premier sur Veille cartographique 2.0.
-
sur Présentation du logiciel Philcarto
Publié: 15 June 2023, 4:34pm CEST par Sogner
Cet article Présentation du logiciel Philcarto est apparu en premier sur Veille cartographique 2.0.
De nombreux logiciels sont disponible pour aider les géomaticiens ou les cartographes à cartographier ou représenter leurs données. Philcarto est l’un d’entre eux. Il a été crée par Philippe Waniez, géographe à l’université de Bordeaux et est un logiciel totalement gratuit. En parallèle du logiciel Philcarto, il est à l’origine de Phildigit et Eclat, des […]
Cet article Présentation du logiciel Philcarto est apparu en premier sur Veille cartographique 2.0.
-
sur CartONG continue d’amplifier son offre de soutien pro bono !
Publié: 15 June 2023, 2:30pm CEST par Yelena Yvoz
Pour la deuxième année consécutive et grâce au Fonjep, CartONG propose un soutien ponctuel pro bono en cartographie et/ou gestion des données aux petites et moyennes structures de solidarité locale et internationale.
-
sur GeoRhena : un SIG qui fait dialoguer trois pays
Publié: 15 June 2023, 9:57am CEST par Clément Dollet
Cet article GeoRhena : un SIG qui fait dialoguer trois pays est apparu en premier sur Veille cartographique 2.0.
GeoRhena est un SIG accueillant des données géographiques transfrontalières, en opendata, capitalisée à l’échelle du Rhin supérieur croisant le territoire français, suisse et allemand. Logo GeoRhena : [https:] Ce projet est porté par la Collectivité européenne d’Alsace et co-financées par plusieurs collectivités de chacun des 3 pays (3 en France, 5 en Allemagne et […]
Cet article GeoRhena : un SIG qui fait dialoguer trois pays est apparu en premier sur Veille cartographique 2.0.
-
sur L’évènement annuel de la géonumérique : le GeoDataDays 2023 fixé à Reims
Publié: 15 June 2023, 9:56am CEST par Clément Dollet
Cet article L’évènement annuel de la géonumérique : le GeoDataDays 2023 fixé à Reims est apparu en premier sur Veille cartographique 2.0.
La représentation spatiale au service des enjeux environnementaux est un réel défi de ces dernières années. Cartographie, modélisation, différentes méthodes pouvant être utilisée pour représenter les conséquences du changement climatique et y développer des outils d’aide pour les études environnementales : gestion durable des ressources naturelles, identification des corridors écologiques à protéger, zones de température à […]
Cet article L’évènement annuel de la géonumérique : le GeoDataDays 2023 fixé à Reims est apparu en premier sur Veille cartographique 2.0.
-
sur Quelles adaptations pour l’augmentation de la demande de logements et pour le réchauffement climatique pour Paris d’ici 2030 ?
Publié: 15 June 2023, 9:27am CEST par BITTANTE
Cet article Quelles adaptations pour l’augmentation de la demande de logements et pour le réchauffement climatique pour Paris d’ici 2030 ? est apparu en premier sur Veille cartographique 2.0.
Quelles adaptations pour l’augmentation de la demande de logements et pour le réchauffement climatique pour Paris d’ici 2030 ? Le lundi 5 juin 2023, le Conseil de Paris doit voter le nouveau Plan Local d’Urbanisme de la Capitale. Ce nouveau plan s’inscrit dans le contexte de neutralité carbone d’ici 2050 et d’adaptation aux impacts du changement […]
Cet article Quelles adaptations pour l’augmentation de la demande de logements et pour le réchauffement climatique pour Paris d’ici 2030 ? est apparu en premier sur Veille cartographique 2.0.
-
sur Évolution d'Act'if, la plateforme de l'économie circulaire
Publié: 14 June 2023, 4:25pm CEST par Amandine Boivin
La CCI Occitanie a fait appel à Makina Corpus pour apporter une évolution substantielle à la solution Act'if.
-
sur La différence entre les SIG et la géomatique
Publié: 14 June 2023, 12:32pm CEST par Sow
Cet article La différence entre les SIG et la géomatique est apparu en premier sur Veille cartographique 2.0.
Bien qu’ils partagent certains concepts et outils, ils ont des domaines d’application distincts et des approches différentes. La géomatique est un terme plus large qui englobe l’ensemble des disciplines et des technologies liées à l’acquisition, à la gestion, à l’analyse et à la représentation de données géographiques. Elle intègre différents domaines tels que la géodésie, […]
Cet article La différence entre les SIG et la géomatique est apparu en premier sur Veille cartographique 2.0.
-
sur Webinaires "Carte blanche" sur les formes contemporaines de cartographies et de géovisualisations de données (GDR Magis)
Publié: 13 June 2023, 9:26am CEST
Dans le cadre de ses activités, l'AR9 propose une série de Webinaires mensuels sous la forme d'une "Carte blanche", un temps consacré à l'exploration et aux discussions sur les formes contemporaines de cartographies et de géovisualisations de données. L'objectif de ces temps d'échange est à la fois de permettre des présentations de travaux, de réalisations ou d'expérimentations cartographiques diversifiées et des échanges collectifs sur les leviers et les enjeux actuels de la représentation de données spatiales tant d'un point de vue conceptuel, opérationnel, méthodologique que technique. Format
Format
Durée : Á partir de 12h30, pour 30mn de présentation en mode visioconférence + 30 mn d'échanges et de discussions. Le webinaire est animé et modéré par l'un.e des porteurs de l'AR 9 (Anne-Christine Bronner, Boris Mericskay, Etienne Côme, Françoise Bahoken, Nicolas Lambert).
Webinaires à venir- 6 juillet 2023 : Najla TOUATI et Laurent JÉGOU : De la carte climatique au chorotype climatique : propositions de modèles graphiques (animation Anne-Christine Bronner)
- 7 septembre 2023 : Jean-Philippe GAUTIER présentera www.cartostat.eu, une application web de cartographie statistique (animation Anne-Christine Bronner)
- 5 Octobre 2023 : Julien GAFFURI, Eurostats, @julgaf, gridviz (Animation Etienne Côme)
- 7 Novembre 2023 : [Maher BEN REBAH], UMR 7533 LADYSS, La plateforme ELYSSA de géovisualisation sur les élections (Animation Françoise Bahoken)
Webinaires passés- 11 mai 2023 : RAJERISON Mathieu, Cerema, @datagistips
Génération (de) cartes (animation Etienne Côme). ? Vidéo du Webinaire ? Ressources Slides
- lundi 17 avril 2023 : DOUET Aurélie, IE UMR Géographie-cités,
CartoDouetna.rm=TRUE. Requête, interactivité et gestion des données manquantes
? Vidéo du Webinaire ? Ressources
- Jeudi 2 février 2023 AUMOND Pierre (CR, Univ. Gustave Eiffel-CEREMA/UMRAE), @SoundCartograp1
Cartographie du paysage sonore urbain ? Vidéo du Webinaire
- Mercredi 7 décembre 2022 Philippe RIVIERE (Visions carto, Observable)
Faire des cartes statistiques avec Observable Plot ? Vidéo du Webinaire
- Mardi 8 novembre 2022 Colin KEROUANTON (IR, PACTE)
Effets spéciaux pour questions spatiales ? Vidéo du Webinaire
Intervenir dans le webinaire
Si vous êtes intéressé.e.s à venir présenter vos travaux ou expérimentations cartographiques vous êtes les bienvenus ! Que vous soyez dans le monde académique, dans le secteur privé ou passionné de cartographie et de géovisualisation contactez le collectif de l'AR9 : @ collectif de l'AR.
Informations nécessaires sur votre intervention :- un titre ;
- une image ;
- un résumé de 3-4 lignes ;
- vos noms, prénoms @ et affiliations.
Projet de l'action de recherche AR9 du GDR Magis
L'objectif général de cette action de recherche du GDR MAGIS est de fédérer des réflexions et des travaux scientifiques d’origines disciplinaires variées menés autour de la (carto)graphie contemporaine au sens large et de la (géo)visualisation de données. Pour ce faire, elle propose d’une part, de mener une veille théorique, méthodologique et technique sur les modalités de la fabrique des cartes et, d’autre part, de fédérer et d’animer une communauté de chercheurs (essentiellement géographes, géomaticiens, cartographes, informaticiens...) lors d’ateliers et de séminaires thématiques et méthodologiques. Lire le projet.
Articles connexes
Conférence Spatial Analysis and GEOmatics (SAGEO) 2023Des sources aux SIG : des outils pour la cartographie dans les Humanités numériques
Des outils pour la cartographie dans les humanités numériques (Plateforme géomatique de l'EHESS)
Humanités numériques spatialisées (revue Humanités numériques, n°3, 2021)
Utiliser l'application Observable pour créer ses propres visualisations de donnéesComment différencier infographie et data visualisation
- 6 juillet 2023 : Najla TOUATI et Laurent JÉGOU : De la carte climatique au chorotype climatique : propositions de modèles graphiques (animation Anne-Christine Bronner)
-
sur Outil de suivi temporel des anomalies sur une plateforme de qualité des analyses et des prévisions océanographiques
Publié: 13 June 2023, 9:00am CEST par Bastien Potiron
Mercator Océan possède un outil de visualisation et d'analyse de données océanographiques dénommé Moniqua.
-
sur L’ère des superpétroliers. Les transports maritimes français au XXe siècle
Publié: 12 June 2023, 12:16pm CEST par r.a.

Ce travail d’historien (1) porte sur un court XXe siècle. Le pétrole n’est devenu l’« or noir » qu’entre le moment où la Grande Guerre révéla la dépendance dangereuse de notre pays et celui où il s’est transformé en « mal-aimé » dont il faut se débarrasser le plus possible dans les dernières années du siècle. Entre temps il occupe une place majeure dans les préoccupations des gouvernants, des dirigeants d’entreprise, mais aussi une place non négligeable dans celle des Français de plus en plus attachés à leur voiture. Quant à l ’« ère des superpétroliers » qui donne son titre à l’ouvrage, elle ne dure guère plus de deux décennies car la prouesse technique se révèle vite une catastrophe financière.
Le sujet comprend plusieurs composantes, économique, technique et politique. La première composante comprend la production ou l’achat du pétrole brut, le transport par oléoduc et surtout par bateau et le raffinage sur le sol national. Ces trois activités peuvent être assurées par une même compagnie ou par plusieurs compagnies, parfois filiales d’un maison-mère. Les achats se font suivant des contrats à long ou à court terme ou sur un marché spot (2). Sur le plan technique, les chantiers navals ont produit des pétroliers de plus en plus performants, c’est-à-dire offrant des coûts de transport de plus en plus bas par tpl (tonne de port en lourd) transportée, grâce à leur gros tonnage. Mais la géographie a ses impératifs. Avec un tirant d’eau élevé un superpétrolier ne peut emprunter des détroits comme celui de Malacca, ou le canal de Suez. La composante politique est majeure. Dans une France dont le sous-sol ne contient pas pétrole, le devoir de l’Etat est d’assurer la sécurité de l’approvisionnement, donc d’avoir des relations stables avec les producteurs. Ce n’est pas la même chose d’acheter du pétrole à la Norvège ou dans un des pays du Moyen-Orient ! Ces trois composantes n’évoluent pas selon les mêmes rythmes. Plusieurs années s’écoulent entre la conception et la livraison d’un nouveau type de pétrolier alors qu’une crise politique peut bouleverser les flux pétroliers maritimes en quelques semaines, voire quelques jours. C’est en fonction de ces données que l’auteur a distingué quatre périodes entre 1931 et 1994.
1931-1958 : un programme d’autonomie maritime
Au lendemain de la Première Guerre mondiale, le nouvel Office National des Combustibles Liquides (1925) se donne comme objectifs de constituer une industrie pétrolière française avec la construction de navires-citernes et de rechercher des approvisionnements. Ce dernier but est facilité par les traités qui mettent fin à la domination ottomane au Moyen-Orient. La nouvelle CFP (Compagnie française des pétroles) obtient, au titre de réparations de guerre, 23,7% de la Turkish Petroleum Compagny. Le pétrole, extrait à Kirkouk, est alors transporté par oléoduc jusqu’à Tripoli puis convoyé par la CNP (Compagnie navale des pétroles, filiale de la CFP jusqu’aux ports de Gonfreville (Normandie) et La Mède (Provence).
Entre 1928 et 1938, la consommation de pétrole est multipliée par quatre et la France est le deuxième acheteur européen alors que le transport du brut s’effectue majoritairement sur des tankers étrangers. Par crainte d’une dépendance dangereuse en cas de guerre, le gouvernement fait voter une loi en 1928, renforcée par un décret en 1931, puis par un nouveau décret en 1950 (le premier décret est suspendu en 1939) instaurant l’obligation de pavillon. 50% des importations (en 1931) puis 66% (en 1950) doivent être faites sous pavillon français. Cette particularité – qui a duré jusqu’en 1992- a entraîné la perte de compétitivité de notre flotte, le coût du transport sur des navires à l’équipage uniquement français étant beaucoup plus élevé que sur les bateaux concurrents.
La Deuxième Guerre mondiale conduit à la dévastation de l’industrie pétrolière française qui doit être entièrement reconstruite. Le redressement maritime est achevé au début des années 1950. La France peut alors profiter de nouveaux gisements en Irak et la CNP livre des bateaux qu’on appelle déjà des « supertankers » avec un port en lourd supérieur à 30 000 tpl (norme permettant le passage dans le canal de Suez). Ses 104 navires permettent à la France d’occuper le 7ème rang mondial en 1954.
1956-1973 : l’âge d’or des transports maritimes français
En 1956, le Moyen-Orient (surtout l’Irak) fournit la majeure partie de la consommation pétrolière française. Chaque année, 25 Mt de brut sont exportés par les ports de Méditerranée orientale et 58 Mt empruntent le canal de Suez. La « Crise de Suez » bouleverse ce trafic. En juillet 1956, Nasser nationalise le canal de Suez, ce qui provoque, trois mois plus tard, une intervention militaire franco-britannique. Le canal est alors entièrement bloqué et les oléoducs Irak-Méditerranée détruits. Il faut réorganiser les itinéraires. Une seule solution : le contournement de l’Afrique par la route du cap de Bonne-Espérance (20 900 km entre le golfe Persique et la mer du Nord, au lieu de 12 000km par Suez), ce qui provoque l’explosion des taux d’affrètement. Même après la réouverture du canal, on ne revient pas à la situation antérieure. On combine un aller France-Moyen-Orient par Suez et un retour par Le Cap avec des bateaux chargés, mais surtout on envisage d’utiliser des pétroliers de très gros tonnage.
Les années 1960 sont des années de réorganisation avec l’arrivée du pétrole algérien et le lancement d’un ambitieux programme d’armement par la CNP qui devient le premier armateur français. Pour diminuer les coûts de transport, on construit des Very Large Crude Carrier (VLCC), de 150 000 tpl à 320 000 tpl. Le premier gros tanker de la CNP sort des chantiers navals en 1970. Ces superpétroliers sont le produit d’innovations technologiques de pointe qui doivent permettre de compenser les charges qui grèvent le pavillon français. Nouvelles proportions, aciers spéciaux, automatisation des tâches de chargement/déchargement, augmentation du débit des pompes…, les superpétroliers assurent une augmentation de la vitesse moyenne et une économie de personnel. Ils n’embarquent que des équipages très spécialisés, moins nombreux (les besoins en équipage ne croissent pas avec la taille du navire), aux conditions de travail attractives (avantages financiers et confort). Néanmoins, les dépenses d’équipage restent plus élevées que sous les pavillons étrangers car tous les marins doivent être français.
La course au gigantisme semble justifiée par une nouvelle fermeture du canal de Suez provoquée par la Guerre des 6 jours (1967). Même si on s’approvisionne alors sur des marchés plus diversifiés et plus proches de l’Europe (Algérie, Etats-Unis, Venezuela), le Moyen-Orient reste un fournisseur majeur. Le pétrolier-roi semble alors le 200 000 tpl capable d’emprunter à l’aller, le canal de Suez sur ballast et, au retour, la route du Cap en pleine charge. Le tonnage moyen de la CNP triple en 10 ans (1961-1971). Ces très gros navires posent néanmoins des problèmes de logistique (équipement des ports, taille des raffineries, passages des détroits), ce qui ne décourage pas la commande des Ultra Large Crude Carriers (ULCC) de plus de 350 000 tpl. L’industrie pétrolière française est alors partagée entre CFP-Total et Elf-Erap qui ont des participations dans les sociétés d’armement.
A la fin des années 1960, la consommation continue d’augmenter, mais la demande est flexible alors que l’offre est rigide. Les premiers doutes sur la viabilité du marché des transports apparaissent. Les experts évoquent le risque d’un excédent de tonnage dans les années à venir d’autant que de lourdes charges pèsent sur le pavillon français alors que les pavillons de complaisance se multiplient dans le monde.
1973- 1979 : les transports maritimes pétroliers dans la tourmente
1973 est une année-tournant dans l’histoire des transports pétroliers. A la suite de la guerre du Kippour (octobre 1973), les pays arabes membres de l’OPEP décident d’augmenter unilatéralement le prix du baril de brut (quadruplement du prix en un trimestre) et d’instaurer un embargo sur les exportations destinées aux pays alliés d’Israël. C’est le premier choc pétrolier. Stagnation de la consommation et accès à des ressources plus proches du consommateur (Alaska, mer du Nord) entraînent la surcapacité des transports maritimes et de l’industrie du raffinage. Il faut alors annuler les commandes et réduire les charges au maximum. Pour répondre à ce dernier objectif, plusieurs solutions sont adoptées : ralentissement de la vitesse, utilisation des pétroliers comme stockage flottant ou comme minéraliers ou céréaliers. Mais les armateurs français souffrent toujours d’un handicap supplémentaire par rapport à leurs concurrents, l’obligation de pavillon.
Dans les années 1970, la France est le seul pays à imposer à sa flotte pétrolière de naviguer sous pavillon national (les Etats-Unis ne l’imposent que pour le cabotage le long de leurs côtes). Le surcoût est alors évalué à 1 milliard de francs par an (de plus, l’obligation de pavillon est incompatible avec le Traité de Rome). En 1977 38% du port en lourd mondial naviguent sous un pavillon de complaisance (Panama, Liberia, Bahamas…) qui fait bénéficier les armateurs d’avantages fiscaux, de facilité d’immatriculation et de l’emploi d’équipages étrangers aux charges sociales et salariales réduites. Mais les marées noires provoquées par des navires affrétés sous pavillon de complaisance soulèvent la colère des opinions publiques. Le traumatisme du naufrage de l’Amoco Cadiz (234 000 tpl) au large de Portsall (Bretagne) en est un exemple. Les organisations internationales doivent durcir leur réglementation.
1979-1994 : le crépuscule de la flotte pétrolière française
La Révolution iranienne de 1979 puis la guerre Iran-Irak de 1980-1988 provoquent une nouvelle flambée du prix du brut (augmentation du prix du baril par 5 ou 6 depuis 1978). C’est le deuxième choc pétrolier. Il est rapidement suivi d’un contre-choc (1981) car la demande s’effondre dans les pays consommateurs qui s’approvisionnent de plus en plus ailleurs qu’au Moyen-Orient (mer du Nord, Afrique de l’Ouest, Mexique…). C’est le cas de Total qui n’y achète plus que la moitié de son pétrole (Arabie Saoudite, E.A.U.). Entre 1979 et 1985, le trafic mondial de brut chute de 58%, ce qui provoque un excédent mondial de pétroliers, surtout dans la catégorie des plus grosses unités.
Face à cette baisse des besoins de capacité de transport, les armateurs français sont contraints d’opérer le retrait de navires, voués à la reconversion en vraquiers ou au désarmement et souvent à la démolition dans de grands chantiers où ils sont transformés en ferraille servant à la fabrication de nouveaux aciers.
Le redressement du commerce du pétrole à la fin des années 1980 ne permet pas d’éviter le naufrage des superpétroliers français. Les ULCC (Ultra large crude carrier) de plus de 300 000 tpl qui arrivent alors sur le marché, sont une réussite de la technologie française mais un échec économique. Lorsqu’ils sont mis en chantier au début des années 1970, deux certitudes motivaient le choix de pétroliers de gros tonnage, celle de la primauté croissante du golfe Persique comme fournisseur et celle d’une croissance continue de la demande. On néglige l’obstacle de leur tirant d’eau, trop élevé pour franchir le canal de Suez ou traverser les détroits de Malacca et du Pas de Calais. La CNN, filiale d’Elf, et la Société maritime Shell commandent donc quatre supertankers aux Chantiers de l’Atlantique capables de construire des navires de 500 000tpl. Mais dès leur mise en service, leur intérêt est remis en cause, révélant l’absence d’études sérieuses sur leur coût de fonctionnement. Non seulement leurs charges financières sont trop lourdes, mais il est difficile de trouver des cargaisons suffisantes. La contrainte du tirant d’eau les empêche de passer par Suez où la navigation est rétablie et l’impossibilité de rejoindre Rotterdam est un handicap majeur. Pour les opérateurs pétroliers, Le Havre dont l’arrière-pays est limité ne peut remplacer le port néerlandais ouvert sur le gros marché européen. Les ULCC sont donc condamnés.
La crise des transports pétroliers français est illustrée par le choix d’Elf qui désarme ses navires pour affréter l’équivalent à l’étranger. Plusieurs rapports commandés par l’Etat arrivent à la même conclusion : une surcapacité de la flotte, des navires vieillissants et surtout une absence de compétitivité due à la contrainte du pavillon. Pour continuer à assurer la sécurité des approvisionnements d’un pétrole dont on importe 96% de la consommation, on adopte un nouveau cadre juridique, le pavillon Kerguelen, en 1986. Sous ce pavillon, les équipages ne comprennent plus que 35% de marins français et ce sont les lois sociales et fiscales des TAAF qui s’appliquent. En 1996 c’est l’ensemble de la flotte pétrolière française (14 bateaux) qui arbore le pavillon Kerguelen. Mais le registre TAAF n’est qu’une réponse partielle à la crise car tous les pays européens adoptent des registres internationaux (dits « bis ») qui leur permettent de recruter des équipages entiers à très bas coût.
Après l’abandon d’une flotte en propre par le groupe Total puis la vente de CNN, dernier armateur français, en 1998, tous les tankers transporteurs de brut sont de propriété étrangère. C’est la fin des illusions françaises.
Aujourd’hui l’essentiel de la flotte mondiale circule sous pavillons de complaisance. Elle est répartie entre 350 compagnies qui siègent dans 50 pays. Les Majors ne possèdent plus que 4% du tonnage mondial. Les efforts de l’Etat français pour assurer la sécurité de l’approvisionnement en pétrole ne portent plus sur le brut mais sur le transport des produits raffinés (3).
Notes :
(1) Benoît Doessant, L’ère des superpétroliers, Editions universitaires François Rabelais, Tours, 2022. (2) Marché spot : appelé aussi « marché au comptant ». Dans ce cas,les actifs négociés font l’objet d’une livraison et d’un règlement instantanés. (3) En dehors de l’évolution de la taille des navires pétroliers, la double coque représente une innovation technologique importante pour limiter le risque des pollutions. L’échouement du pétrolier Exxon Valdez en 1989 a joué un rôle important dans l’essor de cette technologie en suscitant de nouvelles réglementations maritimes.Michèle Vignaux, mai 2023
-
sur Suivi du réservoir de Kakhovka par satellite
Publié: 11 June 2023, 7:35pm CEST par Simon Gascoin
La rupture du barrage de Kakhovka au sud de l’Ukraine a eu lieu tôt le matin du 6 juin 2023.
L’évolution de la hauteur d’eau du lac mesurée par altimétrie satellite est disponible sur Hydroweb. On peut constater que le niveau du lac est passé de 13,80 m le 8 juin à 08:18 à 11,86 m le 9 juin à 08:28, soit une baisse proche de deux mètres en 24h. La surface du lac Kakhovka dans la base OpenStreetMap est 2055 km2 (*). Donc en négligeant les apports en amont du réservoir et l’évaporation, on peut estimer le débit sortant en m3/s : 2055 km2 × 2 m / jour = 2055’000’000 × 2 / (24 × 3600) = 48’000 m3/s. A titre de comparaison, ce débit est similaire à celui du fleuve Congo, ou bien cent fois celui de la Seine.
Hauteur d’eau du réservoir de Kakhovka. Les données proviennent de trois satellites : Sentinel-6A (track number: 42), Sentinel-3A (track number: 197, 311, 584, 698) et Sentinel-3B (track number: 311,425,698).
La vidange du lac se voit aussi par imagerie optique. La bande infrarouge du capteur OLCI du satellite Sentinel-3 permet de bien distinguer la surface inondée en aval du barrage autour de Kherson [voir dans le EO Browser].
 Images Sentinel-3 du 5 juin et 7 juin 2023
Images Sentinel-3 du 5 juin et 7 juin 2023
Ces images ont une résolution assez faible (300 m/pixel) donc on ne peut pas vraiment zoomer davantage sur Kherson. Pour cela il faut chercher des images Sentinel-2 à 20 m de résolution. Malheureusement, la fréquence de revisite de Sentinel-2 est plus faible et les inondations autour de Kherson sont cachées par des nuages dans l’image Sentinel-2 du 8 juin. En revanche, les images radar du satellite Sentinel-1 ne sont pas obstruées par les nuages et révèlent les zones inondées (baisse de la rétrodiffusion = teintes plus sombres) [EO Browser] :
 Images Sentinel-1 la de rétrodiffusion en polarisation VV du 28 mai et 9 juin
Images Sentinel-1 la de rétrodiffusion en polarisation VV du 28 mai et 9 juin
Les images Landsat montrent aussi l’ampleur des inondations. La montée des eaux dans le fleuve Dniepr a même causé la remontée du niveau de l’eau dans son affluent l’Inhoulets !
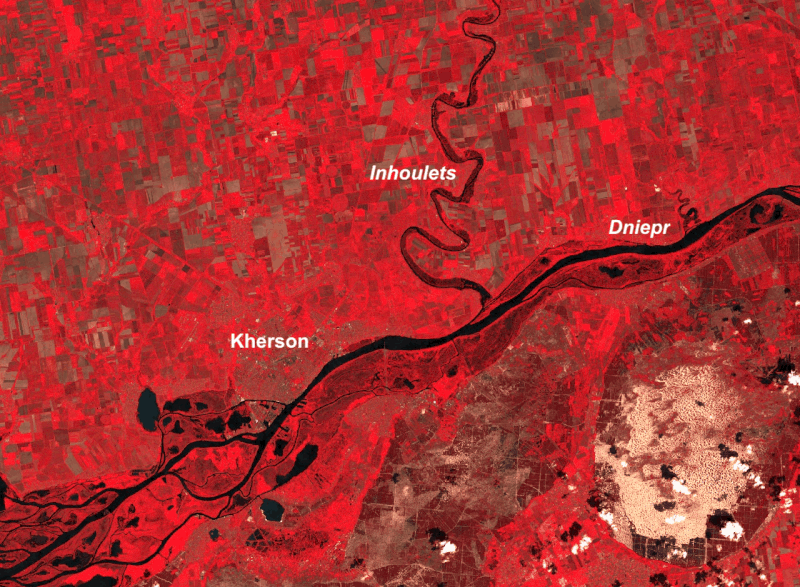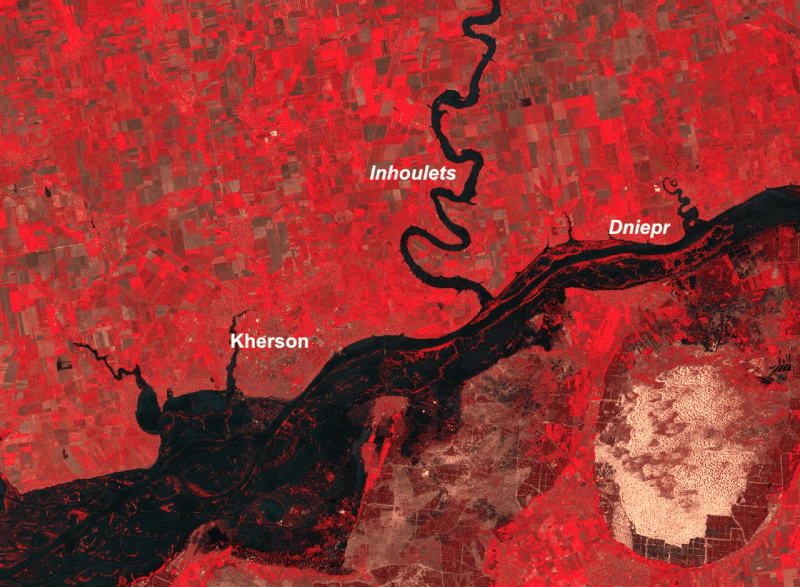 Images Landsat du 01 et 09 juin 2023 (composition colorée avec la bande infrarouge)
Images Landsat du 01 et 09 juin 2023 (composition colorée avec la bande infrarouge)
Sentinel-2 nous permet tout de même de voir le retrait du lac en amont du barrage. Vers Marianske, le trait de côté a reculé de plusieurs centaines de mètres en trois jours.
 Images Sentinel-2 du 5 juin et 8 juin 2023
Images Sentinel-2 du 5 juin et 8 juin 2023
Toutes ces images et données sont publiques et peuvent être diffusées librement.
(*) On peut récupérer le polygone du lac via le plugin QuickOSM par exemple en recherchant la clé wikidata donnée sur openstreetmap.

et calculer sa surface via le menu vecteur > ajouter les attributs de géométrie (attention à bien sélectionner « Ellipsoïdale » ou bien d’utiliser un système de projection adapté au calcul des aires).
 Pour s’assurer que le polygone est correct on peut l’exporter en GeoJSON ou KML et le superposer à une image satellite (ici Sentinel-3 09/06/2023) dans le EO Broswer.
Pour s’assurer que le polygone est correct on peut l’exporter en GeoJSON ou KML et le superposer à une image satellite (ici Sentinel-3 09/06/2023) dans le EO Broswer.

