
Vous pouvez lire le billet sur le blog La Minute pour plus d'informations sur les RSS !
Canaux
5368 éléments (0 non lus) dans 55 canaux
-
 Cybergeo
Cybergeo
-
Revue Internationale de Géomatique (RIG)
-
SIGMAG & SIGTV.FR - Un autre regard sur la géomatique
-
Mappemonde
-
Dans les algorithmes
-
Imagerie Géospatiale
-
Toute l’actualité des Geoservices de l'IGN
-
arcOrama, un blog sur les SIG, ceux d ESRI en particulier
-
arcOpole - Actualités du Programme
-
Géoclip, le générateur d'observatoires cartographiques
-
Blog GEOCONCEPT FR
-
Géoblogs (GeoRezo.net)
-
Conseil national de l'information géolocalisée
-
 Geotribu
Geotribu
-
Les cafés géographiques
-
UrbaLine (le blog d'Aline sur l'urba, la géomatique, et l'habitat)
-
Icem7
-
Séries temporelles (CESBIO)
-
Datafoncier, données pour les territoires (Cerema)
-
Cartes et figures du monde
-
SIGEA: actualités des SIG pour l'enseignement agricole
-
Data and GIS tips
-
Neogeo Technologies
-
ReLucBlog
-
L'Atelier de Cartographie
-
My Geomatic
-
archeomatic (le blog d'un archéologue à l’INRAP)
-
Cartographies numériques
-
Veille cartographie
-
Makina Corpus
-
Oslandia
-
Camptocamp
-
Carnet (neo)cartographique
-
Le blog de Geomatys
-
GEOMATIQUE
-
Geomatick
-
CartONG (actualités)

 Toile géomatique francophone
Toile géomatique francophone
-
 15:47
15:47 Quelle stratification des forêts du Bassin du Congo ?
sur Carnet (neo)cartographiqueVue la déforestation en cours dans les pays du Bassin du Congo, les paysages forestiers ne sont plus considérés comme intacts et leur diminution est hélas actée.
On peut néanmoins s’intéresser à la structure des forêts rémanente pour en proposer une typologie spatiale, ce que les spécialistes appellent une « stratification ». Pour en savoir plus, j’ai mobilisé les données du GLAD (2021) qui sont disponibles sur l’ensemble du monde, mais je les ai limitées à l’Afrique, focalisant mon attention sur le Bassin du Congo.
J’ai mobilisé ces données et les analyses publiées associées, en les traduisant en français et en les adaptant pour les besoins de ce billet. Voir la liste des sources et références consultées.La stratification du couvert forestier a pour objectif de délimiter des régions forestières – en l’occurrence « des strates » – qui sont associées à différentes valeurs de référence du stock de carbone.
L’estimation de la perte de carbone aérien, due aux dommages des forêts tropicales, s’appuie en effet sur la mesure de la diminution ou de la perte de couvert forestier. L’une des manières de s’en rendre compte est d’en faire la cartographie à l’aide d’images satellites. Hansen et al. (2013) ont ainsi réalisé une telle cartographie des pertes du couvert forestier à 30 m de résolution spatiale, que les spécialistes considèrent comme une référence en la matière.
Cependant, le fait que les autres cartographies cohérentes des différents types de forêts (tropicales et pan-tropicales) ne soient pas disponibles à 30 m près impose de caractériser autrement le couvert forestier, à mobiliser en l’occurence plusieurs paramètres pour aboutir à des définitions complexes des différents strates.
La classification des forêts réalisée par Potapov et al. (2012) à l’échelle nationale, conduit à une typologie identifiant des « forêts primaires », des « forêts secondaires », des « zones boisées », qu’il est difficile de reproduire à l’échelle d’un biome puisque les niveaux d’observation diffèrent fondamentalement.
A noter que cette stratification n’est pas sans lien avec l’estimation des paysages forestiers intacts (PFI) dont on a déjà parlé ici, puisque les PFI correspondent aux strates de forêts denses et hautes, denses

La classification des forêts réalisées par Potapov et al. (2012) n’étant pas applicables au niveau local, les stratifications de forêts pan tropicales qui existent – telles celles du GLAD (2021) utilisées ici – ont été définies en utilisant les caractéristiques structurelles des forêts estimées à partir d’analyses statistiques d’images satellites de la canopée. Ont ainsi été mobilisées la méthode de Hansen et al (2013) qui permet d’estimer le pourcentage de couverture de la canopée en 2000, ainsi que celle de Potapov et al (2008) mesurant la hauteur des arbres et le degré d’intégrité de la forêt.
Des seuils de stratification minimisant la variance intra strate sont définis, grâce à une régression fondée sur des estimations ponctuelles du carbone GLAS, comme variable dépendante (Baccini et al., 2012), pour aboutir à la cartographie suivante.

Cette carte permettant de caractériser plus finement la structure du couvert forestier intact.
Sources :
Global land analysis and discovery (GLAD), University of Maryland, Department of Geographical Sciences, 2021.
Fonds de carte : NaturalEarth data, 2023.Références :
Baccini A. et al. 2012, Estimated carbon dioxide emissions from tropical deforestation improved by carbon-density maps Nature Climate Change 2 182-5.
Hansen M.C. et al. 2013, High-resolution global maps of 21-st century forest cover change Science 342 850-3. Potapov P.V. et al. 2008, Mapping the world’s Intact Forest Landscapes by remote sensing. Ecology and Society 13 51.
Potapov P.V. et al. 2012, Quantifying forest cover loss in Democratic Republic of the Congo, 2000-2010, with Landsat ETM+ data Remote Sensing of Environment 122 106-16.
Billets liés :
– Que reste t-il de nos forêts ?
– Contribution des pays du Bassin du Congo à la déforestationGéographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.