Pour en savoir plus sur Hydroweb : Cretaux J-F., Arsen A., Calmant S., et al., 2011. SOLS: A lake database to monitor in the Near Real Time water level and storage variations from remote sensing data, Advances in space Research, 47, 1497-1507 [https:]]
Photo du barrage de Kakhovka par Lalala0405 (Avril 2013) CC BY-SA 3.0, [https:]]


-
sur Le site Thinking in Space et ses cartes originales (Andrew Rhodes)
Publié: 11 June 2023, 7:03pm CEST
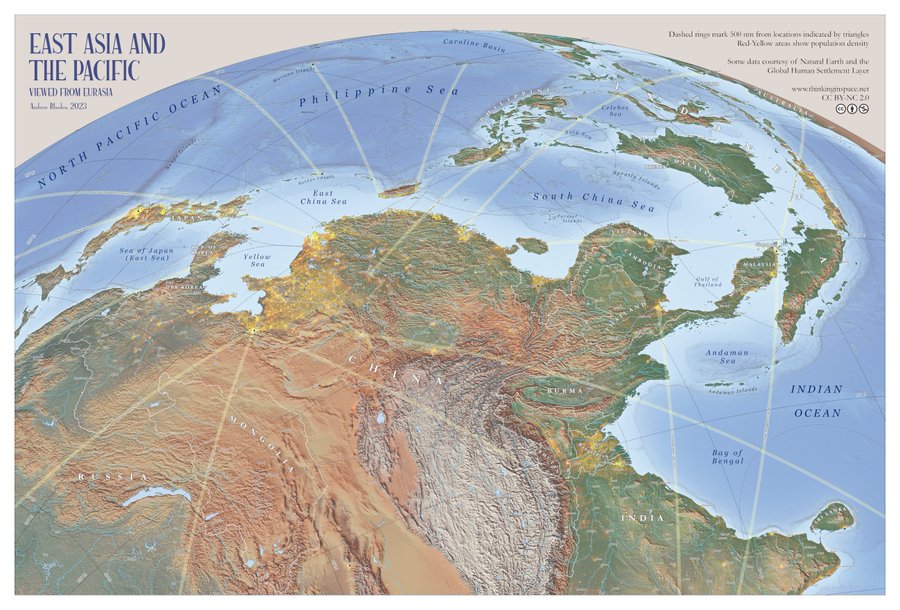
Sur son site Thinking in Space ("Penser dans l'espace"), Andrew Rhodes propose des cartes originales à télécharger gratuitement et des réflexions sur les cartes, la géographie et la géopolitique. Le site tient son nom de l'article qu'il a publié en 2019 dans la Texas National Security Review : Thinking in Space : The Role of Geography in National Security Decision-making. Pour l'auteur, « pouvoir penser dans l'espace constitue un outil crucial, mais souvent sous-estimé par les décideurs. Afin d'améliorer sa capacité à penser dans l'espace, la communauté qui travaille sur les questions de sécurité nationale doit pouvoir évaluer objectivement l'efficacité avec laquelle elle utilise l'information géographique et saisir toutes les occasions d'affiner ses compétences dans ce domaine ».Andrew Rhodes invite à regarder l'Asie et le Pacifique sous un angle différent et à discuter des enjeux géopolitiques et géostratégiques en Indopacifique. Selon lui, « invoquer la "tyrannie de la distance" est devenu un sujet de discussion habituel pour les responsables, soulignant les difficultés d'une réponse rapide et l'importance d'un déploiement avancé dans le Pacifique. Mais le contenu géographique est insuffisant pour prendre en charge ces éléments au-delà des anneaux de distance rudimentaires – qui sont souvent inexacts ». Reprenant les projections orthographiques de Richard Edes Harrison où il puise son inspiration, Andrew Rhodes invite à dépasser les visions imprimées par les projections traditionnelles. Sa carte murale de l'Asie orientale et du Pacifique vus de l'Eurasie est assez originale. Elle renverse le regard en privilégiant le point de vue de la Chine (cf ceintures de pays et d'îles voisines considérés sous son influence). La carte en haute résolution est téléchargeable en licence Creative Commons sur son site.
L'Asie orientale et le Pacifique vus depuis l'Eurasie
(source : A. Rhodes, Thinking in Space, licence Creative Commons, juin 2023)
Dans la même idée, Andrew Rhodes a élaboré la carte "Mahan's Yardstick" centrée à la fois sur l'île de Diego Garcia dans l'océan Indien et celle de Guam dans le Pacifique. L'idée est de reprendre la "distance standard" de 3500 milles nautiques établie en 1899 par Alfred Mahan estimée comme la zone d'intervention maximale pour conduire des opérations navales. Même si les moyens d'intervention militaires ont évolué depuis le XIXe siècle, la carte donne une perspective intéressante sur l'Indo-Pacifique (voir cet article) en soulignant les distances énormes à prendre en compte.
Carte reprenant la distance de 3 500 milles nautiques établie par Alfred Mahan pour appréhender l'immensité de la zone indo-pacifique (crédit : © A. Rhodes, Thinking in Space, 2021)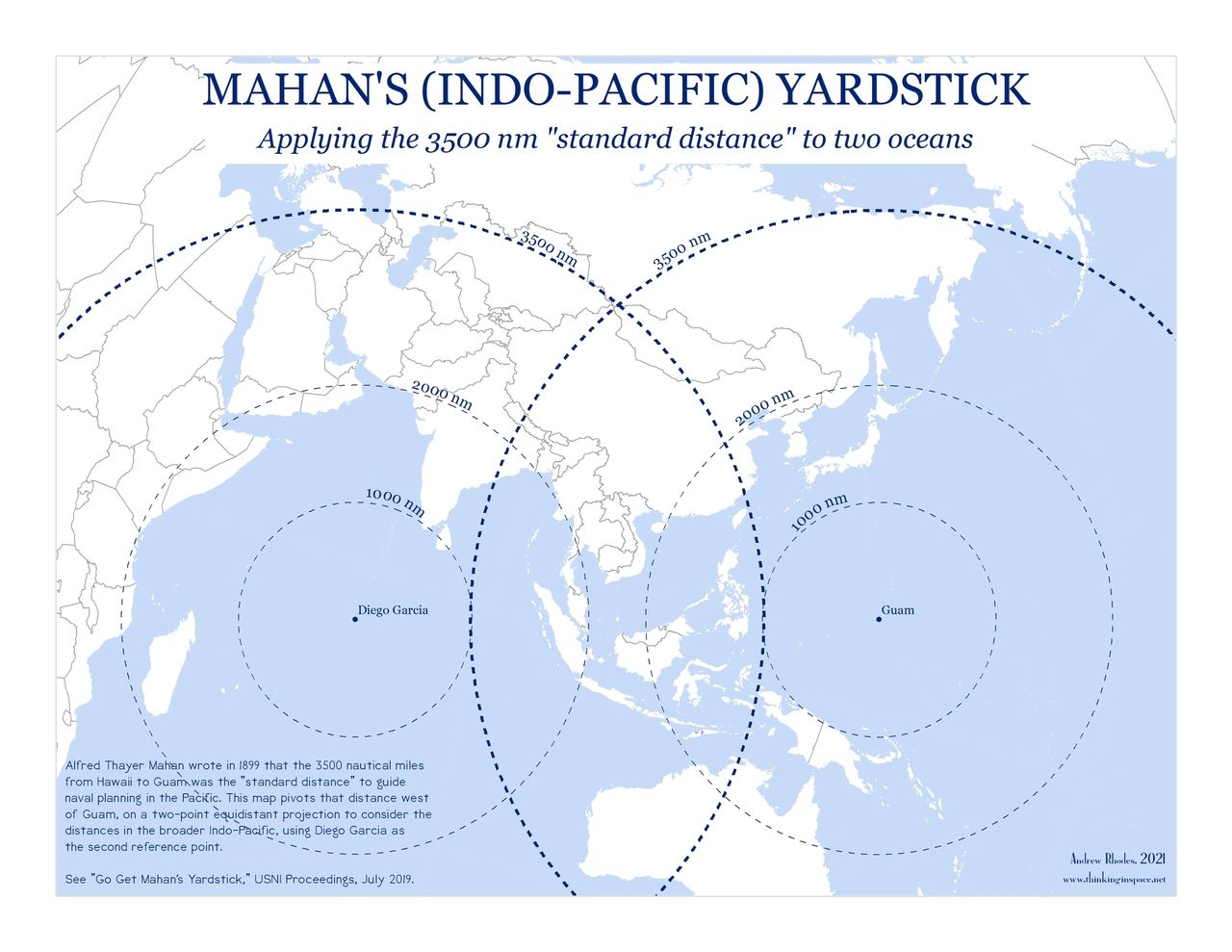 Andrew Rhodes est l'auteur de plusieurs articles de réflexion croisant géopolitique et cartographie. La série de cartes en noir et blanc "Comment la Chine voit l'Asie" est à découvrir. Il cherche aussi à reproduire des cartes anciennes, telle cette carte murale DOD des années 1960. Il est par ailleurs l'auteur d'un article sur James Monteith, cartographe et auteur de manuels de géographie au XIXe qu'il considère comme « le maître des marges » (article en accès libre ici). Au travers de la géographie et des cartes, la visée pédagogique n'est jamais loin : il s'agit de comprendre le monde dans la complexité et la pluralité des regards. Avant de publier ses cartes, Andrew Rhodes les soumet souvent sur son compte Twitter pour voir les réactions qu'elles suscitent et pouvoir intégrer des améliorations en fonction des commentaires. Voir par exemple la carte de l'alliance militaire AUKUS (Australie - Royaume-Uni - Etats-Unis) telle qu'imaginée initialement et le projet cartographique repris et peaufiné quelques mois plus tard.
Andrew Rhodes est l'auteur de plusieurs articles de réflexion croisant géopolitique et cartographie. La série de cartes en noir et blanc "Comment la Chine voit l'Asie" est à découvrir. Il cherche aussi à reproduire des cartes anciennes, telle cette carte murale DOD des années 1960. Il est par ailleurs l'auteur d'un article sur James Monteith, cartographe et auteur de manuels de géographie au XIXe qu'il considère comme « le maître des marges » (article en accès libre ici). Au travers de la géographie et des cartes, la visée pédagogique n'est jamais loin : il s'agit de comprendre le monde dans la complexité et la pluralité des regards. Avant de publier ses cartes, Andrew Rhodes les soumet souvent sur son compte Twitter pour voir les réactions qu'elles suscitent et pouvoir intégrer des améliorations en fonction des commentaires. Voir par exemple la carte de l'alliance militaire AUKUS (Australie - Royaume-Uni - Etats-Unis) telle qu'imaginée initialement et le projet cartographique repris et peaufiné quelques mois plus tard.
Compte Twitter de Rhodes Cartography : @RhodesCartogra1
Liens pour télécharger directement les cartes achevées sur le site Thinking in Space
Sélection de cartes invitant à décentrer le regard sur la zone Indopacifique avec les commentaires :- Mahan's (Indo-Pacific) Yardstick (2021)
- Bathymetry of the Pacific Ocean (2021)
- Composite China Poster (2022)
- Population Density in Asia (2022)
- New Wall Map: East Asia and the Pacific (2023)
- Andrew Rhodes, Thinking in Space: The Role of Geography in National Security Decision-Making, Texas National Security Review 2.4 (November 2019): 90-108.
- Andrew Rhodes, Go Get Mahan’s Yardstick, U.S. Naval Institute Proceedings 145.7 (July 2019)
- Andrew Rhodes, The Second Island Cloud: A Deeper and Broader Concept for American Presence in the Pacific Islands, Joint Force Quarterly 95 (Fourth Quarter 2019): 46-53.
- Andrew J. Rhodes, The Geographic President: How Franklin D. Roosevelt Used Maps to Make and Communicate Strategy, The Portolan, Washington Map Society (Spring 2020) : 7–16.
- Andrew Rhodes, Same Water, Different Dreams: Salient Lessons of the Sino-Japanese War for Future Naval Warfare, Journal of Advanced Military Studies 11.2 (Fall 2020): 35–50.
- Andrew S. Erickson, The Andrew Rhodes Bookshelf: Guiding Leaders across the Indo-Pacific through Geo-History, Strategy & Visual Communications, China Analysis from Original Sources, 12 May 2021.
Articles connexes
La carte, objet éminemment politique : la Réunion au coeur de l'espace Indo-Pacifique ?
La carte, objet éminemment politique : la Chine au coeur de la "guerre des cartes"
La carte, objet éminemment politique. Les tensions géopolitiques entre Taïwan et la Chine
Etudier les conflits maritimes en Asie en utilisant le site AMTI
Une carte réactive de toutes les ZEE et des zones maritimes disputées dans le monde
Les frontières maritimes des pays : vers un pavage politique des océans ?
L'histoire par les cartes : James Monteith, cartographe et éducateur (1831-1890)
Le nord en haut de la carte : une convention qu'il faut parfois savoir dépasser
Projections cartographiques
-
sur Carte interactif de donations: de nouveaux indicateurs à réfléchir
Publié: 9 June 2023, 3:41pm CEST par Maclean
Cet article Carte interactif de donations: de nouveaux indicateurs à réfléchir est apparu en premier sur Veille cartographique 2.0.
Comme le souligne Lukas Frank dans son article « Carte interactive d’aide alimentaire en Alsace« , 2016, les cartographies interactives présentent un intérêt dans l’accompagnement des donateurs dans leur démarche. En comparant plusieurs cartes de ce type sur des sites d’associations, on se rend compte qu’elles ont toutes les mêmes caractéristiques. Autrement dit, les informations transmises sont […]
Cet article Carte interactif de donations: de nouveaux indicateurs à réfléchir est apparu en premier sur Veille cartographique 2.0.
-
sur Revue de presse du 9 juin 2023
Publié: 9 June 2023, 2:20pm CEST
 Revue de presse de la géomatique : SotM FR 2023, LiDAR HD, Panoramax, QField, chronotrains et d'autres sujets encore.
Revue de presse de la géomatique : SotM FR 2023, LiDAR HD, Panoramax, QField, chronotrains et d'autres sujets encore. -
sur Revue de presse du 9 juin 2023
Publié: 9 June 2023, 2:20pm CEST
Revue de presse de la géomatique : SotM FR 2023, LiDAR HD, Panoramax, QField, chronotrains et d'autres sujets encore.
-
sur Le jumeau numérique : l’avenir de la géomatique ?
Publié: 8 June 2023, 9:09am CEST par Marine Dore
Cet article Le jumeau numérique : l’avenir de la géomatique ? est apparu en premier sur Veille cartographique 2.0.
Qu’est-ce qu’un jumeau numérique ? Le jumeau numérique est un concept relativement nouveau, mais qui a déjà révolutionné de nombreux domaines industriels, notamment la géomatique. Un jumeau numérique est une réplique virtuelle d’un objet ou d’un processus réel, qui peut être utilisé pour simuler, surveiller et optimiser son fonctionnement. Le jumeau numérique peut être utilisé pour […]
Cet article Le jumeau numérique : l’avenir de la géomatique ? est apparu en premier sur Veille cartographique 2.0.
-
sur Limites planétaires. Des chercheurs expliquent dans Nature pourquoi la Terre menace de devenir inhabitable
Publié: 8 June 2023, 5:21am CEST
Accès à l'article scientifique
« Plus de 40 experts alertent, dans la revue Nature, sur le franchissement de 7 des 8 lignes rouges planétaires. Ces seuils fatidiques concernent principalement le climat, la biodiversité, l’eau douce, ainsi que les cycles de l’azote et du phosphore. Cette publication s’inscrit dans la longue lignée d’articles scientifiques dédiés aux « limites planétaires ». Théorisée en 2009, la notion englobe neuf paramètres écologiques indispensables à l’équilibre du « système Terre » et, par extension, se rapporte aux seuils limites de perturbation que ces derniers peuvent endurer sans mettre en danger, de manière irréversible, les fondamentaux naturels de la planète » (source : « Des chercheurs expliquent dans Nature pourquoi la Terre menace de devenir inhabitable », Libération).
Rockström, J., Gupta, J., Qin, D. et al. (2023). Safe and just Earth system boundaries. Nature [https:]] . Article publié sous licence Creative Commons Attribution 4.0 International.
Lieux où les « limites planétaires » (ESB) ont déjà été dépassées (source : Rockström & al., 2023)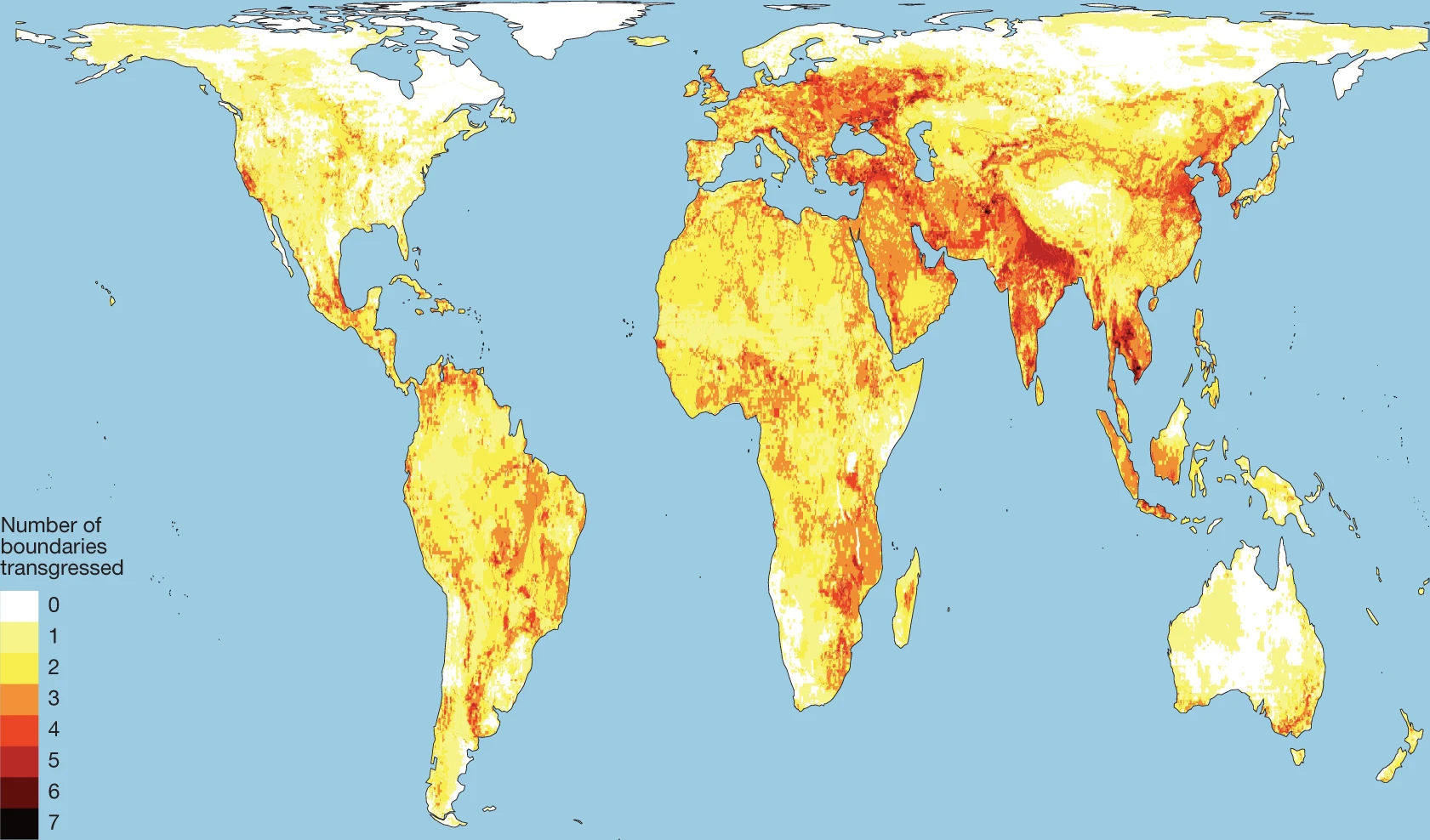 Résumé
Résumé
La stabilité et la résilience du système Terre et le bien-être humain sont inséparablement liés, mais leurs interdépendances sont généralement peu reconnues ; ils sont par conséquent souvent traités indépendamment. Nous utilisons ici la modélisation et l'évaluation de la littérature pour quantifier, à l'échelle globale et sous-globale, les limites sûres et justes du système Terre (Earth System Boundaries) concernant le climat, la biosphère, les cycles de l'eau et des nutriments ainsi que les aérosols. Nous proposons des limites planétaires pour maintenir la résilience et la stabilité du système terrestre (ESB sûres) et minimiser l'exposition à des dommages importants pour les humains du fait des changements du système terrestre (une condition nécessaire, mais non suffisante pour la justice). Nos résultats montrent que ce sont les considérations de justice plus que les considérations de sécurité qui contraignent les ESB intégrés pour le climat et la charge d'aérosols atmosphériques. Sept des huit limites planétaires quantifiées à l'échelle mondiale et au moins deux ESB sûres et justes à l'échelle régionale sont déjà dépassées sur plus de la moitié de la superficie terrestre mondiale. Nous proposons que notre évaluation fournisse une base quantitative pour la sauvegarde des biens communs mondiaux, pour tous aujourd'hui et à l'avenir.
Visualisations concentriques (a) et parallèles (b) des « limites planétaires » ou ESB (crédit : Rockström & al., 2023)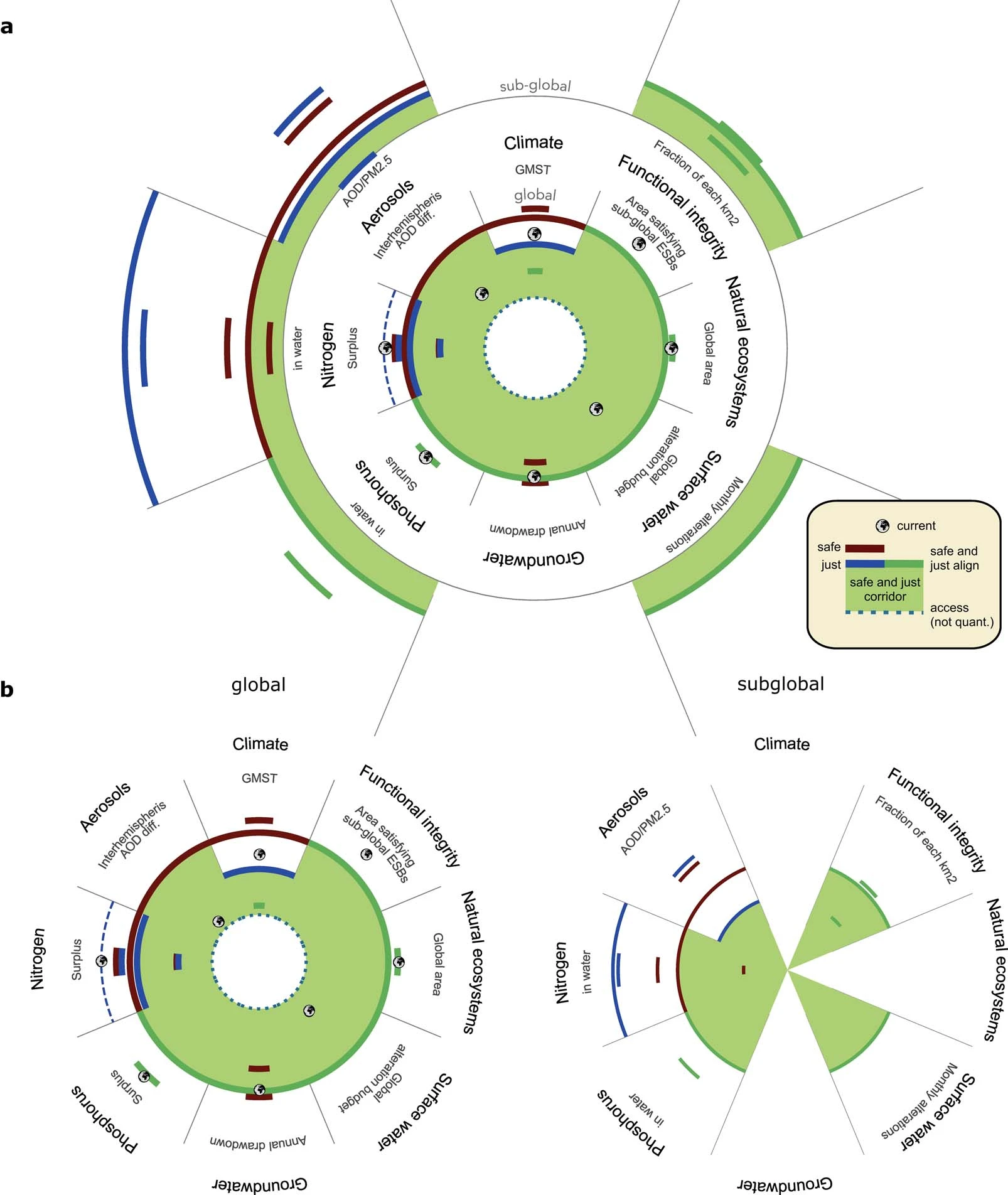
Disponibilité du code et des données
Le codes et les données utilisés pour produire les couches d'information et les figures sont disponibles dans l'article. Les chercheurs se sont appuyés sur plusieurs ensembles de données déjà publiés dans Nature, en ce qui concerne notamment les limites pour le climat, les limites pour l'azote (voir les fichiers modèles), le phosphore (voir les ventilations des scénarios), et un résumé des indicateurs de durabilité agricole, les excédents actuels pour l'azote (voir le référentiel) avec la limite critique de surplus d'azote soustraite, et la concentration sous-globale estimée de phosphate dans le ruissellement sur la base de sa charge estimée dans l'eau douce et des données locales de ruissellement.
L'intégrité fonctionnelle actuelle est calculée à partir de la carte d'occupation du sol WorldCover à résolution de 10 mètres de l'Agence spatiale européenne. La limite de sécurité et l'état actuel des eaux souterraines sont dérivés de l'expérience Gravity Recovery And Climate Experiment et du Global Land Data Assimilation System.
Pour compléter
La 6e limite planétaire est franchie : le cycle de l’eau douce (Bon pote)
Lien ajouté le 30 août 2023
Belle data visualisation interactive et en 3D du Berliner MorgenPost sur les lieux qui risquent de devenir inhabitables d'ici 2100 en raison de la crise climatique. Approche par risques.
— Sylvain Genevois (@mirbole01) April 13, 2022
Climate crisis : Mapping where the earth will become uninhabitable. [https:]] pic.twitter.com/cRH0YqnLlhArticles connexes
Comment le changement climatique a déjà commencé à affecter certaines régions du monde
Atlas de l'Anthropocène : un ensemble de données sur la crise écologique de notre temps
Les territoires de l'anthropocène (cartes thématiques proposées par le CGET)Feral Atlas, une exploration de l’Anthropocène perçu à travers la féralisation
Le calcul de l'IDH prend désormais en compte le calcul des pressions exercées sur la planète (IDHP)
Paul Crutzen et la cartographie de l'Anthropocène
Données SIG sur les écorégions terrestres
Cartes et données sur la disparition des oiseaux en Europe
Eduquer à la biodiversité. Quelles sont les données... et les représentations ?
Une carte de l'INPN pour analyser et discuter la répartition de la biodiversité en France
Utiliser les données de l'UN Biodiversity Lab sur la biodiversité et le développement durable
-
sur L'histoire par les cartes : Biélorussie, histoire d'une nation (BnF-Gallica)
Publié: 7 June 2023, 4:28pm CEST
La BnF propose des rendez-vous réguliers qui interrogent les notions d’État et de démocratie sur tous les continents, en présence de spécialistes et d’acteurs de la politique. La séance du 12 juin 2023 consacrée à la Biélorussie questionne en particulier les enjeux et les conséquences de la guerre en Ukraine pour ce pays.
Carte de la République démocratique Blanche-Ruthénienne, 1919 (source : Gallica)
La couverture médiatique de la situation politique en Biélorussie est relativement faible alors qu’une vague de répression féroce s’abat sur les oppositions, sur la société civile mais aussi sur l’ensemble de la population à la suite du mouvement de contestation sans précédent de 2020 contre la réélection frauduleuse d’Alexandre Loukachenko pour un sixième mandat. Plus de 1 500 prisonniers politiques sont aujourd’hui détenus en Biélorussie dans des conditions particulièrement inhumaines parmi lesquels Ales Bialiatski, fondateur de l’ONG Viasna de défense des droits humains et co-lauréat du prix Nobel de la paix en 2022.
Depuis le 24 février 2022, la Russie utilise la Biélorussie comme base arrière dans son agression contre l’Ukraine. La Biélorussie représente donc un enjeu important de cette guerre. Le régime d’Alexandre Loukachenko, qui s’efforçait de préserver son pouvoir et son indépendance vis-à-vis du Kremlin, soutient désormais l’agression russe contre l’Ukraine. Le 25 mars 2023, Vladimir Poutine a même annoncé avoir conclu un accord avec Alexandre Loukachenko pour le déploiement d’armes nucléaires tactiques russes sur le territoire biélorusse.
Quel est l’impact de la nouvelle situation géopolitique sur le régime politique biélorusse et sur son positionnement régional ? Comment évolue la situation intérieure en Biélorussie ? Comment l’opposition biélorusse se structure-t-elle en exil ? Enfin, quelles pourraient être les perspectives d’intégration de la Biélorussie dans un nouvel ordre européen, dans le cas d’une résolution de la guerre de la Russie contre l’Ukraine ?
Table ronde organisée par la BnF et le ministère de l’Europe et des Affaires étrangères, en français et en anglais avec traduction simultanée en français.
Avec Ryhor Astapenia, chercheur et directeur de l’initiative sur le Bélarus à Chatham House, Tatsiana Khomich, représentante du Conseil de coordination des prisonniers politiques biélorusses, et Tatyana Shukan, docteure en science politique et membre du projet de recherche BIELEXIL – Les exilés bélarusses en Europe centrale et orientale. La table ronde est animée par Faustine Vincent, journaliste au service international du Monde chargée de l’espace post-soviétique.
A cette occasion, le site Gallica consacre un dossier thématique à la « Biélorussie, histoire d'une nation », qui retrace la genèse de ce pays à partir de cartes historiques. Pour comprendre la concurrence des mémoires du passé biélorusse, il convient de revenir sur l’histoire politique de ce pays d’Europe de l’Est, bordé par la Russie au nord-est et à l’est, la Lettonie au nord, la Lituanie au nord-ouest, la Pologne à l’ouest et l'Ukraine au sud. Ayant fait office de confins pendant des siècles, son territoire a été un espace de contact entre les peuples slaves occidentaux et orientaux, entre le monde catholique et le monde orthodoxe, longtemps disputé entre Varsovie et Moscou. Indépendante depuis 1991 seulement, la Biélorussie a été successivement intégrée à la Rus’ de Kiev (Xème-XIIème siècle), au Grand-Duché de Lituanie (1236-1795), à l’Union des Deux-Nations (ou République de Pologne-Lituanie) (1569-1795), à l’empire russe (1795-1917), et enfin à l’Union des républiques socialistes soviétiques (URSS) au sein de laquelle elle a été l’une des républiques soviétiques (1922-1991).
Sources
Article consacré à la Biélorussie sur Wikipédia.
Goujon, Alexandra, Nationalisme et identité en Biélorussie, in Dov Lynch (ed.), Changing Belarus, Chaillot Paper, n° 85, November 2005, pp. 13-24.
Articles connexes
La carte, objet éminemment politique : la guerre en Ukraine
La carte, objet éminemment politique. L'annexion de quatre territoires de l'Ukraine par la Russie
La carte, objet éminemment politique. La vision réciproque de la Russie et de l'Europe à travers la guerre en Ukraine
La carte, objet éminemment politique : l'adhésion de la Finlande à l'OTAN
Ukraine-Russie. Retour sur un an de guerre en cartes et en analyses (février 2022 - février 2023)
Cartographier les dommages subis par les populations civiles en Ukraine (Bellingcat)
Comment cartographier la guerre à distance ?
La cartographie russe et soviétique d'hier à aujourd'hui
-
sur L’analyse géo spatiale pour la gestion des réseaux de distribution d’énergie électrique
Publié: 7 June 2023, 10:40am CEST par Gueye
Cet article L’analyse géo spatiale pour la gestion des réseaux de distribution d’énergie électrique est apparu en premier sur Veille cartographique 2.0.
L’analyse géospatiale est devenue un outil inestimable pour la gestion efficace des réseaux de distribution d’énergie électrique. En combinant les technologies de l’information géographique (SIG) avec les données sur les réseaux électriques, cette approche permet aux gestionnaires de prendre des décisions éclairées basées sur la localisation, la topologie et les conditions environnementales. L’un des principaux […]
Cet article L’analyse géo spatiale pour la gestion des réseaux de distribution d’énergie électrique est apparu en premier sur Veille cartographique 2.0.
-
sur L’implant cérébral Géonumérique obligatoire en 2054 [SF]
Publié: 30 May 2023, 7:00am CEST par Florian Delahaye
Vous êtes en 2054 et l’implant cérébral géonumérique devient obligatoire dès la naissance. La technologie 13G ne permet plus seulement d’améliorer les interconnexions entre les machines. Mais elle garantit également les transferts de signaux électromagnétiques dans le cerveau humain. Grâce aux implants bioniques cérébraux, le système de pensée automatique déclenche… Continuer à lire →
L’article L’implant cérébral Géonumérique obligatoire en 2054 [SF] est apparu en premier sur GEOMATICK.
-
sur Revue de presse du 26 mai 2023
Publié: 26 May 2023, 2:20pm CEST
 En cette période quasi estivale, nous vous proposons une série de news rafraîchissantes pour supporter la transition !
En cette période quasi estivale, nous vous proposons une série de news rafraîchissantes pour supporter la transition ! -
sur Carto-vandalisme dans OpenStreetMap : mythe ou réalité ?
Publié: 24 May 2023, 10:20am CEST
 Détection du vandalisme cartographique dans OSM grâce à de l'apprentissage automatique
Détection du vandalisme cartographique dans OSM grâce à de l'apprentissage automatique -
sur Revue de presse du 12 mai 2023
Publié: 12 May 2023, 2:20pm CEST
 La GeoRDP n'a pas été remarketée, elle s'appuie toujours sur vos contributions et son prix n'a pas changé;)
La GeoRDP n'a pas été remarketée, elle s'appuie toujours sur vos contributions et son prix n'a pas changé;)
-
sur Dancing statistics
Publié: 10 May 2023, 7:20pm CEST par Françoise Bahoken
Avertissement.
Ce billet ne traite pas de cartographie, mais de statistiques et de (choré)graphie.
Il n’en demeure pas moins intéressant, je vous l’assure !Alors imagines, tu aimes bien la cartographie et la chorégraphie, plus généralement la représentation graphique de données … les statistiques. Et puis un jour, frais et pluvieux, en procrastinant sur le site de la jolie revue Images des maths, tu tombes sur un court billet d’Avner Bah-Hen (professeur de Statistiques), intitulé Statistiques et danse pour l’enseignement (voir) et donc qui parle de ça :

Dancing Statistics c’est le nom d’un projet de courts métrages de la British Psychological Society pour aider le public non matheux de formation à comprendre les statistiques. Le projet porté par Lucy Irving de Middlesex University & Andy Fields de l’University of Sussex vise à présenter des concepts et notions de statistique sous une forme moderne et dansée (danse moderne, of course).
Pour cela ils mobilisent une population d’individus, à savoir une petite troupe où les individus sont des danseurs et danseuses contemporain.e.s, positionnés comme suit au départ d’un sujet.

La chorégraphie à laquelle ils et elles prennent part est visualisée en vue de dessus et logiquement accompagnée de musique. Elle se déploie sur une scène qui, parce qu’elle est munie d’axes et de positions tracés au sol facilite, d’une part, le repérage rapide de leurs positions relatives les unes par rapport aux autres, fussent-ils et elles en mouvement ; elle permet d’autre part aux spectatrices de visualiser les éléments clés de concepts et notions usuel.le.s des statistiques ainsi dansés.
Jugez-en par vous même ci-dessous en regardant cette première danse présentant la distribution de fréquence.
D’autres vidéos sont également disponibles :
Échantillonnage et erreur standard
Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.



-
sur Geotribu déménage
Publié: 5 May 2023, 10:20am CEST
 Après 3 ans sur un sous-domaine, le site va revenir sur son domaine principal. Attachez vos ceintures de favoris !
Après 3 ans sur un sous-domaine, le site va revenir sur son domaine principal. Attachez vos ceintures de favoris !
-
sur Appel à communications : “Art(s) et Cartographie(s)”, date-butoir : 31 mai 2023
Publié: 3 May 2023, 11:21am CEST par catherinevhofmann

La Commission Histoire du Comité Français de Cartographie organise le 25 novembre 2023 à l’Institut national d’histoire de l’art à Paris une Journée d’études intitulée « Art(s) et cartographie(s) ».
Par-delà les études classiques sur la place spécifique de la cartographie dans l’histoire des savoirs scientifiques, et les analyses répétées sur les engagements de la cartographie (et des cartographes) dans diverses opérations politiques, il est nécessaire d’envisager les relations de la cartographie avec les arts et les artistes ainsi que ses formes d’implication dans les cultures visuelles des sociétés modernes et contemporaines. Les recherches sur ce sujet sont déjà nombreuses, et fructueuses, et ont permis d’établir de façon décisive les multiples niveaux et formes d’interaction entre les mondes de la cartographie et les mondes de l’art.
Cette Journée d’études souhaiterait être l’occasion de rassembler et de confronter quelques-unes des pistes principales de la recherche actuelle et, en ce sens, elle accueillera des propositions dans plusieurs directions :
1/ Les artistes et la cartographie
Les artistes, depuis longtemps, ont mobilisé la cartographie dans leurs œuvres et ont eux-mêmes dessiné des cartes. Des peintres furent impliqués à la Renaissance dans la réalisation des cartes à grande échelle ; les « pourtraiteurs » au service des corps de ville ont pleinement participé au renouvellement de la cartographie urbaine et de la chorographie à l’époque moderne ; les ingénieurs des Ponts et Chaussées au XVIIIe siècle étaient formés à la cartographie comme au dessin de paysages. Aujourd’hui, de nombreux artistes font de la cartographie un domaine d’investigation privilégié. Ils et elles conçoivent des cartes, ou bien utilisent des cartes déjà faites, les transforment, les assemblent, ou les insèrent dans leurs œuvres. La cartographie est un champ d’actions artistiques très variées et, parfois même, une forme de l’art. On aimerait, au cours de cette Journée d’études, réunir des contributions qui viendraient à la fois illustrer et interroger cette longue fréquentation des artistes et de la cartographie. Les propositions peuvent aborder les périodes les plus anciennes comme les contemporaines.
2/ La cartographie et les métiers d’art
De façon plus spécifique, on aimerait aussi interroger les circulations professionnelles, les transferts et transmissions de pratiques, entre art et cartographie, là encore sur un temps long. Quels sont les métiers d’art impliqués dans les opérations de fabrication des cartes ? Comment, par exemple, s’articulent en termes de pratiques et d’identités professionnelles, les intentions scientifiques, informationnelles, et les motivations décoratives, ornementales, ou symboliques ? Ou bien, autre exemple, peut-on dégager la présence de « styles » ou d’« écoles » dans l’écriture des cartes ? Ou encore, peut-on repérer les trajectoires par lesquelles les cartes sont introduites, reproduites et mobilisées dans les entreprises de divertissement et plus généralement dans les cultures visuelles de leur époque ?
3/ Cartographie, collections, et marché de l’art
Les cartes sont des objets, parfois luxueux, souvent conservés et exhibés (ou au contraire dissimulés) comme des pièces précieuses. Et, à cet égard, elles sont recherchées par des spécialistes, des amateurs, des collectionneurs fortunés, mais aussi des institutions publiques de conservation et de documentation. Autrement dit les cartes, au-delà de leur dimension cognitive, ont d’autres valeurs, tout à la fois affectives, symboliques, patrimoniales, et marchandes, et à ce titre leur circulation dans le public dépend aussi des possibilités et des contraintes du marché. Cette Journée réunira des contributions qui voudront mener l’interrogation dans cette direction : la carte comme objet de collection, comme objet convoité, exhibé pour le prestige ou dissimulé à des fins de capitalisation. Elle aimerait mettre en lumière le rôle décisif des collectionneurs, curateurs, ou autres animateurs du marché, dans la circulation des objets cartographiques et, au-delà, des contenus de connaissance que ces objets véhiculent.
Modalités pratiques
Les propositions de communication (environ 1500 signes), accompagnées d’une courte bio-bibliographie, sont à envoyer à l’adresse suivante : catherine.hofmann@bnf.fr
avant le 30 avril 2023.
Le comité de sélection se réunira en mai et communiquera les résultats de l’appel à communication courant juin. Les communications retenues auront vocation à être publiées dans un numéro de la revue du Comité français de cartographie, Cartes & Géomatique, au courant de l’année 2024.
Bibliographie indicative
Ouvrages
Baynton-Williams Ashley, The curious map book. Chicago, The University of Chicago Press, 2015, 240 p.
Besse Jean-Marc et Tiberghien Gilles A. (ed.), Opérations cartographiques, Arles : Actes Sud ; [Versailles] : ENSP, 2017, 1 vol. (345 p.)
Béziat Julien, La carte à l’oeuvre : cartographie, imaginaire, création, Pessac : Presses universitaires de Bordeaux : Centre de recherche CLARE-ARTES, 2014, Collection ARTES, 1 vol. (162 p.)
Buci-Glucksmann Christine, L’oeil cartographique de l’art, Paris : Galilée, 1996, 1 vol. (177 p.)
Cartwright William, Gartner Georg, Lehn Antje (ed.), Cartography and art, New-York : Springer, 2009, collection : Lectures Notes in Geoinformation and Cartography, 1 vol. (391 p.)
Casey Edward S., Earth-mapping : artists reshaping landscape, Minneapolis : University of Minnesota Press, 2005, 1 vol. (242 p.)
Castro Terasa, La Pensée cartographique des images. Cinéma et culture visuelle, Lyon, Aléas, 2011.
Cosgrove Denis, Apollo’s eye : a cartographic genealogy of the earth in the western imagination. Baltimore ; London : Johns Hopkins university press, 2001, 1 vol. (331 p.)
Dorrian Mark and Pousin Frédéric (ed.), Seeing from above : the aerial view in visual culture. London : I.B. Tauris, 2013, 1 vol. (312 p.)
Dryansky Larisa, Cartophotographies : de l’art conceptuel au land art, [Paris] : CTHS : INHA, Institut national d’histoire de l’art, 2017, 1 vol. (335 p.)
Ferdinand Simon, Mapping beyond measure : art, cartography, and the space of global modernity, Lincoln : University of Nebraska Press, 2019, 1 vol. (298 p.)
Field Kenneth, Cartography : a compendium of design thinking for mapmakers, Redlands, California : Esri Press, 2018, 1 vol. (549 p.)
Harley John B. and Woodward David; Monmonier Mark; Edney Matthew H. and Pedley Mary Sponberg (ed.), The history of cartography, Chicago ; London : The University of Chicago press, 1987-, vol. 1- 4, 6. [Volumes 1, 2, 3 et 6 accessibles en ligne sur le site de l’éditeur : https://press.uchicago.edu/books/HOC/index.html]
Harmon Katharine, You are here : personal geographies and other maps of the imagination. New York : Princeton architectural press, 2004, 1 vol. (191 p.)
Hofmann Catherine (ed.), Tesson Sylvain (préf.), Artistes de la carte : de la Renaissance au XXIe siècle : l’explorateur, le stratège, le géographe, Paris : Autrement, 2012, 1 vol. (223 p.)
Landsman Rozemarijn, Vermeer’s maps, New York, The Frick Collection, DelMonico Books, 2022, 128 p.
Lewis-Jones Huw, The Writer’s map : an atlas of imaginary lands, Chicago : The University of Chicago Press, 2018, 1 vol. (256 p.)
Paez Roger, Operative mapping : maps as design tools. New York : Actar Publishers ; [Barcelona] : ELISAVA, 2019, 1 vol. (327 p.)
Rodney Shirley, Courtiers and cannibals, angels and amazons: the art of the decorative cartographic titlepage, GH Houten : HES & DE GRAAF, 2008, 1 vol. (272 p.)
Schulz Juergen, La cartografia tra scienza e arte : carte e cartografi nel Rinascimento italiano, Modena : F. C. Panini, 2006, 1 vol. (202 p.)
Woodward David (ed.), Art and cartography: six historical essays, Chicago ; London, University of Chicago press, 1987, collection : The Kenneth Nebenzahl Jr. lectures in the history of cartography, 1 vol. (249 p.)
Catalogues d’expositions (par ordre chronologique)
Cartes et figures de la terre [Exposition, Centre Georges Pompidou, Paris, 24 mai-17 novembre 1980]. Paris : Centre Georges Pompidou, Centre de création industrielle, 1980, 1 vol. (479 p.)
Monique Pelletier (ed.), Couleurs de la Terre : des mappemondes médiévales aux images satellitales. [Exposition. Paris, BnF, « Figures du ciel et Couleurs de la Terre », 8 octobre 1998-10 janvier 1999]. Paris : Seuil : BnF, 1998, 1 vol. (175 p.)
Barber Peter and Harper Tom, Magnificent maps : power, propaganda and art [Exposition. Londres, British Library. 2010]. London : The British Library, 2010. 1 vol. (176 p.)
Monsaingeon Guillaume (ed.), Mappamundi, art et cartographie [Exposition, Toulon, Hôtel des arts, Centre d’art du Conseil général du Var, 16 mars-12 mai 2013], Marseille : Parenthèses, impr. 2013, 1 vol. (190 p.)
Gehring Ulrike, Weibel Peter (ed.), Mapping spaces : networks of knowledge in 17th century landscape painting [Exposition, ZKM Museum of contemporary art, Karlsruhe, April 12 – July 13, 2014], Munich : Hirmer, 2014, 1 vol. (504 p.)
Harper Tom (ed.), Maps and the 20th century : drawing the line [Exposition, British Library exhibition, 4 November 2016 – 1 March 2017]. London : British Library, 2016, 1 vol. (256 p.)
Dumasy-Rabineau Juliette, Gastaldi Nadine, Serchuk Camille, Quand les artistes dessinaient les cartes : vues et figures de l’espace français, Moyen âge et Renaissance [exposition, Paris, Hôtel de Soubise-Musée des Archives nationales, 25 septembre 2019-6 janvier 2020], Paris : le Passage : Archives nationales, 2019, 1 vol. (239 p.)

-
sur Retour sur la participation de CartONG à la Nuit de la Géographie 2023 !
Publié: 26 April 2023, 9:47am CEST par Yelena Yvoz
CartONG a, pour la 5e fois consécutive, coordonné plusieurs ateliers de cartographie collaborative simultanément en France, en Afrique francophone et en ligne, à l’occasion de la 6ème édition de la Nuit de la Géographie !
-
sur PyQGIS Resource Browser : un plugin pour parcourir les icônes de QGIS
Publié: 23 April 2023, 6:20pm CEST
 Après le tutoriel et le site, voici le plugin QGIS : PyQGIS Resource Browser ! Idéal pour parcourir les icônes et copier la syntaxe d'intégration.
Après le tutoriel et le site, voici le plugin QGIS : PyQGIS Resource Browser ! Idéal pour parcourir les icônes et copier la syntaxe d'intégration.
-
sur Penser un monde sans frontières depuis l’Afrique
Publié: 20 April 2023, 6:22pm CEST par Françoise Bahoken
Ce n’est pas tous les jours que je peux me vanter d’être la co-autrice d’un document signé de la main d’Achille Mbembé, historien et politologue camerounais, diplômé de l’université Panthéon-Sorbonne Paris 1 et de Sciences Po Paris, avant d’être professeur d’histoire (de l’Afrique) aux États-Unis. Éminent penseur francophone sur l’Afrique post-coloniale et le pouvoir, il tire sa notoriété notamment de son esprit critique sur la décolonisation, les relations France-Afrique et le pouvoir de l’ancien colon français ; esprit qu’il exerce aujourd’hui en vrai globe penseur » depuis Johannesburg où il est installé.
Cette opportunité m’a été proposée par Migreurop, pour la réalisation d’un chapitre de l’Atlas des migrations dans le monde (2022) intitulé Penser un monde sans frontières depuis l’Afrique. Sont présentés ci-après quelques passages ainsi que la carte associé.e.s, le texte intégral étant disponible sur Cairn, mais pour abonné.e.s de l’ESR seulement – m’en faire la demande si souhaité.
« Décider qui peut se déplacer, s’installer, où et dans quelles conditions, est aujourd’hui au cœur des luttes politiques. Comment repenser l’utopie d’un monde sans frontières et partant, d’une Afrique sans frontières ?
Il faut partir du concept de libre circulation, en l’opposant aux conceptions africaines précoloniales du mouvement dans l’espace. Dans le modèle libéral classique, la sécurité et la liberté ont été définies comme un droit d’exclusion : l’ordre consiste à garantir l’ordonnancement inégal des relations de propriété. Affirmer les frontières de la nation, c’est affirmer les frontières de la race, donc donner une définition adéquate des frontières du corps, et de la centralité du corps dans le calcul de la liberté et de la sécurité.
L’Afrique précoloniale n’était sans doute pas un monde sans frontières (du moins pas au sens propre), mais les frontières existantes étaient toujours poreuses et perméables. Comme en témoignent les traditions de commerce à longue distance, la circulation était (et est toujours) fondamentale dans la production de formes culturelles, politiques, économiques, sociales et religieuses. S’arrêter, c’est prendre des risques ; pour survivre, il faut être constamment en mouvement, particulièrement en situations de crise.
(…)
On retrouve cela dans les réseaux et les carrefours (qui sont importants dans la littérature africaine), ainsi que dans les flux de personnes et les flux de nature, tous deux en relation dialectique : dans ces cosmogonies on ne peut imaginer les individus sans ce que nous appelons la nature. (…) ».L’idée à l’origine de la carte qui suit était d’illustrer cette assertion d’Achille Mbembé en montrant que l’Afrique n’est pas un endroit statique, immobile mais une terre truffée de mouvements à la faveur de diverses infrastructures de transport. Pour cela, il a fallu tenter de les cartographier de la manière la plus complète possible, même si l’exhaustivité est illusoire. Plusieurs sources d’information libres et gratuites ont ainsi dû être mobilisées, gérées simultanément et harmonisées pour pouvoir être représentées de manière lisible.
Pour une Afrique des circulations et une circulation en Afrique
 Source : Atlas des migrations dans le monde (2022).
Source : Atlas des migrations dans le monde (2022).L’Afrique dans son entièreté est striée de part et d’autre de linéaires de réseaux terrestres, routiers ou fluviaux, maritimes et aériens (non représentés) qui prennent place à différentes échelles ; un gigantesque réseau transafricain étant d’ailleurs en projet. Ces réseaux sont eux-mêmes ponctués de carrefours et autres hubs d’accès qui structurent les mouvements des personnes, des animaux, des monnaies et des biens, des savoirs et des religions en Afrique depuis plusieurs siècles. Si ces réseaux permettent de parcourir le continent depuis la nuit des temps, n’oublions pas que cela n’est pas toujours très facile : les infrastructures s’articulant parfois tant bien que mal avec la topographie locale, un environnement naturel et des conditions climatiques parfois difficile qui contraignent localement les libres circulations.
« (…) Le partage de l’Afrique au 19e siècle et le découpage de ses frontières selon les lignes coloniales ont transformé le continent en un immense espace carcéral, et chacun d’entre nous en un.e migrant·e illégal·e potentiel·e, incapable de se déplacer sauf dans des conditions de plus en plus répressives. Nous piéger est devenu la condition préalable à l’exploitation de notre travail, c’est pourquoi les luttes pour l’émancipation ont été si étroitement liées aux luttes pour le droit de circuler librement. Si nous voulons parachever la décolonisation, nous devons faire tomber les frontières coloniales et faire de l’Afrique un vaste espace de circulation pour elle-même, pour ses descendant·e·s et pour toutes les personnes qui veulent lier leur destin à notre continent. »
Référence :
Mbembe, A. & Bahoken, F. (2022). Penser un monde sans frontières depuis l’Afrique. Dans : Migreurop éd., Atlas des migrations dans le monde: Libertés de circulation, frontières et inégalités (pp. 144-147). Paris: Armand Colin. [https:]]Billet lié : Françoise Bahoken (2022) Atlas des migrations dans le monde, Carnet néocartographique.
Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.
-
sur Comment tester la lisibilité d’une composition graphique avec un modèle d’IA ?
Publié: 18 April 2023, 8:09am CEST par Laurent Jégou
L’analyse d’image par réseaux de neuronesAvec les systèmes d’Intelligence Artificielle (‘IA’) du type “réseaux de neurones“, il est aujourd’hui possible de simuler l’importance visuelle des éléments d’une image, c’est-à-dire l’ordre et la durée avec laquelle les différentes parties de l’image vont être perçues par un observateur lambda. On parle aussi de saillance visuelle, pour qualifier l’effet de sauter aux yeux.
L’intérêt de ces méthodes réside dans leur capacité à indiquer les éléments les plus lisibles d’une image, les plus saillants, donc sa hiérarchie visuelle :
- Pour vérifier que sa composition graphique (mise en page, planche de cartes…) est bien organisée et de manière efficace (du point de vue de la lisibilité, de la structuration et de la quantité d’information).
- Pour évaluer la lisibilité de choix esthétiques plus originaux, artistiques.
Ces outils peuvent ainsi simuler les réactions de perception visuelle humaine, si on les entraine sur un corpus d’images pré-analysées par des humains. Ainsi, l’algorithme va dégager des règles de perception de son corpus d’entraînement et pourra les reproduire sur de nouvelles images.
Pendant longtemps, ces algorithmes étaient utilisés pour guider des véhicules à partir d’images de caméras, car la demande est forte pour les véhicules autonomes. En 2020, des chercheurs du M.I.T et d’Adobe ont l’idée d’entraîner un réseau de neurones à partir d’images de composition graphique (graphic design) : des posters, des cartes, des tableaux de bord de données… 1000 images ont ainsi été étudiées par 250 personnes, à qui on a demandé de désigner les zones les plus importantes, dans l’ordre de lecture.
Le résultat, le modèle UMSI (Unified Model of Saliency and Importance), est très intéressant (dernière colonne de l’image ci-dessous), d’autant plus que l’article, le code et les données (le modèle résultat de l’analyse du corpus) ont été rendus disponibles (pour une utilisation non commerciale) : predimportance.mit.edu

Comparaison des résultats de l’algo. UMSI aux autres modèles (source : Fosco et al., 2020).
L’algorithme est ainsi utilisable via un carnet interactif Python, hébergé sur GitHub et mis à disposition via une machine virtuelle Binder, le tout gratuitement. Cette installation a été produite pour l’école thématique “TransCarto” du CNRS, en octobre 2021, pour illustrer une présentation sur les images cartographiques.
Comment utiliser librement cet outil ?Pour l’école thématique TransCarto, un carnet interactif Python a été préparé, à partir du carnet source de l’article (fork). Il s’agit d’une page web interactive qui permet d’exécuter du code Python dans une machine virtuelle, à distance, et de récupérer les résultats des traitements. Ce carnet, de type Jupyter Notebook, est hébergé gratuitement dans le gestionnaire de code source GitHub de TransCarto, et il peut être exécuté tout aussi gratuitement via le service Binder.
- Se rendre sur la page GitHub de TransCarto : github.com/transcarto
- Choisir le dépôt “PredImportance-public” : ./transcarto/predimportance-public
- Cliquer sur le bouton “Binder”


Le carnet Jupyter se lance au bout d’un moment plus ou moins long d’initialisation (plusieurs minutes la première fois, avec parfois des plantages, car c’est une ressource gratuite et partagée). Lorsqu’il est démarré, le carnet affiche la liste des fichiers du carnet, il faut choisir le fichier qui contient le notebook par un double-clic sur transcarto_umsi.ipynb

Ce carnet fonctionne suivant le principe général des carnets de code interactif : des cellules sont modifiables et exécutables (bouton flèche triangulaire en haut du carnet), on les édite (éventuellement), puis on les lance une à une pour dérouler l’algorithme petit à petit, du haut vers le bas.
Le fait que le code soit modifiable permet de :
- modifier les fichiers image à analyser (deux images sont fournies par défaut)
- modifier les réglages de l’algorithme (éventuellement, par exemple la palette de couleurs)

On va décrire ici les différents blocs de code du carnet, leur fonction et leur modification potentielle.
- 1°) Le premier bloc est constitué de commentaires sur les prérequis à l’utilisation du code en local. Dans l’image Binder, les pré-requis ont été fournis par le fichier requirements.txt du dépôt (qui sera mis à jour régulièrement pour tenir compte des versions des modules accessibles par Binder, qui évoluent selon les mises à jour de sécurité).
- 2°) Le deuxième bloc réalise les imports du carnet, c’est à dire le chargement des bibliothèques de fonctions utiles, notamment TensorFlow/Keras qui gère le modèle de réseau de neurones. Lors de l’exécution de ce bloc, des messages s’affichent dans la zone de résultat du bloc, ce sont des informations non bloquantes pour la suite du processus.
- 3°) Le troisième bloc contient les fonctions auxiliaires (ouverture et adaptation des images), qui sont appelées par le code principal (bloc 6 – Predict Maps).
- 4°) Le quatrième bloc va télécharger (dans l’image Binder) le (gros) fichier du modèle UMSI, c’est à dire le réseau de neurones et les pondérations issues de l’expérience des 250 participants sur les 1000 images. Ce fichier est stocké sur un serveur externe, car sa taille (115Mo) dépasse le volume autorisé par GitHub en accès gratuit. À l’exécution, ce bloc produit lui aussi des messages d’information non bloquants (chargement, erreurs/problèmes de configuration matérielle).
- 5°) Le cinquième bloc est celui qui permet de choisir ses propres images JPEG à analyser, en fournissant une ou deux URLs vers ces images. Une fois exécuté, il affiche les images et leur éventuel redimensionnement (bandes noires).