-
17:00
QGIS pour afficher des données télémétriques géospatiales
sur OslandiaContexteNous en avions déjà parlé dans un précédent article : l’Agence Spatiale Canadienne (ASC) supporte les vols de ballons stratosphériques ouverts (BSO), opérés en sol canadien, par le CNES. Certains de ces ballons volent à environ 40 km d’altitude dans des conditions proches de l’environnement spatial, d’autres volent plus bas dans l’atmosphère, et tous embarquent un grand nombre d’instruments de mesures et d’observation pouvant atteindre une masse de 800 kg. Une multitude d’organisations (laboratoires, établissements scolaires, industriels, etc), à travers le monde, utilisent de plus petits ballons (du type sondage météo) pour effectuer des expériences. La réglementation des vols de ballons non habité étant différente au Canada, l’ASC a entrepris, en 2018, de développer une plateforme rencontrant les exigences de leurs vols domestiques. Pour suivre ces ballons, leurs données sont transmises à un satellite Iridium, qui les envoie à un serveur sur Terre, où on les récupère.
Ce serveur reçoit donc une trentaine de variables comme la localisation (lat, long), l’altitude, la vitesse, la pression atmosphérique, la température, la tension des batteries etc.
Lors de nos précédents travaux, nous avions construit une preuve de concept, et en concertation avec l’ASC avons décidé d’une autre modalité de représentation de l’information en repartant d’une interface déjà développée par leurs soins. Nous avons transformé l’interface permettant de consulter la télémétrie sans dimension cartographique, en plugin QGIS et l’avons fait évoluer pour visualiser au même endroit les données télémétriques, la position en temps réel et des courbes retraçant l’évolution temporelle de certaines données.
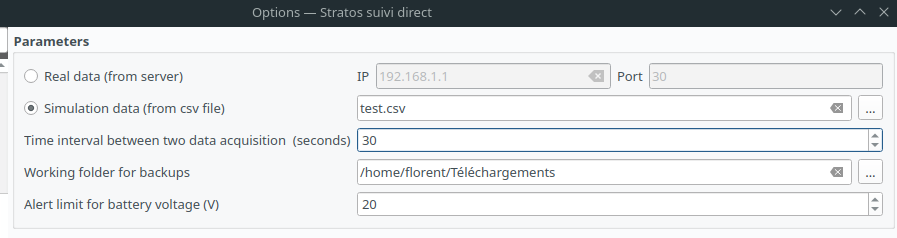
FonctionnalitésLe plugin effectue donc la collecte des données de télémétrie. Il faut dans un premier temps récupérer la donnée et la parser : il s’agit de chaînes de caractères à séparer selon un délimiteur et des longueurs spécifiques.
Deux modes d’acquisition des données sont possibles :- Un mode réel où il faut renseigner l’adresse IP et le port du serveur où récupérer les données
- Un mode simulation où il faut renseigner un fichier CSV contenant des données simulant un vol, ou reprenant des vols précédents
Il est possible de mettre l’acquisition en pause et de réinitialiser l’interface.
Enfin, dans les paramètres, il est possible de saisir un seuil d’alerte pour le voltage de la batterie, en-dessous duquel l’utilisateur sera alerté :
 Les données acquises sont présentées dans 3 zones différentes dans l’interface de QGIS :
Les données acquises sont présentées dans 3 zones différentes dans l’interface de QGIS :
- Une colonne (à droite) qui liste toutes les données recueillies
- Un bloc (en bas) dans lequel on trouve différentes courbes (tension de la batterie, altitude, pression et température)
- Et la carte sur laquelle s’affiche le parcours du ballon, avec deux options de zoom possibles :
- Zoom sur la dernière position du ballon
- Zoom sur l’intégralité de la trace
Une fois l’acquisition terminée, les données sont enregistrées dans le dossier précisé dans les paramètres du plugin, partagées dans un fichier CSV pour les données brutes, et dans un Shapefile pour les données géographiques.
Démonstration vidéo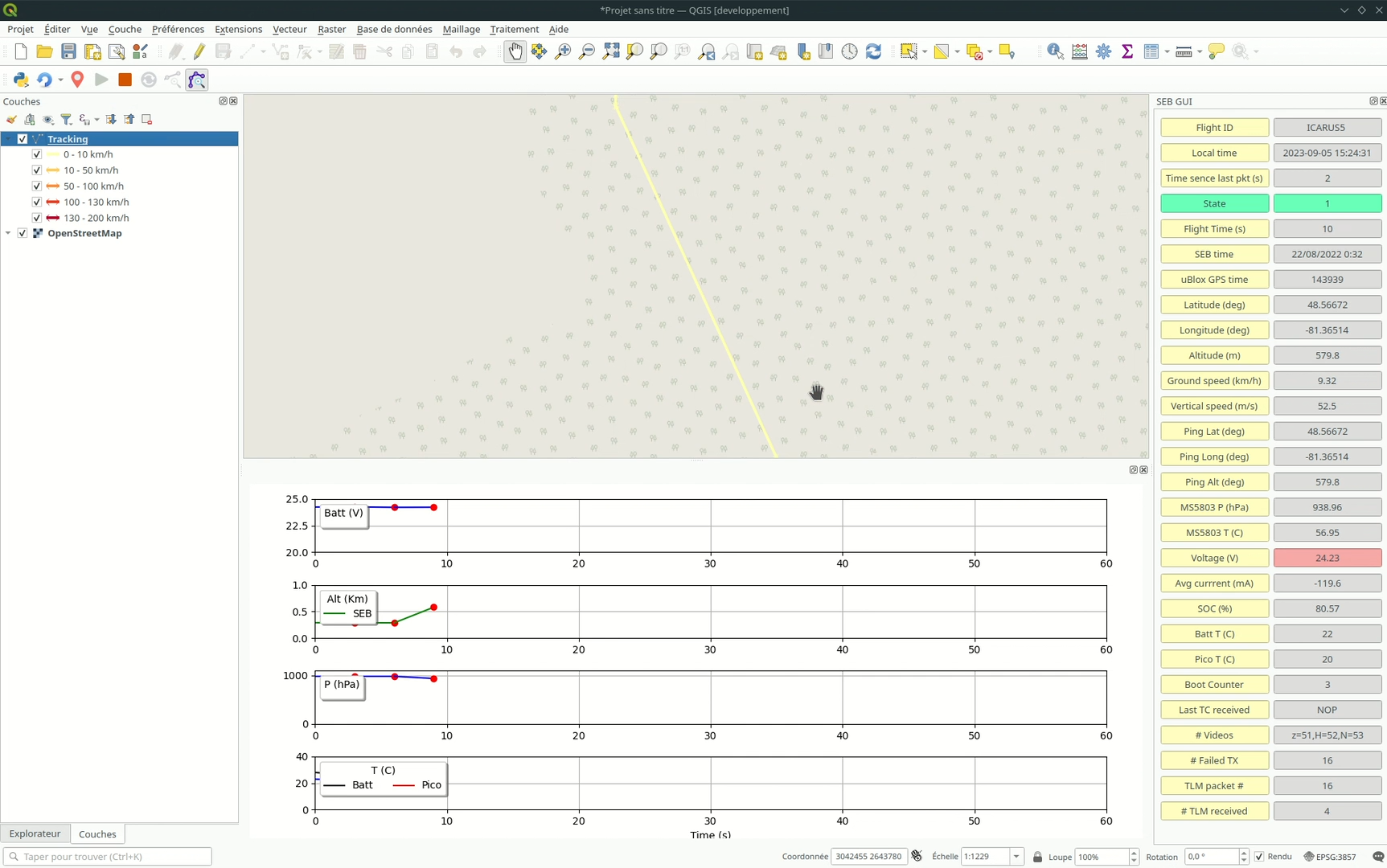
-
13:57
Inscrivez-vous à la conférence "Noms de lieux étrangers : enjeux culturels pour les uns, politiques pour les autres" le 4 octobre 2023
sur Conseil national de l'information géolocaliséeLe CNIG vous invite à participer le 4 octobre de 11h00 à 12h00 à la conférence en ligne
"Introduction à l'exonymie : entre enjeux culturels et souveraineté"
-
13:49
GEO.be : la plateforme open data Belge
sur Veille cartographieCet article GEO.be : la plateforme open data Belge est apparu en premier sur Veille cartographique 2.0.
La France possède une base de données accessible par tout le monde et qui regroupe des données approuvées par le gouvernement: datagouv, qui se divise en plusieurs catégories selon les domaines: urbanisme, environnement, écologie… Cependant, cela existe également dans les autres pays comme en Belgique, un pays francophone. Ce dernier met à disposition de ses […]
Cet article GEO.be : la plateforme open data Belge est apparu en premier sur Veille cartographique 2.0.
-
14:44
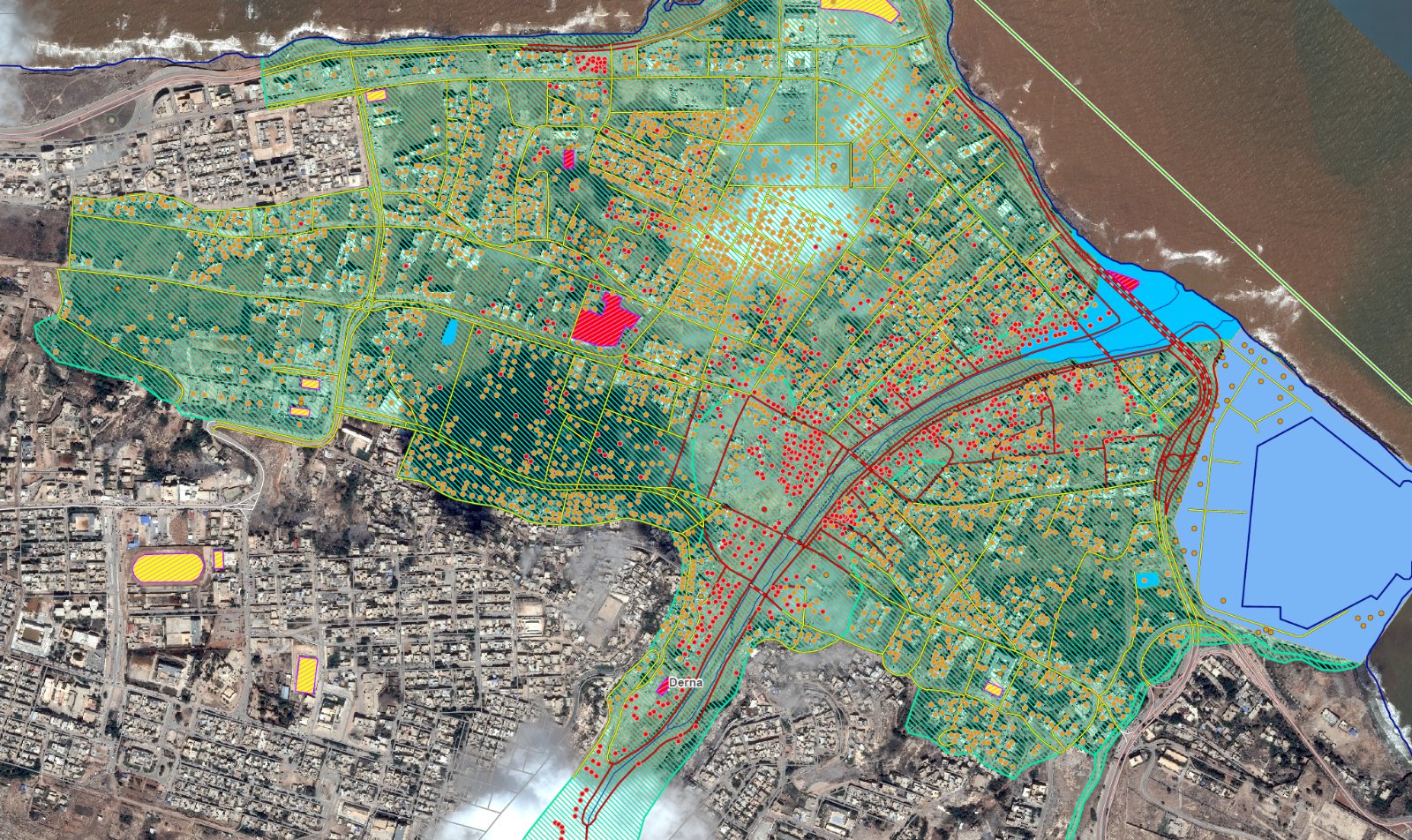
Cartes et données sur les inondations en Libye (catastrophe de Derna)
sur Cartographies numériques
La tempête Daniel, qui a frappé dans la nuit du 10 au 11 septembre 2023 la ville de Derna (100 000 habitants) au nord-est de la Lybie, a entraîné la rupture de deux barrages en amont provoquant une crue de l’ampleur d’un « tsunami » le long de l’oued qui traverse la cité. Le bilan provisoire s'établit à plus de 11 300 morts au 18 septembre 2023. Selon les experts, la situation sociale, économique et politique difficile du pays a contribué à ce lourd bilan humain. Une situation de chaos qui limite les capacités de prévision des services météorologiques locaux et des systèmes d'alerte et d'évacuation.
Inondations en Libye - EMSR696 (Situational reporting Copernicus Emergency Management Service)
1) Traitement médiatique de la catastrophe« Libye : des inondations dans l'est provoquent des milliers de morts » (RFI). Le gouvernement de l'est libyen, désigné par le Parlement et non reconnu par la communauté internationale, a décrété un deuil national de trois jours, suite à la tempête Daniel qui, après la Grèce, la Turquie et la Bulgarie, a fortement affecté la Libye (voir l'animation de cette tempête).
« Avant/Après : les images impressionnantes des inondations en Libye » (Le Figaro). Vue du ciel, la catastrophe naturelle est impressionnante. Une très large partie de Derna est sous les eaux. Le wadi Derna, un simple petit cours d’eau, s’est transformé en une vague semblable à un « tsunami » d’après plusieurs témoins. La cité a été submergée par des vagues de 7 mètres de haut qui ont tout détruit sur leur passage en emportant les voitures et les maisons. « Avant / Après Inondations en Libye : découvrez l’ampleur des dégâts vus du ciel » (Ouest France).
« Inondations en Libye : à Derna, le nombre de morts est toujours incertain » (Le Monde). Selon l’Organisation internationale pour les migrations (OIM), au moins 30 000 personnes qui vivaient dans cette cité de 100 000 habitants ont été déplacées. Une partie des 10 000 disparus après les inondations à Derna pourraient se trouver en mer, ils ont été emportés vers la mer pendant les inondations. La mer rejette leurs corps vers les plages.
« Comment expliquer les inondations monstres qui touchent le pays ? » (BFM-TV). La tempête Daniel s'est transformée en un cyclone subtropical méditerranéen. Ce sont deux facteurs qui semblent s'être combinés pour recharger le système à bloc. La hausse des températures de l'air sous l'effet du réchauffement climatique qui rend l'air plus humide. Et la hausse des températures des océans. Une mer Méditerranée plus chaude et qui s'évapore plus a donc alimenté la puissance du medicane Daniel. « Pourquoi la tempête Daniel a été aussi dévastatrice en Libye ? » (Futura Science).
« Qu’est-ce qu’un medicane, ce phénomène météo responsable des inondations meurtrières en Libye ? » (Le Parisien) Les météorologues appellent ce phénomène un medicane (contraction de "hurricane" et "Méditerranée"). Ce phénomène hybride présente certaines caractéristiques d'un cyclone tropical et d'autres d'une tempête des latitudes moyennes.
« Inondations en Libye : les deux barrages de Derna étaient fissurés » (Euronews). Dans une étude publiée en novembre 2022, l'ingénieur et universitaire libyen Abdel-Wanis Ashour a mis en garde contre une "catastrophe" menaçant Derna si les autorités ne procèdent pas à l'entretien des deux barrages. Malgré cet avertissement, aucuns travaux n'ont été menés.
« Dans une Libye corrompue, les alertes concernant le délabrement des barrages de Derna restées lettre morte » (Le Monde). Un rapport du groupe d’experts de l’ONU avait déjà dénoncé le comportement « prédateur » des groupes et milices qui se disputent le pouvoir depuis plus de dix ans et ont entraîné « le détournement des fonds de l’Etat libyen et la détérioration des institutions et des infrastructures ». Des militants de la société civile demandent une enquête internationale, craignant que les investigations locales ne puissent être fructueuses dans un pays largement gouverné par des groupes armés et des milices.
« Inondations en Libye : des barrages fragilisés par des années de négligences » (Libération). Les deux barrages avaient été construits dans les années 70 par une entreprise yougoslave non pas pour collecter de l’eau mais pour protéger Derna des inondations. Nonobstant les moyens financiers dont dispose le premier pays pétrolier d’Afrique, les travaux n’ont pas été entrepris.
« L'ONU et l'OMS préoccupées par les risques de maladies » (RFI). À Derna, dans l'est de la Libye, une semaine après les inondations dévastatrices provoquées par la tempête Daniel, un très grand nombre de corps se trouve encore sous les décombres. Cette situation représente une menace pour l'hygiène. Sur place, les agences de l'ONU tentent de prévenir la propagation de maladies.
« Les enfants de Libye sont confrontés à une nouvelle tragédie après plus d’une décennie de conflit » (UNICEF). On estime que près de 300 000 enfants ont été exposés à la puissante tempête. Au-delà des risques immédiats de morts et de blessés, les inondations en Libye présentent un risque grave pour la santé et la sécurité des enfants. Avec des approvisionnements en eau potable compromis, les risques d’épidémies de diarrhée et de choléra, ainsi que de déshydratation et de malnutrition, augmentent considérablement. Parallèlement, les enfants qui perdent leurs parents ou sont séparés de leur famille sont plus exposés aux risques de protection, notamment à la violence et à l’exploitation.
« Les inondations en Libye laissent l'ancienne Cyrène meurtrie et menacée de pillage » (Middle East Eye). Des eaux torrentielles et des glissements de terrain ont emporté certaines antiquités du site du patrimoine mondial de l'UNESCO tout en en exposant d'autres pour la première fois.
2) Pistes d'analyse en termes d'aléa / risque / vulnérabilité et enjeux
« Inondations en Libye : un désastre humanitaire sur fond de crise politique » (France Culture). C’est dans la province agricole de Cyrénaïque, située à l’est du pays, que les inondations ont été les plus meurtrières. La municipalité de Derna, qui souffrait déjà d'un manque d'infrastructures, a vu disparaître dans la mer un quart de son territoire en quelques heures. Jalel Harchaoui, spécialiste de la Libye et chercheur au Royal United Service Institute, rappelle la situation difficile que connaît cette ville depuis une dizaine d’années : « c’est une ville qui a un historique politique tout à fait particulier, qui est marginalisée par rapport au reste de la Cyrénaïque. Elle a été le lieu d’un siège imposé par le maréchal Haftar de 2015 à 2019 et qui s'est achevé par une guerre civile. Depuis 2019, il n'y a pas d’infrastructures comme des hôpitaux ou des transports et les reconstructions ont été négligées. »
« L’interaction entre les précipitations, l’exposition et la vulnérabilité exacerbées par le changement climatique a entraîné des impacts généralisés dans la région méditerranéenne » (World Weather Attribution). Un événement aussi extrême que celui observé en Libye est devenu jusqu’à 50 fois plus probable et jusqu’à 50 % plus intense par rapport unréchauffement qui serait inférieur à 1,2°C. Outre le manque d’entretien, les barrages d’Al-Bilad et d’Abu Mansour ont été construits dans les années 1970, sur la base de précipitations relativement courtes, et n’ont peut-être pas été conçus pour résister à un épisode de pluie sur 300 à 600 ans. Un examen complet portant sur les critères de conception des barrages sera nécessaire pour comprendre dans quelle mesure la conception des barrages et le manque d'entretien ultérieur ont contribué à la catastrophe.
« Les inondations en Libye montrent la nécessité d’alertes multirisques précoces et d’une réponse unifiée » (déclaration du Secrétaire général de l'Organisation Météorologique Mondiale). Le patron de l’OMM qui dépend de l’ONU, Petteri Taalas, a estimé que « la plupart des victimes auraient pu être évitées » pointant du doigt la désorganisation liée à l’instabilité politique dans le pays. L'agence météorologique libyenne a émis des avis d'alerte trois jours avant et l'état d'urgence a été déclaré dans certaines parties de l'est de la Libye.
« Les faits sont clairs. Les alertes précoces sauvent des vies et génèrent d’énormes avantages financiers. J’exhorte tous les gouvernements, institutions financières et société civile à soutenir cet effort » (secrétaire général de l’ONU, António Guterres). Voir le plan publié par l'ONU Alertes précoces pour tous. Plan d'action exécutif 2023-2027. Qu’il concerne les crues, les sécheresses, les vagues de chaleur, ou les tempêtes, un système d’alerte précoce est un système intégré qui permet d’être prévenu de l’approche de conditions météorologiques dangereuses et éclaire sur ce que les pouvoirs publics, la collectivité et les individus peuvent faire pour atténuer le choc de leurs effets imminents.
Ksenia Chmutina & Jason von Meding (2019). A Dilemma of Language : “Natural Disasters”. International Journal of Disaster Risk Science. A propos des catastrophes dites "naturelles" : même si les dangers sont naturels, les catastrophes ne le sont pas. Cet article soutient qu’en rejetant continuellement la faute sur la « nature » et en imputant la responsabilité des échecs du développement à des phénomènes naturels « exceptionnels » ou à des « cas de force majeure », on accepte de ceux qui sont à l'origine des catastrophes qu'ils se satisfassent d'une mauvaise planification urbaine, d'inégalités socio-économiques, de politiques mal réglementées, d'un manque d’adaptation et d’atténuation proactives, autant de facteurs qui augmentent la vulnérabilité.
Introduire le chapitre « Les sociétés face aux risques » en Seconde par les inondations en Libye (académie de Normandie). Les notions de « catastrophe naturelle » (tempête) et « technologique » (rupture de barrage) sont abordées, ainsi que celle d’« aléa ». Aussi, la notion de « prévention » peut être approchée en évoquant le rôle des barrages qui étaient censés protéger la ville, mais trop vétustes et mal entretenus.Ici, les notions qui peuvent être approchées sont celles de « pays en développement », « crise », « résilience », « culture du risque »…3) Cartes et données SIG à visualiser en ligne ou à télécharger
Libye : les dégâts dans la ville de Derna et le barrage détruit vus par le satellite Pléiades Neo (Un autre regard sur la Terre). « J’ai vu beaucoup d’images de catastrophes. Celle de Derna est vraiment sidérante. J’ai ressenti la même sidération pour des désastres comme le tsunami de l’océan indien en 2004, l'ouragan Katrina en 2005 ou le tremblement de Terre d’Haïti en 2010 » (@RegardSurTerre). Voir ce fil twitter de @MagaliReghezza qui montre que le séismé d'Haïti était encore d'une autre ampleur.
Images satellites Maxar et Planet des inondations (Geospatial World). Segmentation automatique des images satellite du programme Maxar Open Data (Samgeo).
Cartes et données SIG élaborées par le Service de gestion des urgences CopernicusEMS (dégâts estimés à partir de l'observation d'images satellites). Voir également les zones impactées par la tempête Daniel en Grèce avec l'animation satellite.
Atlas de la mortalité et des pertes économiques dues à des phénomènes météorologiques, climatiques et hydrologiques extrêmes 1970-2019 (Organisation météorologique mondiale) à télécharger en pdf.
4) Utilisation de la cartographie pour organiser l'aide humanitaire
Inondations en Libye en 2023 - Aperçu de la situation d'urgence (Reliefweb). La tempête Daniel a provoqué des inondations à grande échelle dans le nord-est de la Libye, entraînant des pertes de vies humaines et des dégâts aux infrastructures dans plusieurs villes côtières et le long des rivières, notamment Benghazi, Al-Jabal Al-Akhder, Al-Marj, Batah, Bayada, Albayda, Shahat et Sousse. La ville de Derna semble être durement touchée après la rupture de deux barrages en amont, libérant plus de 30 millions de mètres cubes d'eau dans la ville de Derna. Les premiers rapports suggèrent d'importants dégâts aux logements et aux infrastructures critiques. La tempête a exacerbé les problèmes d'accès à l'eau potable et aux soins de santé. Les zones touchées sont désormais confrontées à des risques plus élevés de maladies infectieuses en raison de services de santé perturbés, des réseaux d'égouts endommagés, de la persistance des eaux de crue et de la boue.
Empreinte des bâtiments de la zone touchée par les inondations à Derna (Google Buildings). Les empreintes des bâtiments sont utiles pour toute une une gamme d’applications, depuis l’estimation de la population, la planification urbaine et la réponse humanitaire, jusqu’aux sciences du climat et de l’environnement. Cet ensemble de données ouvertes à grande échelle contient les contours des bâtiments dérivés de données en haute résolution. Fichiers geojson ou csv à télécharger directement.
Données SIG sur la Libye mises à disposition par Humanitarian Data Exchange (HDX), site dédié au partage de données humanitaires.
Articles connexes
Tempête Alex et inondations dans les Alpes maritimes : accès aux cartes et aux images satellitaires
Cartographier la trajectoire des cyclones avec des données en temps réel
Cartes et données sur les séismes en Turquie et en Syrie (février 2023)
Cartes et données sur les tremblements de terre au Japon depuis 1923
Simuler des scénarios de tremblement de terre en utilisant des cartes
Cartes-posters sur les tsunamis, tremblements de terre et éruptions volcaniques dans le monde (NOOA, 2022)
Analyser et discuter les cartes de risques : exemple à partir de l'Indice mondial des risques climatiques
L'évolution de la cartographie humanitaire au sein de la communauté OpenStreetMap
-
13:00
Géonature : des applications Web et mobiles au service de la faune et de la flore
sur Veille cartographieCet article Géonature : des applications Web et mobiles au service de la faune et de la flore est apparu en premier sur Veille cartographique 2.0.
Le site Géonature propose un ensemble d’outils permettant de saisir, gérer et diffuser les données autour de l’observation de la faune et de la flore. Il propose aux utilisateurs un ensemble de protocoles le permettant et tous disponible en open source. Ces services sont proposés par une collaboration entre les parcs nationaux de France mais […]
Cet article Géonature : des applications Web et mobiles au service de la faune et de la flore est apparu en premier sur Veille cartographique 2.0.
-
10:43
cocarto, un SIG de collaboration en ligne
sur Veille cartographieCet article cocarto, un SIG de collaboration en ligne est apparu en premier sur Veille cartographique 2.0.
La suite ESRI particulièrement la partie online (web) nous offre la possibilité de créer des cartes et des applications cartographiques (Dashboard, web applications, sites…) et de pouvoir les partager avec d’autres utilisateurs de son organisation – ou de toute autre structure. Elle demeure, toutefois, plus destinée à des utilisateurs plus ou moins expérimentés vis-à-vis de […]
Cet article cocarto, un SIG de collaboration en ligne est apparu en premier sur Veille cartographique 2.0.
-
9:28
Étudier l'expansion de la Chine en Asie du Sud-Est à travers les caricatures de presse
sur Cartographies numériques
Les cartes humoristiques sont devenues assez courantes dans les médias et sur Internet. Le fil twitter ci-dessous donne des pistes de lecture concernant ces cartes-caricatures, que l'on retrouve souvent en illustrations dans les manuels scolaires. L'objectif est d'en décrypter les symboles et d'en donner une approche critique en confrontant les visions. A l'ère d'Internet et des réseaux sociaux, ces dessins humoristiques circulent de plus en plus. Ils renvoient souvent les uns aux autres dans un jeu de miroir complexe, de sorte qu'il n'est plus possible de les prendre isolément comme on le ferait dans un commentaire classique de document. L'expansion de la Chine en Asie du Sud-Est fournit un bon exemple pour étudier ces représentations et en dégager des visions géopolitiques.Les dessins de Nath Paresh reviennent souvent dans la presse. Il est caricaturiste au National Herald en Inde et ses dessins sont distribués aux États-Unis par Cagle Cartoons (vision indo-américaine) [https:]] pic.twitter.com/0Z5oFEfwrB
— Sylvain Genevois (@mirbole01) May 22, 2023
Les parties du corps émergées du dragon correspondent aux îlots convoités par la Chine. Assez intéressant de voir ici Taiwan assimilé aux îles de la mer de Chine méridionale. La caricature de Nath Paresh est reprise par un journal japonais [https:]]
— Sylvain Genevois (@mirbole01) May 22, 2023
Evolution de la situation géopolitique et de la réprésentation des menaces : l'enjeu n'est pas seulement militaire, il concerne aussi les activités de pêche (allusion ici à la rivalité sino-vietnamienne + incapacité de l'ASEAN à réguler les conflits) [https:]] pic.twitter.com/IAUxyJamyN
— Sylvain Genevois (@mirbole01) May 22, 2023
A confronter avec des dessins humoristiques permettant de jouer sur d'autres stéréotypes que le dragon : la muraille de Chine ou encore le panda... [https:]] [https:]] pic.twitter.com/8t4G1P83Nm
— Sylvain Genevois (@mirbole01) May 22, 2023
Les visions géopolitiques peuvent être intéressantes à décrypter à travers ces dessins humoristiques dès lors qu'on s'emploie à les contextualiser et en dégager des pistes d'interprétation en les confrontant [https:]] [https:]] pic.twitter.com/NW7KpEX1Uy
— Sylvain Genevois (@mirbole01) May 22, 2023
L'occasion de rappeler ce dessin satirique diffusé lors du G7 de 2021 où le sommet international était déjà accusé de vouloir réprimer la Chine. Voir la caricature et ses symboles décryptés sur ce site [https:]]
— Sylvain Genevois (@mirbole01) May 22, 2023
Tse Tsan-Tai a représenté chaque pays occidental par un animal pour en montrer la brutalité. Voir la lecture des symboles proposée par @Propagandopolis [https:]]
— Sylvain Genevois (@mirbole01) September 17, 2023
L'artiste hongkongais exilé Ah To a mis à jour cette carte « Situation en Extrême-Orient » pour refléter les réalités de 2022. Il peut être intéressant de comparer les symboles pour montrer le renversement de la situation géopolitique un siècle après [https:]] pic.twitter.com/mggBTjOdDE
— Sylvain Genevois (@mirbole01) September 17, 2023
La carte, objet éminemment politique. Les tensions géopolitiques entre Taïwan et la Chine
Articles connexes
La carte, objet éminemment politique : la Chine au coeur de la "guerre des cartes"
Etudier les densités en Chine en variant les modes de représentation cartographique
Comment la Chine finance des méga-projets dans le monde
L'histoire par les cartes : l'Asie du Sud-Est à travers des cartes japonaises de la 2e Guerre mondiale
Cartes anciennes sur l'Asie du Sud-Est (Yale-Nus College de Singapour)
Comment l'Asie perçoit le monde ? (France Culture)
Etudier les conflits maritimes en Asie en utilisant le site AMTI
Cartes et caricatures. Recension de cartes satiriques et de cartes de propagande
Les nouvelles façons de « faire mentir les cartes » à l’ère numérique
Jouer avec les stéréotypes en géographie, est-ce les renforcer ou aider à comprendre le monde ?
-
10:15
Appel à commentaires pour le standard Sites Économiques juqu'au 16 octobre 2023
sur Conseil national de l'information géolocaliséeAppel à commentaires pour le standard Sites Économiques juqu'au 16 octobre 2023
-
10:11
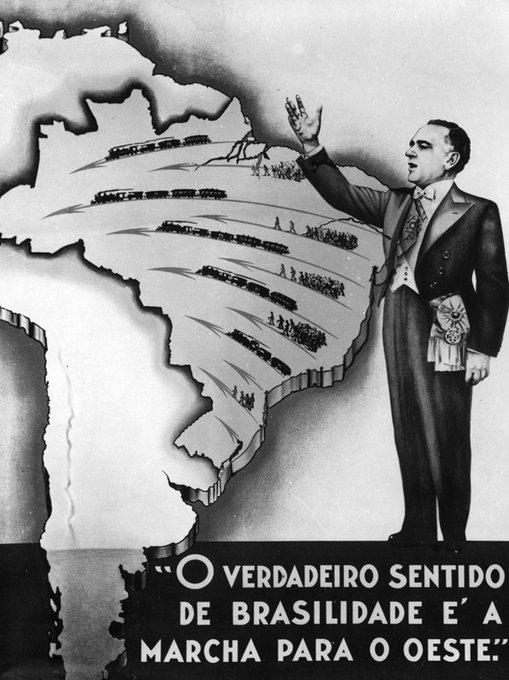
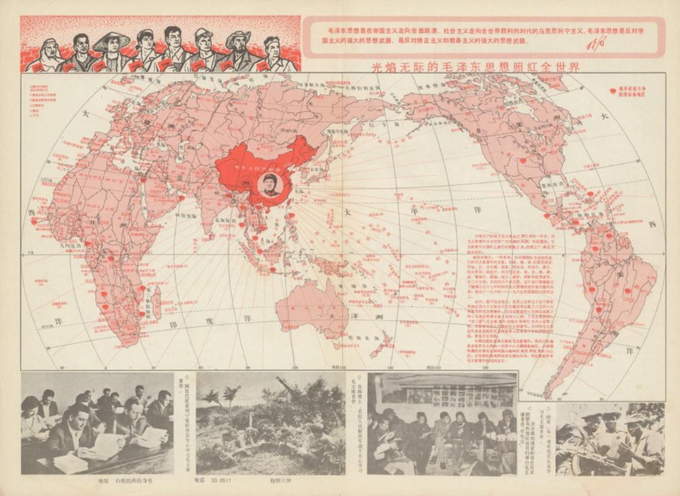
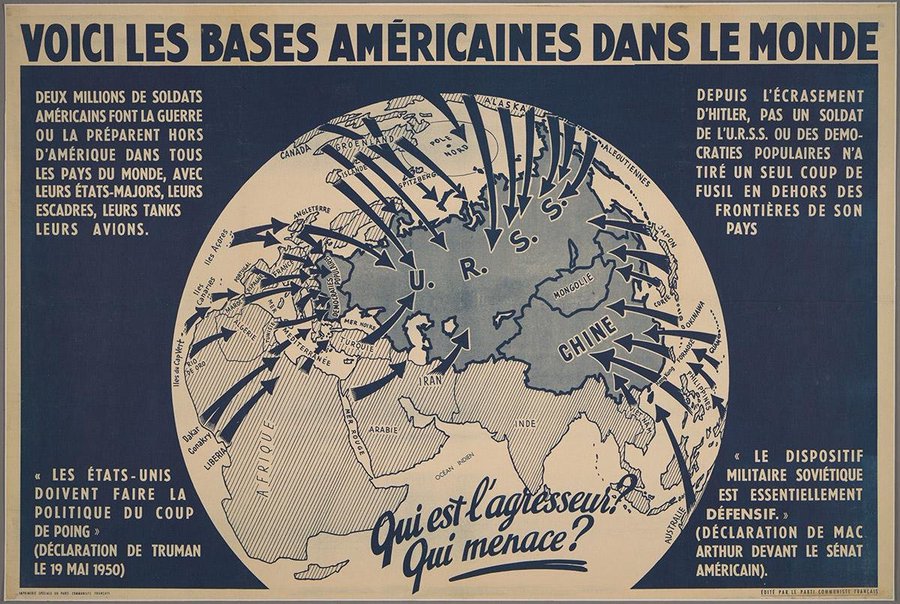
Cartes et caricatures. Recension de cartes satiriques et de cartes de propagande
sur Cartographies numériquesVous cherchez des images de propagande à base de cartes ? Cette page vous propose une recension de ressources sur Internet qui peuvent vous intéresser.
Le compte twitter @propagandopolis sélectionne et commente chaque semaine des images et des cartes historiques. Voir le site de l'auteur qui propose des cartes de propagande américaine et du monde entier : PropagandopolisLe site commercial Barron Maps propose une impressionnante série de cartes satiriques et de cartes de propagande. Roderick Barron (@barronmaps) est spécialisé dans le domaine des cartes de propagande et des cartes imaginaires. Il alimente un blog associé au site qui contient des articles de fond. Il y explore notamment le phénomène des cartes « sério-comiques » de la fin du XIXe et du début du XXe siècle (voir cette présentation vidéo en anglais). On y trouve les oeuvres de Fred W. Rose qui s'est rendu célèbre par ses cartes caricaturales de l’époque victorienne (avec des pieuvres).
La British Library propose également une belle recension de cartes satiriques du monde entier. La page d'accueil retrace la longue histoire des cartes satiriques depuis le XVIIe siècle jusqu'à nos jours, avec de nombreux exemples empruntés à différents pays et différentes époques.
Le site de la célèbre collection David Rumsey constitue une source de premier ordre. On peut y trouver toutes sortes de cartes satiriques, en utilisant son moteur de recherche interne (par exemple avec les mot-clés "propaganda" ou "satirical").
Le site Vividmaps a sélectionné des cartes satiriques de l'Europe, principalement du XIXe et du début XXe siècle (l'âge d'or des nationalismes ayant donné lieu à beaucoup de cartes de propagande). « L’Europe était le siège d’États puissants souvent en concurrence. Ils ont pris part à des guerres sanglantes et ont tissé des intrigues diplomatiques en coulisses. Dans cette confrontation, la satire était non seulement une forme d'art mais aussi une arme dangereuse, dont le but était de montrer à la population et à celle des autres pays qui est qui dans l'arène politique.»
Last but not the least. La formidable série de "cartes persuasives" de l'Université Cornell. « Plus de 800 ?cartes destinées avant tout à influer sur des opinions ou des croyances - à faire passer un message - plutôt qu'à communiquer une information géographique. La collection contient une grande variété de "cartes pour convaincre" : qu'il s'agisse de la cartographie allégorique, satirique ou picturale, de choix sélectifs de l'information, de l'utilisation inhabituelle de projections, de couleurs, de graphiques et de textes, ou encore d'images ou d'affiches de propagande destinées à tromper intentionnellement, ces cartes véhiculent un large éventail de messages religieux, politiques, militaires, commerciaux, moraux et sociaux. »
En complément
Un fil twitter de @GoncharenkoUA sur "la propagande douce" véhiculée par les cartes qui représentent la Crimée comme séparée de l'Ukraine et comme une partie de la Russie.
Un fil twitter de @mirbole01 sur les cartes et dessins humoristiques concernant l'expansion de la Chine en mer de Chine méridionale.
Série d'images et de cartes utilisant la pieuvre comme élément de caricature. Cette sélection de @WryCritic permet de mettre en évidence des points communs et des spécificités d'une caricature à l'autre.Articles connexes
Les nouvelles façons de « faire mentir les cartes » à l’ère numérique
La rhétorique derrière les cartes de propagande sur le coronavirus
Cartographie électorale, gerrymandering et fake-news aux Etats-Unis
Étudier l'expansion de la Chine en Asie du Sud-Est à travers des cartes-caricatures
Qu'est-ce que le Listenbourg, ce nouveau pays fictif qui enflamme Twitter ? (fake map)
Derrière chaque carte, une histoire : découvrir les récits de la bibliothèque Bodleian d'Oxford
Bouger les lignes de la carte. Une exposition du Leventhal Map & Education Center de Boston
La carte, objet éminemment politique




-
19:00
Journée d’études CFC : Arts(s) et Cartographie(s), 25 novembre 2023, INHA (Paris)
sur Cartes et figures du mondeAvec le soutien de l’EPHE-PSL (Histara), du CNRS (Lamop) et de la Bibliothèque nationale de France
Entrée libre
On dispose aujourd’hui de nombreuses études sur la place de la cartographie dans l’histoire des savoirs scientifiques, et sur les engagements de la cartographie dans les entreprises politiques. Mais il est nécessaire d’envisager aussi les relations de la cartographie avec les arts et les artistes ainsi que les formes d’implication de la cartographie dans les mondes de l’art et dans les cultures visuelles des sociétés modernes et contemporaines. C’est dans cette optique que la Commission Histoire du Comité Français de Cartographie organise une Journée d’études intitulée « Art(s) et cartographie(s) », avec l’ambition de rassembler et de confronter quelques-unes des pistes principales de la recherche actuelle.