- 6°) Le sixième bloc ne contient qu’une seule ligne, mais c’est celle qui lance le traitement des images, en appelant les fonctions auxiliaires évoquées plus haut.
- 7°) Enfin, le septième bloc produit les images de résultat : images source, “carte” de saillance selon une palette bleu/vert/jaune (viridis), et superposition en transparence des deux.
-> Il est possible de les télécharger par un shift+clic droit.

On peut générer une image de résultat (carte de saillance) en utilisant le bloc de code vide en bas du carnet.
Il faut pour cela saisir la ligne de code suivante, en utilisant les numéros des images (0 et 1) :
plt.imshow(pred_batch[0])

Le choix de la palette de couleurs de la carte de saillance peut se faire parmi les palettes disponibles dans la bibliothèque de fonctions MatPlotLib. Il faut préciser le nom de la palette dans la ligne de code suivante du bloc 7, en remplacement de “viridis” :
# Overlay heatmap on image
res = heatmap_overlay(im,pred_batch[i],’viridis’);Enfin, comme le code source du carnet est librement accessible, on peut en télécharger une version pour l’exécuter en local sur sa machine, à la condition d’avoir installé les différents prérequis (Python 3.7, TensorFlow, etc.) et de posséder le matériel compatible pour les calculs (GPU vidéo de marque Nvidia).
Interpréter les résultatsLes résultats s’interprètent selon la palette de couleur.

Palette Viridis

La “carte” de saillance seule, selon la palette viridis

L’image d’origine (pour comparaison)
Les parties en jaune vif de l’image résultat sont considérées par l’outil comme étant saillantes, c’est à dire qu’elles correspondent à des régions et à des couleurs qui ont été repérées par les sujets qui ont entraîné le modèle. Elles seront donc généralement vues en premier et attireront le plus l’attention.
À partir de ce constat, on peut comparer la “carte” de saillance avec l’image d’origine et sa structure, sa hiérarchie d’information, pour voir si ces zones correspondent :
- Est-ce que les zones les plus saillantes de la carte de saillance (en jaune) sont aussi celles qui sont intéressantes pour commencer la lecture progressive de l’image et bien en comprendre le contenu ? (titre, légende, parties importantes de la carte)
- Réciproquement, il faut se demander si les zones de la carte d’origine que l’on considère importantes pour la compréhension sont bien saillantes sur l’image générée par l’outil.
Logiquement, le titre principal, bien lisible (position, taille de la police, isolement et contraste), est bien repéré comme saillant visuellement (partie horizontale jaune en haut de la carte de saillance). Ensuite, les zones saillantes sont localisées de manière moins interprétable, sur l’Europe de l’ouest dans la carte de gauche et sur la mer Rouge dans la carte de droite de la planche d’origine. Une explication pourrait être la position des “taches” rouges contrastées (sur fond blanc) dans l’ordre de lecture gauche-droite puis haut-bas. C’est peut-être un biais de cet outil de simulation, à vérifier en comparant avec d’autres analyses de compositions graphiques.
On remarque aussi des valeurs faibles de saillance qui sont intéressantes, notamment sur les légendes (qui devraient pourtant être saillantes pour une bonne compréhension des images), et sur les pays en rouge du haut de la carte de droite (où le phénomène de vieillissement est important). Les dates des deux images ne sont pas saillantes du tout, ce qui rend la compréhension de la planche complexe.
En conséquence, pour améliorer l’efficacité de cette planche cartographique, on pourrait tester :
- une réorganisation de la mise en page (pour placer les cartes verticalement)
- un changement de la palette de couleurs des cartes ?
- une augmentation de la visibilité des légendes
- une augmentation de la visibilité des dates des deux cartes
Il restera à tester l’analyse sur ces nouvelles versions !
Enseignant-chercheur en géographie et géomatique, Univ. Toulouse-Jean Jaurès et UMR LISST-Cieu.
Follow Me:

-
sur C’est le printemps … des cartes !
Publié: 17 April 2023, 2:36pm CEST par Françoise Bahoken
La question demeure : où placer la limite, que définit la limite ? Une topologie de l’espace qui nous correspond (peut-être), et qui entoure ce « nous » qui reste parfois à définir.
Christine Plumejeaud, 2023.Le printemps des cartes, c’est le nom d’un festival annuel de médiation scientifique organisé depuis 2018 autour des cartes et de cartographies de toutes sortes, par un collectif de ge?ographes, cartographes, artistes et passionne?s de la carte à Montmorillon. Issu d’une collaboration entre l’Universite? de Poitiers, la MJC Claude Nougaro de Montmorillon et l’Espace Mende?s France de Poitiers, le festival illustre Montmorillon, une bourgade de la Vienne déjà rendue célèbre par ses éditions cartographiques et qui l’est désormais d’autant plus qu’elle accueille un festival de cartographie.
Le programme proposé cette année est très ambitieux, puisqu’il est question de la représentation des frontières pour (nous) aider à (nous) ouvrir à un monde qui n’a de cesse de se fermer ces derniers temps. Pour cela, le festivalier est invité à accueillir les beaux jours, en dépassant les frontières …

… grâce au concours d’une brochette de cartographes témoignant de la variété du métier et aussi de son dynamisme, sans cesse maintenu depuis la nuit des temps.
Le Festival de Montmorillon est composé de 8 rubriques principales de tous niveaux et accessibles à toutes et à tous.
 Aussi riches et fournies les unes que les autres, les différentes rubriques sont combinées dans un programme à la carte qui évoque, par son motif à la Perpillou [mon grand cousin me souffle à l’oreille qu’on dit « carte en pyjama »] celui du Festival International de Géographie de Saint-Dié des Vosges.
Aussi riches et fournies les unes que les autres, les différentes rubriques sont combinées dans un programme à la carte qui évoque, par son motif à la Perpillou [mon grand cousin me souffle à l’oreille qu’on dit « carte en pyjama »] celui du Festival International de Géographie de Saint-Dié des Vosges.
Plus sérieusement, le programme permet d’alterner entre des conférences, des ateliers, des jeux grandeur nature et des sorties terrains, des tables rondes et des expositions … autrement dit entre des visions scientifiques, des présentations techniques-métiers, des expositions artistiques et/ou ludo-éducatives de cartes et autres processus cartographiques.
Ce qui est m’apparaît intéressant est qu’on voit cohabiter plein de vues différentes : des approches réflexives au sein de présentations pointues et des dispositifs légers plutôt destinés au grand public, à l’information mais aussi à la rêverie. Les propositions sont en effet organisées autour de férus de cartographie qui sont soit très connus, par leur présence dominante dans les médias et pour cause, il s’agit de nos camarades du quotidien le Monde (l’excellent Xémartin Laborde et ses collègues) que l’on ne présente plus, ou soit des collègues mobilisés pour la journée d’étude organisée par l’Atlas historique de la nouvelle Aquitaine et que je salue au passage.La journée étant dédiée aux frontières, une présentation régalienne du Ministère de l’Europe et des Affaires étrangères est organisée sur le rôle du cartographe dans la délimitation du territoire, dans l’écriture, dans « l’élaboration de la frontière ». Rien que àa.
Les présentations éducatives réalisées à destination d’un public de scolaires ne sont pas en reste : on notera le Forum climat organisé à la MJC de Montmorillon entre des élus et élèves ou encore l’exposition Habiter la terre formée de maquettes réalisée par des sixièmes ; ces dernier.e.s pourront ensuite s’amuser avec Zeplindejeux de cartes à jouer pour ne citer qu’eux.
La cartographie se vivant également à Montmorillon, le Festival vous conduira à arpenter le terrain pour admirer les différentes propositions, mais aussi participer activement à la fabrication de cartes, que ce soit dans le cadre d’une party organisée avec vos amis autour d’Open Street Map avec CartoONG, lors d’un atelier à terre de (dé)construction cartographique avec Anne Lascaux, ou bien la tête dans les étoiles, au planétarium de l’espace PMF. Vous pourrez également vous promener en « cartomobile » avec Morgane Dujmovic [Coucou’ Morgane, mais qu’est-ce que c’est ?], à moins que vous ne préfériez une immersion dans le 7e art proposée par Marina Duféal, pour explorer la relation entre la carte et le cinéma.
Bref, il y a de quoi faire, voir, entendre, pratiquer et cheminer sur ou avec des cartes à Montmorillon, et même en manger des cartes, à la carte (si si si, je vous l’assure, Christophe Terrier que j’avais pu rencontrer autour de cartes, non de tartes en cartes il y a quelques années, y propose des Modèles Numériques de Terrain [carte en relief et 3D] au chocolat, pour les plus gourmand.e.s).
Impossible de terminer ce petit billet sans mentionner que vous serez également pris en main par les étudiant.e.s de l’association Cassini des géographes poitevins qui vous apprendront à ne pas perdre le nord du langage cartographique, en réalisant une carte thématique – qui en sera forcément une vraie – avec magrit.
Les carnetiers de Néocarto vous souhaitent un bon festival à Montmorillon.
En savoir plus sur Le printemps des cartes
Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.











-
sur Revue de presse du 14 avril 2023
Publié: 14 April 2023, 2:20pm CEST
 Au même titre que l'eau, la revue de presse est précieuse, elle vous irrigue de l'actualité géomatique : les GéoDataDays, Rapid, du satellite,...
Au même titre que l'eau, la revue de presse est précieuse, elle vous irrigue de l'actualité géomatique : les GéoDataDays, Rapid, du satellite,...
-
sur QGIS : Calcul de surface
Publié: 11 April 2023, 7:10am CEST par Florian Delahaye
Vous voulez connaître la surface d’un objet géographique? Ou vous souhaitez automatiser l’ajout de l’aire d’un polygone dans la table attributaire? Le calcul de surface dans QGIS fait appel à la fonction area associée à la géométrie de l’objet géographique sélectionné. L’unité de la surface calculée par area dépend de… Continuer à lire →
L’article QGIS : Calcul de surface est apparu en premier sur GEOMATICK.
-
sur Vidéos, présentations et interviews des journées QGIS FR 2023
Publié: 5 April 2023, 10:20am CEST
 La Geotribu était bien présente aux journées QGIS FR 2023. En plus d'assurer l'animation de la journée de conférences, Florian et moi avons eu l'idée d'improviser des mini-interviews.
La Geotribu était bien présente aux journées QGIS FR 2023. En plus d'assurer l'animation de la journée de conférences, Florian et moi avons eu l'idée d'improviser des mini-interviews. -
sur Revue de presse du 31 mars 2023
Publié: 31 March 2023, 2:20pm CEST
 Une revue de presse de la géomatique très synthétique : marégraphe 3D, ressources des journées QGIS FR 2023, hypergéolocalisation et une spéléologue cartographe
Une revue de presse de la géomatique très synthétique : marégraphe 3D, ressources des journées QGIS FR 2023, hypergéolocalisation et une spéléologue cartographe -
sur Qualité des données : un voyage sur la plateforme humanitaire d'OpenStreetMap
Publié: 27 March 2023, 4:30pm CEST
 Offrir des données de qualité quand elles sont produites par des centaines de personnes de niveaux différents est un défi. Focus sur les méthodes en cartographie humanitaire avec HOT OSM.
Offrir des données de qualité quand elles sont produites par des centaines de personnes de niveaux différents est un défi. Focus sur les méthodes en cartographie humanitaire avec HOT OSM. -
sur Publication d'un site avec les icônes QGIS
Publié: 24 March 2023, 6:20pm CET
 Pour faciliter le travail d'intégration des icônes de QGIS par les développeurs de plugins, j'ai automatisé la génération et la mise à jour d'un site web : PyQGIS Icons Cheatsheet.
Pour faciliter le travail d'intégration des icônes de QGIS par les développeurs de plugins, j'ai automatisé la génération et la mise à jour d'un site web : PyQGIS Icons Cheatsheet.
-
sur CartONG sur le terrain dans le nord-est de la Syrie pour fournir un soutien SIG à Solidarités International
Publié: 23 March 2023, 9:30am CET par Yelena Yvoz
En février, CartONG a mené une mission de deux semaines en Syrie pour accompagner l'équipe de Solidarités International (SI) en matière de Systèmes d'Information Géographique. Une mission qui s'inscrit dans le cadre d'une consultance plus large que CartONG mène pour les équipes de terrain de SI en Syrie depuis septembre 2022. Plus d'informations dans cet article.
-
sur Reconstitution d'images aériennes historiques
Publié: 22 March 2023, 2:20pm CET
 Reconstitution d'images aériennes historiques
Reconstitution d'images aériennes historiques -
sur Revue de presse du 17 mars 2023
Publié: 17 March 2023, 2:20pm CET
 Geotribu lance un appel à volontaires pour continuer à vous parler de QGIS, de PostgreSQL, du LiDAR, d'OpenStreetMap,...
Geotribu lance un appel à volontaires pour continuer à vous parler de QGIS, de PostgreSQL, du LiDAR, d'OpenStreetMap,...
-
sur Visualiser la première loi de la géographie de W. Tobler ? L’auto-corrélation spatiale
Publié: 14 March 2023, 4:20pm CET par Françoise Bahoken
 Préambule : Ce travail s’inscrit dans le cadre des réflexions collectives menées dans le cadre du projet Tribute to Tobler – TTT. pour redévelopper les méthodes de Tobler dans des environnements contemporains de géovisualisation.
Préambule : Ce travail s’inscrit dans le cadre des réflexions collectives menées dans le cadre du projet Tribute to Tobler – TTT. pour redévelopper les méthodes de Tobler dans des environnements contemporains de géovisualisation.
Ce billet présente le Notebook Autocorrélation Spatiale [accéder] – English version : Spatial Autocorrelationréalisé par Laurent Jégou (Univ. de Toulouse 2/UMR LISST) et publié le 14 mars 2023.
“I invoke the first law of geography: everything is related to everything else, but near things are more related than distant things.”
« J’invoque la première loi de la géographie : tout interagit avec tout, mais les objets proches ont plus de relations que les objets éloignés. » Tobler, 1970.
Cette fameuse phrase est énoncée par Tobler en 1970, dans un article intitulé “A computer movie simulating urban growth in the Detroit region” publié dans la revue Economic geography, 46(sup1), 234-240 et disponible en ligne [PDF].
Laurent Jégou indique que Tobler a lancé cette idée un peu comme une boutade lors d’une réunion de l’International Geographical Union en 1969, puis a creusé cette question dans un article de 1970. L’époque étant aux premières réflexions sur l’utilisation d’un ordinateur en géographie, cette hypothèse est devenue une question de recherche fertile, qui a produit de nombreuses autres publications. Elle était déjà apparue chez R.A. Fisher en 1935, mais n’avait pas connu le contexte favorable de la géomatique pour se développer.
Cette “loi” est à l’origine des concepts de dépendance spatiale, de pondération des distances d’effets et d’autres analyses du rôle de l’espace et des distances. Nous allons nous intéresser ici à une famille d’indicateurs qui sont directement liés à la notion de relations spatialisées : l’autocorrélation spatiale.
***
L’autocorrélation spatiale est le degré selon lequel les objets proches sont plus reliés entre eux qu’avec des objets lointains. Ainsi, elle mesure la façon dont la valeur d’une variable est semblable pour des objets spatialement proches.
***
La mesure de l’autocorrélation spatiale implique donc de disposer d’une variable spatialisée et d’une métrique de distance, une façon de tenir compte de l’espacement géographique entre les objets.
Plusieurs recherches ont proposé des indicateurs pour mesurer cette autocorrélation spatiale. Laurent Jégou présente d’abord les indicateurs globaux qui correspondent à une valeur unique pour l’ensemble de la zone d’étude. Il s’agit de l’indice de contiguïté de Geary, ou “C de Geary” (Geary, 1954) et le I de Moran (1950). Le carnet présente ensuite les indicateurs locaux, tels que les versions locales du I de Moran et du C de Geary (Geary local et Getis&Ord) ; enfin ceux développés dans le champs de l’économétrie spatiale par Anselin (1995) sous le nom de LISA : Local Indicators of Spatial Association.
Le carnet propose de visualiser l’utilisation de ces indicateurs, en utilisant un jeu de données statistiques sur les logements, les ménages et des jeux de test sur les départements métropolitains français (Sources INSEE et IGN).


En fin de carnet, une carte interactive interactive est proposée représenter les différents indicateurs proposés, en jouant sur leurs paramètres : ci-après ceux qui ont permis de réaliser la carte précédente sur la part de résidences principales en 2019.

Accéder à la version interactive pour réaliser une carte
Réalisation : Laurent Jégou, 2023
Références :
– Laurent Jégou (2023) Autocorrélation Spatiale, Notebook Observable.
– Waldo R. Tobler (1970), A computer movie simulating urban growth in the Detroit region, Economic geography
– Anselin, L. (1995). Local indicators of spatial association—LISA. Geographical analysis, 27(2), 93-115. en ligne : [https:]]
– Getis, A., & Ord, J. K. (1992). The analysis of spatial association by use of distance statistics. Geographical analysis, 24(3), 189-206., en ligne : [https:]]Voir aussi :
TTT dans Neocarto
La collection TTT des travaux en français de et après Tobler : hal.archives-ouvertes.fr/TTT/
L’espace de travail collaboratif de TTT : ./tributetotobler/Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.
-
sur Journée d’études: “Numérisation 3D : le plan de Charleville, dit plan Dodet, 1724”, 6 avril 2023
Publié: 13 March 2023, 5:17pm CET par catherinevhofmann
Résultats du projet et perspectives Jeudi 6 avril 2023, 13 h 30 – 17 h 30 Archives nationales, Pierrefitte-sur-Seine, auditoriumLa journée sera également accessible en distanciel :
Réalisé en 1724 par l’architecte Nicolas Dodet pour Louis Henri de Condé, le plan dit Dodet est une représentation en trois dimensions de la ville de Charleville (Ardennes). Rappelant les plans reliefs construits à partir de la fin du XVIIe siècle, les élévations des façades des principaux bâtiments et des immeubles de la ville, dessinées sur papier fort, ont été collées perpendiculairement sur le réseau des rues et des places de sorte à former un plan « maquette ».
En 2021-2022, une campagne de numérisation et de captation 3D du plan Dodet a été entreprise dans le cadre d’un partenariat entre les Archives nationales et le Centre Roland Mousnier (CNRS, Sorbonne Université). Elle a permis de réaliser un « jumeau numérique » du plan destiné à constituer une base de données sociodémographiques de la population de Charleville, de sa création au début du XXe siècle.
 Programme de la journée
Programme de la journée
Introduction :
13 h 45 : Un projet R&D mené en partenariat avec le Centre Roland Mousnier,
CNRS – Sorbonne Université,
par Bruno Ricard, directeur des Archives nationales
CONTEXTE DU PROJET
14 h
À l’origine, ANR MPF (mobilités, populations, familles)
par François-Joseph Ruggiu, professeur à la Faculté des Lettres de Sorbonne Université, Centre Roland Mousnier (CNRS, Sorbonne Université) et Maison française d’Oxford (CNRS, MEAE et Université d’Oxford)
14 h 15
Le partenariat scientifique entre les Archives départementales des Ardennes et Sorbonne Université pour l’exploitation du fonds déposé des archives communales de Charleville
par Léo Davy, directeur des Archives départementales des Ardennes
14 h 30
Le plan Dodet comme source historique de la connaissance de Charleville
par Youri Carbonnier, professeur histoire moderne à l’Université d’Artois, Centre de Recherche et d’Etudes Histoire et Sociétés (CREHS), Arras
14H45
Le plan maquette de Charleville des Archives nationales : un objet original
par Nadine Gastaldi, Mission Cartes et Plans, Archives nationales
DE LA CONCEPTION A LA MODELISATION NUMERIQUE DU PLAN DODET
15 h
Conception et mise en place de la captation
par Sylvain Rassat, ingénieur d’études au CNRS ; Marc Paturange, responsable de l’atelier de photographie, et William Siméonin, photographe, Archives nationales
15 h 15
Lasergrammétrie
par Grégory Chaumet, ingénieur en numérisation et modélisation, Centre André Chastel, Sorbonne Université
15 h 30
La prise de vue
par William Siméonin
15 h 45
Les post traitements pour élaborer l’objet numérique
par Sylvain Rassat
16 h pause
PERSPECTIVES
16 h 15
Finalisation du modèle 3D
par Grégory Chaumet
16 h 30
Diffusion et médiation
par Carole Marquet-Morelle, directrice des musées de Charleville-Mézières
16 h 45
Diffusion et archivage
par Flore Hervé, responsable du département de l’image et du son, Archives nationales
Découvrir la vidéo de présentation de la modélisation du plan « Dodet » [https:]]
20230406_JE_Numerisation-3DTélécharger

-
sur Préparez la conférence QGIS FR avec QDT
Publié: 12 March 2023, 6:20pm CET
 Afin de suivre au mieux les rencontres 2023 des utilisateurs francophones de QGIS, je vous propose de déployer facilement un profil QGIS avec tout ce qu'il faut dedans pour suivre les ateliers et présentations. Bonne conférence !
Afin de suivre au mieux les rencontres 2023 des utilisateurs francophones de QGIS, je vous propose de déployer facilement un profil QGIS avec tout ce qu'il faut dedans pour suivre les ateliers et présentations. Bonne conférence !
-
sur La vraie carte du monde (Chéri Samba)
Publié: 9 March 2023, 11:34pm CET par Françoise Bahoken
Samba wa Mbimba N’zingo Nuni Masi Ndo Mbasi dit Chéri Samba est un monument de l’art contemporain africain au point où je ne sais plus si je chérie ce Samba parce qu’il en est un porte-drapeau, de la peinture noire d’aujourd’hui, ou bien parce que j’apprécie ses œuvres, certaines d’entre elles mobilisant des représentations cartographiques du monde. CQFD.
Chéri Samba émerge sur la scène artistique internationale en 1989, dans l’exposition Magiciens de la Terre qui avait présenté une centaine d’artistes contemporains « non occidentaux » à Paris : au Centre national d’art et de culture Georges-Pompidou et à la Grande Halle de la Villette, en même temps.
La vraie carte du monde est depuis lors très connue des férus de l’art contemporain africain. Acquise en 2012 par la Fondation Cartier pour l’art contemporain, cette œuvre a été notamment présentée en 2004, lors de l’exposition J’aime Chéri Samba ;, en 2011 lors de l’exposition Mémoires Vives et en 2015, lors de Beauté Congo 1926-2015 Congo Kitoko.

La Vraie Carte du Monde (200 x 300 x 3 cm) met en scène un auto-portrait de son auteur placé au milieu d’un planisphère évoquant celui de Peters, mais renversé et aplati dans son hémisphère sud. L’ensemble est présenté sur un fond sombre, bleu nuit qui semble traduire un environnement au froid intense, qui s’oppose à la chaleur de terres flamboyantes.
Le personnage apparaît comme incrusté dans la toile, au cœur même du planisphère. Il est vêtu d’un blouson aux motifs bleus (assortis au fond) qui évoquent un camouflage militaire ; il est surmonté d’un sweat-shirt zippé au ton blanc qui tranche à la fois avec le blouson et avec le col rayé de bandes rouge et noire.
A l’exception de quelques terres bleuies, situées aux confins de l’hémisphère sud, les pays du monde sont dans l’ensemble représentés dans un dégradé de tons chauds allant du rouge au blanc, jusqu’au jaune dans sa partie centrale.
La toile montre l’image d’un monde en feu en son cœur, qui pourrait logiquement évoquer l’urgence climatique contemporaine. Une urgence depuis laquelle émerge, tel un patriarche, un homme noir dénonçant en silence, avec un regard aussi profond que l’attitude et le sourire sont énigmatiques, le préoccupant état actuel du monde.
Chéri Samba indique qu’il a eu l’idée de faire cette carte après avoir consulté l’ouvrage Mes étoiles noires de Lilian Thuram, duquel il s’est senti proche et responsable.
C’est pourquoi il reprend un passage de l’ouvrage de Thuram qu’il mentionne telle une broderie, en fil blanc sur fond noir, au bas de la toile.

« Non, cette carte n’est pas à l’envers… Les cartes que nous utilisons généralement placent l’Europe en haut et au centre du monde. Elle paraît plus étendue que l’Amérique latine alors qu’en réalité elle est presque deux fois plus petite : l’Europe s’étend sur 9,7 millions de kilomètres carrés et l’Amérique latine sur 17,8 millions de kilomètres carrés. Cette présente carte questionne nos représentations. En effet, le géographe australien Stuart McArthur, en 1978, a placé son pays non plus en bas et excentré, mais en haut et au centre. Cette carte résulte aussi des travaux de l’Allemand Arno Peters, en 1974, qui a choisi de respecter les surfaces réelles de chaque continent. Il montre, par exemple, que l’Afrique avec ses 30 millions de kilomètres carrés, est deux fois plus grande que la Russie qui compte 17,1 millions de kilomètres carrés. Pourtant, sur les cartes traditionnelles, c’est le contraire… Placer l’Europe en haut est une astuce psychologique inventée par ceux qui croient être en haut, pour qu’à leur tour les autres pensent être en bas. C’est comme l’histoire de Christophe Colomb qui « découvre » l’Amérique, ou encore la classification des « races » au XIXe Siècle qui plaçait l’homme blanc en haut de l’échelle et les autres en bas. Sur les cartes traditionnelles, deux tiers de la surface sont consacrés au « Nord », un tiers au « Sud ». Pourtant, dans l’espace, il n’existe ni Sud ni Nord. Mettre le Nord en haut est une norme arbitraire, on pourrait tout aussi bien choisir l’inverse. Rien n’est neutre en termes de représentation. Lorsque le Sud finira de se voir en bas, ce sera la fin des idées reçues. Tout n’est qu’une question d’habitude. »
Cette longue citation accompagne ainsi la mise en scène par l’auteur de son auto-portrait pour souligner que c’est « L’Afrique qui fait que le Monde existe ».
L’auteur représente alors le continent noir telle qu’il le voit, selon ses dires. Il use pour cela d’une projection cartographique lui permettant de placer l’hémisphère sud au nord, et, de l’étendre de sorte qu’il occupe les trois quarts de la toile. Il balaie ainsi l’image usuelle du Monde renvoyée par la projection euro-centrée traditionnellement adoptée et qui permet à certains de se sentir injustement au-dessus des autres : « […] il y a des gens qui se croient supérieurs et qui se placent en haut alors que les autres sont placés en bas […]».
_____________
Visiter l’exposition J’aime Cheri Samba présentée en 2004 à Paris par la Fondation Cartier.
En français sous titré en allemand.Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.
-
sur Évolution de l'accès aux données Copernicus
Publié: 7 March 2023, 9:00am CET
 Évolution des portails d'accès aux données europénnes de la constellation satellites Sentinel en 2023
Évolution des portails d'accès aux données europénnes de la constellation satellites Sentinel en 2023 -
sur Revue de presse du 3 mars 2023
Publié: 3 March 2023, 2:20pm CET
 Fini la neige et le vin chaud, on reprend le fil de l'actualité : QGIS, ChatGPT, INPN, un hackathon, un forum de la topo, des médailles au CNRS, Ingrid Kretschmer,...
Fini la neige et le vin chaud, on reprend le fil de l'actualité : QGIS, ChatGPT, INPN, un hackathon, un forum de la topo, des médailles au CNRS, Ingrid Kretschmer,... -
sur Portails d'accès aux données Sentinel, 'the road so far'
Publié: 28 February 2023, 9:00am CET
Historique des portails d'accès aux données Sentinel en Europe et en France et description de leur grandes fonctionnalités -
sur Données Copernicus et Sentinel
Publié: 21 February 2023, 9:00am CET
Introduction et description des données d'observation de la terre produite dans le cadre du progamme européen Copernicus -
sur Revue de presse du 17 février 2023
Publié: 17 February 2023, 2:20pm CET
 De l'espace au terrain, la terre continue d'être cartographiée sous toutes les coutures.
De l'espace au terrain, la terre continue d'être cartographiée sous toutes les coutures.
-
sur Une datavisualisation comme outil d’aide à la décision
Publié: 14 February 2023, 4:15pm CET par Isabelle Coulomb
 (clic pour agrandir)
(clic pour agrandir)
Cet article a pour point de départ l’image ci-contre. Il s’agit d’une affiche au format A4, présentant un outil d’aide à la décision sur le dépistage mammographique du cancer du sein.
Cette affiche s’adresse aux femmes de 50 à 74 ans et montre la balance bénéfices-risques du dépistage du cancer du sein. Je dois avouer que ma première lecture de cette visualisation m’a plutôt ébranlée.
La plupart du temps, les représentations servent à illustrer des études, des rapports ou alimentent des tableaux de bord. En général, ce qu’elles montrent vient conforter ce que l’on savait d’une répartition ou confirmer une tendance. Il est plus rare qu’elles montrent quelque chose d’inattendu.
C’est pourtant le cas avec ce visuel qui met en parallèle les situations « avec » et « sans » dépistage. Cette représentation, nommée « icon array » en anglais, est celle utilisée pour des données concernant des risques. Elle se base sur un nombre de femmes, ici 2 000, plus facile à appréhender qu’un pourcentage, et met en vis à vis les 2 hypothèses « avec » ou « sans » dépistage.
Cette affiche reprend, sur un mode plus communiquant, un autre graphique publié par le Harding Center for Risk Literacy, à partir de données issues d’une revue Cochrane. L’organisation Cochrane est un organisme international indépendant dont la mission est de « favoriser la prise de décisions de santé éclairées par les données probantes, grâce à des revues systématiques pertinentes, accessibles et de bonne qualité et à d’autres synthèses de données de recherche. »
Cela signifie que le nombre de décès par cancer du sein parmi des populations de 1 000 femmes de 50 ans et plus passe de 5 sans dépistage à 4 avec dépistage, soit 1 décès évité. Cela signifie également que sur les 1 000 femmes dépistées, 5 feront l’objet d’un surdiagnostic, c’est-à-dire atteintes d’une tumeur non évolutive.
J’étais, comme certainement beaucoup de personnes, convaincue que la balance penchait largement en faveur du dépistage. Une tumeur décelée à un stade précoce semble plus facile à traiter, sans doute avec des traitements moins lourds. C’est l’intuition de base sur laquelle reposent toutes les campagnes organisées de dépistage du cancer, dans la plupart des pays occidentaux, depuis plus de 20 ans.
Or, avec le recul et les études médicales effectuées ces dernières années, on s’aperçoit que les choses ne sont pas aussi simples. Si la mortalité par cancer du sein a tendance à baisser au fil du temps, difficile toutefois de faire la part entre l’amélioration de l’efficacité des traitements et les effets du dépistage.
Il apparaît cependant que les avantages du dépistage ne compensent pas les risques, dont le principal est celui du surdiagnostic. Les microlésions détectées à la mammographie et traitées en tant que tumeurs cancéreuses n’auraient peut-être pas évolué. Sauf que, une fois repérées, il est impossible de faire comme si elles n’existaient pas.
Pour approfondir le sujet, je renvoie à la lecture d’informations publiées sur le site de l’association Cancer Rose, ou encore à celle du livre de la Dre Cécile Bour, intitulé « Mammo ou pas mammo ? », présenté de façon très pédagogique. Ce livre reprend en détail la construction de cette dataviz, présentée comme outil d’information des femmes face au choix de se faire dépister.
Ne pas confondre dépistage et préventionLe but des campagnes de dépistage est d’inciter les femmes dont l’âge est compris entre 50 et 75 ans à effectuer une mammographie tous les 2 ans. Le message utilise aussi le levier de la peur, puisque le cancer est toujours une maladie potentiellement mortelle. Il joue également sur l’idée qu’en se faisant dépister, on y gagnerait une protection : « ma mammo est OK, c’est bon, je suis tranquille pour 2 ans ! ». Or, il s’agit d’une idée erronée. Une tumeur peut apparaître et se développer entre 2 mammographies ; on parle alors de « cancer de l’intervalle ».
Une véritable prévention consisterait plutôt en mener des actions pour la lutte contre les addictions autorisées telles que le tabac et l’alcool, l’adoption d’une alimentation saine et équilibrée (et moins sucrée), l’habitude d’une activité physique régulière, les pratiques permettant de réduire l’excès de stress. Il y aurait sûrement beaucoup d’intéressantes dataviz à construire pour illustrer ces passionnants sujets.
Comment un message juste peut être invisibilisé
par une communication de masseDepuis les années 90, le mois d’octobre se pare de rose en faveur de la lutte contre le cancer du sein. D’une campagne de collecte de fonds pour la recherche, l’opération glisse vers la diffusion d’un message pour encourager le dépistage. Même parée d’intentions généreuses, cela s’apparente davantage à une opération de marketing.
Face au rouleau compresseur d’une opération disposant d’une forte et ancienne notoriété, difficile de faire entendre une parole différente. Face à un message simple, voire simpliste, il est compliqué d’en présenter un nouveau, plus difficile à expliquer. Là réside une difficulté en communication : ce n’est pas parce qu’un message est juste qu’il sera entendu, même avec de belles dataviz pour l’illustrer avec pédagogie.
Le curieux chemin qui a conduit cette dataviz sous mes yeuxComme le cancer du sein est un sujet qui me concerne personnellement, je me tiens régulièrement informée à son propos : livres, magazines, lettres d’information, sites internet… Pourtant, l’outil d’aide à la décision pour le dépistage du cancer du sein dont il est question ici m’est parvenu par un tout autre canal.
C’est Éric que je remercie de me l’avoir apporté. Il l’a lui-même découvert au cours de sa quête sans fin de nouvelles et intéressantes dataviz. S’intéressant à la question de la mesure du risque, il a lu l’ouvrage Calculated Risks, de Gerd Gigerenzer, dans lequel l’exemple du dépistage du cancer du sein est cité. Comme quoi, la statistique mène à tout.
L’article Une datavisualisation comme outil d’aide à la décision est apparu en premier sur Icem7.
-
sur Jointure spatiale dans QGIS
Publié: 8 February 2023, 2:37pm CET par Florian Delahaye
Vous cherchez à connaître le total ou la moyenne d’une variable par zone géographique? Vous voulez connaître par exemple la surface bâtie communale par maille de 500 x 500 m? Ce tutoriel SIG enseigne comment utiliser la jointure spatiale dans QGIS. Après avoir défini la jointure spatiale, trois modules du… Continuer à lire →
L’article Jointure spatiale dans QGIS est apparu en premier sur GEOMATICK.
-
sur Revue de presse du 3 février 2023
Publié: 3 February 2023, 2:20pm CET
 Le #MapFailbruaryChallenge est lancé, que ce soit en chanson ou en carte n’oubliez pas de partager vos carto-fails.
Le #MapFailbruaryChallenge est lancé, que ce soit en chanson ou en carte n’oubliez pas de partager vos carto-fails.
-
sur Cycle de conférence en histoire de la cartographie, BnF-site Richelieu, 9 février-11 mai 2023
Publié: 2 February 2023, 7:05pm CET par Catherine Hofmann
Mappemondes, atlas, globes et cartes à toutes les échelles exercent sur nous un véritable pouvoir de fascination. D’où vient cette emprise ? Pourquoi dresse-t-on des cartes depuis la nuit des temps ? A quels besoins et usages répondent-elles ? Qui en sont les auteurs ?
Voici quelques-unes des questions auxquelles le département des Cartes et plans de la Bibliothèque nationale de France se propose de répondre grâce à un cycle d’initiation à l’histoire de la cartographie, ouvert à tout public, qui couvrira deux mille ans d’histoire dans une approche tout à la fois diachronique et thématique.
Les quatre premières séances se dérouleront de février à mai 2023, les jeudis de 18h30 à 20h, et seront complétées par deux présentations de documents originaux ouvertes, sur inscription, aux participants du cycle.
Réservation recommandée sur affluences.com (rubrique BnF-Evénements culturels)
ProgrammeJeudi 9 février 2023 : La Cartographie de l’Antiquité au Moyen Age
Par Emmanuelle Vagnon, chargée de recherche, CNRS-LAMOP
Jeudi 9 mars 2023 : Cartographies du monde et projets cosmographiques à la Renaissance
Par Georges Tolias, directeur d’études, FNRS (Athènes) – EPHE (Paris)
Jeudi 13 avril 2023 : La cartographie marine : des portulans à Beautemps-Beaupré (XIIIe- XVIIIe siècle)
Par Catherine Hofmann, conservatrice générale, BnF, département des Cartes et plans
Jeudi 11 mai 2023 : Cartographie et art militaire (XVIIe- XIXe siècle)
Par Isabelle Warmoes, conservatrice du patrimoine, musée des Plans-reliefs


-
sur Voeux 2023 et bilan 2022
Publié: 30 January 2023, 10:20pm CET
 La tribu vous adresse ses meilleurs voeux à toutes et tous les visiteurs du géotipi. Petit retour sur 2022 pour attaquer au mieux 2023.
La tribu vous adresse ses meilleurs voeux à toutes et tous les visiteurs du géotipi. Petit retour sur 2022 pour attaquer au mieux 2023. -
sur Retour vers le futur du #30DayMapChallenge 2022
Publié: 28 January 2023, 4:00pm CET
 Rétrospective profane et gratuite sur les perles du 30DayMapChallenge de 2022
Rétrospective profane et gratuite sur les perles du 30DayMapChallenge de 2022 -
sur Revue de presse du 20 janvier 2023
Publié: 20 January 2023, 2:20pm CET
 Une revue de presse collaborative : GeoNetwork-UI, OpenStreetMap, iota2, des cyberattaques, des évènements,..
Une revue de presse collaborative : GeoNetwork-UI, OpenStreetMap, iota2, des cyberattaques, des évènements,.. -
sur Créer un index des voies dans QGIS
Publié: 13 January 2023, 2:20pm CET
 Créer un index des voies dans QGIS
Créer un index des voies dans QGIS
-
sur L’indépendance financière en Géomatique
Publié: 9 January 2023, 7:00am CET par Florian Delahaye
Pouvoir d’achat, inflation, réforme des allocations chômage, grèves pour de meilleures rémunérations et enfin la nouvelle réforme des retraites à venir, cette riche actualité amène à réfléchir sur ses propres moyens de subsistance à court, moyen et long terme et à l’indépendance financière en Géomatique. A l’heure où les plus… Continuer à lire →
L’article L’indépendance financière en Géomatique est apparu en premier sur GEOMATICK.
-
sur Revue de presse du 6 janvier 2023
Publié: 6 January 2023, 2:20pm CET
 Pour bien débuter 2023 : une cartographie du supporterisme, geOrchestra se structure, Openstreetmap lance une consultation, découvrez Nîmes à différentes époques, à vos agendas pour les GéoDataDays 2023,...
Pour bien débuter 2023 : une cartographie du supporterisme, geOrchestra se structure, Openstreetmap lance une consultation, découvrez Nîmes à différentes époques, à vos agendas pour les GéoDataDays 2023,... -
sur Installer QGIS sur Ubuntu avec apt
Publié: 5 January 2023, 10:20am CET
 Installer QGIS sur la distribution la plus répandue de l'écosystème Linux pose encore question, voire des problèmes. Un tutoriel sur la marche à suivre pour s'en rappeler quand le besoin se fait sentir.
Installer QGIS sur la distribution la plus répandue de l'écosystème Linux pose encore question, voire des problèmes. Un tutoriel sur la marche à suivre pour s'en rappeler quand le besoin se fait sentir.
-
sur Je viens de ou bien je vais à Yaoundé ?
Publié: 2 January 2023, 12:32pm CET par Françoise Bahoken
[UPDATE] 3 juin 2023.
L’ouvrage Villes enchantées coordonné par Raphaël PIERONI et Jean-François STASZAK a reçu le Prix du livre de géographie (étudiants, lycéens) 2023 !!! Un grand bravo !
Suis fière d’y avoir un peu participé avec la chanson dont il était question dans ce billet.Dans ce court billet, comme dans le texte auquel il fait référence, s’il n’y a point de cartographies, ni de cartes et ni même d’images, il est tout de même questions de migrations. Ces migrations diffèrent cependant de celles que j’ai maintenant l’habitude d’examiner, car elles sont locales et concernent le cœur de l’Afrique noire. Elles sont aussi décrites par le recours à une chanson.
Pour rédiger le texte Je vais à Yaoundé commentant la chanson éponyme, je suis donc sortie de ma zone de confort, pour mon plus grand plaisir tant l’exercice fut amusant et rafraichissant.
Nous vous invitons donc à contribuer à Villes enchantées. L’idée est simple : il s’agit de choisir une chanson qui évoque plus ou moins directement une ville, un lieu ou un espace urbain, et d’écrire un court texte qui en fait le commentaire, d’un point de vue géographique ou urbanistique, mais qui peut être très subjectif. Il peut s’agit d’un lieu réel ou fictif, spécifique ou générique.
En répondant favorablement et à chaud à ce message tambouriné de Raphaël Pieroni et Jean-François Staszak (Univ. de Genève) sur la liste des géographes francophones, je me suis retrouvée face au petit défi personnel d’écrire un texte sur une ville (ah bon ? ben oui) à partir d’une chanson (ah?!). Je fus immédiatement saisie d’une sorte de stress lié à un excessif engouement pour cette idée, qui m’avait pourtant plue d’emblée. Mais n’y avais-je pas répondu favorablement trop rapidement ?
Quelle ville allais-je donc choisir d’évoquer ? Et ensuite quelle chanson ? C’est pas comme si j’écoutais de la musique tous les jours…
Vu l’un des chefs d’orchestre que je ne connaissais que de nom, j’ai immédiatement pensé qu’il fallait que je choisisse une ville africaine. Dakar fut la première qui me vint à l’esprit, évoquée par l’artiste Youssou N’dour, dans From Village to Town – un album que j’aime beaucoup -. Si ce texte pouvait convenir dans un contexte d’écriture professionnel, je ne trouvais pas l’idée satisfaisante pour deux raisons principales. La première est que les travaux sur l’Afrique subsaharienne/noire portent quasi exclusivement sur la belle et majestueuse Afrique de l’ouest : le Sénégal, le Mali, le Niger (mais moins le Nigéria), la Mauritanie et ainsi de suite. L’Afrique centrale m’apparaît (depuis quelques temps déjà) comme le parent pauvre de ces travaux sans que je sache vraiment pourquoi (enfin, je peux le deviner, mais je n’en suis pas spécialiste). La seconde raison est que je me suis étrangement sentie comme obligée d’écrire quelque chose sur Yaoundé, alors que j’avais initialement pensé à Dakar, et que, maintenant, je pensais aussi à Lagos. Ce choix de Yaoundé m’a questionné. pourquoi Celui-là ? C’est bizarre comme je m’assigne ici, moi-même, toute seule, une obligation de choisir cette ville, dont je savais qu’elle me renverrait immédiatement à une identité d’appartenance quasi exclusive à cette sous-région d’Afrique noire, alors que ce n’est pas le cas. Est-ce que les autres auteurs et autrices de cet ouvrage allaient choisir leur ville à chanter/enchantée en fonction d’un sentiment d’appartenance ? Pourquoi je fais cela ? Tout de suite, à l’heure ou j’écris ces lignes, je ne me sens même pas, ou même plus de Yaoundé d’où je suis partie il y à plus de trente ans, après y avoir vécut quelques treize années de ma vie. Bref.
Ayant par ailleurs la conviction qu’il n’allait pas y avoir beaucoup de textes sur des villes africaines, j’ai donc réfléchi à une chanson sur Yaoundé. Laquelle choisir ? Comme cette chanson devait être “populaire” et qu’il fallait que je puisse écrire dessus, mon esprit s’est rapidement arrêté sur Je vais à Yaoundé de André-Marie Talla. Mais était-elle assez populaire pour le public européen occidental auquel l’ouvrage m’apparaissait se destiner ? Pour moi, en tous cas, elle l’était et c’est gaiment que je soumettais peu après l’appel, ma proposition de ville enchantée.

La réponse ne se fit pas attendre.

Les coordinateurs de l’ouvrage ayant accueilli favorablement mon idée, je me lançais dans la soirée qui suivi à l’écriture de ce court texte d’environ 700 mots, portant sur les mobilités des espaces ruraux vers les centres espaces urbains, dans le Cameroun des années 1975/1980.
Extraits

Lire la suite dans… Villes enchantées. Chansons et imaginaires urbains, pages 108-109.
ou le manuscrit auteur déposé dans HAL
Référence : Françoise Bahoken (2022), Je vais à Yaoundé, André-Marie Tala (1975), in : Raphaël Pieroni et Jean-François Staszak (coord.), Villes enchantées. Chansons et imaginaires urbains, Georg Editor, Seine-Bourg (Suisse), pp. 108-109.
Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.
-
sur Parquet devrait remplacer le format CSV
Publié: 29 December 2022, 12:19pm CET par Éric Mauvière
Parquet est un format ouvert de stockage de jeux de données. Créé en 2013 par Cloudera et Twitter, longtemps réservé aux pros du big data, il a beaucoup gagné en popularité ces derniers mois. Bien plus compact, super-rapide à lire, compris par davantage d’outils, Parquet est devenu une alternative crédible à l’omniprésent CSV.
C’est un standard ouvert, comme le CSV, qui prend les données telles qu’elles sont collectées, en simples tables de lignes et de colonnes. Si CSV empile des lignes, Parquet raisonne d’abord en colonne : il les distingue, les catégorise selon leur type, documente leurs caractéristiques fines. Cela rend les données plus faciles à manipuler, plus rapides à parcourir. Et comme elles sont intelligemment compressées, elles prennent bien moins de place de stockage, jusqu’à 10 fois moins qu’un fichier texte délimité !