Programme
8h45 Accueil – café Ouverture 9h15 Introduction à la journée par Jean-Marc Besse (CNRS-EHESS) et Catherine Hofmann (BnF, département des Cartes et plans) 9h30 Anca Dan, Professeur attachée en sciences de l’Antiquité, ENS-PSL Cartes sur mosaïque : quelques chorographies antiques 10h Pause-café Première session Artistes-cartographes en Europe au XVIe siècle Sous la présidence de Gilles Palsky (Université Paris I) 10h15 Juliette Dumasy-Rabineau, maîtresse de conférences en histoire médiévale à l’université d’Orléans et Camille Serchuk,professeure d’histoire de l’art à la South Connecticut State University Les artistes cartographes français aux XVe et XVIe siècles 10h45 Jan Trachet, chercheur postdoctoral au département d’archéologie de l’Université de Gand et Bram Vannieuwenhuyze, professeur associé en histoire de la cartographie à l’Université d’Amsterdam Les cartes des artistes-cartographes à Bruges, 1557-1572 : des œuvres isolées ou collaboratives ? 11h15 Ulrike Gehring,professeur à l’Universität Trier Fb III – Art History, Coastal Profiles. The Interface between mimetic and cartographic representation 11h45 Présentation des œuvres exposées par les artistes Annie Lunardi et Marcoleptique 12h15 Pause déjeuner Seconde session Art et cartographie en France aux XVIIe et XVIIIe siècles Sous la présidence de Lucile Haguet (Bibliothèque municipale du Havre) 13h30 Pierre-Olivier Marchal, doctorant à l’EHESS – Centre Alexandre Koyré Représenter le territoire : une circulation des savoirs cartographiques dans l’œuvre de Jean-Baptiste et Pierre-Denis Martin (1659-1742) 14h Geoffrey Phelippot, doctorant à l’EHESS – Centre Alexandre Koyré Cartographie et bricolage ornemental : Nicolas Guérard à la Sphère Royale 14h30 Pause Troisième session 15h Art contemporain et cartographie Mathieu Pernot, photographe, et Monika Marczuk, chargée de collections à la BnF-CPL Cartes en mouvement 15h30-17h Table ronde « Art contemporain et cartographie : rencontres, échanges, déplacements » Animée par Jean-Marc Besse, avec : Ann Valérie Epoudry, artiste plasticienne, diplômée de Sciences-Po Paris, doctorante à l’École Nationale Supérieure d’Architecture de Toulouse (LRA) Guillaume Monsaingeon, philosophe, chercheur et commissaire d’exposition indépendant Florence Troin, géographe-cartographe CITERES-EMAM, CNRS & Université de Tours Pauline Guinard, maître de conférences HDR en géographie, ENS Contact : catherine.hofmann@bnf.fr Fichier pdf. du programme :
Programme-JE-CFC-histoire-INHA-25-novembre-2023Télécharger

-
Découvrez nos cartes dédiées aux Journées européennes du patrimoine 2023 - #1Jour1Carte
sur Makina CorpusCette année à l'occasion des Journées du patrimoine, nous vous avons concocté une collection de cartographies dédiées aux thèmes de la culture et du patrimoine. Au programme : les journées du patrimoines, les plus grands labels des villes et les jardins remarquables !
-
6:36
Bascule des géoservices de l'IGN vers une Géoplateforme
sur Cartographies numériques
Le programme Géoplateforme vise à doter la puissance publique d’une infrastructure collaborative et mutualisée pour la production et la diffusion des géodonnées. Son ambition est de permettre aux porteurs de politiques publiques et aux collectivités locales qui le souhaitent de bénéficier très simplement de fonctionnalités avancées pour diffuser leurs propres données et s’ouvrir à des communautés contributives. Cet espace, composante géographique de l'État-plateforme reconnue grand projet numérique de l'État, répond notamment aux enjeux de souveraineté des données de l’État face aux géants de l’Internet.La Géoplateforme s'inscrit pleinement dans la dynamique des Géo-communs soutenue par l'IGN. En effet, si l'institut a bien vocation à porter ses propres services sur la Géoplateforme, celle-ci se veut en premier lieu un outil commun au monde public. C'est la mobilisation progressive de partenaires, producteurs et usagers de données géographiques qui doit permettre d'atteindre cet objectif.

L'IGN informe les utilisateurs des géoservices du Géoportail d'une bascule vers sa nouvelle Géoplateforme. La date d’arrêt de l’infrastructure du Géoportail est fixée au 31 décembre 2023. Pour les internautes des sites web portés par l’IGN (Géoportail, Remonter le temps, Géoportail de l’Urbanisme…), c’est transparent.Pour découvrir les nouvelles fonctionnalités de la Géoplateforme
Les principaux changements pour tous les géoservices inhérents au passage à la Géoplateforme sont :
- Changements d’URL
L’usage du protocole [HTTPS] / TLS 1.2 est imposé pour accéder aux géoservices, sans exception possible.
Les géoservices ne sont plus accessibles via le Réseau Interministériel de l’État (RIE)- Changements du contrôle d’accès
Les actuelles « clés » Géoportail (personnelles et publiques) disparaissent, elles sont remplacées par un nouveau mécanisme de contrôle des accès sur les données non libres.
Pour les données à accès restreint (par exemple pour les SCAN 25®, SCAN 100® et SCAN OACI de l’IGN), un nouveau mécanisme de diffusion sera mis en place.
Par défaut, tout devient open source et accessible librement.- Principaux changements de certains géoservices
Les géoservices exposant des standards OGC n'exposent plus que la dernière version :
WMS 1.1 n’est plus supporté (seulement le 1.3)
WFS 1.0 n’est plus supporté (seulement le 2.0)
Le service d’auto-configuration disparaît (l’API JavaScript est adaptée en conséquence) (lien vers article ici)
Les flux INSPIRE intègrent les flux génériques de la Géoplateforme
Les services de téléchargement (via le site Géoservices) et de diffusion de données anciennes (via le site Remonter Le Temps) évoluent sans conservation des interfaces API actuellesLien ajouté le 27 septembre 2023
Le replay et le support de présentation du temps d'info #Géoplateforme consacré à la première version de [https:]] , le futur service public des cartes et données du territoire, sont disponibles ! #Géocommuns
— IGN France (@IGNFrance) September 27, 2023Articles connexes
Depuis le 1er janvier 2021, l'IGN rend ses données libres et gratuites
Les anciens millésimes de la BD Topo disponibles en téléchargement sur le site de l'IGN
Lidar HD : vers une nouvelle cartographie 3D du territoire français (IGN)
Zoom sur le service Edugéo (IGN) proposé à travers le portail de ressources Eduthèque
Chercher une carte IGN par thème d'études
Mise à disposition de la base Demandes de valeurs foncières (DVF) en open data
Carte lithologique de la France au 1/50 000e sur InfoTerre (BRGM)
DataFrance, une plateforme de visualisation de données en open data
Recension de liens pour se procurer des fonds de cartes SIG
-
20:01
Plateforme de cartes en ligne du Patrimoine mondial de l'UNESCO
sur Cartographies numériques
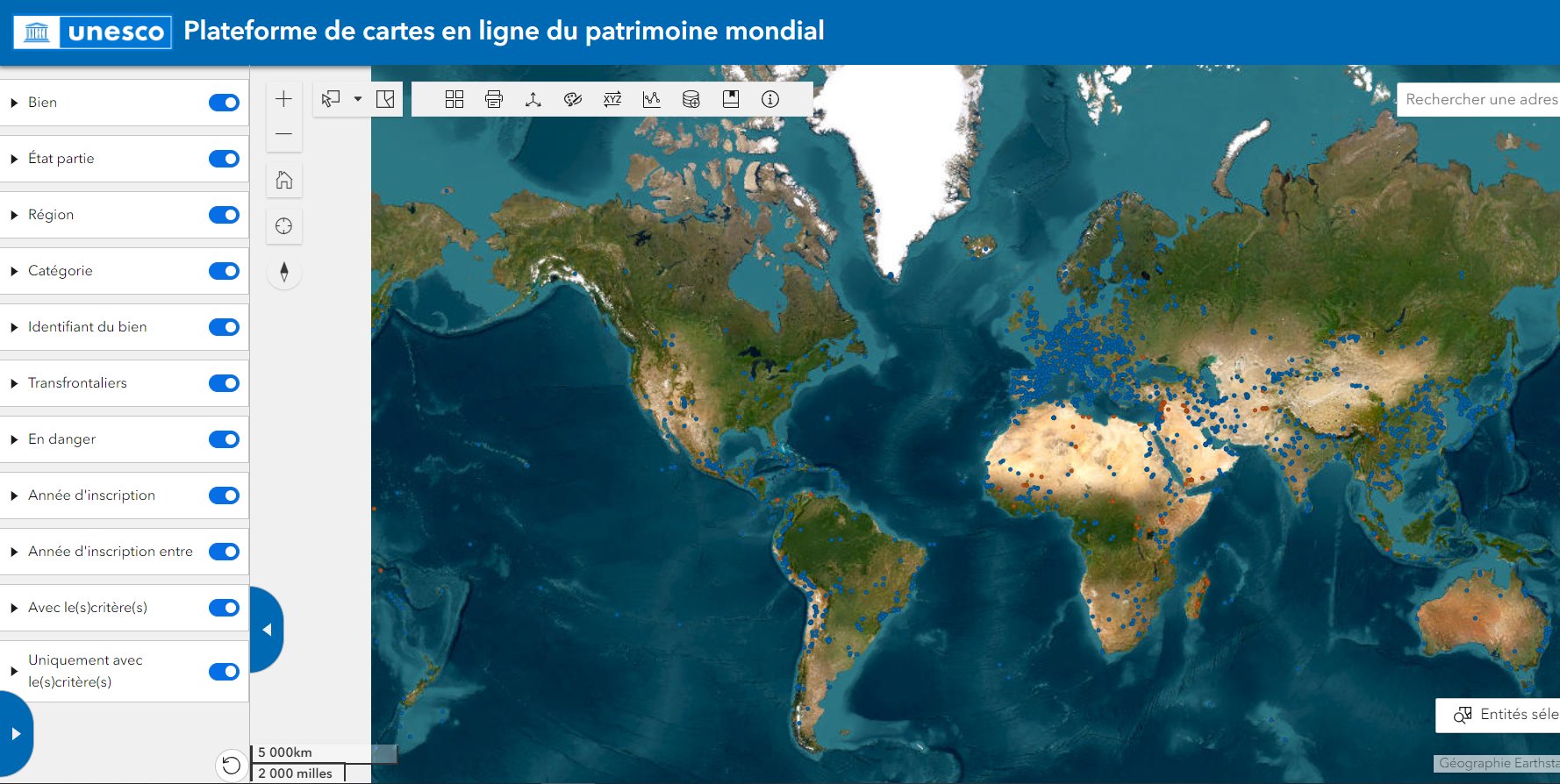
L'UNESCO lance une Plateforme de cartes en ligne du patrimoine mondial. Cet outil de suivi, lié aux bases de données existantes de l'UNESCO, affiche les sites géoréférencés du patrimoine mondial avec leurs zones tampons, et permet d'effectuer des opérations cartographiques de base. La plateforme est destinée aux États adhérents à la Convention du patrimoine mondial, aux gestionnaires de sites, aux organisations consultatives, à l'UNESCO et à bien d'autres acteurs.
Accès à la Plateforme de cartes en ligne du patrimoine mondial (source : UNESCO)
La plateforme SIG de l'UNESCO est destinée à :- Renforcer la protection de la valeur universelle exceptionnelle des biens du patrimoine mondial en fournissant aux États membres un système d’information géographique en ligne pour améliorer le suivi de leur état de conservation.
- Améliorer la qualité et la cohérence des cartes des biens du patrimoine mondial, pour faciliter l’accès et l’analyse des données géographiques du patrimoine mondial, afin de développer des systèmes de gestion adéquats.
- Faciliter la planification et la préparation d’évaluations d’impact sur le patrimoine, d’évaluations d’impact environnemental, ainsi que d’autres documents pertinents et complexes sur la base de cartes accessibles et précises des limites des biens du patrimoine mondial et de leurs zones tampons.
- Aider les développeurs de projets (y compris du secteur privé) à mieux comprendre les différentes limites de protection du patrimoine mondial et les guider dans l’évaluation de projets situés dans les limites ou à proximité d’un bien du patrimoine mondial. Il s’agit d’un outil directement pertinent pour la mise en œuvre de l’engagement à respecter des zones d’exclusion ou des projets relatifs à l’énergie éolienne.
Avec la mobilisation de ressources additionnelles, d’autres couches de données pourraient être ajoutées au système, à commencer par les facteurs affectant les biens tels qu’ils sont répertoriés dans le Système d’information sur l’état de conservation.
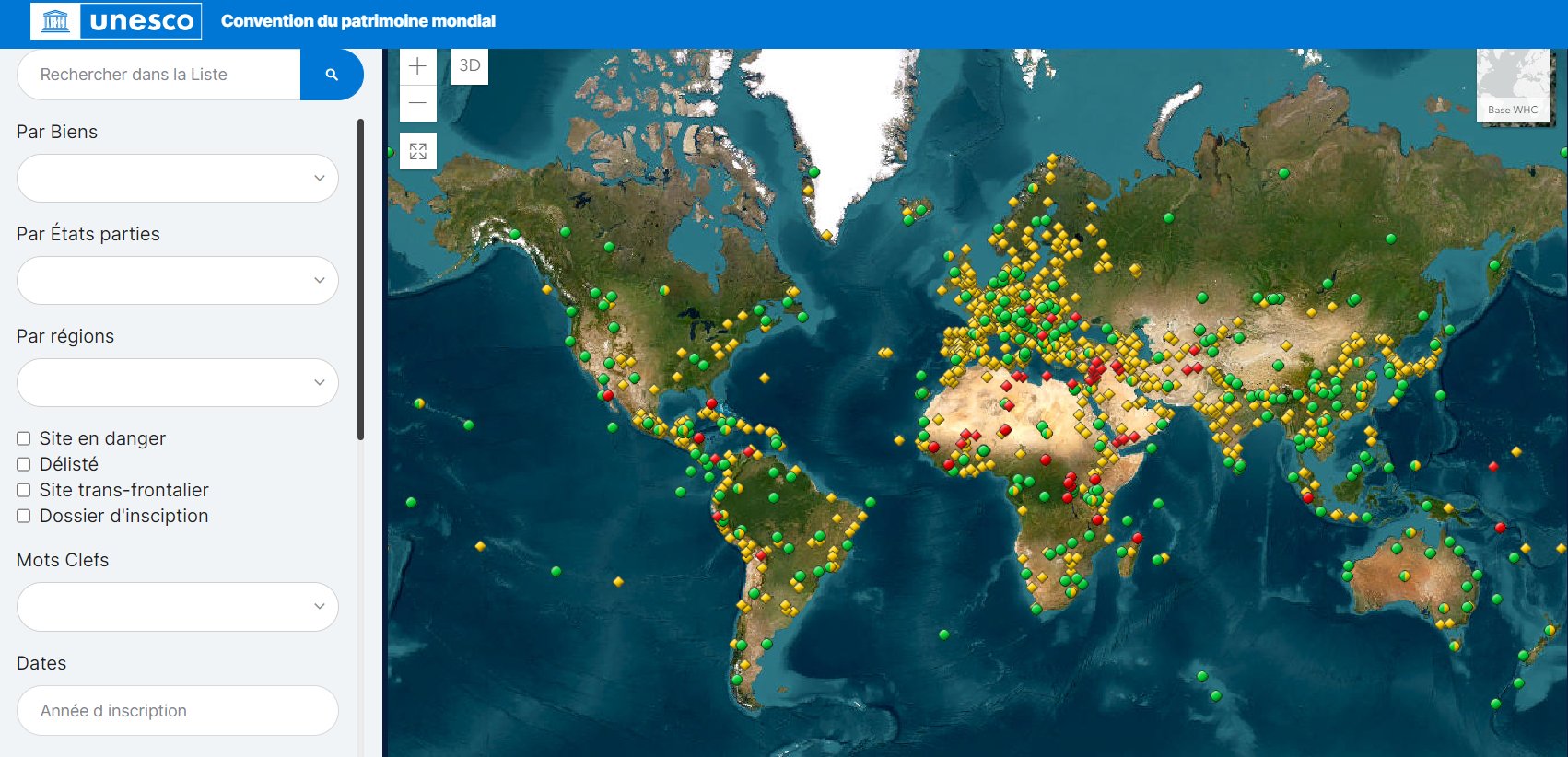
L’inscription d’un bien sur la liste du Patrimoine mondial est une reconnaissance de sa « valeur universelle exceptionnelle », qui le rend digne d’être préservé comme patrimoine de l’humanité. Les données sur le patrimoine mondial de l'UNESCO sont téléchargeables à partir d'une carte interactive. Les fichiers proposés sur cette page (format kml et xls) intègrent la géolocalisation des sites et permettent une réutilisation des données dans un globe virtuel ou un SIG. La base de données permet de distinguer les sites naturels, culturels ou mixtes (avec leur date d'inscription à la liste de l'UNESCO) ainsi que les sites en danger. Une recherche en plein texte permet, à partir de mots-clés, de raffiner la recherche à partir de certains critères. Il est possible par exemple de choisir en fonction des critères de sélection ayant présidé à leur inscription comme sites naturels, culturels ou mixtes.
Carte interactive avec accès aux données géolocalisées (source : UNESCO)
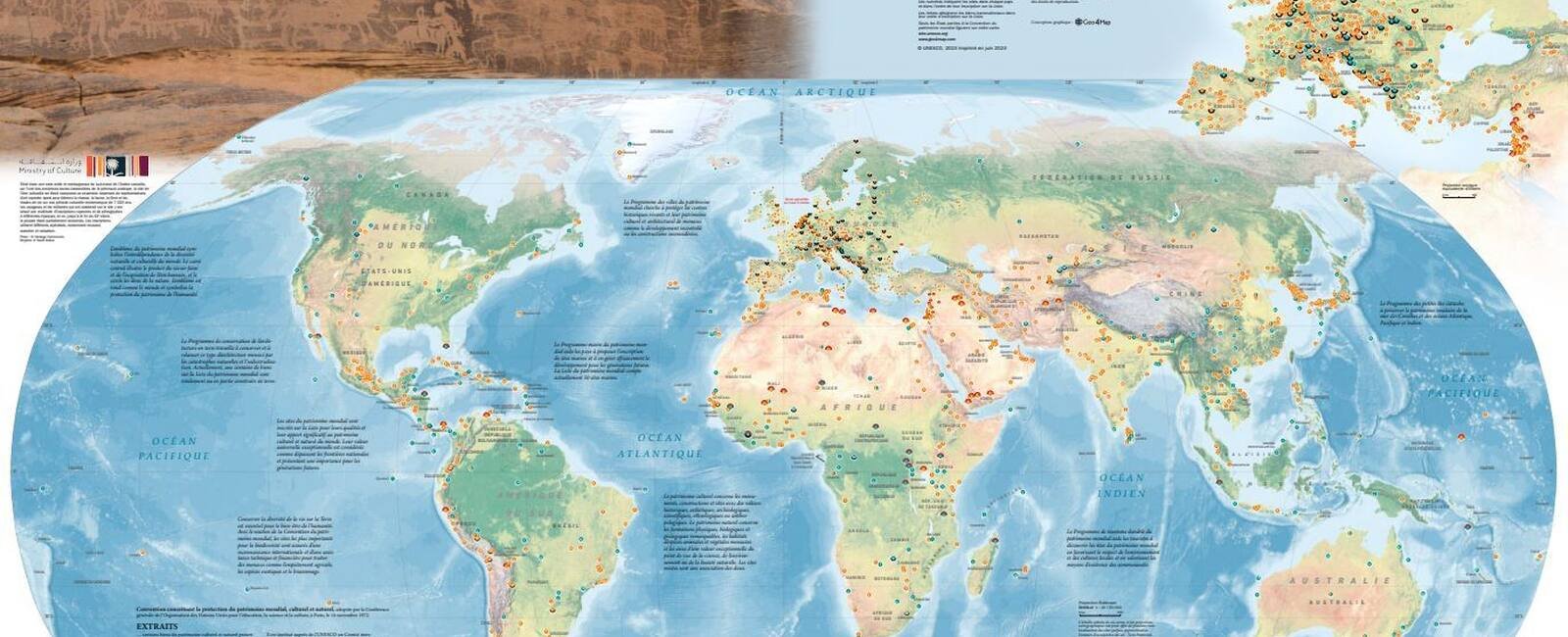
La carte du patrimoine mondial 2023 est disponible en haute résolution et dans différentes langues. Cette carte murale est disponible en téléchargement (avec la possibilité de comparer avec d'anciennes cartes depuis 2002).
Carte des sites du patrimoine mondial au format affiche murale (source : UNESCO)
Données disponibles sur la France :- Plate-forme de données ouvertes du ministère de la Culture (Data.culture.gouv.fr)
- Base des lieux et équipements culturels en France - Basilic (Data.gouv.fr)
- Base de données des Journées Européennes du Patrimoine en France (Data.gouv.fr)
- Liste et localisation des Musées de France (Data.gouv.fr)
Pour aller plus loin
Lionel Prigent (2013). L'inscription au patrimoine mondial de l'Unesco, les promesses d'un label ? Revue internationale et stratégique 2013/2 (n° 90), p.127-135
Mélanie Duval, Ana Brancelj et Christophe Gauchon, Élasticité des normes et stratégies d’acteurs : analyse critique de l’inscription au patrimoine mondial de l’UNESCO, Géoconfluences, juin 2021.
Bernard Debarbieux (2020). Imaginaires et rhétoriques de la mondialité au patrimoine culturel immatériel de l’UNESCO. L’Espace géographique 2020/4 (Tome 49), p. 354-370.
Jean-Christophe Fichet (2020). Le patrimoine mondial de l’UNESCO en cartes. Carto-lycée.Articles connexes
Carte des événements des Journées européennes du patrimoine en France (2019)
L'histoire par les cartes : les cartes de la Société de documentation industrielle, un inventaire du patrimoine industriel de la France de l'entre-deux-guerres
Mise à disposition de la Base de données nationale des bâtiments (BDNB) en open data
France Pixel Bâti. Naviguer dans la structure du patrimoine bâti français en haute définitionEtudier les formes urbaines à partir de plans cadastraux
-
16:05
Colloque : “Cartographies et représentations des îles en Méditerranée (XVe- XXe siècles)”, Corte, 3-4-5 octobre 2023
sur Cartes et figures du mondeArgumentaire scientifique
Au cours des trente dernières années le Musée de la Corse a constitué une collection de cartes et plans anciens exclusivement consacrés à l’île ainsi que plusieurs livres attachés à sa géographie historique. Ce fonds rassemble des figures cartographiques qui couvrent la période de 1520 à 1900. L’enrichissement progressif par acquisitions et la mise en œuvre d’un inventaire en ligne incitaient à mettre en lumière cet ensemble patrimonial sous trois formes complémentaires : sa publication sous forme d’un beau livre, sa présentation au public sous la forme d’une exposition, et enfin un colloque scientifique.
L’objet de ce colloque, au regard de l’exposition, est de replacer la cartographie de la Corse dans la perspective plus large de la représentation des îles en Méditerranée depuis le Moyen âge jusqu’à l’époque contemporaine, tant dans les techniques cartographiques utilisées que dans ses différents contextes politiques et intellectuels, aussi bien dans le monde arabe que dans la chrétienté occidentale. Il s’agira d’analyser la spécificité de la représentation de l’espace insulaire méditerranéen, et de ses enjeux territoriaux.
Le colloque dont les sessions sont prévues à Corte, dans les locaux de l’Université de Corse, les 3 et 4 octobre 2023, seront complétées le 5 octobre par une visite de l’exposition Cartografià. La Corse en cartes, au Musée et celle, ensuite, d’une présentation d’ouvrages anciens à la Bibliothèque patrimoniale Tommaso Prelà à Bastia.