Parquet sait aussi organiser l’information en groupes de milliers de lignes, voire en fichiers distincts, partitionnés, ce qui accélère les requêtes en les dirigeant plus vite vers les seules données pertinentes pour le traitement désiré. La richesse de son dictionnaire de métadonnées est d’une efficacité redoutable, au niveau de celles des index d’une base de données.
À rebours du paradigme classique de R ou Python, il n’est plus nécessaire de charger toute une table en mémoire pour l’analyser, les données sont lues uniquement là où elles sont utiles, sans aucune conversion ou recopie (c’est le principe de localité).
Des avantages incontestables par rapport à CSVRésumons les deux points forts de Parquet par rapport au format CSV :
- un fichier Parquet a la taille d’un CSV compressé, il prend jusqu’à dix fois moins de place de stockage.
- Il est parcouru, décodé et traité bien plus rapidement par les moteurs de requêtes analytiques.
Dernier avantage : Parquet sait modéliser des types complexes, une colonne comprenant par exemple une structure hiérarchique, un contenu JSON ou le champ géométrique de nos couches SIG (cf. plus loin le projet GeoParquet).
Encore faut-il savoir créer et lire le format ParquetJusqu’à il y a peu, seuls des outils très spécialisés permettaient de générer ou lire le format Parquet. En quelques mois, la donne a radicalement changé. Le vaste projet Apache Arrow, porté à partir de 2016 par Wes McKinney (le créateur de la librairie Python/Pandas) et des dizaines de développeurs majeurs du monde de la datascience, est sans nul doute à l’origine de cette accélération.
La plupart des outils analytiques de la datascience, jusqu’à JavaScript dans le navigateur, lisent les formats Parquet et son jeune cousin Arrow en s’appuyant sur un noyau commun de routines C++ développées dans le cadre du projet Apache Arrow.
Enfin, le formidable moteur portable DuckDB met à la portée de n’importe quel PC les performances d’un moteur de base de données traditionnel sur serveur. DuckDB est désormais, avec des données Parquet, plus rapide qu’une base PostgreSQL pour les requêtes d’analyse.
R offre un environnement efficace pour travailler avec ParquetVotre tableur favori ne propose pas encore de fonction “Enregistrer sous .parquet”, mais cela ne saurait tarder. Pour aller au plus vite, ce classeur Observable en ligne vous permet de le faire : il vous invite à téléverser un CSV, le type des colonnes tel que deviné vous est présenté, vous pouvez télécharger la version .parquet de votre fichier et déjà admirer la belle réduction de taille.
Pour visualiser le contenu d’un fichier Parquet, à l’opposé, Tad est un utilitaire libre multiplateforme efficace et véloce ; il autorise même les filtrages et les agrégations. À vous de jouer !
Les convertisseurs en ligne CSV => Parquet sont toutefois limités : à l’évidence par la taille des CSV que vous pouvez téléverser (quelques dizaines de Mo), et parfois parce qu’ils “typent” incorrectement certaines colonnes : vos codes département ou commune se retrouveront amputés du 0 initial, ou pire, une erreur surviendra parce qu’une colonne de codes département sera intuitée numérique au vu des premières lignes, mais produira une erreur à l’apparition des 2A ou 2B des départements Corse.
Pour l’heure, R offre un environnement très efficace pour créer des fichiers Parquet (Python aussi, sans doute). La librairie R arrow fait l’essentiel du travail, avec vélocité et robustesse.
Le fichier des migrations résidentielles : un CSV de 2 Go qui devient facile à manipuler converti en ParquetNous allons explorer les avantages du format Parquet à partir d’une table respectable de 20 millions de lignes et 33 colonnes. L’Insee met à disposition la base des migrations résidentielles, issue du recensement de la population, sous deux formats, CSV zippé et .dbf. Le format dbf (DBASE) me rappelle de vieux souvenirs, je ne sais pas qui l’utilise encore… J’espère convaincre mes amis de l’Insee de remplacer un jour ces .dbf par des .parquet !
Chaque résident se trouve comptabilisé dans ce tableau qui résulte d’une ventilation selon une trentaine de caractéristiques de la personne ou de son ménage : commune de résidence et résidence un an avant, CSP, tranche d’âge, type de logement, etc.
Une ligne correspond à un croisement de caractéristiques, elle peut regrouper plusieurs personnes. La colonne IPONDI en donne le nombre : comme il s’agit d’une estimation, IPONDI est en pratique une valeur décimale. C’est la seule colonne numérique, toutes les autres sont des catégories qualitatives d’une nomenclature : code commune, code CSP, etc.
Voici un aperçu de ce CSV, on reconnait le délimiteur français (;), et des valeurs qui peuvent commencer par un 0. Ce CSV n’est pas si simple à afficher, car peu de programmes peuvent ouvrir un fichier texte de 2 Go. J’utilise EmEditor dont la version gratuite fait cela en un clin d’œil.
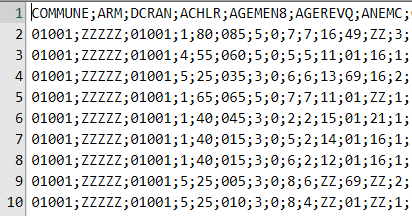
J’ai rencontré plusieurs personnes s’étant bien pris la tête avec un tel fichier. Dans R ou Python, il faut le charger en entier en mémoire, dont l’occupation peut atteindre en pointe les 10 Go : c’est difficilement supportable, et inenvisageable quand l’environnement de travail R est sur serveur et multi-utilisateurs. On s’en sort habituellement en chargeant les données dans une base comme PostgreSQL, ce qui demande pas mal d’écriture, de temps de chargement et oblige à dupliquer les données.
Dans R, les quelques lignes suivantes assurent la conversion vers Parquet, une fois pour toutes, en moins d’une minute.
library(tidyverse) library(arrow) library(data.table) write_parquet( fread("data/FD_MIGCOM_2019.csv") |> mutate(across(-IPONDI, as.factor)), "data/FD_MIGCOM_2019.parquet" ) # data.table::fread est très efficace pour charger des gros CSV (50 s ici) # IPONDI est la seule col. numérique, les autres seront typées factors plutôt que string # write_parquet génére l'équivalent Parquet du CSV en entréeLa version Parquet ne fait plus que 200 Mo, dix fois moins que le CSV de départ. Et elle est directement utilisable avec peu de mémoire, y compris en contexte multi-utilisateurs, aussi facilement qu’une table dans une base de données. En raison de sa nature de standard ouvert, elle a l’avantage supplémentaire de pouvoir être lue par un grand nombre d’outils analytiques.
Les colonnes caractères de nomenclature doivent être typées avec soinAttardons-nous sur le typage des colonnes qualitatives, car c’est un important facteur d’optimisation des fichiers Parquet. Une colonne de type caractère comprenant les codes souvent répétés d’une nomenclature peut être décrite de façon optimisée à partir du dictionnaire de ses valeurs distinctes, et d’un simple n° d’indice, un entier.
Ces colonnes qualitatives “dictionary-encoded” sont bien plus rapides à lire que les colonnes caractères classiques. Pour l’heure, la plupart des outils automatiques de conversion vers Parquet négligent cette structure optimisée. Dans R, dès lors que les “strings” sont convertis en “factors”, qui reposent sur la même idée de dictionnaire, on pourra générer un Parquet bien optimisé. En pratique, les requêtes deviennent deux fois plus rapides encore, cela vaut donc le coup d’y penser !
Clic droit sur FD_MIGCOM_2019.parquet dans mon explorateur de fichiers et Tad m’affiche en deux secondes le contenu de cette table Parquet. Chaque colonne apparait bien typée, et mes codes géographiques n’ont pas été altérés :
 Avec Tad, je peux trier, filtrer sur plusieurs colonnes, et même agréger !
Comprenons comment optimiser une requête en évitant les chargements ou recopies inutiles
Avec Tad, je peux trier, filtrer sur plusieurs colonnes, et même agréger !
Comprenons comment optimiser une requête en évitant les chargements ou recopies inutiles
Revenons dans R avec une première requête simple, compter les habitants de Toulouse qui ont changé de logement en un an :
read_parquet("data/FD_MIGCOM_2019.parquet") |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) # 93151 # 7 sSept secondes peut sembler un bon résultat pour compter ces 93 151 personnes, mais on peut réduire le temps de calcul à une seconde avec cette variante :
read_parquet("data/FD_MIGCOM_2019.parquet", col_select = c(COMMUNE, IRAN, IPONDI)) |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) # 93151 # 1 sCe qui est encore excessif, car la librairie duckdb peut nous faire descendre à 150 ms :
library(duckdb) con <- dbConnect(duckdb::duckdb()) dbGetQuery(con, "SELECT sum(IPONDI) FROM 'data/FD_MIGCOM_2019.parquet' WHERE COMMUNE = '31555' AND IRAN <> '1'") # 93151 # 150 msComment comprendre que l’on arrive à ces performances assez hallucinantes, et l’impact de ces variantes d’écriture sur la charge d’exécution ?
Soyez vigilants avec les pipelines d'instructions chaînéesDans R et dplyr, le chainage des opérations avec le pipe
|>(ou%>%) conduit à séparer les traitements. Ainsi, dans l’écriture suivante;read_parquet()charge en mémoire toute la table avant de la filtrer drastiquement.read_parquet("data/FD_MIGCOM_2019.parquet") |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) # 93151 # 7 sParquet, on l’a vu, encode séparément chaque colonne, si bien qu’il est très rapide de cibler les seules colonnes utiles pour la suite d’un traitement. La restriction suivante apportée au
read_parquet()par uncol_selectdiminue considérablement la charge mémoire, expliquant la réduction du temps d’exécution d’un facteur 7 :read_parquet("data/FD_MIGCOM_2019.parquet", col_select = c(COMMUNE, IRAN, IPONDI)) |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) # 93151 # 1 sPour autant, on n’évite pas la recopie d’une partie du contenu de FD_MIGCOM_2019.parquet (trois colonnes) vers la mémoire de travail de R.
La variante DuckDB est bien plus optimisée : le fichier FD_MIGCOM_2019.parquet est lu et traité en place sans (presque) aucune recopie des données en mémoire :
library(duckdb) con <- dbConnect(duckdb::duckdb()) dbGetQuery(con, "SELECT sum(IPONDI) FROM 'data/FD_MIGCOM_2019.parquet' WHERE COMMUNE = '31555' AND IRAN <> '1'") # 93151 # 150 msCette notion de “zéro-copie” est fondamentale : elle est au cœur du projet Arrow et avant lui de la conception du format Parquet.
Les requêtes compilées sont plus efficacesUne requête considérée globalement est plus facilement optimisable par un moteur intelligent, qui va chercher le meilleur plan d’exécution. C’est comme cela que les moteurs de bases de données relationnelles fonctionnent, prenant en considération par exemple les clés et les index ajoutés aux tables.
Le chainage proposé par dplyr (ou Pandas dans Python) est toutefois plus agréable à écrire ou à relire qu’une requête SQL. Comment réunir le meilleur des deux mondes ?
C’est possible dans R avec
open_dataset()qui plutôt que lire directement le contenu du fichier, se contente d’ouvrir une connexion, prélude à l’écriture d’une chaine d’instructions qui ne sera compilée et exécutée que par l’ordre finalcollect():open_dataset("data/FD_MIGCOM_2019.parquet") |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) |> collect() # 93151 # 1 sCette écriture conduit le moteur (ici arrow et non plus dplyr) à comprendre qu’il n’a pas besoin de lire toutes les colonnes de la table Parquet. Elle n’est pas tout à fait aussi rapide que le SQL direct dans DuckDB, mais elle s’en approche.
Partitionnez pour simplifier le stockage et les mises à jouropen_dataset()a un autre mérite, celui de permettre d’ouvrir une connexion vers un ensemble partitionné de fichiers physiques décrivant la même table de données.La base des migrations fait ici 200 Mo, c’est relativement faible. On considère qu’un fichier Parquet peut raisonnablement aller jusqu’à 2 Go. Au-delà, il y a tout intérêt à construire un dataset partitionné.
La base des courses des taxis de New-York représente 40 Go de données couvrant plusieurs années, et elle se décompose en une partition de dizaines de fichiers Parquet, découpés par année et par mois. Ce découpage est logique, il permet par exemple de ne mettre à jour que les nouveaux mois de données fraichement disponibles. La clé de partitionnement correspond également à une clé de filtrage assez naturelle.
R et Arrow arrivent à requêter l’ensemble de ce dataset en moins d’une seconde (DuckDB fait cinq à dix fois mieux).
Voici comment constituer un dataset Parquet partitionné à partir de la base plus modeste des migrations résidentielles, avec ici un seul champ de partitionnement :
write_dataset(fread("data/FD_MIGCOM_2019.csv") |> mutate(across(-IPONDI, as.character)), path = "data/migres", partitioning = c('IRAN'))Cela crée une petite arborescence de fichiers Parquet :
Nous pouvons désormais comparer les performances de la même requête, sur l’ensemble partitionné en dix fichiers, ou sur le fichier Parquet unique.
La partition accélère naturellement nettement l’exécution (200 ms contre 1 s) car le filtrage suivant sur IRAN correspond à la clé de partitionnement, il n’est donc pas besoin d’ouvrir le second fichier de la partition :
open_dataset("data/migres", partitioning = c('IRAN')) |> filter(COMMUNE == '31555' & IRAN != 1) |> summarise(i = sum(IPONDI)) |> collect() # 93151 # 200 ms open_dataset("data/FD_MIGCOM_2019.parquet") |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) |> collect() # 93151 # 1 sParquet et DuckDB surpassent les bases de données relationnelles classiquesJe me suis intéressé à cette base de migrations pour conseiller un client peinant à la traiter dans R. Travaillant dans une agence d’urbanisme, il voulait simplement extraire les données pertinentes pour sa métropole. Dans le cas de Toulouse, cela reviendrait à extraire de la base les personnes résidant dans l’EPCI de Toulouse-métropole, ou y ayant résidé l’année précédente.
Je m’appuie pour ce faire sur une table annexe listant les communes de Toulouse Métropole. Il s’agit ensuite d’opérer une double jointure avec la base des migrations, utilisant successivement COMMUNE (code de la commune de résidence) et DCRAN (code de la commune de résidence antérieure).
Grâce à DuckDB, cela s’exécute en 2 secondes, je n’ai même pas eu à me préoccuper d’indexer la table principale. Dans PostgreSQL 15, même après avoir indexé COMMUNE et DCRAN, la requête prend plus de 20 secondes. Ite missa est. DuckDB et Parquet écrasent tout !
library(duckdb) con = dbConnect(duckdb::duckdb()) dbSendQuery(con, "CREATE TABLE COM_EPCI_TOULOUSE AS SELECT * FROM read_csv('data/communes_epci_tls.csv', AUTO_DETECT = TRUE, ALL_VARCHAR = TRUE)") dbGetQuery(con, "SELECT M.* FROM 'data/FD_MIGCOM_2019.parquet' as M LEFT JOIN COM_EPCI_TOULOUSE as C1 ON M.COMMUNE = C1.CODGEO LEFT JOIN COM_EPCI_TOULOUSE as C2 ON M.DCRAN = C2.CODGEO WHERE C1.CODGEO IS NOT NULL OR C2.CODGEO IS NOT NULL ") |> summarise(i = sum(IPONDI)) # 282961 # 2,5 sParquet et Arrow sont deux technologies complémentairesCloudera est l’une des entreprises conceptrices originelles de Parquet, en 2013, avec Twitter et Google. Quand Wes McKinney la rejoint en 2014, lui qui a créé la célèbre librairie Pandas pour Python (équivalent de R/Tidyverse), il comprend vite qu’il y a là un format d’avenir : un modèle de “dataframe” universel, qui peut encore s’optimiser.
Wes rêve d’un format de données qui soit quasi-identique dans sa représentation physique (stockée ou streamée via les réseaux) à sa représentation en mémoire, qui éviterait toutes ces coûteuses opérations de conversion des différents formats textes ou “propriétaires” vers les bits que manipulent les processeurs. Le pire exemple est naturellement celui du CSV, où les nombres sont d’abord stockés comme des chaines de caractères, qu’il faut décoder (“désérialiser”). Avec ce format idéal auquel le projet Apache Arrow donne forme à partir de 2016, les processeurs pourront déplacer des pointeurs vers des sections de bits de données, sans jamais les recopier.
Si Parquet, format binaire “streamable” (découpable en petits morceaux autonomes) orienté colonnes, s’approche de cet idéal, il impose tout de même une forme de décodage avant d’être porté en mémoire, par exemple parce qu’il compresse les données. A contrario, un fichier physique constitué à partir d’un format Arrow prend beaucoup plus de place car il n’est pas compressé.
Parquet a le mérite d’exister et d’être déjà beaucoup utilisé, il est optimisé pour l’archivage et le partitionnement, Arrow pour les traitements, les accès concurrents et les systèmes très distribués.
Wes McKinney a su motiver de très bons programmeurs au sein du projet Apache Arrow pour bâtir à la fois une spécification de format et des librairies partagées, dont une interface très performante entre Parquet et Arrow. Nous voyons – nous humains – des fichiers Parquets, les moteurs analytiques et les réseaux travaillent à partir de leur conversion en structures Arrow.
Dans le même ordre d’idée, plutôt que chacun dans son coin implémente un module de lecture de fichiers CSV, l’effort est désormais centralisé au sein du projet Arrow. R, Python, Rust, Julia, Java et bien d’autres réutilisent les librairies C++ du projet Arrow. Il en existe même un portage pour JavaScript en Web-Assembly : nos navigateurs savent désormais lire des fichiers Arrow ou Parquet (cf. les librairies Arrow.js, Arquero ou duckdb-wasm).
Ainsi, à rebours de la logique intégrée des systèmes de bases de données, il est aujourd’hui possible de rendre indépendants – sans sacrifier la performance – les sources de données et les moteurs analytiques, les uns et les autres pouvant se déployer dans n’importe quel environnement, portable ou distribué.
GéoParquet pourrait renouveler le stockage des données géographiques tabulairesLe cahier des charges de Parquet prévoyait la possibilité de décrire des colonnes stockant des structures complexes, imbriquées, organisées en listes. Parquet est donc tout à fait capable de modéliser des données spatiales, qui complètent typiquement une table de données classique par un champ géométrique.
À la clé, tous les avantages déjà évoqués : stockage réduit, données volumineuses possiblement partitionables, traitements accélérés, nouveau standard plus facilement acceptable par l’industrie, réduisant l’écart entre l’exotisme des formats SIG et les formats de données statistiques plus traditionnels.
Géoparquet permettra de gérer plusieurs systèmes de référence géographique dans le même dataset, voire plusieurs colonnes de géométrie.
Le projet GeoParquet est déjà bien avancé et le format est d’ores et déjà utilisable. Vous pouvez générer des fichiers GeoParquet avec R ou Python, et les ouvrir, grâce à l’intégration GeoParquet dans GDAL, dans la dernière version de QGIS (3.28).
Voici un exemple à partir d’un fichier historique des cultures en Ariège, obtenu au format geopackage. La conversion en GeoParquet aboutit à un fichier deux fois plus petit, de contenu identique. L’équivalent au format Esri shape produirait un ensemble de fichiers de plus de 500 Mo, de taille quasiment 10 fois supérieure.
Les trois versions s’ouvrent dans R ou dans QGIS avec la même rapidité.
library(sf) library(sfarrow) # [https:] # le gpkg pèse 110 Mo # l'équivalent esri shape 540 Mo gpkg_file = "data/filiation_20_07.gpkg" # liste des couches de ce geopackage : 1 seule couche st_layers(gpkg_file) read_sf(gpkg_file) |> st_write_parquet("data/filiation_20_07_d09.parquet") # le geoParquet généré pèse 60 Mo
 Un fond de carte GeoParquet ouvert dans QGIS
Pour résumer
Un fond de carte GeoParquet ouvert dans QGIS
Pour résumer
Parquet est un standard ouvert particulièrement bien adapté pour stocker des données volumineuses, et traiter des fichiers avec beaucoup de colonnes, ou comprenant des nomenclatures.
Sa structure astucieusement croisée et documentée en colonnes et en groupes de lignes exploite à merveille les capacités des processeurs modernes : parallélisation, vectorisation, mise en cache. Elle est aussi compatible avec une organisation partitionnée ou une distribution “streamée” des données.
Comme Arrow, Parquet épouse le principe de localité : rapprocher les process des données, les lire là où elles se trouvent, plutôt que recopier les données dans des espaces de traitement spécialisés. C’est l’objectif du “zéro-copie” : il permet de travailler avec des données plus volumineuses que la mémoire disponible et de dépasser ce goulet d’étranglement classique, bien connu des praticiens de R ou Python.
GéoParquet est en passe de résoudre le casse-tête de l’hétérogénéité des formats SIG, de leur apporter de nouveaux gains de performance et de substantielles économies de stockage.
Un des formats majeurs de la boite à outils Arrow, Parquet est la face émergée d’un nouvel écosystème décloisonnant les données et les process qui les traitent, complémentaire des bases de données relationnelles traditionnelles.
Si la plupart des outils d’analyse de données lisent désormais les fichiers Parquet, le nouveau moteur portable DuckDB est tout spécialement optimisé pour en tirer le meilleur parti. Il démontre des performances extraordinaires, qui ne cessent de croitre, tirées par la créativité et l’enthousiasme d’une belle communauté de développeurs open-source.
Pour aller plus loinPrésentation du format
- Apache Parquet pour le stockage de données volumineuses
- What is the Parquet File Format?
- What Is Apache Parquet?
- Parquet file format
Différences Arrow / Parquet
- Difference between Apache parquet and arrow
- [https:]]
- The Columnar Roadmap: Apache Parquet and Apache Arrow
Pour jouer avec Parquet
- Tad: A better way to view & analyze data
- Online, Privacy-Focused Parquet File Viewer
- Dbeaver: Universal Database Tool
- How to set up DBeaver SQL IDE for DuckDB
- DuckDB redonne une belle jeunesse au langage SQL
- Package R Parquetize
Le projet Arrow
- Apache Arrow: High-Performance Columnar Data Framework (Wes McKinney)
- Apache Arrow: a cross-language development platform for in-memory analytics
L’article Parquet devrait remplacer le format CSV est apparu en premier sur Icem7.
-
sur Geomatys labellisé CNES PME
Publié: 20 December 2022, 2:58pm CET par user

Depuis juin 2022, Geomatys est titulaire du label CNES PME pour une durée de trois ans, en récompense de son expertise en “standardisation de système d’information géospatiaux interopérables”. Attribué depuis 2020, et comme son nom l’indique, ce label est attribué aux PME innovantes et crédibles agissant dans le domaine du spatial.
The post Geomatys labellisé CNES PME first appeared on Geomatys.
-
sur Photos sur une carte dans QGIS
Publié: 19 December 2022, 11:19am CET par Florian Delahaye
Vous disposez de relevés terrain avec de magnifiques clichés. Vous voulez afficher ces photos sur une carte dans QGIS. Alors, ce tutoriel SIG vous montre trois manières de géolocaliser des photos sur le logiciel. Les photos sont acquises par drone dans le sud du Morbihan entre Lorient et Vannes pour… Continuer à lire →
L’article Photos sur une carte dans QGIS est apparu en premier sur GEOMATICK.
-
sur Revue de presse du 16 décembre 2022
Publié: 16 December 2022, 2:20pm CET
 Dernière revue de presse de 2022 : PostgreSQL et PostGIS ont la cote, Shapely s'offre une deuxième jeunesse, Overture sort du chapeau,...
Dernière revue de presse de 2022 : PostgreSQL et PostGIS ont la cote, Shapely s'offre une deuxième jeunesse, Overture sort du chapeau,... -
sur Contribution Mapillary et retour d'expérience
Publié: 9 December 2022, 2:20pm CET
 Contribution Mapillary et retour d'expérience
Contribution Mapillary et retour d'expérience -
sur Revue de presse du 2 décembre 2022
Publié: 2 December 2022, 2:20pm CET
 GeoRDP du 2 décembre : la revue de presse de la géomatique qui ressemble à un calendrier de l'avent qu'on ouvrirait toutes les 2 semaines tout le long de l'année ! Bonne dégustation !
GeoRDP du 2 décembre : la revue de presse de la géomatique qui ressemble à un calendrier de l'avent qu'on ouvrirait toutes les 2 semaines tout le long de l'année ! Bonne dégustation ! -
sur Revue de presse du 18 novembre 2022
Publié: 18 November 2022, 2:20pm CET
 L’équipe de GeoTribu accompagnée de contributeurs bénévoles achalandent les rayons de la GeoRDP en actualités toutes fraîches : OSRM, IGN, Cartobio, télédétection, PCRS, ...
L’équipe de GeoTribu accompagnée de contributeurs bénévoles achalandent les rayons de la GeoRDP en actualités toutes fraîches : OSRM, IGN, Cartobio, télédétection, PCRS, ... -
sur Création de zooms circulaires et autres astuces amusantes de mise en page dans QGIS
Publié: 17 November 2022, 1:30pm CET
 Paramétrer la mise en page de QGIS pour afficher des zooms circulaires. Traduction d'un article de North Road.
Paramétrer la mise en page de QGIS pour afficher des zooms circulaires. Traduction d'un article de North Road. -
sur Revue de presse du 4 novembre 2022
Publié: 4 November 2022, 2:20pm CET
 GeoRDP du 4 novembre 2022 : QGIS, Topohelper, Clipper 2, JOSM, Lego, LASTIG, des évènements et des rencontres à venir, de la lecture.
GeoRDP du 4 novembre 2022 : QGIS, Topohelper, Clipper 2, JOSM, Lego, LASTIG, des évènements et des rencontres à venir, de la lecture.
-
sur across() est plus puissant et flexible qu’il n’y parait
Publié: 3 November 2022, 5:44pm CET par Éric Mauvière
La librairie R dplyr permet de manipuler des tables de données par un élégant chainage d’instructions simples : select, group_by, summarise, mutate… à la manière du langage de requête SQL.
dplyr est le module central de l’univers tidyverse, une collection cohérente de librairies spécialisées et intuitives, ensemble que l’on a souvent présenté comme le symbole du renouveau de R.
Arrivée à maturité il y a deux ans avec sa version 1.0, dplyr accueillait en fanfare l’intriguant élément “across()”, destiné à remplacer plus d’une dizaine de fonctions préexistantes. across() est ainsi devenu l’emblème de la version toute neuve de la librairie emblématique du “R moderne” !
Je l’ai constaté, across() est encore insuffisamment compris et utilisé, tant il implique une façon de penser différente de nos habitudes d’écriture. Cet article vous présente, au travers de 7 façons de le mettre en œuvre, sa logique assez novatrice. Il s’adresse en priorité à des lecteurs ayant déjà une connaissance de R et dplyr.

across() permet de choisir un groupe de colonnes dans une table, et de leur appliquer un traitement systématique, voici sa syntaxe générique :

Je vais présenter l’usage d’across() avec la base Gaspar, qui décrit les risques naturels et industriels auxquels chaque commune française est exposée. J’en ai préparé un extrait décrivant sept risques pour la métropole. Chaque colonne indicatrice de risque vaut 0 ou 1 (présence).
library(tidyverse) tb_risques = read_delim(str_c(" [https:] "20221027-104756/tb-risques2020.csv"), col_types = c('reg' = 'c')) # A tibble: 34,839 x 11 com dep reg lib_reg risq_inond risq_seisme risq_nucleaire risq_barrage risq_industriel risq_feux risq_terrain <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> 1 01001 01 84 Auvergne-Rhône-Alpes 1 0 0 0 0 0 0 2 01002 01 84 Auvergne-Rhône-Alpes 0 1 0 0 0 0 1 3 01004 01 84 Auvergne-Rhône-Alpes 1 1 0 0 0 0 1 4 01005 01 84 Auvergne-Rhône-Alpes 0 0 0 0 0 0 0 5 01006 01 84 Auvergne-Rhône-Alpes 0 1 0 0 0 0 0 6 01007 01 84 Auvergne-Rhône-Alpes 1 1 0 1 0 0 0 7 01008 01 84 Auvergne-Rhône-Alpes 0 1 0 0 0 0 0 8 01009 01 84 Auvergne-Rhône-Alpes 1 1 0 0 0 0 0 9 01010 01 84 Auvergne-Rhône-Alpes 1 1 0 1 1 0 0 10 01011 01 84 Auvergne-Rhône-Alpes 0 1 0 0 0 0 1 # ... with 34,829 more rowsVoici par exemple la traduction cartographique de la colonne risq_barrage (risque de rupture de barrage, en bleu la modalité 1) :
across() cible un ensemble de colonnes avec la même syntaxe que celle utilisée dans un select().
Rappelons les mécanismes de la sélection de colonnes dans dplyr – ils sont nombreux et astucieux – au travers de quelques exemples :
# "tidy selection" : offre plein de possibilités pour spécifier des colonnes # à partir de leur nom, de leur type, de leur indice... tb_risques |> select(codgeo, starts_with('risq_')) tb_risques |> select(where(is.character), risq_nucleaire) # on peut même intégrer une variable externe # ces 3 variables constituent chacune une liste de noms de colonnes de risques c_risques = tb_risques |> select(starts_with('risq_')) |> names() c_risques_naturels = str_c("risq_", c('inond','seisme','terrain')) c_risques_humains = str_c("risq_", c('barrage','industriel','feux','nucleaire')) tb_risques |> select(1:3, all_of(c_risques_humains)) # note : ceci fonctionne, mais plus pour longtemps : avertissement "deprecated" tb_risques |> select(codgeo, c_risques_humains) # il faut donc entourer toute variable (simple ou liste de colonnes) avec all_of()across() utilise les mêmes mécanismes de sélection concise (tidy selection) à partir d’indices, de portions de noms ou via les types de colonnes : caractère, numérique, etc.
La “tidy selection” ne fonctionne pas partout dans dplyr (ou sa copine tidyr) : seuls quelques verbes en tirent parti comme select(), pivot_longer(), unite(), rename_with(), relocate(), fill(), drop_na() et donc across().
À l’inverse, group_by(), arrange(), mutate(), summarise(), filter() ou count() n’autorisent pas la tidy selection (group_by(1,2) ou arrange(3) ne fonctionnent pas).
Une bonne part de la magie d’across(), on va le voir, consiste à amener la souplesse de la tidy selection au sein de ces verbes qui normalement ne l’implémentent pas (ce “pontage” est aussi dénommé bridge pattern).
1 - rowSums() et across()Voici un premier exemple avec la fonction de sommation de colonnes rowSums(), qui précisément n’est pas compatible avec la tidy selection.
Pour sommer des colonnes, on devait auparavant les écrire toutes (dans un mutate()), ou utiliser une obscure syntaxe associant rowSums() avec un select() et un point.
across() simplifie tout cela :
# on peut sommer des colonnes à la main avec mutate() tb_risques |> mutate(nb_risques = risq_inond + risq_seisme + risq_feux + risq_barrage + risq_industriel + risq_nucleaire + risq_terrain) # ou avec rowSums() tb_risques %>% mutate(nb_risques = rowSums(select(., starts_with('risq_')))) # note : cette syntaxe complexe, où le . rappelle la table en cours, # ne fonctionne qu'avec l'ancien "pipe" %>% # >>> on peut faire plus simple avec across() tb_risques |> mutate(nb_risques = rowSums(across(starts_with('risq_')))) # ou avec une liste de colonnes stockée dans une variable c_risques_humains tb_risques |> mutate(nb_risques = rowSums(across(all_of(c_risques_humains)))) # pour mémoire : cette alternative rowwise() est À EVITER ! # les performances sont catastrophiques (30 s contre 0,5 s ci-dessus) : tb_risques |> rowwise() |> mutate(nb_risques = sum(c_across(all_of(c_risques_humains))))Cette première utilisation d’across() est basique (et méconnue), elle ne fait intervenir que le premier paramètre d’across() : une sélection de colonnes.
rowSums() (ou sa cousine rowMeans()) conduisent le traitement souhaité (somme ou moyenne) sur ces colonnes.
2 - summarise() et across()Celles et ceux qui ont déjà joué avec across() l’ont probablement employé dans le contexte d’un summarise(), par exemple pour sommer “vite fait” tout un paquet de colonnes numériques.
across() invite à spécifier les colonnes visées, puis le traitement à opérer sur chacune d’entre elles. De façon optionnelle, les colonnes produites par le calcul sont renommées pour mieux traduire l’opération conduite, avec par exemple ajout d’un préfixe ou d’un suffixe aux noms de colonne d’origine.

# série de 5 écritures équivalentes pour compter les communes à risque # avec across et une fonction toute simple tb_risques |> summarise(across(starts_with('risq_'), sum)) # across et une fonction "anonyme", avec une option tb_risques |> summarise(across(where(is.numeric), \(r) sum(r, na.rm = TRUE))) # R 4.1 # across avec l'écriture "en toutes lettres" de la fonction tb_risques |> summarise(across(5:last_col(), function(r) { return( sum(r, na.rm = TRUE) ) })) # across et une fonction anonyme, écriture ultra concise tb_risques |> summarise(across(-(1:4), ~sum(., na.rm = TRUE))) # across avec une variable listant les colonnes tb_risques |> summarise(across(all_of(c_risques), ~sum(., na.rm = TRUE))) # across avec une autre variable et une règle de renommage tb_risques |> summarise(across(all_of(c_risques_humains), \(r) sum(r, na.rm = TRUE), .names = "nb_{col}")) # A tibble: 1 x 4 nb_risq_barrage nb_risq_industriel nb_risq_feux nb_risq_nucleaire <dbl> <dbl> <dbl> <dbl> 3731 1819 6565 480across() opère un renversement de l’ordre naturel, habituel des opérations, tout en les séparant sous forme de paramètres distincts, de nature très différente : liste (de colonnes) et fonctions (de traitement et de renommage).
Considérez les deux écritures suivantes, la première correspond à nos habitudes de pensée, la seconde, avec across(), introduit une nouvelle façon de modéliser les traitements. Elle n’est pas immédiate à intégrer, elle peut même paraitre abstraite, peu intuitive. Pourtant, l’absorber, franchir ce pas logique, permet de s’ouvrir à de nouvelles dimensions d’analyse et de programmation (dite “fonctionnelle”).

Autre caractéristique fondamentale d’across() : le même traitement est répété indépendamment pour chaque colonne( seule une fonction très particulière comme rowSums() permet de combiner plusieurs colonnes dans une même opération).