Comité scientifique
Vannina Marchi van Cauvelaert, Maître de conférences en histoire du Moyen Âge (UMR 6240 LISA – Université de Corse)
Emmanuelle Vagnon-Chureau, Chargée de recherche CNRS en histoire du Moyen Âge (UMR 8589 LAMOP)
Pierre-Jean Campocasso (Direction du Patrimoine)
Direction scientifique
Maurice Aymard (EHESS)
Henri Bresc (Paris X Nanterre -Institut Européen en Sciences des Religions, Paris)
Coordination
Dominique Gresle, Commissaire de l’exposition, à l’initiative du colloque
Organismes partenaires
UMR 6240 Lieux Identités eSpaces Activités – Université de Corse
UMR 8589 Laboratoire de Médiévistique Occidentale de Paris – CNRS
Musée de la Corse – Collectivité de Corse
Participants
Christophe Austruy (EHESS)
Emiliano Beri (Univ. Genova)
Nathalie Bouloux (Université de Tours)
Lorenzo Brocada (Univ. Genova)
Philippe Colombani (Université de Corse)
Antoine Franzini (Univ. Gustave Eiffel, Marne -La- Vallée)
Catherine Hofmann (BNF – Cartes et plans)
Jean Charles Ducène (EPHE)
Frank Lestringant (Paris Sorbonne)
Joseph Martinetti (Univ. Côte d’Azur)
Paolo Militello (Univ. Catane)
Marie-Vic Ozouf-Marignier (Directeur d’études EHESS)
Pierre Portet (Conservateur général du Patrimoine. Archives de Corse)
Giampaolo Salice (Univ. Cagliari)
Georges Tolias (EPHE Paris – FNRS Athènes)
Programme
(Les exposés de 25 minutes seront suivis de 5 mn de discussion)
Mardi 3 octobre (Université de Corse, amphi à préciser)
9h Discours d’accueil et introduction scientifique des travaux
Maurice Aymard et Henri Bresc
10h- 13h première session : Les îles dans la cartographie médiévale arabe et latine
Henri Bresc
Edrisi au service de Roger II de Sicile
Jean Charles Ducène
La Corse dans la cartographie arabe
Vannina Marchi van Cauvelaert (MCF Hdr, Université de Corse)
Insularité et iléité : les représentations médiévales de la Corse et de la Sardaigne (XIIIe-XVe)
Emmanuelle Vagnon
Grandes et petites îles de Méditerranée occidentale dans les premières cartes marines
Nathalie Bouloux
Les îles de la Méditerranée occidentale (Corse, Sardaigne, Sicile) dans les manuscrits et les éditions de la Géographie de Ptolémée
Déjeuner (buffet)
15h-18h deuxième session : Cartes d’îles et insulaires au XVIe siècle
Antoine Franzini
La carte manuscrite de la Corse présente dans l’Atlas hydrographique de Vesconte Maggiolo (1512)
Georges Tolias
L’avènement de l’insulaire : hypothèses sur la genèse d’un genre.
Frank Lestringant (Sorbonne Université)
La Corse dans le Grand Insulaire d’André Thevet.
PH Colombani
La route des îles de la Couronne d’Aragon : dominer, unir, partager, une histoire méditerranéenne.
Dîner
Mercredi 4 octobre (Université de Corse)
9h30-12h30 troisième session : géopolitique des îles méditerranéennes à l’époque moderne
Maurice Aymard
Architectes militaires et/ou cartographes : la Sicile après Lépante. Représentation et défense du territoire.
Catherine Hofmann
La représentation des îles dans la cartographie marine à Marseille au XVIIe siècle. Le cas de l’Atlas Boyer (1648)
Christophe Austruy
Coronelli et l’Arsenal de Venise. Vraies légendes et fausses cartes.
Giampaolo Salice
Geopolitica e rivoluzione sociale nella conquista delle isole intermedie
tra Sardegna e Corsica.Emiliano Beri et Lorenzo Brocada
La Corsica di Accinelli: una missione strategica in chiave cartografica.
Déjeuner (buffet)
14h30-17h30 quatrième session : La Corse et les îles jusqu’à aujourd’hui
Marie -Vic Ozouf Marignier
Les représentations de la Corse dans les géographies illustrées (1880-1910).
Paolo Militello
James Boswell, Pasquale Paoli et Thomas Phinn dans l’ “Account of Corsica […] illustrated with a new and Accurate Map of Corsica” (1768).
Joseph Martinetti (MCF en géographie, Université Nice Côte d’Azur)Dans la continuité des isolarii, une nouvelle cartographie géopolitique des îles méditerranéennes est-elle possible ?
Dîner de clôture
Jeudi 5 octobre
Matinée : visite de l’exposition Cartografià. La Corse en cartes (Dominique Gresles, commissaire de l’exposition)
Puis transfert à Bastia pour la présentation d’ouvrages issus du fonds Tommaso Prelà
Affiche et programme pdf du colloque :
Colloque-Corte-3-5-octobre-2023-programmeTélécharger Affiche-du-colloqueTélécharger

-
Makina Corpus sponsorise la DrupalCon Lille 2023
sur Makina CorpusLa DrupalCon 2023 revient en France du 17 au 20 octobre et notre équipe y participe
-
9:00
Oslandia signe un partenariat avec OPENGIS.ch sur QField
sur OslandiaQui sommes nous ? Pour ceux qui ne connaissent pas Oslandia, ou OpenGIS.ch, ou même QGIS, rafraichissons les mémoires :
Pour ceux qui ne connaissent pas Oslandia, ou OpenGIS.ch, ou même QGIS, rafraichissons les mémoires :
 Oslandia est une entreprise française spécialisée dans les systèmes d’information géographique opensource (SIG). Depuis notre création en 2009, nous proposons des services de conseil, de développement et de formation en SIG, avec une expertise reconnue. Oslandia est un « pure-player » opensource, et le plus grand contributeur français à la solution QGIS.
Oslandia est une entreprise française spécialisée dans les systèmes d’information géographique opensource (SIG). Depuis notre création en 2009, nous proposons des services de conseil, de développement et de formation en SIG, avec une expertise reconnue. Oslandia est un « pure-player » opensource, et le plus grand contributeur français à la solution QGIS. Quant à OPENGIS.ch , il s’agit d’une entreprise Suisse spécialisée dans le développement de logiciels SIG open-source. Fondée en 2011, OPENGIS.ch est de son côté le plus grand contributeur suisse à la solution QGIS. OPENGIS.ch est le créateur de QField, la solution de SIG mobile open-source la plus utilisée par les professionnels de la géomatique.
Quant à OPENGIS.ch , il s’agit d’une entreprise Suisse spécialisée dans le développement de logiciels SIG open-source. Fondée en 2011, OPENGIS.ch est de son côté le plus grand contributeur suisse à la solution QGIS. OPENGIS.ch est le créateur de QField, la solution de SIG mobile open-source la plus utilisée par les professionnels de la géomatique.OPENGIS.ch propose également QFieldCloud en tant que solution SaaS ou on-premise pour la gestion collaborative des projets de saisie terrain.

 Certains ne connaissent pas encore #QGIS ?
Certains ne connaissent pas encore #QGIS ?
Il s’agit d’un système d’information géographique libre et opensource qui permet de créer, éditer, visualiser, analyser et publier des données géospatiales. Multiplateforme, QGIS est utilisable sur ordinateur, serveur, en application web ou comme bibliothèque de développement.
QGIS est un logiciel libre développé par de multiples contributeurs dans le monde entier. C’est un projet officiel de la fondation OpenSource Geospatial OSGeo et soutenu par l’association QGIS.org. cf [https:]]
Un partenariat ? Nous sommes aujourd’hui heureux d’annoncer notre partenariat stratégique visant à renforcer et à promouvoir QField, l’application mobile de la solution SIG opensource QGIS.
Nous sommes aujourd’hui heureux d’annoncer notre partenariat stratégique visant à renforcer et à promouvoir QField, l’application mobile de la solution SIG opensource QGIS. Ce partenariat entre Oslandia et OPENGIS.ch est une étape importante pour QField et les solutions SIG mobiles opensource, qui permettra de consolider la plateforme, en offrant aux utilisateurs du monde entier un accès simplifié à des outils efficaces pour la collecte, la gestion et l’analyse des données géospatiales sur le terrain.
Ce partenariat entre Oslandia et OPENGIS.ch est une étape importante pour QField et les solutions SIG mobiles opensource, qui permettra de consolider la plateforme, en offrant aux utilisateurs du monde entier un accès simplifié à des outils efficaces pour la collecte, la gestion et l’analyse des données géospatiales sur le terrain. QField, développé par OPENGIS.ch, est une application mobile opensource de pointe qui permet aux professionnels des SIG de travailler en toute efficacité sur le terrain, en utilisant des cartes interactives, en collectant des données en temps réel et en gérant des projets géospatiaux complexes sur des appareils mobiles Android, IOS ou Windows.
QField, développé par OPENGIS.ch, est une application mobile opensource de pointe qui permet aux professionnels des SIG de travailler en toute efficacité sur le terrain, en utilisant des cartes interactives, en collectant des données en temps réel et en gérant des projets géospatiaux complexes sur des appareils mobiles Android, IOS ou Windows.
 QField est multiplateforme, basée sur le moteur QGIS, et permet donc un partage des projets de manière fluide entre les applications bureautiques, mobiles et web.
QField est multiplateforme, basée sur le moteur QGIS, et permet donc un partage des projets de manière fluide entre les applications bureautiques, mobiles et web.
On en dit quoi ? QFieldCloud ( [https:]] ), la plateforme web collaborative de gestion de projets QField, bénéficiera également du partenariat, et pourra être enrichie pour compléter la gamme d’outils de la solution QGIS.
QFieldCloud ( [https:]] ), la plateforme web collaborative de gestion de projets QField, bénéficiera également du partenariat, et pourra être enrichie pour compléter la gamme d’outils de la solution QGIS. Côté Oslandia, nous sommes très heureux de collaborer avec OPENGIS.ch sur les technologies QGIS. Oslandia partage avec OPENGIS.ch une vision commune du développement de logiciel libre et opensource : une implication forte dans les communautés de développement, un travail dans le respect de l’écosystème, une très grande expertise, et une optique de développement logiciel de qualité industrielle, robuste et pérenne.
Côté Oslandia, nous sommes très heureux de collaborer avec OPENGIS.ch sur les technologies QGIS. Oslandia partage avec OPENGIS.ch une vision commune du développement de logiciel libre et opensource : une implication forte dans les communautés de développement, un travail dans le respect de l’écosystème, une très grande expertise, et une optique de développement logiciel de qualité industrielle, robuste et pérenne. Avec ce partenariat, nous souhaitons proposer à nos clients la plus grande expertise possible sur l’ensemble des composants logiciels de la plateforme QGIS, depuis la captation de la donnée jusqu’à sa diffusion.
Avec ce partenariat, nous souhaitons proposer à nos clients la plus grande expertise possible sur l’ensemble des composants logiciels de la plateforme QGIS, depuis la captation de la donnée jusqu’à sa diffusion. Côté OpenGIS.ch, Marco Bernasocchi ajoute :
Côté OpenGIS.ch, Marco Bernasocchi ajoute :
L’engagement pour l’opensourceLe partenariat avec Oslandia représente une étape cruciale dans notre mission visant à fournir des outils SIG mobiles de premier plan avec un réel crédo OpenSource. La complémentarité de nos compétences permettra d’accélérer le développement de QField ainsi que de QFieldCloud, et de répondre aux besoins croissants de nos utilisateurs .
Prêts pour le terrain ? Nos deux entreprises s’engagent à continuer à soutenir et à améliorer QField et QFieldCloud en tant que projets opensource, garantissant ainsi un accès universel à cette solution de SIG mobile de haute qualité sans aucune dépendance à un fournisseur.
Nos deux entreprises s’engagent à continuer à soutenir et à améliorer QField et QFieldCloud en tant que projets opensource, garantissant ainsi un accès universel à cette solution de SIG mobile de haute qualité sans aucune dépendance à un fournisseur. Et vous, êtes vous prêts pour le terrain ?
Et vous, êtes vous prêts pour le terrain ?Alors téléchargez QField ( [https:]] ) , créez des projets sur QGIS, partagez-les sur QFieldCloud !
 Si vous avez besoin de formation, support, maintenance, déploiement ou développement de fonctionnalités spécifiques sur ces plateforme, n’hésitez pas à nous contacter, vous aurez les meilleurs experts disponibles : infos+mobile@oslandia.com
Si vous avez besoin de formation, support, maintenance, déploiement ou développement de fonctionnalités spécifiques sur ces plateforme, n’hésitez pas à nous contacter, vous aurez les meilleurs experts disponibles : infos+mobile@oslandia.com
-
20:33
Le forum d'OpenstreetMap, un lieu d'échange autour des enjeux de la cartographie collaborative et de l'open data
sur Cartographies numériques
Le forum d'OpenStreetMap (@OSM_FR) est très intéressant à observer et à analyser pour appréhender les enjeux actuels concernant la cartographie collaborative et l'open data en matière de géodonnées.
Les débats concernent notamment la place et le rôle que doit jouer OpenStreetMap en tant que première plateforme de crowdsoucing, en lien avec la question délicate de la coopération possible (souhaitable ?) avec des entreprises privées. Voir par exemple le problème de la réutilisation d'images haute résolution venant d'autres fournisseurs (Maxar ou autres...). Il s'agit aussi d'anticiper les évolutions et réfléchir à la manière de faire évoluer le modèle de données ouvertes avec des enjeux importants sur la façon de valoriser le modèle attributaire d’OSM. Plus la quantité de données augmente et plus le besoin de standardiser les structures est important. OpenStreetMap présente l’avantage de n’avoir qu’un unique espace sémantique, obligeant la communauté à tenir en cohérence des concepts bien différents qui ne le sont habituellement pas (les bâtiments et la voirie proche, les routes et les réseaux électriques…). Voir la consultation de la communauté sur cette question d'évolution du modèle de données.
Les enjeux en termes d'éducation et formation ne sont pas oubliés, à travers une rubrique EducOSM. Sur cette page, est présenté notamment l'enseignement des Sciences numériques et Technologie (SNT) dans les établissements scolaires. Paru au bulletin officiel de l’Éducation nationale, de la jeunesse et des sports, le bulletin officiel spécial n°1 du 22 janvier 2019 fixe le programme d’enseignement de Sciences Numériques et Technologie de la classe de seconde générale et technologique. Dans le programme en annexe (page 15), dans la thématique Localisation, cartographie et mobilité, il est fait mention de contenus dans lesquels on trouve la capacité attendue "Contribuer à OpenStreetMap de façon collaborative". La communauté OpenStreetMap propose de comparer 7 manuels scolaires de seconde qui traitent de cette capacité (Les manuels scolaires et OSM, quels traitements en SNT ?). Des pistes d'activités pédagogiques sont également proposées autour de "Carto-parties" qui exploitent les données OSM et permettent d'initier à la cartographie collaborative (Carto-Partie au lycée agricole de Beaulieu). Les "bonnes pratiques" pour contribuer à OpenStreetMap en SNT sont décrites sur le site de la DANE de l'académie de Lyon, qui est mis à jour régulièrement. Une page OpenstreetMap, la cartographie collaborative ! présente en détail l'intérêt d'utiliser OSM et de construire des activités pédagogiques avec cet outil open source pour initier et faire réfléchir aux enjeux de la cartographie collaborative et de l'open data.
Articles connexes
Autour d’OpenStreetMap, les tensions grandissent sous l'influence des entreprises
L'évolution de la cartographie humanitaire au sein de la communauté OpenStreetMap
Une cartographie très précise des densités à l'échelle mondiale pour améliorer l'aide humanitaire
Utiliser la grille mondiale de population de la plateforme Humanitarian Data Exchange
Microsoft met en téléchargement 800 millions d'empreintes de bâtiments
Tentative de "caviardage cartographique" à l'avantage de la Chine dans OpenStreetMap
-
13:36
Panoramax, l’alternative libre pour photo-cartographier les territoires
sur Cartographies numériquesPanoramax fédère les initiatives (des collectivités, des contributeurs OSM, de l’IGN...) pour favoriser l'émergence d'un géocommun de bases de vues immersives. Aujourd’hui l’utilisation de photos/vues immersives de rues via Google StreetView et/ou Mapillary, ou via des prestations privées (ESRI/Cyclomédia, SOGEFI etc.) ouvre pas mal d’opportunités en termes de rationalisation des déplacements, facilitation et accélération du recueil d’information nécessaire aux traitements de certaines procédures et finalement d’amélioration de la connaissance du territoire. La collecte, le partage et l’utilisation de ces données restent cependant compliqués : problème de licences, dépendance à des sociétés privées dont la stratégie n’est pas orientée vers l’ouverture des données ou dont la stratégie n’est pas claire, difficulté à partager des bonnes pratiques, à s’assurer de la pérennité d’une solution pour y appuyer des usages métiers à partager, etc.
A terme, Panoramax pourrait devenir une sorte de StreetView à la française, mais il est encore trop tôt pour savoir quel sera l'avenir du projet. Il existe déjà une application semblable Mapillary qui semble rencontrer un succès important à l'échelle mondiale, même si la finalité est un peu différente. Sur Panoramax, les photos sont fournies par la communauté, hébergées sur plusieurs instances, disponibles en licence CC-BY-SA 4.0 et téléchargeables en pleine résolution. Il est d'ores et déjà possible d'y déposer des images et de l'utiliser en lien avec différentes applications cartographiques (notamment QGIS).
- Interface de versement des photos sur le forum Géocommuns.
- Contribution sur GitHub
- Plugin Panoramax pour Q-Gis
- Synchronisation avec JOSM
L'équipe est portée par La Fabrique des géocommuns et sponsorisée par Institut national de l'information géographique et forestière : La Fabrique des géocommuns, incubateur de communs à l’IGN. Lancée en 2021, la Fabrique a pour ambition d'initier et d'accompagner le développement de services publics numériques construits autour de géocommuns.Articles connexes
Pour aider à géolocaliser des photographies, Bellingcat propose un outil de recherche simplifié à partir d'OpenStreetMap
L'évolution de la cartographie humanitaire au sein de la communauté OpenStreetMap
Autour d’OpenStreetMap, les tensions grandissent sous l'influence des entreprises
Facebook prend le contrôle de Mapillary, le principal concurrent de Google Street View
Google Street View et sa couverture géographique très sélective


-
11:51
Iota2 ne fait pas que de la classification, elle fait aussi des indicateurs environnementaux !
sur Séries temporelles (CESBIO)Contexte scientifiqueLe projet SOCCROP, qui a été financé par l’association Planet A, avait pour objectif de développer un indicateur pour quantifier les échanges annuels de CO2 entre les parcelles cultivées et l’atmosphère. Mesurer les flux permet d’accéder à l’évolution des stocks de carbone des sols agricoles. Cet indicateur peut être utile dans différents contextes :
- pour les inventaires nationaux d’émissions de gaz à effet de serre (GES),
- en tant qu’indicateur de l’effet des pratiques sur les bilans de C pour la Politique Agricole Commune (PAC)
- pour quantifier l’évolution des stocks de C pour les marchés du C en agriculture.
Cet indicateur ayant été au préalable testé sur de petites zones en Europe, un des objectifs du projet SOCCROP était de tester la possibilité de l’appliquer sur de vastes territoires et dans des contextes pédoclimatiques plus contrastés (i.e. sur plusieurs continents).
Cet indicateur est calculé en utilisant la chaîne de traitement iota2 à partir des images Sentinel-2 de niveaux 2A afin d’estimer la fixation nette du CO2 trimestrielle sur un an. L’indicateur du projet SOCCROP est basé sur une méthodologie très similaire à celle de l’indicateur “Carbon Tier 1” (CT1) développé dans le cadre du projet H2020 NIVA. Le CT1 NIVA avait été développé en se basant sur la relation empirique décrite par Ceschia et al. (2010) reliant le flux net annuel de CO2 (NEP, pour Net Ecosystem Production) aux nombres de jours où la végétation est photosynthétiquement active (NDAV pour “Number of days of active végétation”) (Figure 1).
 Figure 1: Flux net annuel de CO2 en fonction des jours où la végétation est active
Figure 1: Flux net annuel de CO2 en fonction des jours où la végétation est active
Cette relation s’appuie sur une quarantaine d’années de mesures de flux net de CO2 obtenues par la méthode d’Eddy covariance des fluctuations turbulentes, cumulées sur une quinzaine de sites en Europe (couvrant une large gamme de pédoclimats et types de culture). Cette relation est applicable aux principales grandes cultures en Europe. L’indicateur NIVA CT1 utilise donc cette relation relativement simple pour estimer le flux net de CO2 à partir de l’observation du nombre de jours où la végétation est active (NDAV) :
NEP = a · NDAV + b (1)
où les paramètres a et b ont été calibrés sur des mesures de flux du réseau ICOS réalisées en Europe selon
 et
et  avec des erreurs respectives de
avec des erreurs respectives de  et
et  . Une expression analytique de l’incertitude peut être dérivée pour cet indicateur. Elle combine l’incertitude intrinsèque du modèle de régression (contenue dans l’incertitude des paramètres) avec l’incertitude sur la mesure du NDAV. Elle s’écrit :
. Une expression analytique de l’incertitude peut être dérivée pour cet indicateur. Elle combine l’incertitude intrinsèque du modèle de régression (contenue dans l’incertitude des paramètres) avec l’incertitude sur la mesure du NDAV. Elle s’écrit :
A ce stade, l’idée naturelle est d’utiliser la télédétection pour estimer le NDAV. Cela repose toutefois sur l’hypothèse forte que la végétation verte observée par satellite est toujours active d’un point de vue photosynthèse. A partir d’images optiques, on produit un indice de végétation comme le NDVI. Dans le cadre du CT1 NIVA, nous avons fait l’hypothèse que le NDAV est bien approximé en comptant le nombre de jours où le NDVI est supérieur ou égal à 0.3 qui est une valeur typique caractérisant un sol nu.
Cependant, dans le cadre du projet SOCRROP, plusieurs améliorations ont été suggérées pour améliorer la précision de l’indicateur. En particulier la prise en compte de variables climatiques comme la température de l’air et le rayonnement global. En effet, en fonction des conditions climatiques, la végétation et le sol n’ont pas le même niveau d’activité.
Ainsi, une analyse précise des données expérimentales du réseau de stations de flux Européennes labellisées par ICOS montre que le modèle initial (1) peut être modifié sous la forme suivante :
 (2)
(2)où
 est le nombre de jours vert,
est le nombre de jours vert,  est le nombre de jours durant lesquels la respiration du sol est potentiellement plus active car il fait chaud, et c et d sont des paramètres de régression. Dans ce contexte, est défini comme le nombre de jours où NDVI >0.3. est définie comme le nombre de jours tel que NDVI <0.3 et tel que le rayonnement global est supérieur à un certain seuil
est le nombre de jours durant lesquels la respiration du sol est potentiellement plus active car il fait chaud, et c et d sont des paramètres de régression. Dans ce contexte, est défini comme le nombre de jours où NDVI >0.3. est définie comme le nombre de jours tel que NDVI <0.3 et tel que le rayonnement global est supérieur à un certain seuil  . La calibration de ce modèle sur les données flux du réseau ICOS permet d’obtenir que
. La calibration de ce modèle sur les données flux du réseau ICOS permet d’obtenir que  ,
,  et
et  . Comme pour l’indicateur originel, l’expression analytique de l’incertitude peut être dérivée comme :
. Comme pour l’indicateur originel, l’expression analytique de l’incertitude peut être dérivée comme : (3)
(3)Dans le cadre du projet SOCCROP, c’est l’indicateur (2) avec son incertitude (3) qui sont considérés. Cependant, pour des raisons d’analyse, l’information du nombre de jours de vert peut se révéler intéressante. Ainsi, il a aussi été décidé de conserver le nombre de jours de vert par trimestre.
Enjeux du projetL’enjeu essentiel de ce projet pour l’équipe CS GROUP était de démontrer le passage à l’échelle du code développé par l’INRAe sur un environnement cloud en optimisant les temps de calcul et les coûts associés. Pour démontrer ce passage à l’échelle, 180 tuiles Sentinel-2 ont été produites avec cette chaîne. Ces tuiles couvrent, sur une année agricole entière, 4 pays européens (Belgique, Espagne, Italie et Pays-Bas) ainsi que qu’un ensemble de zones éco-climatiques variées en Australie, au Brésil, aux États-Unis (plus précisément en Géorgie au cœur de la Corn Belt) et au Sénégal.




Figure 2 : Répartition des tuiles
Ce démonstrateur a été déployé sur l’infrastructure d’AWS, sur leur centre de calcul de Frankfurt pour bénéficier d’un accès optimisé aux données Sentinel-2 et de leur service d’orchestration de traitement serverless et managé Fargate. Pour ce faire, les chaînes de traitements MAJA et iota2 ont été instanciées et configurées pour produire rapidement les cartes d’indices voulues en optimisant les coûts. L’objectif final de cette démonstration étant d’anticiper et d’estimer le coût d’une production annuelle de l’indice SOCCROP sur l’ensemble des surfaces continentales.
Aspects techniques de la chaîne de traitement SOCCROPLa chaîne de traitement SOCCROP, mise en œuvre par CS Group, est constituée de 2 blocks de traitements, illustrée dans la figure 2, permettant la récupération des données Sentinel-2 et la production de l’indice.
 Figure 3 : Schéma des différents blocs de la chaîne de traitement SOCCROP
Figure 3 : Schéma des différents blocs de la chaîne de traitement SOCCROP
Pour les données Sentinel-2 L2A non disponibles sur le site THEIA, la chaîne MAJA est utilisée pour produire des réflectances de surface (niveau 2A) à partir des images Sentinel-2 de niveau 1C. La chaîne MAJA a été choisie car elle permet la détection précise des nuages et de leurs ombres ainsi que la correction des effets atmosphériques sur des séries temporelles d’images. La précision des masques de nuages obtenus par MAJA offre une meilleure précision à l’indicateur SOCCROP qui est très sensible aux altérations du signal (nuage, saturation, ombre). Cette précision est nécessaire car elle évite les propagations d’erreurs lors d’étapes comme le sur échantillonnage temporel.
De plus, MAJA, dans ses dernières versions, offre la possibilité de ne produire qu’une partie des sorties (réflectances de surface ou masques) ce qui permet d’optimiser les temps de production et de réduire les volumes de donnés à stocker sur une année. En effet, seules les bandes rouges et proche-infrarouges et 3 masques (les masques de nuage, de saturation et de bord) sont nécessaires pour le calcul de l’indice SOCCROP par « iota2 ».
Le second pipeline encapsule la chaîne iota2 qui calcule l’indice de carbone à partir des bandes rouges et proche-infrarouges des produits L2A. La boite à outils iota2 dispose de nombreuses fonctions permettant entre autres de calculer des cartes d’indices spectraux. La chaîne gère de manière automatique les données d’entrées, la configuration de la méthode d’interpolation temporelle et de correction des nuages. Elle offre également la possibilité d’exploiter des données tierces, comme les informations d’ensoleillement et de température disponible dans les données ERA5. De même, pour alléger les coûts de stockage et de calcul, iota2 a été modifié pour ne prendre en compte que les bandes et les masques nécessaires. Grâce à ces améliorations, l’espace stocké des images a pu être réduit de moitié et le temps de production des cartes diminué significativement. Le traitement par tuile natif de iota2 et les traitements hautement parallélisés offert par l’OrfeoToolBox [https:] bibliothèque de traitement d’images sur laquelle les deux chaînes de traitement sont basées, ainsi que les capacités de distribution de traitements du service Fargate d’AWS ont permis de réaliser la production annuelle sur les 180 tuiles en un peu moins d’une semaine (hors temps de récupération des produits L2A depuis Theia).
Au final, les cartes trimestrielles d’indice carbone SOCCROP sont produites sous la forme d’une image multi–bandes :
- Bande 1 : Nombre de jour de vert pour le premier trimestre
- Bande 2 : Nombre de jour de vert pour le deuxième trimestre
- Bande 3 : Nombre de jour de vert pour le troisième trimestre
- Bande 4 : Nombre de jour de vert pour le quatrième trimestre
- Bande 5 : Indicateur de flux net annuel de CO2 (gC/m²) (Equation 3)
- Bande 6 : Incertitude de l’indicateur (Equation 4)