Un bouquet de fonctions (par exemple sum et mean) peut être appelé dans un seul across(), en utilisant une liste.
Enfin, comme on l’a déjà souligné, il est très facile avec across() d’injecter des variables dans une chaine de requête, et donc d’écrire ses propres fonctions pour raccourcir et simplifier ses scripts.
3 - mutate() et across()mutate() avec across() suit la même logique qu’un summarise(), tout en préservant le niveau de détail (le nombre de lignes) de la table d’origine. across() permet typiquement de recoder ou “normaliser” (convertir en % par exemple) un ensemble de colonnes.
Les colonnes transformées sont souvent renommées, pour plus de clarté, les colonnes d’origine pouvant être conservées, ou non.
Recodage :
# recoder des colonnes : 1 => 'exposée', 0 => '' tb_risques |> mutate(across(starts_with('risq_'), \(r) ifelse(r == 1, 'exposée', ''))) # recoder selon le risque, 1 => 'barrage', 'inond', 'nucleaire'.... # cur_column() indique le nom de la colonne en cours de lecture tb_risques |> mutate(across(starts_with('risq_'), \(r) ifelse(r == 1, str_sub(cur_column(), 6), ''))) |> select(com, all_of(c_risques_naturels)) # A tibble: 34,839 x 4 com risq_inond risq_seisme risq_terrain <chr> <chr> <chr> <chr> 1 01001 "inond" "" "" 2 01002 "" "seisme" "terrain" 3 01004 "inond" "seisme" "terrain" 4 01005 "" "" "" 5 01006 "" "seisme" "" # ... with 34,834 more rowsNormalisation :
# conversion en % : 100 * nb de communes exposées / nb total de communes tb_risques |> summarise(across(starts_with('risq_'), sum), nb_com = n()) |> mutate(across(starts_with('risq_'), \(r) 100 * r / nb_com)) # A tibble: 1 x 8 risq_inond risq_seisme risq_nucleaire risq_barrage risq_industriel risq_feux risq_terrain nb_com <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> 59.2 25.1 1.38 10.7 5.22 18.8 53.8 34839 # conversion en % avec renommage tb_risques |> summarise(across(starts_with('risq_'), sum), nb_com = n()) |> mutate(across(starts_with('risq_'), \(r) 100 * r / nb_com, .names = "part_{str_sub(col, 6)}"), .keep = "unused") # conversion en % avec une variable pour la liste des colonnes à traiter tb_risques |> summarise(across(all_of(c_risques_humains), sum), nb_com = n()) |> mutate(across(all_of(c_risques_humains), \(r) 100 * r / nb_com, .names = "part_{str_sub(col, 6)}"), .keep = "unused") # éliminer les colonnes d'origine # A tibble: 1 x 4 part_barrage part_industriel part_feux part_nucleaire <dbl> <dbl> <dbl> <dbl> 10.7 5.22 18.8 1.384 - filter() et 2 variantes d'across() : if_all() et if_any()Que veut dire filtrer une table en considérant tout un ensemble de colonnes ?
Je peux vouloir filtrer cette table des risques de deux façons différentes : dégager les communes cumulant tous les risques, ou celles présentant au moins un risque.
Cette dualité a conduit les concepteurs d’across() à en décliner deux variantes : if_all(), qui reprend la logique d’across() (même condition pour toutes les colonnes), et if_any(), qui ne s’intéresse qu’à la possibilité qu’une colonne au moins remplisse la condition définie par la fonction anonyme.
Par souci de cohérence, across(), étant l’équivalent de if_all(), devient au sein d’un filter() déconseillé (déprécié) au profit de if_all().
# across() est encore utilisable dans filter(), mais plus pour longtemps tb_risques |> filter(across(starts_with('risq_'), \(r) r == 1)) # un avertissement invite à utiliser plutôt if_all() tb_risques |> filter(if_all(starts_with('risq_'), \(r) r == 1)) |> select(com) # A tibble: 4 x 1 com <chr> 1 13039 2 13097 3 42056 4 84019 # 4 communes sont exposées aux 7 risques : Fos-sur-Mer, St-Martin-de-Crau, # Chavanay et Bollène # if_any pour une condition vérifiée sur une colonne au moins # parmi celles décrites dans une variable c_risques_humains tb_risques |> filter(if_any(all_of(c_risques_humains), \(r) r == 1)) |> select(com, all_of(c_risques_humains)) # plus de 10 000 communes exposées à un risque humain # A tibble: 10,679 x 5 com risq_barrage risq_industriel risq_feux risq_nucleaire <chr> <dbl> <dbl> <dbl> <dbl> 1 01007 1 0 0 0 2 01010 1 1 0 0 3 01014 0 1 0 0 4 01024 0 1 0 0 5 01027 1 1 0 0 # ... with 10,674 more rows5 - mutate() et if_all() ou if_any()if_all() et if_any() ne sont pas réservés au contexte d’un filter(), il est possible de les utiliser avec un mutate(), matérialisant dans une nouvelle colonne le respect d’une condition.
Je pourrai ainsi comparer les communes à risque avec les communes sans aucun risque.
tb_risques |> mutate(risque_humain = if_any(all_of(c_risques_humains), \(r) r == 1)) |> select(com, all_of(c_risques_humains), risque_humain) # A tibble: 34,839 x 6 com risq_barrage risq_industriel risq_feux risq_nucleaire risque_humain <chr> <dbl> <dbl> <dbl> <dbl> <lgl> 1 01001 0 0 0 0 FALSE 2 01002 0 0 0 0 FALSE 3 01004 0 0 0 0 FALSE 4 01005 0 0 0 0 FALSE 5 01006 0 0 0 0 FALSE # ... with 34,834 more rows # variante : un comptage simple tb_risques |> count(if_any(all_of(c_risques_humains), \(r) r == 1)) |> select(`exposition risque humain` = 1, nb_com = n) # A tibble: 2 x 2 `exposition risque humain` nb_com <lgl> <int> 1 FALSE 24160 2 TRUE 106796 - group_by() et across()group_by() ne permet pas d’utiliser directement la “tidy selection”, across(), dans sa syntaxe la plus simple (sans fonction), lui apporte cette souplesse d’écriture.
# regroupement selon les colonnes d'indice 2 à 4 tb_risques |> group_by(across(2:4)) |> summarise(across(where(is.numeric), sum)) # regroupement selon les colonnes de type caractère, sauf la 1ère tb_risques |> group_by(across(where(is.character) & -1)) |> summarise(across(where(is.numeric), sum)) tb_risques |> group_by(across(where(is.character) & -1)) |> summarise(across(all_of(c_risques_humains), sum)) # A tibble: 96 x 7 # Groups: dep, reg [96] dep reg lib_reg risq_barrage risq_industriel risq_feux risq_nucleaire <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> 1 01 84 Auvergne-Rhône-Alpes 70 56 0 20 2 02 32 Hauts-de-France 0 48 0 0 3 03 84 Auvergne-Rhône-Alpes 73 5 31 0 4 04 93 Provence-Alpes-Côte d'Azur 53 14 173 1 5 05 93 Provence-Alpes-Côte d'Azur 17 37 162 0 # ... with 91 more rows
Il devient également possible, avec across(), d’injecter une variable dans un group_by(), comme on va le voir dans la section suivante.
7 - arrange() et across()Avec across(), le verbe de tri arrange() gagne lui-aussi en souplesse d’écriture.
# cette écriture ne marche pas, arrange n'est pas "tidy select" compatible tb_risques |> arrange(3) # mais avec across, ça marche tb_risques |> arrange(across(3)) # on peut utiliser desc à titre de fonction tb_risques |> arrange(across(3, desc))
Ce bloc plus riche considère, par département, la part de communes exposée au risque rupture de barrage. Le type de risque devient un paramètre, prélude à l’écriture possible d’une fonction.
# deux variables pour cibler un risque risq = 'barrage' col_risq = str_glue("risq_{risq}") # risque barrage par département tb_risques |> group_by(dep) |> summarise(across(all_of(col_risq), sum), nb_com = n()) |> mutate(across(all_of(col_risq), \(r) 100 * r / nb_com, .names = "part_{.col}"), .keep = 'unused') |> # on ne garde pas les variables d'origine arrange(across(str_glue("part_risq_{risq}"), desc)) # avec str_glue(), across() peut même décoder une formule ! # A tibble: 96 x 2 dep part_risq_barrage <chr> <dbl> 1 13 46.2 2 46 38.0 3 38 34.0 4 10 32.7 5 19 30.7 # ... with 91 more rows # Bouches-du-Rhône, Lot, Isère, Aube et Corrèze ont la plus forte # part de communes exposées au risque de rupture de barrageCette dernière variante utilise across() à tous les étages : group_by(), summarise(), mutate() et arrange() !
# nouvelle variable pour les colonnes de regroupement # on veut pouvoir regrouper soit par département, soit par région # (avec le libellé associé) nivgeo = c("reg","lib_reg") tb_risques |> group_by(across(all_of(nivgeo))) |> summarise(across(all_of(col_risq), sum), nb_com = n(), .groups = 'drop') |> # raccourci pour ungroup() mutate(across(all_of(col_risq), \(r) 100 * r / nb_com, .names = "part_{.col}"), .keep = 'unused') |> arrange(across(str_glue("part_risq_{risq}"), desc)) # A tibble: 13 x 3 reg lib_reg part_risq_barrage <chr> <chr> <dbl> 1 84 Auvergne-Rhône-Alpes 21.6 2 76 Occitanie 20.0 3 93 Provence-Alpes-Côte d'Azur 19.6 4 75 Nouvelle Aquitaine 13.1 5 44 Grand-Est 10.3 # ... with 8 more rowsCes 7 exemples démontrent la puissance et la flexibilité d’across(), qui nous permet d’écrire des programmes plus élégants, plus flexibles.
Ayez le réflexe DRY : Don’t Repeat Yourself. Dès que vous détectez une répétition dans vos scripts, la même formule réécrite pour x colonnes, des blocs de code qui ne diffèrent que par quelques variables, il y a de fortes chances qu’across() vous rende service, vous aide à écrire des scripts plus robustes, lisibles et paramétrables.
across() fait intervenir, le plus souvent, l’écriture d’une petite fonction (dite anonyme), matérialisant l’opération à répéter, qui peut ainsi être optimisée.
Il vous invite à écrire vos propres fonctions plus globales, sans en passer par la complexité des {{}}, enquos() et autres :=, toutes syntaxes assez vilaines, impossibles à retenir (et à expliquer).
Pour aller plus loin- Column-wise operations
- Why did it take so long to discover across() ?
- Bridge patterns
- across : appliquer des fonctions à plusieurs colonnes
- Mon top 7 des évolutions récentes de tidyverse
L’article across() est plus puissant et flexible qu’il n’y parait est apparu en premier sur Icem7.
-
sur Geomatys se développe et recrute un(e) full stack développeur (se)
Publié: 28 October 2022, 5:12pm CEST par user
Nous sommes à la recherche d’un(e) développeur(euse) Full Stack (Bac+5 ou Ecole d’ingé.) dans l’univers Java avec une première expérience (ou stage) réussie en Java/Spring et/ou Javascript/Angular

Ce que nous cherchons chez vous :
- De la curiosité. En veille permanente sur l’évolution des technologies
- Autonomie et pragmatisme dans vos prises de décisions
- Une capacité et un plaisir à travailler en équipe
- De la rigueur. La lisibilité du code/des Api est fondamentale. Les tests font partie intégrante de votre process de dev.
- Une envie de travailler sur des technologiques riches
- Attentif à l’architecture avec réflexion sur les performances de gestion de données volumineuses et de leur traitements
Si vous avez de l’enthousiasme, une appétence pour la cartographie / les problématiques spatiales, et une envie de travailler dans un domaine ultra-innovant, envoyez-nous votre CV (isabelle.pelissier@geomatys.com), pas besoin de lettre de motivation, rien de tel que des projets concrets pour juger de vos compétences (liens Github… ou autre)
Poste à pourvoir sur Montpellier
Salaire selon expérience
Qui sommes-nous ?
GEOMATYS est un éditeur de logiciel qui développe depuis 15 ans des produits et des nouveaux systèmes d’informations permettant de traiter l’information géographique. Notre activité d’édition logicielle nous conduit à développer des bibliothèques dédiées au traitement de gros volume d’information géographique, des Geo-Webservices et des frameworks cartographiques, que nous intégrons ensuite pour les besoins de nos clients.
Nous sommes une société influencée par la forte culture technique de ses dirigeants, développant des projets innovants au service d’industriels et de scientifiques dans des domaines aussi variés que l’Environnement, le Spatial ou la Défense.
Grâce à un travail reconnu en recherche et développement, notre société, GEOMATYS, a gagné une expertise lui permettant de travailler désormais auprès de grands comptes (Naval Group, Airbus, Le CNES ….).
Vous intégrerez une équipe dédiée au développement d’applications à fortes dominantes géographiques, constituée de développeurs fullstack principalement orientés Java et angular, pour des environnements Docker/Kubernetes, combinés à de nombreux produits open-sources tel que la suite Elastic (ELK), ou PostGreSQL/PostGIS.
The post Geomatys se développe et recrute un(e) full stack développeur (se) first appeared on Geomatys.
-
sur Divagations à propos du temps
Publié: 21 October 2022, 9:34pm CEST par Isabelle Coulomb
 Bonjour, je suis le temps.
Bonjour, je suis le temps.Donnée universelle, avec l’implacable régularité du métronome, je passe.
Immuable et inexorable, j’avance de la même manière, partout, toujours.
Je suis la richesse la plus équitablement répartie : 60 secondes par minute, 24 heures par jour, 12 mois par an, c’est pareil pour tout le monde.
Ce qui change, pour vous autres, êtres humains, c’est la perception que vous avez de moi. Dans l’ennui, la peine ou la douleur, je vous semble long. Mais dès que la joie fleurit, vous trouvez que je passe trop vite.
Dans l’époque frénétique et connectée où vous vivez, où les sollicitations pleuvent de toutes parts pour beaucoup d’entre vous, vous êtes nombreux à dépenser beaucoup d’énergie à courir après les aiguilles de la montre. Je suis toujours présent, et pourtant, je vous manque.
Cependant, je reste bien toujours le même. La seule inconnue, pour chacun de vous, c’est de savoir quand cesserez-vous de voir l’horloge tourner. Moi, de toute façon, je continuerai, jusqu’à la fin des temps…
L’horloge ne cesse jamais de tourner
Évidemment, depuis la nuit des temps, on a cherché à me mesurer. De calendriers antiques en cadrans solaires, on a voulu me quantifier avec toujours plus de précision, jusqu’aux plus précises horloges atomiques. Cependant, difficile de savoir exactement quand j’ai commencé. Et, question encore plus vertigineuse, savoir si je finirai un jour.
La statistique, qui se penche sur tous les domaines de la connaissance, n’a pas manqué de s’intéresser à moi. Le moindre indicateur ne fournit aucune information utile s’il n’est pas daté. Dire que la population totale de la ville de Toulouse est de 498 596 habitants ne présente un intérêt qu’en précisant en 2019.
Et cela prend une toute autre dimension si l’on ajoute que cette population était de 466 219 en 2013. Cela permet au statisticien de faire quelque chose dont il raffole : une comparaison
 ! Et même de calculer une évolution
! Et même de calculer une évolution  ! Entre 2013 et 2019, la population toulousaine a augmenté de près de 7 %.
! Entre 2013 et 2019, la population toulousaine a augmenté de près de 7 %.Le taux d’évolution est assez simple à calculer : Te = ((Va-Vd) / Vd) * 100 = (Va/Vd – 1) * 100, où Va et Vd sont les valeurs de départ et d’arrivée. Il y a des calculateurs en ligne qui font le calcul tout seuls. Un peu plus compliqué, le taux d’évolution annuel moyen est, comme son nom l’indique, une moyenne par an. Dans cet exemple, il vaut 1,13 %. La formule pour le calculer est assez jolie, même si elle peut intimider les personnes réticentes aux mathématiques : Tem = (((Va/Vd)**(1/n)) – 1) * 100, où n est le nombre de périodes, 6 dans cet exemple.
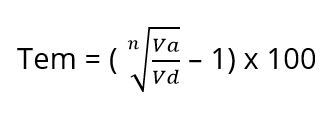 La boîte à outils du statisticien
La boîte à outils du statisticienAvec dans sa trousse à outils, ces 2 formules, ainsi que les calculs d’une moyenne simple et d’un pourcentage, le statisticien dispose de la base indispensable. Ensuite, une grande partie de son art réside dans savoir représenter les données qu’il a calculées, pour pouvoir les interpréter.
Une donnée, pour avoir du sens, doit être datée. Elle en prend davantage s’il est possible de la comparer. Et moi, le temps, je déploie tout mon potentiel lorsque le statisticien dispose de toute une série de données. L’Insee consacre tout une rubrique de son site aux séries chronologiques. Dans la rubrique consacrée à la population, on trouve des séries remontant jusqu’à 1876.
La série chronologique va de pair avec sa représentation la plus naturelle : la courbe d’évolution. Peu importe l’unité de mesure, on me couche sur l’axe des abscisses. Et on mesure la donnée représentée sur l’axe des ordonnées. Par exemple, l’électrocardiogramme mesure l’activité électrique du cœur.
Plutôt qu’une courbe d’évolution, dans les cas où le nombre de périodes de la série n’est pas trop important, un diagramme en barres verticales peut opportunément être utilisé. Et si les intervalles sont d’inégales amplitudes, le statisticien aura recours à l’histogramme, dans lequel la grandeur représentée est proportionnelle à la surface de chaque barre.
Un autre moyen efficace de représenter des données temporelles est de construire une série de petits graphiques, un pour chaque période (sous réserve que le nombre de périodes ne soit pas trop grand). Les outils numériques rendent aussi possible la construction d’animations temporelles, qui peuvent produire des effets visuels éloquents.
La première courbe d’évolution de l’histoire
Cette forme de représentation semble aujourd’hui une évidence tant on la rencontre un peu partout. Cela n’a pas toujours été le cas. On doit ses premières apparitions, dans les années précédant la Révolution française, au génial et inventif William Playfair. Le même a également eu l’idée des diagrammes en barres et circulaires.
Cela s’applique bien en cartographie statistique : créer une série de cartes thématiques et les afficher successivement rend visible l’évolution du phénomène cartographié dans le temps et dans l’espace. Ceci est par exemple mis en œuvre dans l’application Géodes, de Santé Publique France, pour suivre l’évolution hebdomadaire et quotidienne des taux d’incidence, de positivité et de dépistage du Covid-19 (données de laboratoires Si-Dep).
La distance, la vitesse et moiRevenons pour finir sur cette bonne vieille courbe d’évolution. En voici un exemple très éloquent :
Il provient de la thèse de doctorat intitulée « Les transports face au défi de la transition énergétique. Explorations entre passé et avenir, technologie et sobriété, accélération et ralentissement. », soutenue en novembre 2020, par Aurélien Bigo. Il représente l’évolution de la distance parcourue par jour. Il est plus conçu pour les lecteurs experts d’un rapport de thèse que pour le public large d’un journal, par exemple. On imagine bien qu’Éric Mauvière, expert en datavisualisation, aurait quelques petites remarques sur la présentation de ce graphique, sur les titres, les légendes, la typographie, le choix des couleurs… Il est déjà très intéressant tel qu’il est.
Il montre quelle place absolument prépondérante a pris la voiture individuelle dans les modes de déplacement en à peine un siècle. Les progrès technologiques, permis par l’abondance de sources d’énergie, ont considérablement augmenté les vitesses de déplacement. Des vitesses plus élevées permettent d’aller plus loin ou de mettre moins de temps. Visiblement, la priorité a été donnée à aller plus loin plutôt qu’à gagner du temps. Je ne sais pas vous, mais moi, cela me fais réfléchir sur l’importance que l’on m’accorde, ou pas…
L’article Divagations à propos du temps est apparu en premier sur Icem7.
-
sur Revue de presse du 21 octobre 2022
Publié: 21 October 2022, 2:20pm CEST
 L'automne est là et bien là et les news tombent aussi régulièrement et nonchallamment que les feuilles des arbres. A vos géorateaux et bon ramassage !
L'automne est là et bien là et les news tombent aussi régulièrement et nonchallamment que les feuilles des arbres. A vos géorateaux et bon ramassage !
-
sur Publier des rasters volumineux avec GeoServer
Publié: 18 October 2022, 6:51pm CEST par Florian Delahaye
En Système d’Informations Géographiques (SIG), la manipulation de données rasters demande souvent des ressources informatiques importantes. Le poids d’une image raster augmente notamment avec sa résolution spatiale et sa couverture géographique. Mais la complexité de gestion de ce type de donnée géographique ne se limite pas aux propriétés des pixels… Continuer à lire →
L’article Publier des rasters volumineux avec GeoServer est apparu en premier sur GEOMATICK.
-
sur Journée d’étude : L’histoire de la cartographie et son écriture à l’épreuve du renouvellement, Campus Condorcet (Aubervilliers), 25/11/2022
Publié: 12 October 2022, 12:49pm CEST par Catherine Hofmann
Depuis les années 1980, l’histoire de la cartographie a vu ses concepts, ses objets, ses méthodes d’investigation et ses manières d’écrire se transformer profondément sous l’influence des analyses de John Brian Harley et de ses émules (D. Woodward, C. Jacob, M. Edney, etc.). Une nouvelle manière d’écrire l’histoire de la cartographie s’est progressivement installée, y compris en France, en lien avec une réflexion plus générale sur les représentations de l’espace.
Quarante ans après, la journée d’étude organisée par la Commission « Histoire » du Comité Français de Cartographie se propose de revenir sur ces évolutions et le tournant « déconstructionniste », mais aussi d’interroger de façon élargie la cartographie et son histoire en la confrontant aux apports récents des sciences humaines (histoire, histoire de l’art, littérature, anthropologie, sociologie, etc.) et à la dématérialisation massive tant des modes de production et usages de la cartographie que des méthodes permettant de l’explorer et de l’analyser.
 Nicolas Bion, Globe terrestre dressé sur les observations de Mrs de l’Académie royale des sciences et sur les nouveaux mémoires des plus fameux et expérimentée (sic) voyageurs, Paris, avant 1733
Programme
Nicolas Bion, Globe terrestre dressé sur les observations de Mrs de l’Académie royale des sciences et sur les nouveaux mémoires des plus fameux et expérimentée (sic) voyageurs, Paris, avant 1733
Programme
- 9 h : Accueil et introduction
- 9 h 30 -11 h : Table-ronde : Comment écrire aujourd’hui l’histoire de la cartographie ? Débats et perspectives, avec Christian Jacob, Josef Konvitz et Gilles Palsky
Animée par Jean-Marc Besse (CNRS-EHESS)
- 11 h -11 h15 : Pause-café
- 11 h15 -12 h 30 : Première session : l’histoire de la cartographie à la rencontre de la littérature et de l’histoire des savoirs
Sous la présidence d’Emmanuelle Vagnon (CNRS-LAMOP)- Isabelle Ost (Université Saint-Louis, Bruxelles) : Littérature et cartographie : épistémologies croisées
- Zoé Pfister (Université de Bourgogne) : « Lieux, objets et gestes » du savoir cartographique. Approches spatiale, matérielle et pragmatique du projet de Lannoy de Bissy (1873-1889)
- 12 h 30 -14 h : Déjeuner
- 14 h -15 h 30 : Deuxième session : l’histoire de la cartographie et son écriture
Sous la présidence d’Émilie d’Orgeix (EPHE-PSL)- Monika Marczuk (BnF, Dép. des Cartes et plans) : Approche processuelle et approche pragmatique de l’histoire de la cartographie. Convergences et limites
- Carolina Martinez (CONICET, Buenos Aires) : « Ibérisation », « atlantisation », américanisation : l’histoire de la cartographie des « mondes ibériques » au début du XXIe siècle
- Anca Dan (CNRS, Paris) : De l’histoire de la cartographie à l’histoire des représentations spatiales : de l’utilité du postcolonialisme à l’ère numérique
- 15 h 30 -16 h : Pause-café
- 16 h -17 h 30 : Troisième session : les usages de l’histoire de la cartographie dans l’enseignement et dans la construction des savoirs
Sous la présidence d’Isabelle Warmoes (Musée des plans reliefs)- Jordana Dym (Skidmore College, NY, USA) : Leçons de la salle de classe : la pédagogie comme travail de terrain pour l’enseignement de l’histoire de la carte et de la cartographie
- Félix de Montety (Université Grenoble Alpes) : Le langage, des cartographes. Comment écrire l’histoire des méthodes de représentation et approches visuelles en cartographie linguistique
- Fanny Madeline et Alexis Lycas (Université Paris I et EPHE-PSL) : Cartographier l’Europe et la Chine médiévales : productions et usages de la carte chez les médiévistes
- 17 h 30 : Conclusions de la journée.
- 25 novembre 2022
- Campus Condorcet – Centre des colloques – Salle 100 – Aubervilliers (Métro ligne 12, Front Populaire)
- Entrée libre
- Contact : catherine.hofmann@bnf.fr

![[https:]](https://www.geotests.net/depot/160_Afrique_Ctg%202000-2050_Pop%20Agee.jpg’){kind=link}
![[https:]](https://www.geotests.net/depot/winds.jpg’){kind=link}
-
sur Revue de presse du 7 octobre 2022
Publié: 7 October 2022, 2:20pm CEST
 Dans le pipeline de l'actualité : le Géotuileur IGN, de la 3D, un fond OSM VTT, un atlas de l'anthropocène, le 30DayMapChallenge qui approche, le SAGEO qui s'annonce, un Podcast géomatique, un livre PostGIS
Dans le pipeline de l'actualité : le Géotuileur IGN, de la 3D, un fond OSM VTT, un atlas de l'anthropocène, le 30DayMapChallenge qui approche, le SAGEO qui s'annonce, un Podcast géomatique, un livre PostGIS -
sur Faire une carte façon Ed Fairburn avec QGIS
Publié: 30 September 2022, 10:00am CEST
 Utiliser les modes de fusion pour produire avec QGIS une carte inspirée des dessins d'Ed Fairburn.
Utiliser les modes de fusion pour produire avec QGIS une carte inspirée des dessins d'Ed Fairburn. -
sur Revue de presse du 23 septembre 2022
Publié: 23 September 2022, 2:20pm CEST
 GeoRDP du 23 septembre : les GéoDataDays 2022 ont été couronnés de succès, certaines des briques logicielles les plus connues sont mises à jour, des initiatives viennent redonner vie à des illustres cartographes et la géomatique continue de nous donner à voir sa diversité et son intérêt.
GeoRDP du 23 septembre : les GéoDataDays 2022 ont été couronnés de succès, certaines des briques logicielles les plus connues sont mises à jour, des initiatives viennent redonner vie à des illustres cartographes et la géomatique continue de nous donner à voir sa diversité et son intérêt.
-
sur Recrutement: IE en Télédétection
Publié: 15 September 2022, 10:41am CEST par user