Figure 3 : Cartographie du flux net annuel de CO2 pour l’année 2019 en tC de CO2/ha à l’échelle pixel Sentinel 2 (10m) (Gauche). Cartographie du flux net annuel de CO2 pour l’année 2020 (Droite). Les trois lettres indiquées pour chaque culture correspondent aux codes de cultures du RPG : MIS pour maïs grain, BTH pour blé tendre d’hiver, CZH pour colza d’hiver, SOG pour sorgho, PPH pour prairie permanente, LUZ pour luzerne, SOJ pour soja, MLO pour mélange d’oléagineux, TRN pour tournesol…voir [https:]Le tableau 1 présente les temps moyens de traitement pour chaque étape du pipeline. Le temps requis pour le traitement par MAJA est relativement long dans la mesure où une année entière de données Sentinel-2 est traitée d’un trait. Un découpage de la période temporelle pourrait être réalisé pour distribuer ces calculs, mais cela peut avoir un impact sur la qualité des produits. Les cartes de carbone sont produites en environ 7h par iota2. Ici la majorité du temps est dépensée dans l’interpolation temporelle de la série annuelle.
Temps de traitements des données L1C (peps)
Temps de traitement des données L2A (théia)
Traitement par MAJA : 72h
Téléchargement L2A : 7h
Traitement iota2 : 7h
Traitement iota2 : 7h
Temps de traitement d’une tuile L1C : 79h
Temps de traitement d’une tuile L2A : 14h
Tableau 1 : Coût d’exploitation d’une tuile pour une année de données Sentinel-2, dans le cadre SOCCROP
Conclusion et perspectivesLa collaboration entre l’équipe CS GROUP et l’INRAE a permis de démontrer la possibilité d’un passage à l’échelle du code développé par l’INRAe sur un environnement cloud en optimisant les temps de calcul et les coûts associés. Cet outil nous a permis d’estimer les flux nets annuel de CO2 des principales grandes cultures sur une bonne partie de l’Europe de l’Ouest et sur plusieurs autres zones test dans le monde grâce à l’utilisation des données Sentinel-2 et de la chaine iota2. L’indicateur a montré une bonne cohérence avec les pratiques connues sur le terrain comme la mise en œuvre de cultures intermédiaires (ex. en Bretagne ou en Géorgie).
C’est donc une approche assez opérationnelle permettant d’estimer un indicateur lié au bilan C des grandes cultures dans une optique de versement de primes environnementales (éco-schèmes) pour la PAC ou dans un contexte d’inventaires nationaux d’émissions de GES. Cependant cette approche ne permet pas de prendre en compte l’effet de l’ensemble des pratiques sur les bilans C des parcelles. Pour ce faire, il faudrait intégrer au calcul de l’indicateur des données relatives aux récoltes et aux amendements organiques (ce qui correspond à la méthode TIER 2 du projet NIVA). C’est cette méthode qui serait à privilégier dans le cadre d’un financement des agriculteurs en fonction de la quantité de carbone qu’ils stockent. Pour y parvenir, les agriculteurs et les autorités devraient s’accorder pour que les données de pratiques soient accessibles à l’échelle de la parcelle.
L’approche a toutefois montré ses limites dans les zones à fort ennuagement comme en Belgique ou au Brésil. Pour une production opérationnelle à l’échelle globale, il serait donc nécessaire d’utiliser des données satellitales radar (ex. Sentinel-1) en complément des données optiques Sentinel-2. L’utilisation des donnes Sentinel-1 pour interpoler de manière opérationnelle les trous dans les séries temporelles de NDVI issues de Sentinel-2 est explorée par plusieurs unités de recherches. Ce n’est donc probablement qu’une question de temps avant que l’approche mise en œuvre dans le cadre de SOCCROP puisse être appliquées de manière opérationnelle à l’échelle globale en s’appuyant sur l’utilisation combinée des données Sentinel 1 et 2.
ContributeursPour le CESBIO-INRAe: Ludovic Arnaud, Mathieu Fauvel et Eric Ceschia
Pour CS-Group: Alice Lorillou, Mickael Savinaud et Benjamin Tardy
-
CumaCalc : un outil de calcul pour établir les coûts de revient prévisionnels d'investissement en CUMA
sur Makina CorpusSuite à la création de mycumalink pour Fédération Nationale des CUMA, une plateforme de mise en relation et la mutualisation de matériel agricole des C
-
11:17
Le Satellite Pléiades Neo : L’Ère de l’Imagerie Terrestre de Haute Résolution
sur Veille cartographieCet article Le Satellite Pléiades Neo : L’Ère de l’Imagerie Terrestre de Haute Résolution est apparu en premier sur Veille cartographique 2.0.
Depuis leur lancement en avril 2021, les satellites Pléiades Neo, exploités par Airbus Defence and Space, ont apporté une révolution dans le domaine de l’observation de la Terre. Cette nouvelle génération de satellites d’observation offre des capacités inégalées en matière d’imagerie terrestre de haute résolution. Leur technologie avancée, leur agilité et leur précision font de […]
Cet article Le Satellite Pléiades Neo : L’Ère de l’Imagerie Terrestre de Haute Résolution est apparu en premier sur Veille cartographique 2.0.
-
14:12
Les SIG au service de l’agriculture : le Drone Agricole d’ESRI
sur Veille cartographieCet article Les SIG au service de l’agriculture : le Drone Agricole d’ESRI est apparu en premier sur Veille cartographique 2.0.
Alors qu’un précédent article vous avez présenté les bénéfices des systèmes d’information géographique dans l’agriculture moderne, nous revenons aujourd’hui sur ce sujet pour aborder de manière plus spécifique la nouvelle avancée de la société ESRI : le Drone Agricole. Comme mentionné précédemment, les Systèmes d’Information Géographique (SIG) associés aux dernières avancées technologiques jouent aujourd’hui un […]
Cet article Les SIG au service de l’agriculture : le Drone Agricole d’ESRI est apparu en premier sur Veille cartographique 2.0.
-
10:31
La cartographie au service des secouristes : le cas du séisme au Maroc
sur Veille cartographieCet article La cartographie au service des secouristes : le cas du séisme au Maroc est apparu en premier sur Veille cartographique 2.0.
La carte : outil indispensable pour faciliter l’action des secours Lors de catastrophes naturelles impliquant fortement la vie des populations, la cartographie joue un rôle majeur dans l’efficacité et la rapidité d’intervention des secours. C’est pourquoi il est nécessaire que les cartographes lors des gestions de crise prennent le temps de modéliser ces cartes. Le […]
Cet article La cartographie au service des secouristes : le cas du séisme au Maroc est apparu en premier sur Veille cartographique 2.0.
-
6:45
Cartes et données sur le séisme au Maroc (septembre 2023)
sur Cartographies numériques
Le Maroc a été touché dans la nuit du 8 au 9 septembre 2023 par un séisme d'une magnitude de 6,8 à 7 sur l'échelle de Richter dans la province d'Al-Haouz, au sud-ouest de la ville de Marrakech. Près de 3 000 personnes ont perdu la vie et on dénombre plus de 5 500 blessés. L’épicentre a été localisé dans la chaîne du haut Atlas, à une quarantaine de kilomètres du Djebel Toubkal, le point culminant du Maroc. L’épicentre est proche d’Amizmiz et à environ 70 km au sud-ouest de Marrakech et 140 km au nord-ouest de Ouarzazate. La profondeur du foyer a été estimée à 25 km. La secousse a été ressentie à Rabat, à Casablanca, à Agadir et à Essaouira, semant la panique parmi la population. Le séisme a été aussi ressenti dans le sud du Portugal et de l’Espagne, en Algérie et dans les îles de Lanzarote, de Fuerteventura et à Madère. Mais c'est dans le Haut-Atlas que les dégâts sont les plus importants. La province d'Al-Haouz, rurale et assez difficile d'accès, par ailleurs destination de prédilection pour les amoureux de la nature et du tourisme de montagne, déplore plus de la moitié des victimes.
Carte d'intensité du séisme au Maroc en septembre 2023 (Source : USGS, Wikipédia)
1) Traitement médiatique de la catastrophe
« Les images du séisme qui a fait plus de 2000 morts » (Le Parisien). Nombreux sont les Marocains à avoir passé la nuit dans la rue, par crainte de répliques. « Séisme au Maroc : une tragédie nationale en images » (Slate).
« Toulia, rescapée devenue le visage de la souffrance » (BFM-TV). Au lendemain du drame, son visage a fait la Une de nombreux médias français et étrangers. Elle est désormais sans domicile à Marrakech. Elle n'est "pas très heureuse d'être le symbole de tout ça". Toulia, une mère de famille âgée de 55 ans, est devenue sans le savoir l'un des visages horrifié de la catastrophe qui a frappé le Maroc. La même image médiatique a été reprise par Libération, BBC News, Washington Post, The Telegraph...
« Cartes : là où le tremblement de terre a frappé le Maroc » (New York Times) avec carte des séismes majeurs au Maroc depuis 1900. Des informations diffusées sur les réseaux sociaux ont indiqué que certains villages n'avaient toujours pas reçu d'assistance plus d'un jour après le séisme. La région compte de nombreuses maisons en briques crues et peu d’infrastructures parasismiques. En raison des routes coupées, de nombreux villages du haut Atlas restent isolés. Des dégâts ont aussi été signalés dans la vieille ville historique de Marrakech. La Médina, site classé au patrimoine mondial de l'UNESCO datant de plusieurs siècles et entourée de murs en grès rouge, a été endommagée et certains bâtiments se sont entièrement effondrés.
« Séisme au Maroc : pourquoi la catastrophe était imprévisible » (TV5 Monde).
Le Maroc se trouve à la frontière de la plaque tectonique africaine, qui s’étend de l’océan Atlantique jusqu’à la Syrie en traversant la mer Méditerranée. Cette situation géographique expose régulièrement le royaume à des séismes dévastateurs, comme celui d'Agadir en 1960, qui a fait plus de 12 000 morts et détruit 75% de la ville ; ou encore à Al Hoceïma en 2004, qui a causé la mort la mort de 628 personnes et des dégâts matériels considérables. Florent Brenguier, de l’Institut des Sciences de la Terre de l’Université de Grenoble, précise cependant que la puissance du séisme de vendredi est inhabituelle : “les zones les plus concernées par les secousses sismiques sont situées à 25 kilomètres plus au Nord, vers les côtes et le Détroit de Gibraltar. Là, l’épicentre ne se situe pas à l'interface entre deux plaques tectoniques.
« Le tremblement de terre a pris les scientifiques de court par sa violence dans cette zone » (20 Minutes).
Le Maroc est exposé aux séismes, mais ils surviennent plutôt habituellement 500 km plus au nord, vers Gibraltar, dans une région frontière entre les plaques tectoniques africaine et européenne. On parle d’une bande de 50 à 100 km où l’activité sismique est soutenue, avec des mouvements d’un côté et de l’autre de cette frontière très rapides à l’échelle de la sismologie. De l’ordre de plusieurs millimètres par an. Certes, le Haut Atlas n’est pas très loin de cette zone frontière. Mais l’activité sismique y est considérée jusque-là comme modérée, avec historiquement des séismes de magnitude 4, mais pas plus.
« Séisme historique au Maroc avec une magnitude surprenante pour les experts ! » (Futura Science). Avec une magnitude de 6,8 à 6,9, il s’agirait là du plus puissant tremblement de terre enregistré jusqu’à présent dans le pays.
« Le tremblement de terre a pris les scientifiques de court par sa violence dans cette zone » (20 Minutes).
Le Maroc est exposé aux séismes, mais ils surviennent plutôt habituellement 500 km plus au nord, vers Gibraltar, dans une région frontière entre les plaques tectoniques africaine et européenne. On parle d’une bande de 50 à 100 km où l’activité sismique est soutenue, avec des mouvements d’un côté et de l’autre de cette frontière très rapides à l’échelle de la sismologie. De l’ordre de plusieurs millimètres par an. Certes, le Haut Atlas n’est pas très loin de cette zone frontière. Mais l’activité sismique y est considérée jusque-là comme modérée, avec historiquement des séismes de magnitude 4, mais pas plus.
« Les séismes de cette ampleur sont “rares mais pas inattendus” au Maroc » (Courrier international). Le séisme qui a secoué le Maroc vendredi serait le résultat de la rupture d’une faille inverse, le type de faille qui engendre les montagnes. La faible profondeur de son foyer et sa proximité avec une zone densément peuplée aux constructions fragiles expliquent l’ampleur des dégâts.
« Séisme au Maroc : Mohammed VI en première ligne » (Le Point). Mohammed VI a décrété un deuil national de trois jours, « avec mise en berne des drapeaux sur tous les bâtiments publics » ainsi que « l'accomplissement de la prière de l'absent dans l'ensemble des mosquées du royaume ». Face à l'ampleur des dégâts, la plus haute autorité de l'État a décidé de mettre en place immédiatement une commission interministérielle. Elle sera chargée du déploiement d'un programme d'urgence de réhabilitation et d'aide à la reconstruction des logements détruits dans les zones sinistrées dans les meilleurs délais. Mohammed VI se montre aussi soucieux de contrôler son image dans les médias qu'il semble se méfier de l'aide internationale. « Séisme au Maroc : le silence gênant de Mohammed VI » (France-Info).
« Un premier bilan du séisme au Maroc en 10 points et 5 cartes et graphiques inédits » (Le Grand Continent). L’efficacité de la réponse politique au séisme et à ses conséquences sociales pourrait se transformer en enjeu clef de politique intérieure. Le président turc Erdogan qui a remporté les élections de mai dernier, avait par exemple vu sa campagne mise en difficulté par les critiques de sa réponse au séisme et du défaut d’anticipation attribué à son gouvernement. Au Maroc, le séisme de 2004 à Al-Hoceima dans la région du Rif, qui avait fait le plus grand nombre de victimes depuis le séisme d’Agadir de 1960, a été suivi de séquences de protestation des populations de cette région qui compte parmi les plus pauvres du Maroc, dénonçant l’arrivée tardive des secours et la mauvaise gestion du gouvernement — région où devait naître 12 ans plus tard, en 2016, l’important mouvement populaire du Rif.
« À Marrakech, la peur des répliques, mais aussi celle de voir fuir les touristes » (Le Monde). Marrakech, qui compte un peu moins d'un million d'habitants, a été lourdement frappée par ce tremblement de terre, puisqu'elle n'est située qu'à quelques dizaines de kilomètres au nord de l'épicentre. Les Français sont nombreux à détenir des riads qu’ils louent sur place aux touristes. Ils tentent de rassurer leur clientèle et d’éviter que suite au séisme les voyageurs ne se détournent d’une destination qui retrouvait des niveaux de fréquentation d’avant le Covid. « Un moment de panique: au Maroc, un Français, propriétaire d'un hôtel près de Marrakech, a tout perdu » (BFM-TV).
« Pourquoi certains villages n'ont-ils pas été immédiatement secourus ? » (BFM-TV). Difficilement accessibles par les routes, qui ont été endommagées ou obstruées par des blocs de pierre, des villages isolés du Maroc sont toujours dans l'attente des secouristes, plus de 48 heures après le tremblement de terre.
« Une ONG française accuse Marrakech de bloquer l'aide humanitaire » (BFM-TV). Le président de l'association Secouristes sans frontières assure que ses équipes sur place n'ont "toujours pas" reçu l'accord du gouvernement marocain pour intervenir et être "bloquées" par Marrakech. Le Maroc a accepté l'aide officielle de quatre pays, l’Espagne, le Royaume-Uni, le Qatar et les Emirats arabes unis. La France n'est pour l'instant pas dans le lot. Plus de 830 000 Marocains vivent en France tandis que plus de 30 000 Français vivent au Maroc, selon les données des autorités françaises.
« Rabat ne veut pas se comporter en pays meurtri que le monde viendrait charitablement secourir » (Le Figaro). Sylvie Brunel, ancienne présidente d'Action contre la Faim, estime que face aux offres d’aide humanitaire aux arrière-pensées géopolitiques, il est légitime que le Maroc se positionne en État souverain. « Les Marocains ont l'expérience des séismes... Il faut faire très attention car l'expérience des séismes montre que le grand risque, c'est l'afflux de bonnes volontés qui provoque un engorgement de l'aide et une impossibilité à agir efficacement... Le Maroc ne veut pas se retrouver dans la situation du proverbe qui dit que "la main qui donne est au dessus de la main qui reçoit" » (interview pour BFM-TV). Géopolitique et gestion des risques : « Pourquoi le Maroc n'accepte pas l'aide de la France ? » (Europe 1). « Maroc : La diplomatie du séisme » (débat sur Public Sénat).
« Maroc : géopolitique d'une catastrophe » (Le Dessous des cartes). Comment expliquer que la France ne fait pas partie des premiers pays sélectionnés pour apporter de l’aide ?
« Tremblement de terre au Maroc : le difficile acheminement de l’aide internationale humanitaire » (Libération). » Les premières vingt-quatre à quarante-huit heures sont cruciales pour sauver des vies. Des voix s'élèvent pour faire remarquer qu'en cas de séisme les premières heures sont déterminantes et qu'il peut être dommageable d'attendre une réponse officielle pour décider si le pays a besoin d'aide.
« L'UNICEF estime qu'environ 300 000 personnes n'ont plus de maisons. Parmi elles, il y aurait environ 100 000 enfants » (BFM-TV). « 530 écoles et 55 internats endommagés selon le ministère marocain de l'Education nationale » (France-Info).
« Séisme au Maroc : la technologie peut-elle aider à prévoir ou à prévenir les séismes ? (France-Info). Il faut savoir qu’aujourd’hui, presque tous les mobiles ont un capteur de mouvements suffisamment sensible pour détecter des ondes sismiques. En analysant les vibrations d’un seul téléphone, il y aurait pas mal de fausses alertes. Mais comme cette détection est désormais intégrée d’usine à tous les mobiles Android, cela permet de s’appuyer sur des milliers de téléphones. Notamment, les plus proches de l’épicentre pour prévenir tous les autres. Encore une fois, ce n’est pas une prédiction, mais une alerte.
« Le séisme au Maroc a aussi dévasté le patrimoine historique, endommageant palais, mosquées et minarets » (Le Monde). Au moins vingt-sept monuments emblématiques de la région de Marrakech ont été détruits ou endommagés par le tremblement de terre qui a tué plus de 2 900 personnes. « Séisme au Maroc : l'Unesco dresse un premier bilan des monuments touchés » (LeMatin.ma).
« Comment se relever ? Le défi maintenant, c’est que tout ne soit pas reconstruit en béton » (Libération). L’entrepreneur Oussama Moukmir, fondateur d’une coopérative dédiée à la bioconstruction, promeut un bâti conforme aux normes sismiques, mais confectionné à partir de matériaux locaux et durables, en usant de méthodes anciennes. « Séisme au Maroc : les maisons en terre crue critiquées à tort » (Reporterre).
« Le phénomène controversé des "lumières sismiques" intrigue internautes et scientifiques » (France-Info). Depuis le séisme du 8 septembre au Maroc, des vidéos amateurs montrant des phénomènes lumineux présentés comme liés au tremblement de terre circulent sur les réseaux sociaux. Ils sont parfois décrits comme des "lumières sismiques", un phénomène que la science peine à expliquer.
« Séisme au Maroc : raconter un événement exceptionnel à l’étranger, le défi de la presse régionale » (La rvue des médias). Sans bénéficier des mêmes moyens que la presse nationale, les quotidiens régionaux déploient des techniques pour articuler ces actualités à l'échelle locale. Aussi exceptionnel soit-il, un événement survenu à l’étranger n’est pas forcément traité en une. Pour les inondations survenues en Libye quelques jours après le séisme au Maroc, par exemple, la couverture médiatique de la PQR est moindre.
2) Pistes d'analyse scientifique en termes d'aléa/risque/vulnérabilité et enjeux
Séisme au Maroc : "C'est une rareté d'avoir de si gros séismes dans cette zone" (France24)Le Centre national pour la recherche scientifique et technique (CNRST) basé à Rabat a indiqué que le séisme était d'une magnitude de 6,8 degrés sur l'échelle de Richter et que son épicentre se situait dans la province d'Al-Haouz, au sud-ouest de la ville de Marrakech. Il s'agit du plus puissant séisme à frapper le royaume à ce jour. Un phénomène "surprenant", selon Florent Brenguier, sismologue à l’Institut des Sciences de la Terre de l’Université de Grenoble, car la zone où se trouve l'épicentre ne se situe pas "à l'interface entre deux plaques tectoniques".
« Séisme au Maroc. "Marrakech n’est pourtant pas la zone la plus active du pays" » (Challenge.ma).
En Turquie, on était sur un mouvement horizontal, puisque la Turquie s’échappe en gros vers l’ouest, elle « part » vers la Grèce. Il y a un coulissement horizontal des plaques. Là, on est plutôt sur une convergence entre l’Afrique et l’Eurasie ou l’Ibérie, la partie espagnole, et sur des failles chevauchantes : le relief du Haut-Atlas est en train de monter sur l’avant-pays au nord. Mais on est toujours dans un contexte de limite de plaques. Il faut voir à quelle magnitude le séisme va se fixer. On est autour de 6,8 ou 6,9, ce qui est une intensité assez forte. Cela correspond en gros à un déplacement moyen sur la faille de l’ordre d’un mètre, en quelques secondes, sur plusieurs kilomètres. Forcément, ça secoue énormément la région (Philippe Vernant, enseignant-chercheur à l’université de Montpellier (sud) et spécialiste en tectonique active, notamment au Maroc).
En 2011, un nouveau règlement de construction parasismique (RPS 2000) a été mis en place, et est appliqué dans la majorité des nouvelles constructions des zones urbaines marocaines. Mais selon Philippe Guéguen, directeur de recherche à l’Institut des Sciences de la Terre de l’Université de Grenoble, de nombreux bâtiments plus anciens et monuments historiques échappent à ces nouvelles normes : “la réglementation n’est pas faite pour ce type de bâtiment, il n’y a pas de règle particulière. Il faudrait les renforcer, ou les remplacer par des bâtiments plus récents, plus modernes. Mais personne ne fait ça. Et la mise en application des normes demande du temps.”
Michel Sébrier, Lionel Siame, El Mostafa Zouine, Thierry Winter, Yves Missenard, Pascale Leturmy (2006). Tectonique active dans le Haut Atlas marocain. Comptes Rendus Geoscience, Vol. 338, 1–2, January 2006, Pages 65-79. La révision critique des données sismologiques et structurales, associée à l'acquisition de nouvelles données topographiques, géomorphologiques et sur la géologie du Quaternaire permet de situer les failles actives majeures du Haut Atlas aux niveaux des failles bordières nord et sud. La segmentation de ces failles suggère qu'elles ont le potentiel pour générer des séismes de magnitude 6,1 à 6,4.
Taj-Eddine Cherkaoui & Ahmed El Hassani, Seismicity and Seismic Hazard in Morocco 1901-2010, Bulletin de l’Institut Scientifique de Rabat, section Sciences de la Terre, 2012, n° 34, p. 45-55. Voir également le site personnel de Taj-Eddine Cherkaoui sur la sismicité et l'aléa sismique au Maroc.
B. Theilen-Willige, R. Löwner, F. El Bchari, H. Wenzel (2013). Remote Sensing and GIS Contribution to the Detection of Areas Susceptible to Local Site Effects during Earthquakes and to Tsunami Waves in W-Morocco. Vienna Congress on Recent Advances in Earthquake Engineering and Structural Dynamics 2013 (VEESD 2013). Lorsque des tremblements de terre ou des tsunamis se produisent, des actions immédiates et efficaces sont nécessaires pour réduire les dommages matériels et les pertes humaines. Les techniques de télédétection et SIG sont étudiées dans le cadre du projet W-Maroc afin de contribuer à l'inventaire systématique et standardisé des zones les plus sensibles aux mouvements du sol.
Abdelouahad Birouk, Aomar Ibenbrahim, Azelarab El Mouraouah & Mohamed Kasmi (2020). New Integrated Networks for Monitoring Seismic and Tsunami Activity in Morocco. Annals of Geophysics, 63, 2, SE220, 2020. Un certain nombre de réseaux ont été déployés pour mesurer le niveau de la mer et surveiller l'activité sismique en temps réel au Maroc, qui a connu plusieurs tremblements de terre destructeurs au cours de son histoire. Ce nouveau réseau sismique consiste en un hub pour la gestion des données satellites et les 48 stations sismiques au sol, toutes reliées à une Unité centrale d’acquisition, de traitement et de stockage des données à Rabat. Par rapport au réseau précédent, le nouveau réseau a permis d'enregistrer cinq fois plus d'événements par an et a contribué à abaisser le seuil des magnitudes détectées. Une surveillance 24h/24 et 7j/7 a été mise en place pour cette surveillance et pour fournir une alerte sismique rapide aux autorités nationales compétentes dans le cadre de la gestion des risques sismiques.
Pour comprendre l'origine du séisme, l'Observatoire éducatif méditerranéen (EdumedObs) met à la disposition des enseignants un dossier à ouvrir dans Tectoglob3D. L'outil se présente comme un globe virtuel en 3D. Le logiciel Tectoglob3D permet d'étudier des sismogrammes, de réaliser des coupes, d'ajouter des foyers et de faire de la tomographie sismique. L'application peut être utilisée directement en ligne sur le site SVT de l'académie de Nice (voir cette vidéo de présentation).
« Maroc, Lybie, Grèce : plus la société est inégalitaire, plus la catastrophe est meurtrière » (Futura Sciences). L’investissement dans les biens communs, la répartition des richesses et celle du pouvoir déterminent la vulnérabilité des populations aux catastrophes naturelles, explique Jean-Paul Vanderlinden qui est professeur en économie écologique à l’Université de Versailles Saint-Quentin-en-Yvelines et membre du laboratoire CEARC (cultures, environnements, Arctique, représentations, climat) de l’Observatoire de Versailles Saint-Quentin. Ses travaux portent sur l’analyse du risque existentiel au niveau local et son articulation avec le changement climatique.
« Pour une analyse géographique des catastrophes : le cas du séisme du 8 septembre au Maroc » (Le Grand Continent). David Goeury rappelle la nécessité de procéder à une analyse géographique des catastrophes pour comprendre comment peut se déployer une aide d’urgence. La polémique stérile sur l’aide internationale est venue masquer la réalité du territoire touché et les spécificités du déploiement des secours d’urgence en zone de haute montagne. L’émotion, les élans de générosité et l’incompréhension de réalités territoriales complexes ont nourri des discours particulièrement confus.
« Séisme : géopolitique du désastre marocain » (Blast). Aboubakr Jamaï, Professeur des relations internationales à Aix-en Provence, décrypte et analyse ce que cet évènement tragique révèle de la situation politique et sociale du royaume chérifien ainsi que de ses relations diplomatiques, plus que tendues, avec la France.
3) Cartes et données SIG à visualiser en ligne ou à télécharger
Cartographie du tremblement de terre par l'United States Geological Survey (USG) avec l'intensité sismique, les failles tectoniques, la densité de population, etc...
Cartographie du séisme et de la zone impactée par l'United Nations Satellite Centre (UNOSAT-UNITAR) avec analyse de la population exposée.
Ressources fournies par le Global Disaster Alert and Coordination System (GDACS).
Ressources mises à disposition par le Centre Sismologique Euro-Méditerranée (CSEM).
Données SIG sur le Maroc mises à disposition sur Humanitarian Data Exchange (HDX), site dédié au partage de données humanitaires.
Cartographie des villages en attente d'aide (fichier kml sur Google Maps).
Tous les villages et douars situés à moins de 50 km de l’épicentre du séisme (fichier kml sur Google Maps).
Cartes et données SIG élaborées par le Service de gestion des urgences CopernicusEMS (dégâts estimés à partir de l'observation d'images satellites).
Images Maxar en haute résolution diffusées en données ouvertes avec possibilité de comparer les images avant et après la catastrophe sur le visualisateur en ligne. Inscription sur le site nécessaire pour pouvoir télécharger des images prêtes à l'analyse. Voir ce tutoriel pour optimiser le téléchargement et faciliter la réutilisation des images Maxar dans Q-Gis.
Fichiers des plaques tectoniques à télécharger au format shp ou geojson. Carte des séismes dans le monde sur la période 1900-2018 disponible en pdf.
Base de données des tremblements de terre dans le monde (NCEI - NOAA) avec la géolocalisation, la magnitude, la distance du foyer par rapport à l'épicentre, les pertes humaines, les dégâts matériels.
Séisme au Maroc : la déformation du sol vue par satellite (Futura Sciences). Les secours ont eu accès rapidement aux images satellitaires de la zone dévastée par le séisme au Maroc grâce à la Charte internationale « Espace et catastrophes majeures ». Mais les satellites sont également capables d’observer très finement la déformation du sol. Des données essentielles pour mieux comprendre ce qui s’est passé dans la nuit du 8 au 9 septembre.2
Des images et des analyses à partir d'images satellites Pléiades (CNES) sont mises à disposition dans le cadre de la Charte internationale « Espace et catastrophes majeures ». Cartes réalisées par UNITAR / UNOSAT. Certaines images permettent d'étudier la déformation au sol vue depuis les satellites.
4) Utilisation de la cartographie pour organiser l'aide humanitaire
La communauté OpenStreetMap s'est mobilisée en urgence pour mettre à jour la cartographie de la zone touchée par le séisme, faciliter les secours et organiser la logistique. L'équipe humanitaire HOT Osm (@hotosm) a appellé tous les volontaires à une grande opération de cartographie collaborative dans le cadre de la procédure « Disaster Response » qu'elle a mise en place pour couvrir ce type de catastrophe. Pour participer à cette cartographie à distance : [https:]]
Données SIG déjà mises à disposition sur le site HOT Osm. Les données concernant les bâtiments sont régulièrement mises à jour.
« Dans la province d’El Haouz, dans les zones rurales, les maisons sont construites en terre, les unes à coté des autres ce qui rend parfois difficile de séparer les bâtiments de leur entourage, surtout si il y des arbres à côté. Je propose de cartographier la bâtiment selon leur contour extérieur, indépendamment de la forme intérieur du bâtiment » (témoignage de Fatima Eddaoudi responsable Tasking Manager de HOT). Les discussions portent également sur le périmètre à prendre en compte (disponible en geosjson) et l'avancée du travail de saisie cartographique qui nécessite des processus réguliers de validation (voir la grille de tâches en geojson).
Rapport d'impact 2022-23 sur les opérations conduites par HOT Osm « Cartographions notre monde ensemble »
« Qualité des données : un voyage sur la plateforme humanitaire d'OpenStreetMap » (Geotribu). Delphine Montagne parle de son travail bénévole et solidaire de validation au sein des campagnes d'HOT OSM, le volet humanitaire d'OpenStreetMap.
Réponse au tremblement de terre en Turquie et en Syrie (février 2023) : les ressources mises à disposition permettent de mettre en évidence l'intérêt de la cartographie humanitaire et l'expérience déjà acquise par HOT Osm lors du séisme en Turquie et Syrie.
Articles connexes
Cartes et données sur les séismes en Turquie et en Syrie (février 2023)
Cartes et données sur les tremblements de terre au Japon depuis 1923
Simuler des scénarios de tremblement de terre en utilisant des cartes
Un nouveau modèle de plaques tectoniques pour actualiser notre compréhension de l'architecture de la Terre
Carte-poster des tremblements de terre dans le monde de 1900 à 2018 (USGS)
Cartes-posters sur les tsunamis, tremblements de terre et éruptions volcaniques dans le monde (NOOA, 2022)
Analyser et discuter les cartes de risques : exemple à partir de l'Indice mondial des risques climatiques
Une anamorphose originale montrant l'exposition accrue des populations au risque volcanique
Les éruptions volcaniques et les tremblements de terre dans le monde depuis 1960
L'évolution de la cartographie humanitaire au sein de la communauté OpenStreetMap
-
10:20
Monter un kit de géolocalisation à haute précision
sur Geotribu Tutoriel de montage d'un kit de géolocalisation à haute précision (rover RTK) à coût limité, sans avoir à faire de soudure ni production de pièces sur mesure, juste à brancher. Variante du tutoriel de l'INRAE (projet Centipede).
Tutoriel de montage d'un kit de géolocalisation à haute précision (rover RTK) à coût limité, sans avoir à faire de soudure ni production de pièces sur mesure, juste à brancher. Variante du tutoriel de l'INRAE (projet Centipede).
-
12:42
Cartes et données sur le rugby en France et dans le monde
sur Cartographies numériquesLa Coupe du monde de rugby à XV, qui a lieu en France du 8 septembre au 28 octobre 2023, est l'occasion de s'intéresser à l'importance de ce sport à l'échelle de la France et du monde. Le rugby est devenu un sport mondialisé, mais ultra-polarisé au regard du petit nombre de pays participants. En France, ce sport s'est largement diffusé au delà de la région sud-ouest, qui reste malgré tout son fief d'origine avec des clubs historiques comme Toulouse ou Bayonne.
1) La géographie du rugby à l'échelle mondiale
Carte des pays participants à la Coupe du monde de rugby à XV 2023 (source : Wikipédia)
.jpg)
La Coupe du monde de rugby à XV est organisée tous les quatre ans depuis 1987. Depuis l’édition de 1991, cette compétition se déroule en deux phases : une phase de qualification et un tournoi final. Seules quatre nations figurent au palmarès de la Coupe du monde. La Nouvelle-Zélande a remporté trois fois le trophée en 1987, 2011 et 2015, tout comme l'Afrique du Sud en 1995, 2007 et 2019. L'Australie a gagné deux fois en 1991 et 1999 et l'Angleterre a gagné l'épreuve en 2003, seul pays de l'hémisphère Nord à s'emparer du trophée planétaire. La France a été présente trois fois en finale (1987, 1999, 2011). Malgré une ouverture aux différents continents et aux nouveaux venus par qualification, le bilan fait apparaître que la compétition est jusqu'ici dominée par cinq nations, trois de l'hémisphère Sud et deux européennes : l'Australie, la Nouvelle-Zélande, l'Afrique du Sud pour le Sud ; l'Angleterre et la France pour l'Europe. Seules ces cinq sélections nationales sont parvenues à se hisser en finale. Avec trois qualifiés en Coupe du monde, le rugby sud-américain est en pleine progression. Le Japon, qui a été le précédent pays organisateur en 2019, fait figure un peu d'exception en Asie.
Des données concernant la participation par nations, la fréquentation par nombre de spectateurs ou la présence dans les stades sont disponibles sur Wikipedia. Pour obtenir des données plus détaillées, consulter le site officiel rugbyworldcup.com.- Géographie du rugby (extrait de l'émission "Géographie à la carte", France Culture)
« En réalité, la Coupe du monde de rugby n’est pas si mondiale que ça : ce sont toujours les mêmes pays qui gagnent mais ce sont toujours aussi les mêmes qui participent. Lorsque l’on regarde quels sont les pays qui sont qualifiés pour la Coupe du monde 2023 – et la situation était similaire pour les éditions précédentes – , il y a 12 places qui sont déjà « trustées », et il n’y a que 20 nations qui participent, ce qui signifie que le reste du monde se partage seulement huit places. C’est une ouverture qui est un peu difficile. C’était le propos tenus par Jean-Pierre Augustin dans son étude géographique du rugby, qui expliquait que c’était une mondialisation inachevée et peut-être au fond, inachevable… Car cette pratique qui est née au début du XIXe siècle au Royaume-Uni s’est in fine assez peu développée. Aujourd’hui, on compte 132 fédérations nationales qui font partie de la fédération internationale, un chiffre qui, à l’échelle du sport, est tout petit, comparé à la FIFA ou à la fédération internationale de volley qui en compte plus de 220. La pratique du rugby est très ancrée dans certains pays, même si on observe un fléchissement, que les choses sont en train d’évoluer par le biais de différents canaux : la professionnalisation […], l’arrivée du rugby à 7 dans le programme olympique depuis les JO de Rio de 2016, et la féminisation, qui a permis de grossir les rangs des licencié.es et des pratiquant.e.s de rugby. »- « 10 points, 9 cartes et graphiques sur le monde du rugby » (Le Grand Continent)
Demain le XV de France défie les All Blacks pour l'ouverture de la Coupe du monde de rugby !
— Julien Migozzi (@JulienMigozzi) September 7, 2023
Mais d'ou viennent les Bleus ?
Petit thread pour explorer la géographie mondiale des 1165 joueurs du XV de France, avec ce site construit pour l'occasion : ?? [https:]]
1/9 pic.twitter.com/U3SLoLK7sw
La carte officielle de la coupe du monde de rugby : la projection d'Atlantis (1948) pic.twitter.com/JC8mrA7IdH
— Jules Grandin (@JulesGrandin) September 8, 2023
2) La géographie du rugby à l'échelle nationale
Hélène Joncheray, David Sudre et Antoine Lech, « Le monde de l’Ovalie et ses espaces », Norois, 244 | 2017.
« Le rugby en Lorraine : vers un nouvel "effet Coupe du monde" ? » (INSEE, 2015).
« Coupe du monde : le rugby a-t-il vraiment dépassé les frontières de l'Ovalie ? » (France-Info, 2023).
« Rugby : du combat celte au jeu occitan (L'Histoire).
« Rugby à la télévision : jusqu’en 1995, c’était le paléolithique » (La revue des médias).
« 200 ans de ballon ovale » (archives Gallica).
Même s'il peut exister un "effet coupe du monde", le sport ce n'est pas que la compétition et il peut être intéressant d'étudier les pratiques sportives à travers le nombre de clubs et de licenciés. Le rugby témoigne d'une diffusion à partir du Sud-Ouest, même si aujourd'hui sa pratique a tendance à se généraliser.
Part des licenciés de rugby en France métropolitaine en 2020 (source : Jean Dupin, INJEP, Data.gouv.fr)
Les données sont issues du recensement des licences et clubs auprès des fédérations sportives agréées par le ministère chargé des sports. Voir le site de l'INJEP pour utiliser les données du recensement 2021.
Il existe des inégalités entre les femmes et les hommes dans la pratique du sport. Les femmes pratiquent davantage le sport de manière encadrée ou en club, mais elles sont moins nombreuses à participer à des compétitions. Le rugby reste, avec le footbal, l'un des sports les plus inégalitaires en termes d'égalité homme/femme, si l'on prend comme critère le nombre d'inscrit.e.s par fédération sportive en France.
Le rugby, l'un des sports les moins pratiqués par les femmes (source : INJEP, 2021)
?La carte du rugby professionnel (depuis la saison 98-99 pour la première division et la saison 00-01 pour la deuxième)
— surlatouche.fr (@surlatouche_fr) May 4, 2020
31 départements sur 96 ont ainsi été représentés au niveau pro (35%) pic.twitter.com/ipMEQNn5c3
Articles connexesA l’occasion de la coupe du monde de rugby à XV qui commence aujourd’hui en France, j’ai dessiné la carte de tous les clubs emblématiques de rugby ? pic.twitter.com/mzAIGxmlIi
— Alcatela (@Alexismouss) September 8, 2023
L’Atlas des sports, le site qui interroge le monde sportif et ses dynamiques socio-spatiales
Approche multiscalaire des pratiques sportives. L'exemple des sports de « balle au pied »
La cartographie des clubs de football à travers les réseaux sociaux
Football : cartographie de tous les pays affrontés par les Bleus dans leur histoire
La cartographie du Tour de France d'hier à aujourd'hui
Cartes des pistes cyclables en Europe et en France
Classer les villes cyclables en France et dans le monde. Quels sont les indicateurs utilisés ?
Cartographier les espaces du tourisme et des loisirs -
8:26
L’Atlas des sports, le site qui interroge le monde sportif et ses dynamiques
sur Cartographies numériques
Véritable observatoire des pratiques sportives, l'Atlas des sports propose de représenter les différentes cultures du domaine et leurs formes de spatialisation. Les articles enrichis de figures analysent les combinaisons spécifiques à chaque pratique sportive, comme des comportements, des systèmes de valeurs et les rapports au corps qui sont mis en œuvre dans les situations motrices et les espaces appropriés.Ce projet qui rassemble de multiples contributions émanant de chercheurs et de chercheuses en sciences sociales est porté par des scientifiques du laboratoire Espaces et SOciétés (CNRS/Institut Agro/Le Mans Université/Nantes Université/Université d’Angers/Université de Caen Normandie/Université Rennes 2). Le laboratoire ESO propose par ailleurs une série d'Atlas sociaux sur Angers, Caen, Le Mans, Nantes et Rennes (voir ce billet de présentation).
Les cultures sportives, combinaisons spécifiques à chaque sport de pratiques, de comportements, de systèmes de valeurs et de rapports au corps (S. Darbon, 2010) mettent en œuvre des situations motrices dans des espaces appropriés (J-P Augustin, 2011). Ainsi, l’inscription des pratiques sportives dans des lieux nécessite des mises en ordre et des aménagements spatiaux. La sportivation qui caractérise le monde contemporain rassemble à la fois des sports de compétition et des ludo-sports, les activités sportives évoluant désormais à l’intersection entre ces deux formes de pratique, qu’elles soient individuelles ou collectives. C’est pourquoi les finalités de cet atlas sont à la fois de favoriser la création d’un réseau informel de chercheurs et de chercheuses, appartenant à différentes disciplines scientifiques et travaillant sur les multiples dimensions de la spatialisation de l’objet « sport », et d’analyser ce que les diverses contributions peuvent apporter les unes par rapport aux autres.
Un projet organisé autour de 12 thématiques :
- Patrimoine, patrimonialisation, enjeux de mémoire et hauts lieux du sport
- Diffusion spatiale des sports
- Pratiques sportives: inégalités et différenciations
- Mobilités et circulations des sportifs
- Fabrique des territoires du sport
- Les marchés du sport: enjeux économiques, flux financiers
- Polarisations, métropolisations
- Espaces du sport. Usages et conflits d’usages
- Enjeux géopolitiques et politiques
- Spectacles sportifs: du local au global
- Territoires du sport santé
- Problèmes sociaux
Ludovic Lestrelin, Yvonnick Le Lay, François Madoré et Stéphane Loret coordonnent le projet. Les auteur·e·s réalisent les traitements statistiques et cartographiques de leurs planches de manière autonome ou avec le soutien de Simon Charrier et Stéphane Loret. Stéphane Loret a mis en œuvre le site web du projet.
Parmi les premiers articles à découvrir :
- Les marathons en France : entre effet de métropolisation et dissémination
- Le surf fédéral en France : une activité sportive de moins en moins «régionalisée»
- De la réinvention touristique et culturelle des hauts-lieux de la production des sports équestres: le cas des Haras nationaux en France
- Castres Olympique, une particularité dans le Top 14
- La course à pied en France, marqueur de la ruralité
- Le Paris Saint-Germain : d’un club de football francilien à une franchise sportive mondiale
- L’irréversible métropolisation du rugby d’élite masculin français
Bibliographie :- Augustin J.-P., « Qu’est-ce que le sport ? Cultures sportives et géographie », Annales de géographie [En ligne] 2011/4 n° 680, pp. 361-382 http://www.cairn.info/revue-annales-de-géographie-2011-4-page-361.htm
- Darbon S., « Les pratiques sportives au filtre de l’anthropologie », La revue pour l’histoire du CNRS [En ligne] n° 26, 2010, pp. 24-29, DOI : 10.4000/histoire-cnrs.9268; [histoire-cnrs.revues.org] .
- Gillon P., Grosjean F., Ravenel L., Atlas du monde sportif. Business et spectacle : l’idéal sportif en jeu, Paris, Autrement, col. « Atlas/Monde », 2010, 80p.
Atlas national des fédérations sportives en France (2019)
[https:]]
Petit atlas du sport. Disponible sur le journal Zeit online (en allemand)
[https:]]
Articles connexesApproche multiscalaire des pratiques sportives. L'exemple des sports de « balle au pied »
Cartes et données sur le rugby en France et dans le monde
La cartographie des clubs de football à travers les réseaux sociaux
Football : cartographie de tous les pays affrontés par les Bleus dans leur histoire
La cartographie du Tour de France d'hier à aujourd'hui
Cartes des pistes cyclables en Europe et en France
Classer les villes cyclables en France et dans le monde. Quels sont les indicateurs utilisés ?
Cartographier les espaces du tourisme et des loisirs
-
18:14
Une histoire du conflit politique. Elections et inégalités sociales en France 1789-2022 (Julia Cagé, Thomas Piketty)
sur Cartographies numériquesLe nouveau livre de Julia Cagé et Thomas Piketty, « Une histoire du conflit politique », s'accompagne d'un site Internet très riche qui fournit les données des élections majeures en France depuis 1848, des tableaux de bord ainsi que des cartes permettant de conduire des comparaisons à l'échelle des communes.
Qui vote pour qui et pourquoi ? Comment la structure sociale des électorats des différents courants et mouvements politiques a-t-elle évolué en France de 1789 à 2022 ? En s’appuyant sur un travail inédit de numérisation des données électorales et socio-économiques couvrant plus de deux siècles, cet ouvrage propose une histoire des comportements électoraux et des inégalités socio-spatiales en France de 1789 à 2022. Pour la première fois, il devient possible de comparer la structure des électorats sur une longue période.
L'ensemble des données, graphiques et extraits du livre sont disponibles en ligne sur le site unehistoireduconflitpolitique.fr. Grâce à la numérisation des archives électorales au niveau des 36000 communes pour toutes les élections législatives et présidentielles de 1848 à 2022 et les principaux référendums de 1793 à 2005, il devient possible pour la première fois de comparer précisément qui vote pour qui.- Cartographie. Comment se répartissent les votes et les richesses dans l'hexagone depuis 1789 ?
Choisissez les élections (législatives, présidentielles, référendums) ou les caractéristiques socioéconomiques (revenu, capital immobilier, etc.) que vous souhaitez cartographier, puis zoomez sur le territoire de votre choix. - Conflit. Comment vote votre commune depuis deux siècles, et où se situe-t-elle dans la répartition des richesses ?
Visualiser la place de votre commune par rapport à la moyenne nationale et son évolution dans le temps, pour toutes les élections et les caractéristiques socioéconomiques. - Portrait. Qui a le vote le plus populaire et le plus bourgeois ?
Pour toutes les élections et les courants politiques, découvrez comment le score obtenu varie avec la richesse de la commune.
Le module cartographique permet de faire des comparaisons du vote par courants politiques et sur du temps long, ce qui est assez inédit.
On peut recroiser ces cartes avec les portraits par communes qui permettent d'étudier l'évolution politique sous forme de courbes cumulatives plus spécifiquement pour les communes que l'on souhaite.
Un générateur de graphiques permet de comparer différents candidats et courants politiques pour voir lesquels sont les plus "populaires" ou les plus "bourgeois". C'est très démonstratif pour mettre en évidence la sociologie du vote. En même temps, on peut discuter les termes "populaire" et "bourgeois" (il existe beaucoup de déciles intermédiaires) et questionner la significavité de la donnée qui est le revenu communal moyen.
Liens pour télécharger les ressources- Accès direct au module cartographique
- Page pour télécharger les données
- Cartes de l'ouvrage
- Cartes des annexes
- Graphiques du livre au format pdf
- Graphiques du livre au format xlxs
Commentaires dans les médias
« Julia Cagé et Thomas Piketty livrent une vision inédite de l’histoire politique française » (Le Monde).
« Les critiques ne manqueront pas face à l’ampleur et à l’ambition de l’ouvrage de Cagé et Piketty. Mais l'ouvrage des deux économistes se pose d’emblée comme une référence. Malgré des limites, son approche replace les inégalités sociales au cœur des études du vote » (Tribune de Vincent Tiberj, Le Monde).
« Julia Cagé et Thomas Piketty : le vote Macron est le plus bourgeois de l'Histoire ! » (interview des auteurs pour France Inter qui évoquent la notion de classes "géo-sociales").
« Les six enseignements à retenir du livre de Thomas Piketty et Julia Cagé, une nouvelle somme globalisante, un énorme pavé façon livre-enquête, deux siècles d’histoire électorale et une question simple : "Qui vote pour qui et pourquoi ?" » (Libération).
« Une histoire du conflit politique par Julia Cagé et Thomas Piketty, le livre qui relance la gauche » (L'Obs).
« Une histoire du conflit politique sans géographie » (Metropolitiques.eu). Julia Cagé et Thomas Piketty livrent une somme ambitieuse analysant les élections en France depuis la Révolution de 1789, qui accorde une place centrale à la notion de « classe géo-sociale ». Selon Frédéric Gilli, le livre comporte toutefois des limites méthodologiques importantes notamment dans l’usage des données géographiques.
« Une histoire du conflit politique sans géographie » (La Vie des idées). Pour Michel Offerlé, l'éco-histoire du conflit politique en France proposée par Julia Cagé et Thomas Piketty est une défense de la bipartition électorale : le clivage gauche-droite est le fondement de notre démocratie et il a permis le progrès social. Il faut donc travailler à le rétablir. Pour entrer dans le livre, il faut accepter cinq clés qui sont à la base de leur méthodologie et de leur démonstration et accepter la définition implicite du conflit qui est ici implicitement donnée.
« La thèse de Julia Cagé et Thomas Piketty est une fable historique », selon l’historien Nicolas Roussellier (L'Obs). Le spécialiste de l’histoire politique française regrette le « schématisme » du nouvel ouvrage des deux économistes. Selon lui, l’électorat de Macron n’est pas « le plus bourgeois de l’histoire ».
« Cagé et Piketty ne nous aveuglent-ils pas ? » (Alternatives économiques). Pour Christophe Ramaux, l’optimisme de la volonté de Julia Cagé et Thomas Piketty est louable. « Là où il y a une volonté, il y a un chemin » aurait dit Lénine. Encore faut-il avoir une bonne boussole… Car que les « faits sont têtus » !
Articles connexes
Dis-moi où tu vis, je te dirai ce que tu votes ? (Géographie à la carte, France Culture)
L'évolution du vote des Français sur la 1999-2022 sur le site du Politoscope
Bureaux de vote et adresses de leurs électeurs en France (Répertoire électoral unique - INSEE)
Analyser les cartes et les données des élections présidentielles d'avril 2022 en France
La carte de l'abstention aux élections régionales de juin 2021
Géopolitique de la twittosphère en période d'élections présidentielles
Les résultats des élections européennes du 26 mai 2019 en cartes et en graphiques
S'initier à la cartographie électorale à travers l'exemple des élections présidentielles de novembre 2020 aux Etats-Unis - Cartographie. Comment se répartissent les votes et les richesses dans l'hexagone depuis 1789 ?
.jpg)