La Tour du Valat est un institut de recherche pour la conservation des zones humides méditerranéennes basé en Camargue, sous le statut d’une fondation privée reconnue d’utilité publique. Fondée en 1954 par le Dr Luc Hoffmann, elle est à la pointe dans les domaines de la recherche multidisciplinaire, l’établissement de ponts entre science, gestion et politiques publiques et l’élaboration de plans de gestion. Elle s’est dotée d’une mission ambitieuse : « Les zones humides méditerranéennes sont préservées, restaurées et valorisées par une communauté d’acteurs mobilisés au service de la biodiversité et des sociétés humaines ».
La Tour du Valat a développé une expertise scientifique reconnue internationalement ; elle apporte des réponses pratiques aux problèmes de conservation et de gestion durable des ressources naturelles. La Tour du Valat emploie environ 80 personnes dont une quinzaine de chercheurs et autant de chefs de projets. Elle accueille également sur son site plusieurs autres structures, ainsi que de nombreux doctorants, post-doctorants, stagiaires et/ou volontaires en saison estivale. Plus de détail sur http://www.tourduvalat.org
La Tour du Valat recrute un/e Ingénieur d’étude en analyse de données pour le suivi des zones humides à l’aide des outils d’Observation de la Terre (OT)
Contexte
Le Bassin Méditerranéen est un des 32 Hotspots mondiaux de biodiversité. Ceci grâce, notamment, à la présence d’une grande diversité de zones humides, considérées comme les écosystèmes les plus riches et les plus productifs de la région. Cependant, malgré leur importance pour l’Homme et la nature, ces milieux sont également les plus menacés par les activités humaines. En effet, selon une étude récente réalisée par l’Observatoire des Zones Humides Méditerranéennes (OZHM), on estime que près de la moitié des habitats humides naturels ont disparus depuis les années 1970 au sein de cette région. Une des principales causes de ce déclin rapide serait leur perte directe, avec leur conversion vers d’autres formes d’usage des sols.
Face à cette situation alarmante, il est donc crucial de rassembler un maximum d’informations pertinentes sur l’état des zones humides méditerranéennes et d’analyser les tendances de leurs habitats naturels ainsi que celles des principales menaces qui pèsent sur eux. C’est dans ce contexte que l’OZHM, coordonné par la Tour du Valat dans le cadre de l’Initiative MedWet, développe depuis une dizaine d’année un ambitieux programme de suivi de ces écosystèmes, basé sur les outils et technologies d’Observation de la Terre (OT). Parallèlement, de nouvelles approches d’analyse des images satellitaires ont prouvé leur capacité à extraire de l’information pertinente. Principalement basées sur des méthodes d’apprentissage profond (Deep Learning) et pour les plus récentes sur le transfert de domaine. Elles permettent, par exemple, d’appliquer des modèles, appris sur une zone donnée, sur d’autres zones pour lesquelles il existe peu ou pas de données d’apprentissage. Ce poste d’Ingénieur d’Étude en Télédétection proposé ici, vient donc répondre à ce besoin d’amélioration des connaissances sur les zones humides à l’aide des outils d’OT. Il s’agit d’une part, de mettre en place une chaine de traitements basée sur des algorithmes développés en collaboration avec divers partenaires scientifiques de la Tour du Valat, tels que le laboratoire ICube de l’Université de Strasbourg ou encore l’UMR Littoral, Environnement, Télédétection, Géomatique (LETG) de l’Université Rennes II et, d’autre part, de valider celles-ci sur des données réelles fournies par l’OZHM. La personne retenue devra donc contribuer à la mise en œuvre de différents projets en cours, notamment le projet AIonWetlands (appuyé par le programme Space Climate Observatory), ainsi qu’un projet de R&D porté par le Ministère de la Transition Ecologique et visant à développer une modélisation nationale des milieux humides en France métropolitaine et de leurs fonctions.
Missions
- Contribuer, avec d’autres partenaires techniques de la Tour du Valat, à la mise en œuvre d’outils d’analyse et de traitement des images satellites (essentiellement optiques), notamment ceux intégrant des algorithmes d’Intelligence Artificielle (Deep Learning et Machine Learning)
- Extraire, à l’aide de ces outils, des informations pertinentes sur l’état et les tendances des zones humides suivies, leurs fonctions, ainsi que les principales pressions qu’elles subissent
- Contribuer au développement et à l’application de protocoles de validation de ces résultats cartographiques
- Automatiser, le plus possible, les chaines de traitement et les intégrer dans les protocoles de suivi de l’OZHM, notamment en lien avec les indicateurs spatialisés
- Contribuer, au développement et à la gestion des bases de données spatialisées de l’OZHM (indicateurs de suivi des zones humides)
- Contribuer à la rédaction des rapports techniques des différents projets dans lesquels il/elle sera impliqué(e), en particulier les deux mentionnés plus haut
- Participer à l’élaboration des différents produits de l’OZHM, notamment les rapports sur l’état et les tendances des zones humides méditerranéennes
Profil et compétences recherchées
Indispensables :
- Bac+5 (M2 ou Ingénieur) en informatique, en télédétection ou en géomatique ou toute autre discipline dans les sciences de l’environnement intégrant une forte composante en traitement d’imagerie satellitaires (géographie, aménagement du territoire/littoral, écologie, etc.)
- Maîtrise des outils SIG et de traitement des données d’Observation de la Terre
- Connaissances en analyse de données et apprentissage. Une bonne pratique des algorithmes d’apprentissage profond, sans être obligatoire, sera un plus indéniable
- Autonomie, esprit d’initiative et bonnes capacités d’analyse, de synthèse et rédactionnelles
- Capacité à travailler en équipe, notamment avec des partenaires externes
- Anglais scientifique et de communication en milieu professionnel fortement souhaité
Constitueraient des atouts :
- Connaissance des indicateurs pour le suivi des écosystèmes (état, tendances et pressions)
- ·Maitrise des outils statistiques pour l’analyse des données
- Connaissance et/ou expérience en méditerranée
Encadrement
L’Ingénieur d’Etude sera intégré(e) au sein de l’équipe du Thème « Dynamiques des Zones Humides et Gestion de l’Eau » et placé(e) sous la supervision du responsable de l’Axe « Dynamique Spatiale des Zones Humides », M. Anis Guelmami guelmami@tourduvalat.org.
Type de contrat : Le poste est à pourvoir en Contrat à Durée Déterminée de 18 mois.
Rémunération : 2300€ à 2600€ brut mensuel, selon expérience professionnelle.
Date de prise de poste : Le poste est à pourvoir dès que possible.
Lieu de travail : Tour du Valat, Le Sambuc, 13200 Arles avec la possibilité de télétravailler 2j/semaine.Comment postuler
Envoi des candidatures à Johanna Perret : perret@tourduvalat.org
(Référence à indiquer : TdV-2022-Suivi Spatialisé ZH) avant le 16 octobre 2022, comportant :- Une lettre de motivation
- Un curriculum vitae
- Deux contacts de référents
Les candidat(es) présélectionné(es) seront convoqué(es) pour un entretien en visio-conférence ou en présentiel en fonction des contraintes géographiques.
Pour toute question sur le processus de soumission de candidatures, merci de vous adresser à Johanna Perret perret@tourduvalat.org.
The post Recrutement: IE en Télédétection first appeared on Geomatys.
-
sur Revue de presse du 9 septembre 2022
Publié: 9 September 2022, 2:20pm CEST
 Découvrez notre sélection de la quinzaine : Géoplateforme, LiDAR, le 30DayMapChallenge qui se prépare, le SotM, des évènements autour de la carte,...
Découvrez notre sélection de la quinzaine : Géoplateforme, LiDAR, le 30DayMapChallenge qui se prépare, le SotM, des évènements autour de la carte,...
-
sur Le syndrome de l’empilement
Publié: 4 September 2022, 2:04pm CEST par Éric Mauvière
Les graphiques en barres empilées sont notoirement peu lisibles, la presse le sait et les évite. Des alternatives plus efficaces existent. Nous les rencontrons pourtant partout dans la production institutionnelle : pas une étude statistique, pas un rapport d’activité où l’on ne subisse ces guirlandes de bâtons multicolores[1], leurs légendes extensibles et leurs inévitables aides au déchiffrage.
Prenons deux exemples publiés la semaine dernière : à chaque fois la matière est intéressante, mais le traitement graphique la dessert.
Vous avez 5 secondes pour capter une première idée simple qui vous surprenne et vous donne envie d’aller plus loin dans l’exploration (j’aime bien ce test basique, que m’a confié un data-journaliste).
Publication de la Drees : Impact des assurances complémentaires santé et des aides sociofiscales à leur souscription sur les inégalités de niveau de vie (septembre 2022)
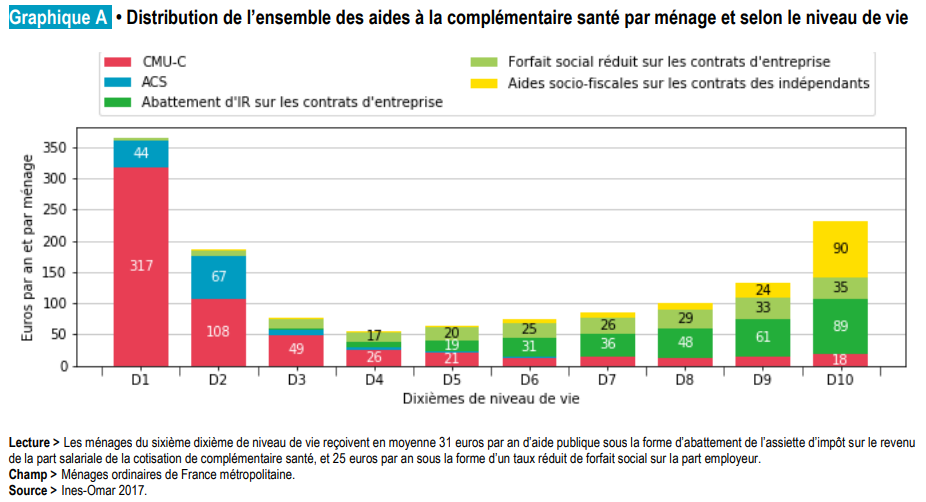
Publication de l’Insee : Un habitant sur sept vit dans un territoire exposé à plus de 20 journées anormalement chaudes par été dans les décennies à venir (août 2022)
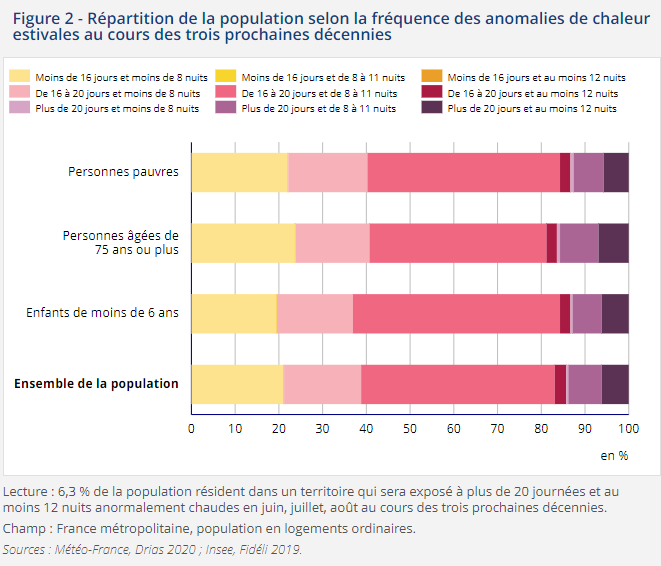 Un graphique inutile car trop complexe, dans une étude par ailleurs fort intéressante
Un graphique inutile car trop complexe, dans une étude par ailleurs fort intéressante
Vous n’y êtes pas arrivés ? Ou vous avez seulement vu dans le 1er exemple que la CMU concerne surtout les plus précaires, ce qui ne vous a rien appris ? Ne stressez pas, c’est normal. Ces graphiques n’offrent pas de point d’entrée évident, et l’absence de titre informatif ne fait rien pour les sauver. Faute de base horizontale ou verticale commune, la plupart des séries (identifiées par une même couleur) ne sont pas signifiantes « dans l’instant minimal de vision », pour reprendre les mots de Jacques Bertin, le grand sémiologue français.
Considérez par exemple la série rose pâle ci-dessus : présente-t-elle ou non des variations significatives ? Cela ne saute pas aux yeux. Seules les séries jaunes et violettes, aux extrémités, sont rapidement évaluables, disposant d’un solide point d’appui à gauche ou à droite.
Souvent, la juxtaposition de couleurs vives complique l’effort de sélection que l’œil doit conduire pour isoler chaque concept. On le constate dans le premier graphique, par ailleurs constellé de chiffres sans grand intérêt. Enfin, qui souffre de déficience visuelle, même légère, sera peu à la fête, compte tenu du nombre de couleurs à distinguer ou de l’emploi abusif de l’opposition rouge / vert.
Le second graphique (Insee) est un peu plus amical : moins de chiffres, des couleurs plus douces, des axes plus explicites. Mais je n’en retiens rien – si je refuse d’y passer plus de 20 secondes – trop de catégories sans contraste évident surchargent ma mémoire de travail.
Désempilez et simplifiez en catégorisantRevenons aux données publiées par la Drees. Comment leur rendre mieux justice ?
Il s’agit de dépenses de santé et des différentes aides soutenant les ménages selon leur niveau de vie : cela concerne et parle – a priori – à tout le monde. Quels sont les principaux contrastes, les lois et les ordres de grandeur à retenir ?
La science de la sémiologie graphique, formalisée par Jacques Bertin et Edward Tufte, pour ne citer que les plus connus, nous donne les règles à suivre, dont voici une mise en musique.
Les variables visuelles les plus efficaces sont la position dans le plan et la longueur rapportée à une base commune. L’organisation du diagramme suivant, en colonnes, et ses barres horizontales alignées à gauche répondent à ces critères.
La loi de proximité issue de la théorie de la Gestalt[2] privilégie le légendage direct de chaque série. Il est naturellement assuré par la disposition tabulaire : plus besoin d’une légende déportée obligeant à des allers et retours visuels fastidieux.
La théorie de la charge cognitive (que Bertin anticipe) encourage les tris logiques et l’extraction de grandes catégories : on oppose ici de gauche à droite les aides ciblant les niveaux de vie modestes à celles concernant les plus aisés. À côté de ces deux grandes catégories, qui dégagent une première image mentale facile à imprimer, le profil du total des aides relève d’un autre niveau de lecture : la distribution est symétrique, elle favorise les extrémités de l’éventail des niveaux de vie.
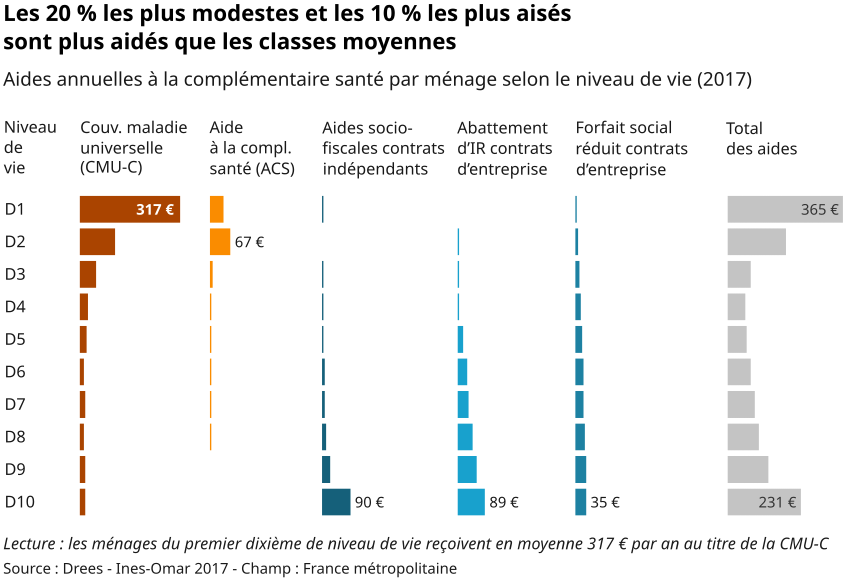
L’emploi de la couleur, subtil et souriant, souligne ces différents niveaux de lecture. Il laisse de côté le funeste duo rouge-vert rétif aux daltoniens, et n’hésite pas à utiliser le gris.
Quelques chiffres clés sont portés pour saisir l’ordre de grandeur des barres et souligner les maxima ainsi que les oppositions entre les deux principaux groupes d’aides. L’unité € précise ces chiffres pour une appréhension immédiate de ce dont il s’agit (un montant financier).
Avec ces chiffres repères, nul besoin de dessiner une grille ou des axes gradués, qui surchargeraient inutilement le graphique. Précisons que les données de l’étude sont téléchargeables pour qui voudrait les consulter en détail ou, comme moi, faire ses propres graphiques.
L’aide à la lecture sous le graphique – dont on devrait même pouvoir se passer – vient surtout expliciter les notations « D1-D10 ». Pour soulager le lecteur et lui éviter de scanner le diagramme, elle se rapporte au premier chiffre, au premier symbole visuel rencontré dans le sens de la lecture.
Certains sigles sont explicités : CMU-C, ACS. D’autres libellés sont un peu abrégés pour une meilleure homogénéité et un bandeau d’en-tête réduit à 3 lignes seulement. Tous les textes s’affichent à l’horizontale, le lecteur n’a pas à torturer ses cervicales pour comprendre un axe.
La date des données est plus clairement exposée, de fait elle est un peu ancienne. Depuis, CMU-C et ACS ont été fusionnées dans une nouvelle mesure : la « complémentaire santé solidaire » (2019).
Le titre enfin, l’élément le plus important de cette visualisation, expose le message clé. Sur deux lignes, il présente une coupure « logique » en fin de première ligne (règle de lisibilité trop méconnue elle aussi). La nature de l’indicateur présenté apparait en sous-titre, c’est à la fois nécessaire et suffisant.
Ce n'est pas au lecteur de faire l'effort de déchiffrer, c'est à vous de faire lisible et mémorableOn le voit, cette nouvelle représentation ne prend pas plus de place que l’original. Elle expose autant de données et surtout elle révèle bien davantage, avec plus d’efficacité. Davantage qu’un tableau croisé mis en couleurs, tel quel, dans un « grapheur », elle traduit la démarche analytique du rédacteur-concepteur. Chaque petit ciselage compte et contribue à l’évidence de l’ensemble : confort, équilibre, simplicité, mémorabilité.
Ce n’est pas au lecteur de faire l’effort de déchiffrer vos graphiques, c’est à vous, auteur, statisticien, expert du sujet, pédagogue obstiné, de faire ce qu’il faut pour que le ou les messages principaux « sautent aux yeux ».
Ce travail, la « résolution du problème graphique » comme l’énonçait Bertin, apporte beaucoup de plaisir à celui qui le mène. Des outils intelligents comme DataWrapper – conçus par des sémiologues avertis – le rendent accessible à tout un chacun en offrant de tester en confiance différentes variantes. Ne vous en privez pas, et surtout n’en privez pas vos lecteurs !
Pour aller plus loin« La plus grande qualité d'une image,
John Tukey, Exploratory Data Analysis, 1977
c'est quand elle nous amène à remarquer
ce que l'on ne s'attendait pas à voir. »Voici quelques ressources :
[1] Stacked bars are the worst, Robert Kosara, 2016
[2] Psychologie de la forme, Wikipedia
[3] What to consider when creating stacked column charts, Lisa Charlotte Muth, 2018
PS : Il faudrait conduire un autre genre d’étude pour comprendre l’étrange fascination qu’exerce le diagramme en barres empilées sur le statisticien. J’ai quelques hypothèses en tête. Ce visuel consacre le geste statistique canonique, croiser deux critères. Il permet de “mettre à disposition” dans un petit espace un volume significatif de données. Docile à la mise en couleurs, il ravit le concepteur tout comme le maquettiste. Ne cédant pas à la facilité d’un message trop trivial, il rappelle – discrètement – que l’accès à la connaissance se mérite !
L’article Le syndrome de l’empilement est apparu en premier sur Icem7.
-
sur Revue de presse du 26 août 2022
Publié: 26 August 2022, 2:20pm CEST
 Geotribu prépare sa rentrée, découvrez notre sélection du mois d'Août : OpenLayers, Boule, PostgreSQL, QGIS, OpenStreetMap, open data, exposition,...
Geotribu prépare sa rentrée, découvrez notre sélection du mois d'Août : OpenLayers, Boule, PostgreSQL, QGIS, OpenStreetMap, open data, exposition,... -
sur API Python de FME : comment travailler avec des rasters et GDAL
Publié: 2 August 2022, 2:00pm CEST
 Comment travailler avec des librairies Python dans FME. Illustration avec GDAL.
Comment travailler avec des librairies Python dans FME. Illustration avec GDAL. -
sur Revue de presse du 29 juillet 2022
Publié: 29 July 2022, 2:20pm CEST
 Découvrez notre sélection du mois de Juillet : PhilCarto, Bertin.js, de la carte aux terrains de foot, le Tour de France, les Rencontres Géomatiques de La Réunion qui se préparent...
Découvrez notre sélection du mois de Juillet : PhilCarto, Bertin.js, de la carte aux terrains de foot, le Tour de France, les Rencontres Géomatiques de La Réunion qui se préparent... -
sur Classification automatisée avec le plugin QGIS dzetsaka
Publié: 22 July 2022, 10:20am CEST
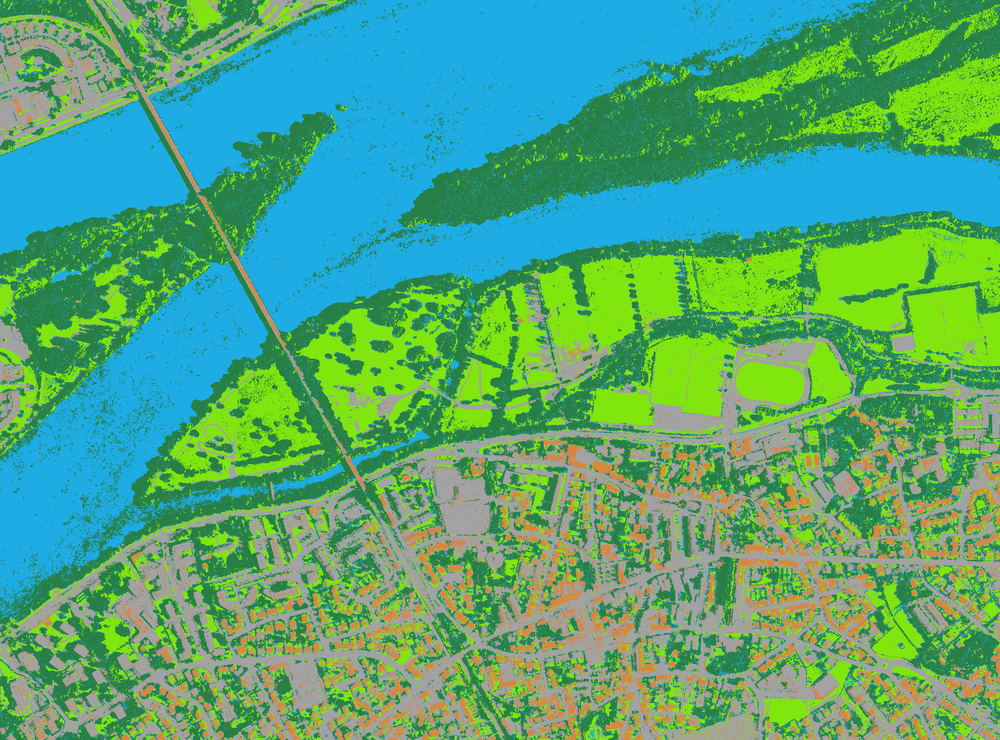 Présentation de Dzetsaka, un plugin QGIS pour faire de la classification semi-automatisée.
Présentation de Dzetsaka, un plugin QGIS pour faire de la classification semi-automatisée. -
sur Réaliser une carte comme la couverture de l'album Unknow Pleasures de Joy Division
Publié: 11 July 2022, 8:00pm CEST
 Comment faire des cartes à la mode de Joy Division avec les générateurs de géométrie de QGIS
Comment faire des cartes à la mode de Joy Division avec les générateurs de géométrie de QGIS
-
sur Cartes et géomatique : les articles 2016 sont en ligne
Publié: 31 May 2022, 6:41pm CEST par Lucile Haguet
Cartes & Géomatique précédemment Le Monde des cartes est une publication trimestrielle du Comité français de cartographie. Les articles de la revue sont publiés sur le site du CFC un an après leur publication sur support papier. Ne sont recensés ici que les articles en histoire de la cartographie.
n° 228, juin 2016 : “Cartographie et traités de paix (XVe-XXe siècle)” (actes du colloque des 19 et 20 novembre 2015, Archives diplomatiques, La Courneuve)Introduction (Isabelle Warmoes, Catherine Hofmann, Isabelle Nathan)
Entre la liste et le terrain, la carte dans les négociations de paix au XVe siècle (Dauphiné et Savoie, France et Bourgogne) (Léonard Dauphant)
Les cartes au service de la diplomatie (Jean-François Moufflet)
La rectification de la frontière du nord en 1779, sur le terrain, à La Flamengrie (Jean-Louis Renteux)
Une frontière pour les Pyrénées : l’épisode trop méconnu de la commission topographique franco-espagnole Caro-Ornano (1784-1792) (Jean-Yves Puyo, Jacobo García Álvarez)
La frontière franco-italienne sous le Consulat et l’Empire (Michel Lechevalier)
Le géographe Kiepert et les Balkans à Berlin (1878) (Goran Sekulovski)
Cartes topographiques et détermination des frontières en zones montagneuses (Nicolas Jacob)
La délimitation des frontières maritimes – Le rôle du cartographe, principes généraux, cas d’école (Eric van Lauwe, Didier Ortolland, Jean-Pierre Pirat)
Les limites de la carte, objet juridique (Françoise Janin)
L’expertise territoriale des vaincus austro-hongrois (Nicolas Ginsburger)
Le plébiscite de Klagenfurt du 10 octobre 1920 (Roseline Salmon)
Cartes et contre-cartes à la conférence de paix de Paris (1919-1920) : débats cartographiques au sein de la délégation britannique (Daniel Foliard)
De l’Empire ottoman au chaos moyen-oriental (Denis Bauchard)
-
sur Appel à communications : « L’histoire de la cartographie et son écriture à l’épreuve du renouvellement » – Date butoir : 6 juin 2022
Publié: 25 April 2022, 7:28pm CEST par Catherine Hofmann
Journée d’études
Le vendredi 25 novembre 2022, salle 100, Centre des colloques, Campus Condorcet, Aubervilliers
Organisateur : Comité Français de Cartographie (commission ‘histoire’)

Argumentaire :
Depuis les années 1980, l’histoire de la cartographie a vu ses concepts, ses objets, ses méthodes d’investigation et ses manières d’écrire se transformer profondément. Sous l’influence des analyses de John Brian Harley et de quelques autres (D. Wood, C. Jacob, M. Monmonier, J. Schulz, J. Black, M. Edney, entre autres), l’intérêt s’est porté vers la dimension symbolique des cartes, leurs modes de présence dans les cultures visuelles modernes, leur valeur politique et sociale (en particulier dans le cadre de l’affirmation des États-nations), leurs implications multiples dans les entreprises impériales et coloniales, etc., dans un effort général pour s’éloigner d’une approche strictement positiviste et « naturaliste » de la cartographie et de son histoire. Une nouvelle manière d’écrire l’histoire de la cartographie s’est progressivement installée, attentive aux contextes sociaux et culturels de la fabrication et de l’usage des cartes, aux jeux d’échelles (du général au particulier), et soucieuse d’envisager désormais la cartographie tout autant du côté des processus et des opérations (techniques, scientifiques, politiques, etc.) dont elle est le théâtre permanent, que du côté des objets, des productions et des acteurs plus ou moins prestigieux sur lesquels la recherche se focalisait naguère encore.
La journée d’étude organisée par la Commission « Histoire » du Comité Français de Cartographie propose de revenir sur les formes et les objets de l’écriture de l’histoire de la cartographie considérée dans un temps long. On insistera surtout sur la période contemporaine, en relation au renouvellement actuel des outils, notamment numériques.
Les contributions attendues peuvent répondre à l’une des trois directions suivantes :
– La première porte sur l’héritage des écrits de John Brian Harley, quarante ans après la publication de ses premiers travaux, et plus généralement sur l’ensemble des propositions qui ont marqué les approches « déconstructionnistes » dans l’histoire récente de la cartographie. Quel bilan peut-on en tirer, du point de vue des enseignements et des expériences en matière d’écriture historiographique ? A quelles négociations ces travaux ont-ils donné lieu pour concilier la tension entre la lecture internaliste et l’approche culturelle et sociale des objets cartographiques ? Comment ont-ils renouvelé l’étude de l’histoire de la cartographie et de ses acteurs ? Quelle place doit-on accorder aujourd’hui, à l’« analyse processuelle » (étude des processus cartographiques ) telle qu’elle est proposée par Matthew Edney par exemple ?
– La seconde direction proposée consiste à envisager la cartographie et son histoire en la confrontant de façon élargie aux apports récents des sciences sociales, de l’histoire des arts et de la littérature, de l’anthropologie visuelle et des médias, ainsi qu’aux perspectives ouvertes dans le champ spécifique des disciplines historiques par la micro-histoire, l’histoire globale, l’histoire matérielle, etc. En quoi l’écriture de l’histoire de la cartographie peut-elle être affectée par ces nouvelles manières d’envisager l’histoire des sociétés et de leurs cultures spatiales ? Comment, et jusqu’où, peut-elle répondre à ces sollicitations et se les approprier ? Qu’a-t-elle, symétriquement, à proposer, à apporter, notamment pour ce qui concerne le renouvellement des paradigmes spatiaux en cours au sein des sciences sociales et de l’histoire ?
– Mais l’histoire de la cartographie a une histoire, à la fois passée et très actuelle. Dans une troisième direction de réflexion, on aimerait alors envisager l’histoire de la cartographie, d’une part du point de vue des récits dont elle a été l’objet depuis au moins le XVIIIe siècle, et d’autre part du point de vue de l’impact, a priori considérable, provoqué par l’introduction des outils numériques, sur la reconfiguration de ces récits. Comment l’histoire de la cartographie a-t-elle été racontée, par les cartographes et par d’autres, du XVIIIe au XXe siècle, avec quelles motivations, quelles visées, scientifiques ou politiques ? Comment, aujourd’hui, à l’époque de la dématérialisation des objets cartographiques, et de leurs mises en relation avec les autres formes de l’économie iconographique, est-il possible de parler encore d’histoire de la cartographie stricto sensu ?
Modalités pratiques
• Les propositions de communication (environ 1500 signes), accompagnées d’une courte bio-bibliographie, sont à envoyer avant le 6 juin 2022 à l’adresse suivante : catherine.hofmann@bnf.fr.
• Le comité de sélection communiquera les résultats de l’appel à communications au plus tard le 30 juin 2022.
• Les communications retenues auront vocation à être publiées dans un numéro de la revue du Comité français de cartographie, Cartes & Géomatique, au courant de l’année 2023.
-
sur Cartes et géomatique : les articles 2017 sont en ligne
Publié: 31 March 2022, 6:23pm CEST par Lucile Haguet
Cartes & Géomatique précédemment Le Monde des Cartes est une publication trimestrielle du Comité Francais de Cartographie. Les articles de la revue sont mis en ligne sur le site du CFC un an après leur publication sur support papier. Ne sont recensés ici que les articles en histoire de la cartographie.
n° 234, décembre 2017 : “A l’échelle du monde – La carte : objet culturel, social et politique, du Moyen Age à nos jours” (actes du colloque d’Albi les 17 et 18 octobre 2016)Bulletin 234 – Introduction (Thibault Courcelle, Emmanuelle Vagnon, Sandrine Victor)
La mappemonde d’Albi – Un pinax chôrographikos (Anca Dan)
La carte comme substitut au voyage (Nathalie Bouloux)
Représenter et décrire l’espace maritime dans le califat fatimide (David Bramoullé)
Quand le cartographe parle de sa carte (Jean-Charles Ducène)
Une cartographie des Lumières (Gilles Palsky)
Penser à l’échelle du monde pour maîtriser le temps en France et en Grande-Bretagne, 1870-1914 (Isabelle Avila)
Un autre monde ? (Clarisse Didelon-Loiseau, Christian Vandermotten, Christian Dessouroux)
Regards croisés sur la création des cartes à l’échelle du monde aujourd’hui (Thibault Courcelle, Emmanuelle Vagnon, Sandrine Victor)