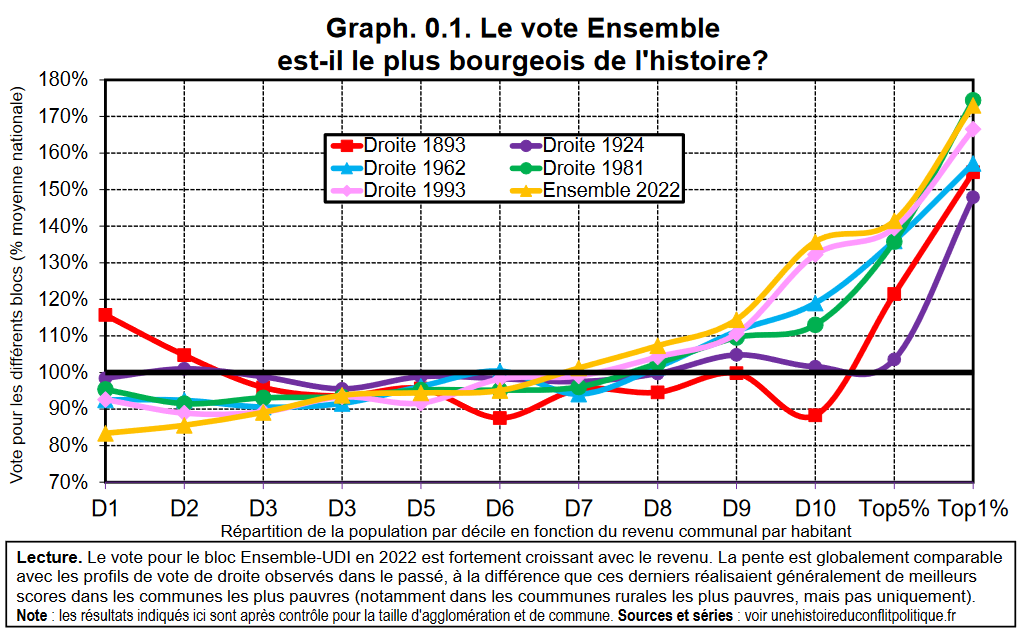
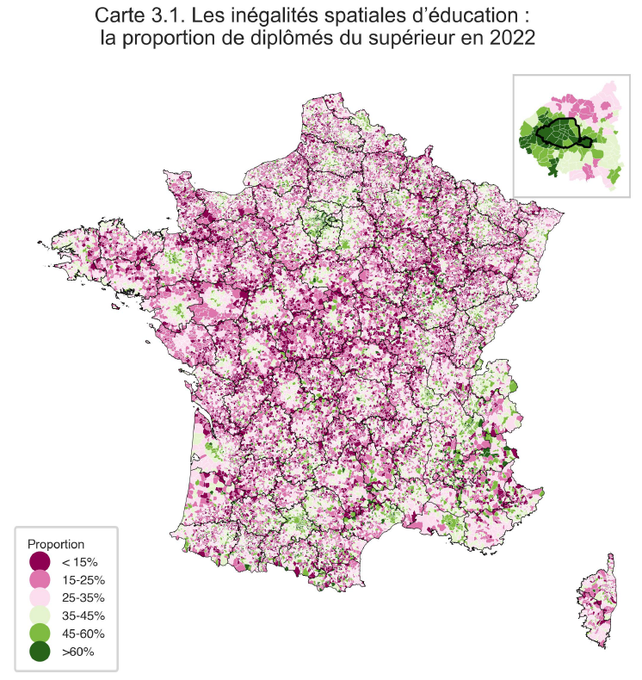
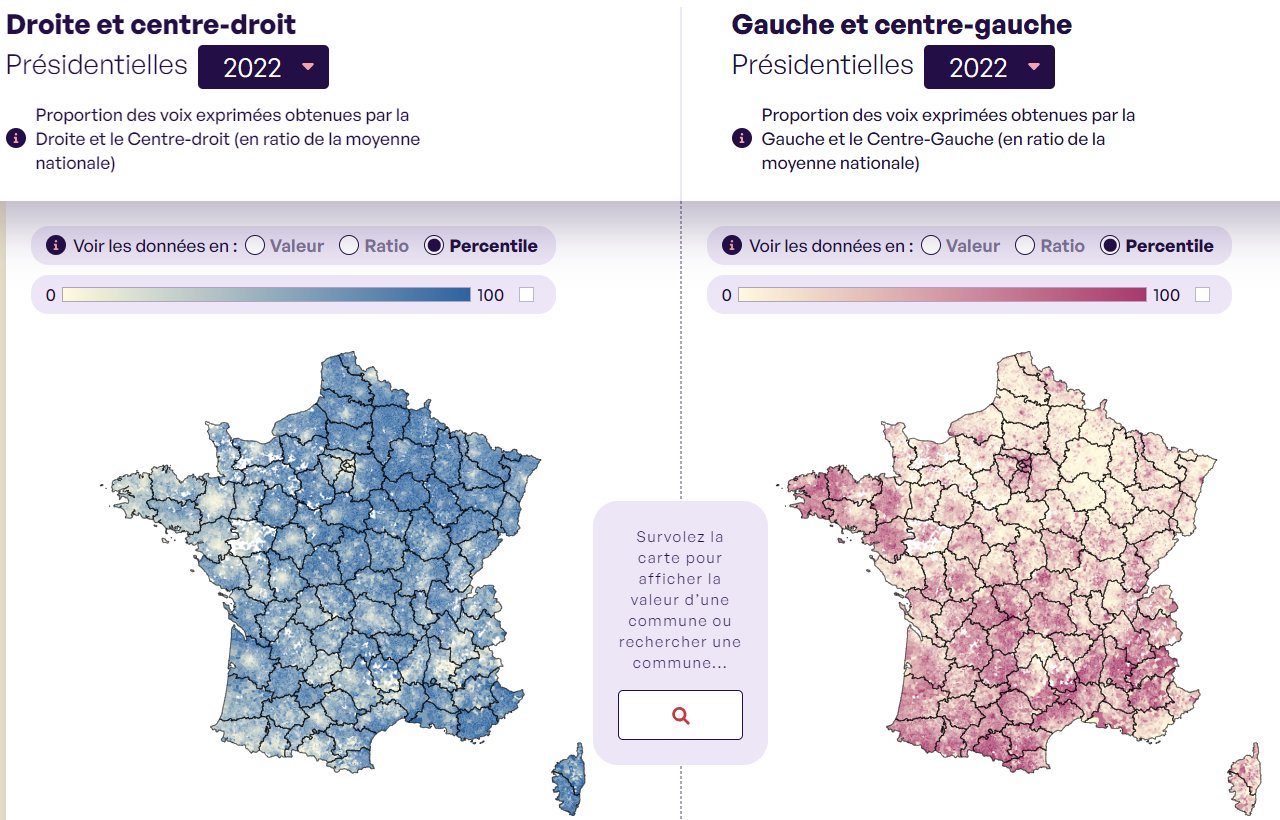
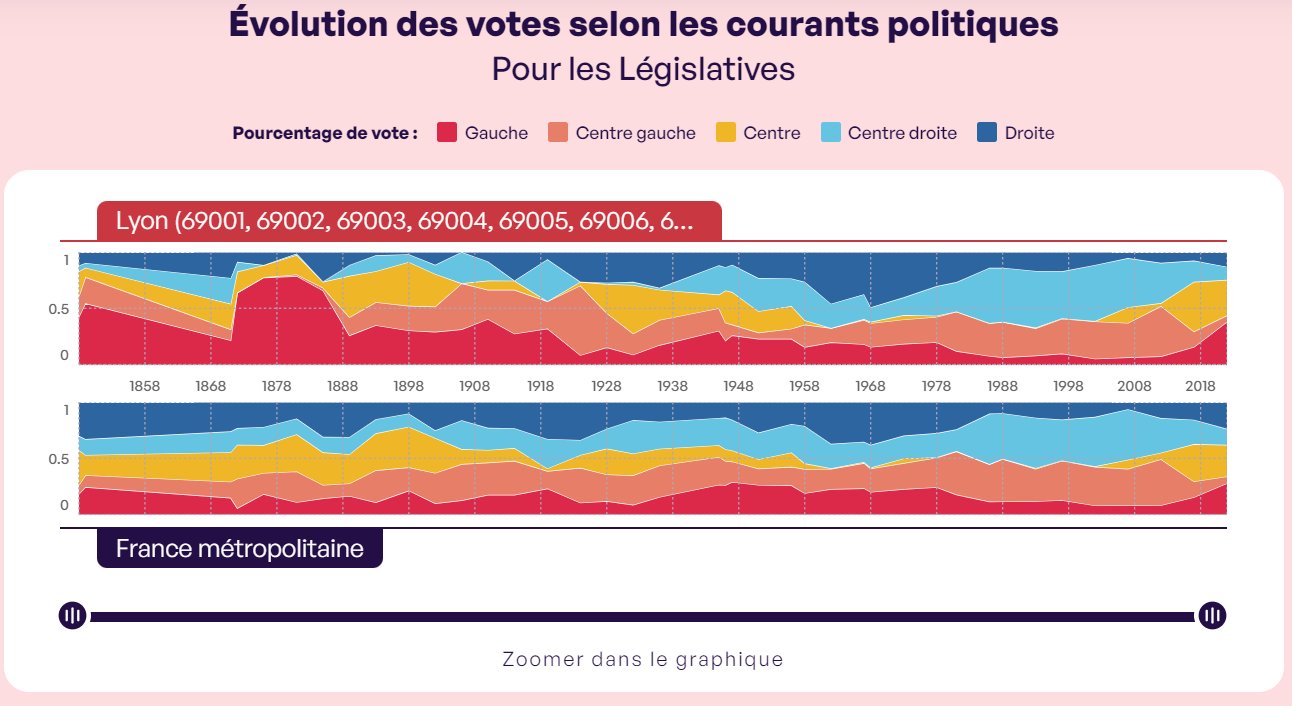
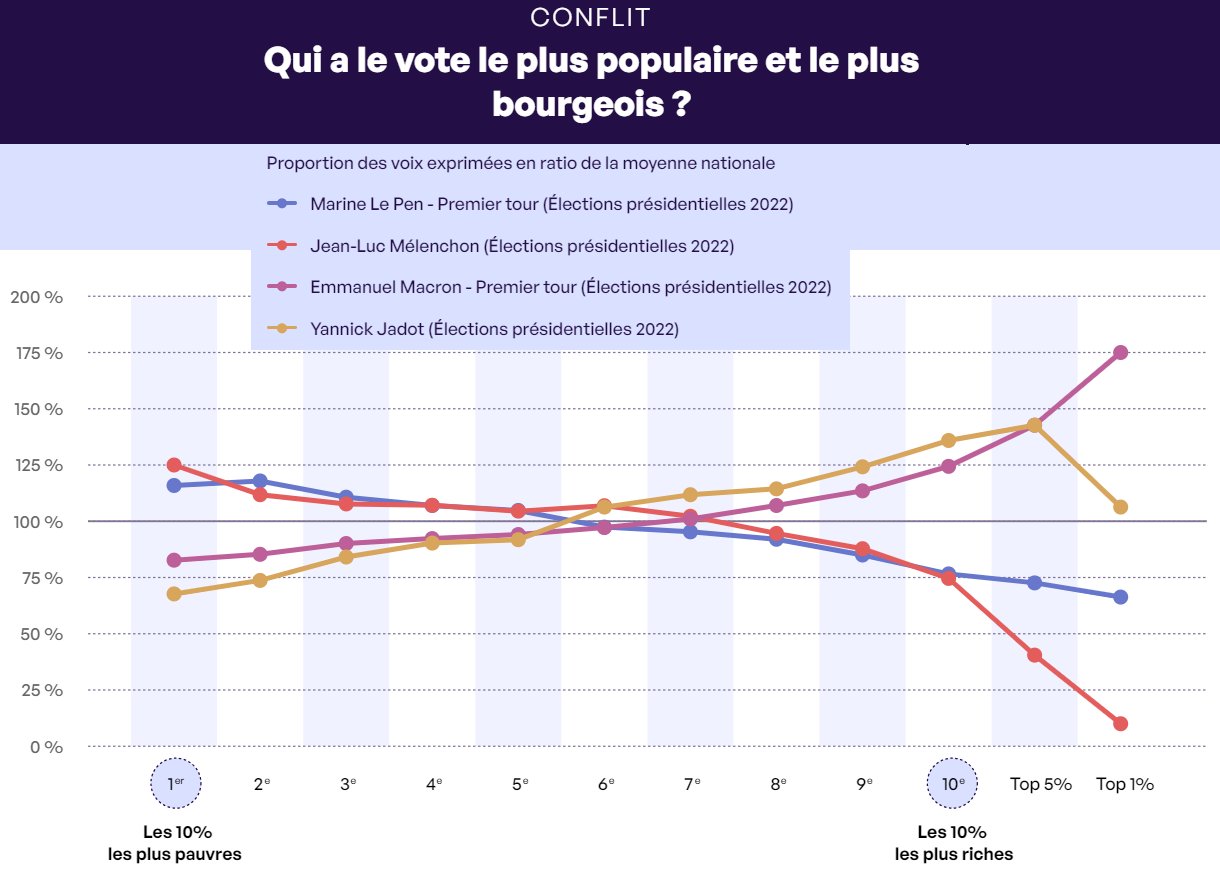
-
8:51
C’est la rentrée pour nos mapathons !
sur CartONG (actualités)Après une saison 2022-2023 qui a rassemblé plus de 700 participant·es et soutenu directement 5 organisations et 3 communautés OpenStreetMap, nous sommes de retour pour une nouvelle saison de mapathons !
-
20:30
30e Conférence Internationale sur l’Histoire de la Cartographie (ICHC) - Lyon 1er-5 juillet 2024
sur Cartographies numériques
La 30e Conférence Internationale sur l’Histoire de la Cartographie (ICHC) aura lieu à Lyon du 1er au 05 juillet 2024 sur le thème « Confluences - Interdisciplinarité et nouveaux défis dans l'histoire de la cartographie ». La conférence est ouverte à tous ceux qui travaillent sur l'histoire de la cartographie, indépendamment de la région géographique, de la langue, de la période ou du sujet. La conférence encourage la coopération et la collaboration libres et sans entraves entre les spécialistes de la cartographie de nombreuses disciplines universitaires, les conservateurs, les collectionneurs, les marchands et les institutions par le biais de conférences illustrées, de présentations, d'expositions et d'un programme social.L’appel à contributions est ouvert sur le site [https:]] du 1er septembre 2023 au 20 novembre 2023 pour des communications orales individuelles, des sessions thématiques (groupe de communications individuelles), des posters et des ateliers sur les possibilités d’intégrer une démonstration technique d’analyse associées à l’histoire de la cartographie. La langue officielle de la conférence sera l’anglais, et toutes les présentations devront être faites dans cette langue (il n’y aura pas de traduction simultanée). Toute présentation (communication orale, poster ou atelier) implique que la personne responsable vienne à Lyon pour la faire en présentiel.
La 30e édition de l'ICHC encourage particulièrement des présentations sur les thèmes suivants :
- Cartographie des déplacements, voyages et rencontres en cartographie.
Englobe la production de cartes pour aider les voyageurs et les touristes à atteindre leurs objectifs, à organiser l'hébergement et le transport, et la manière dont les territoires sont mis en valeur.
- Cartes et réseaux - Utilisation, échange et circulation des cartes
Explore les interrelations entre les producteurs de cartes, en tenant compte de la diffusion de nouveaux champs d'intérêt, de nouvelles utilisations, de l'introduction de nouvelles techniques et des réseaux de partage.
- Cartographie de la nature, des espaces sauvages et de l'agriculture
Vise une nouvelle compréhension de la manière dont les espaces naturels, sauvages et agricoles ont été traités, y compris la végétation, les montagnes, les étendues d'eau, les productions agricoles, les environs des villes et les risques naturels.
- Le développement de l'urbanisme et de la cartographie
La planification implique ou suppose une connaissance précise de la réalité topographique, ce qui a conduit à des améliorations de la cartographie, tant au niveau des techniques de mesure que de la conceptualisation, et récemment à l'introduction de la cartographie numérique.
- Nouvelles perspectives sur la transition numérique
Étudie la manière dont la dématérialisation introduit de nouvelles problématiques : décomposition en couches vectorielles à assembler et organiser pour de nouveaux usages, nouveaux rapports entre données et expression graphique, big data, conservation (ou mise au rebut) des données historiques/anciennes et des cartes numériques.
- Et tout autre aspect de l'histoire de la cartographie.
L’appel à communications propose 4 types d’interventions :
- Communication orale : présentation de 15 à 20 minutes sur une recherche en cours
- Posters : présentation dédiée à montrer une analyse de dispositifs visuels accompagnées de textes succincts
- Ateliers/Workshops : possibilités d’intégrer une démonstration technique des possibilités d’analyse associées à l’histoire de la cartographie
- Session thématique : proposition d’une séance de communications orales (les résumés des différentes interventions doivent être communiqués au comité scientifique)
Dates importantes : appel à communications/ateliers/posters - du 01/09/2023 au 20/11/2023
Réponse du comité scientifique : janvier 2024
- Exposition Représenter le lointain : une vision européenne (2 avril - 13 juillet 2024)
Exposition organisée à la Bibliothèque Municipale de Lyon, dans le cadre des "Conférences Internationales d'Histoire de la Cartographie" (ICHC) 2024.
- Exposition | Traces papier - Cartes et images de voyages en France et ailleurs, XVIIe-XXIe siècle (15 mai - 29 septembre)
Exposition organisée à la Bibliothèque Denis Diderot, dans le cadre des "Conférences Internationales d'Histoire de la Cartographie" (ICHC) 2024.
-
13:50
Contribution des pays du Bassin du Congo à la déforestation
sur Carnet (neo)cartographiqueA la suite du billet précédent sur les paysages forestiers intacts, on peut logiquement s’interroger sur la déforestation ces dernières années, sur la contribution des différents pays du Bassin du Congo.
Pour ce faire, j’ai mobilisé les données disponibles dans le dernier rapport sur l’État des forêts (EDF) publié par le Partenariat pour les forêts du Bassin du Congo (PFBC), pour “présenter les écosystèmes forestiers d’Afrique centrale et leur environnement de gestion”. Ce rapport fait notamment état de données qui fournissent des mesures sur la déforestation réalisées de 2009 à 2020.
M’étant fixée pour objectif de cartographie la répartition des pays du point de vue de la déforestation, j’ai réalisée une carte descriptive combinant le stock de surfaces déforestées (en hectares) et le taux illustrant la contribution en pourcentage de l’ensemble des pays concernés à la déforestation du Bassin du Congo, sur la période 2009-2020.
En examinant les premiers résultats cartographiques obtenus, j’ai finalement réalisé deux cartes prenant en compte ou non la contribution du Cameroun, pour lequel les données n’étaient disponibles, dans les sources que j’ai consultées, que jusqu’en 2018 (carte 1).
Carte 1. Profil des pays du Bassin du Congo en termes de déforestation de 2009 à 2018

Si l’on étend la période de représentation à 2020, en conservant le Cameroun, la configuration des pays change de de manière importante (Carte 2), puisque le Cameroun qui avait la contribution la plus importante jusqu’en 2018, à plus de 35% voit, cède sa place, par simple permutation, au Gabon.
Carte 1. Profil des pays du Bassin du Congo en termes de déforestation de 2009 à 2020

Au delà du changement de position du Cameroun et du Gabon, ces deux cartes permettent aussi de montrer comment la présence de données manquantes ou lacunaires peut conduire à travestir la réalité et, surtout, à empêcher la mesure de la déforestation à l’œuvre depuis 2009 dans les pays du Bassin du Congo. Du coup, on aimerait bien savoir pourquoi les données sont manquantes pour le Cameroun…
Billet lié :
– Que reste t-il de nos forêts ?Source :
Partenariat pour les forêts du Bassin du Congo (PFBC), 2021, État des forêts, RapportGéographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.
-
18:19
[MUSCATE & THEIA] Production of Sentinel-2 L2A is late
sur Séries temporelles (CESBIO)Update on 25 september 2023 : we have no backlog left in Europe, and the system is catching up on the other regions of the world
Update on 9 september 2023 : 25 days processed in a week over France ! We are catching up a bit
CNES has bought and built a new HPC cluster, named T-Rex, that will soon replace the former one, HAL. T-Rex will drastically improve our processing capacity ! T-Rex started its operations this summer, but the transition is complex, as T-Rex reuses the most powerful nodes of HAL, needs a synchronisation of all the data sets (the data volumes to copy are huge), and of course, has a different OS version and a new scheduler. We have anticipated the changes in our systems, using a simulated environment to test our softwares, but, you know, simulations are not the reality.
As a result, the production of MUSCATE (THEIA) is still running on HAL, but some of the best processors of HAL have been migrated to T-REX, reducing our production capacity. moreover, we have been asked to stop producing on week-ends, to allow a faster copy of the data from HAL to T-Rex.
As a result, yet, we have not been able to catch-up the production that we had halted for a few weeks when the new version of CAMS was put in production, and for some sites, for instance, in France, we are late by one month. Please be assured that the teams are doing their best to catch it up.
-
6:13
L'histoire par les cartes : une carte japonaise du XVIIe raconte le voyage d'Edo à Kyoto
sur Cartographies numériques
Source : The Scenic Route? The Library’s 117-foot Map from 17th-century Japan, 21 août 2023 (Library of Congress Blogs)Bien avant l'avènement de Google Earth et des livres de voyage, des cartes illustées servaient à guider les voyageurs sur leur route. La carte T?kaid? bunken ezu, peinte sur deux rouleaux, mesure plus de 3,6 mètres de long. La carte en rouleau illustré date de 1690. Elle est à découvrir sur le site de la Bibliothèque du Congrès.
Extrait de la carte "T?kaid? bunken ezu" à découvrir sur le site de la Bibliothèque du Congrès
Le cartographe Ochikochi Doin a étudié en 1651 la route de près de 500 km qui relie Edo (maintenant connue sous le nom de Tokyo) à Kyoto, et le célèbre artiste Hishikawa Moronobu a donné forme à ses découvertes en 1690 via cette carte illustrée à la plume et à l'encre. Une version non colorée est visible sur le site du British Museum. L'Université de Manchester en propose également une réimpression ultérieure.
La carte est un d?ch?zu (« carte routière ») imprimé sur bois. Elle reproduit les 486 kilomètres de ce parcours à une échelle de 1:12000. La carte représente cinq tronçons principaux de la route du Tokaido, fournissant un compte rendu détaillé des commodités, des points de repère et du terrain avec en fond des images de montagnes, de rivières et de mers. Elle montre les 53 stations ou villes postales, qui bordaient l'itinéraire pour fournir aux voyageurs hébergement et nourriture. Des monuments célèbres tels que le Mt Fuji et le Mt Oyama sont représentés sous plusieurs angles et à différentes stations.
Extraits du parchemin à découvrir sur le site de la Bibliothèque du Congrès
La carte emprunte au genre japonais de l’emaki (???, littéralement « rouleau peint »), noté souvent e-maki, un système de narration horizontale illustrée dont les origines remontent au VIIIe siècle au Japon.
La carte "T?kaid? bunken ezu", élaborée à la manière d'un guide quotidien comme pour un road trip, est aujourd'hui reconnue comme un grand artefact culturel : il est considéré comme un chef-d'œuvre de la cartographie japonaise.
Pour compléter
Les plus anciennes cartes itinéraires japonaises, ou Dochuzu, remontent au XVIIe siècle et suivent divers modèles durant la période d'Edo. Certaines adoptent une forme diagrammatique pour représenter les principaux axes de circulation terrestre de l'archipel, dont les célèbres Gokaid? conçues et développées au cours du shogunat Tokugawa. Longues de plusieurs centaines de kilomètres, ces cinq routes majeures, partant de la ville d'Edo sont jalonnées de stations (shukuba) comportant auberges, postes de contrôle et relais de chevaux. Achevé dès 1624, le T?kaid?, qui relie Edo à Ky?to, est la plus importante et la plus fréquentée d'entre elles : représentant une distance totale d'environ 500 km, longeant par endroits le littoral, la « route de la mer de l'Est », et ses cinquante-trois étapes, a inspiré de nombreux maîtres de l'estampe (Hokusai, Hiroshige). Source : Le Japon et la mer. Une cartographie asiatique (Paris Sorbonne)
Le médecin et naturaliste Philip Franz Siebold (1796-1866), qui a rassemblé une importante collection de cartes sur le Japon au XIXe, a produit une très belle carte de voyage « Mont Fuji et T?kaid? - Route de la mer orientale » (1840), d'après un livre de voyage japonais gravé sur bois en couleur du début du XVIIIe siècle. A découvrir sur le site de la collection David Rumsey.
Articles connexes
L'histoire par les cartes : la collection de cartes japonaises de la Manchester University Library
L'histoire par les cartes : une carte japonaise de l'Afrique du début de l'ère Meiji (1876)L'histoire par les cartes : l'Asie du Sud-Est à travers des cartes japonaises de la 2e Guerre mondiale
Signaler les enfants bruyants dans sa rue : Dorozoku, un site cartographique controversé au Japon
Cartes et données sur les tremblements de terre au Japon depuis 1923
Comprendre la mégapole japonaise en utilisant le site "To?kyo?, portraits et fictions"
Carte des road trips les plus épiques de la littérature américaine
-
16:29
Cartographie nationale des lieux d'inclusion numérique
sur Cartographies numériques
La Cartographie nationale des lieux d'inclusion numérique agrège une 30e de jeux de données et compte près de 18 000 structures. Elle permet d'identifier, localiser et mettre en avant les centres et les espaces qui proposent un accompagnement et des ressources pour aider les citoyens à développer leurs compétences numériques. Le travail est piloté par l’Agence nationale pour la cohésion des territoires (ANCT) et La MedNum avec l’appui de Datactivist.
Accès aux lieux d'inclusion numérique par région sur le portail cartographie.societenumerique.gouv.frLa large diffusion de la Cartographie permet de :
- contribuer à une meilleure orientation des bénéficiaires de services de médiation numérique ;
- promouvoir l'inclusion numérique, en mettant en avant les espaces d'inclusion numérique de notre territoire ;
- faciliter les partenariats locaux : la collaboration avec diverses organisations pour le déploiement de cet outil peut favoriser des partenariats solides et durables au sein de votre écosystème local.
Zoom sur un territoire permettant de repérer les lieux où l'on trouve un Conseiller numérique (en rouge)
Le schéma répond aux spécifications du schéma "Lieux de médiation numérique" élaboré collaborativement et disponible sur le site schema.data.gouv.fr. Il existe un réel besoin d’une vision nationale, complète et actualisée de l’offre de médiation numérique. Des acteurs de la médiation numérique, notamment les hubs, ont produit de nombreuses données de recensement des lieux et des offres de médiation mais souvent, ces productions ne respectent pas le même format, rendant alors impossible une vision formalisée, complète et partagée de l’offre nationale de médiation numérique. La standardisation permet de décrire l'offre de médiation numérique de manière harmonisée. Elle repose sur un travail de concertation dans lequel des utilisateurs représentatifs ont défini un schéma de données qui décrit le format des fichiers, les différents champs, les valeurs possibles.
Le jeu de données fourni par Data Inclusion est disponible au format json et csv sur Data.gouv.fr.
Une rapide représentation cartographique des données montre la forte inégalité dans la répartition des lieux d'inclusion numérique à l'échelle nationale (à recroiser avec la répartition de la population française). La base de données permet de mettre en évidence la diversité des lieux d'accueil (mairies, médiathèques, centres sociaux, maisons de quartier, missions locales, associations, fablabs...).rd-mediation-num/
La stratégie nationale pour un numérique inclusif, initiée en 2018, a permis l’émergence et le développement de nombreux dispositifs dédiés à l’accompagnement des 14 millions de Françaises et de Français en fragilité avec le numérique, sous l’impulsion de l’Agence nationale de la cohésion des territoires (ANCT). La création de La MedNum participait de cette stratégie, pour structurer l’offre de médiation numérique et participer à la consolidation économique comme à l’augmentation de la capacité d’action des acteurs et actrices de ce secteur. Les évolutions de ces dernières années semblent cependant participer à une reconfiguration de cet écosystème : crise sanitaire, généralisation de la dématérialisation, déploiement d'infrastructures numériques, recrutement massif de 4000 conseillers et conseillères numériques, mise en œuvre de solutions numériques pour les aidants et aidantes et installation sur les territoires de Hubs territoriaux pour un numérique inclusif. Afin d'accompagner ces évolations a été mis en place en 2022 un Observatoire de l'inclusion numérique qui est au coeur des missions de La MedNum.
Articles connexes
Infrastructures numériques : un accès encore inégal selon les pays
Cartographier les données des tests PISA : quelle lecture géographique des inégalités en matière d'éducation ?
Étudier les inégalités entre établissements scolaires à partir de l'Indice de position sociale (IPS)
Rapport sur les inégalités mondiales 2022 (World Inequality Lab)
Des inégalités dans l'équipement informatique des écoles primaires en France et outre-mer (rapport CNESCO, octobre 2020)
Un atlas des fractures scolaires par Patrice Caro et Rémi Rouault : comment lire et analyser les inégalités socio-spatiales en éducation ?
La cartographie des inégalités à travers l'Indice de privation multiple au Royaume-Uni (rapport 2019)
Géographies de l'exclusion numérique par Mark Graham et Martin Dittus
Monroe Work et la visualisation des inégalités scolaires dans l'entre-deux-guerres aux Etats-Unis


-
10:50
QGIS rencontre AWS S3
sur OslandiaDepuis QGIS 3.22 Bia?owie?a, il est possible de lier des documents externes (documents stockés sur des plateformes utilisant le protocole WebDAV, telles que Nextcloud, Pydio, etc.) à des données géographiques. Cette fonctionnalité permet d’introduire une composante de Gestion Électronique de Documents (GED) dans les SIG.
La livraison de cette fonctionnalité auprès de la communauté QGIS s’est faite grâce au financement de la Métropole de Lille, et elle se voit aujourd’hui enrichie grâce à l’implication et au financement de la Métropole de Lyon qui utilise une infrastructure de GED basée sur le stockage d’objets dans le cloud, qu’elle souhaite pouvoir exploiter à travers son SIG.
C’est un bel exemple de cercle vertueux où des utilisateurs mutualisent des financements afin d’enrichir les fonctionnalités de QGIS au bénéfice du plus grand nombre : les contributions se sont enchainées pour améliorer les jalons posés par d’autres utilisateurs.
Amazon Simple Storage Service (AWS S3)Depuis QGIS 3.30 ‘s-Hertogenbosch, il est donc possible d’utiliser le type de stockage AWS S3 lors de la configuration du widget Pièce jointe, ainsi que le nouveau type d’authentification dédié :
 Nouveau type d’authentification AWS S3
Nouveau type d’authentification AWS S3Notre article précédent présente un guide sur la configuration du formulaire de la couche géographique, afin de disposer d’une interface ergonomique permettant de visualiser les documents, et les envoyer sur le système de stockage directement via le formulaire de l’entité géographique.
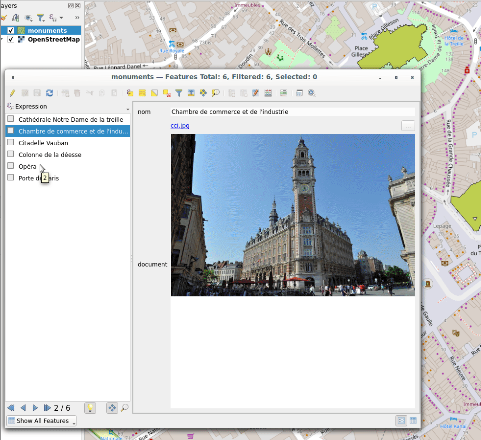
Aperçu d’un fichier joint
Il suffit à présent de sélectionner AWS S3 comme type de stockage et d’authentification :
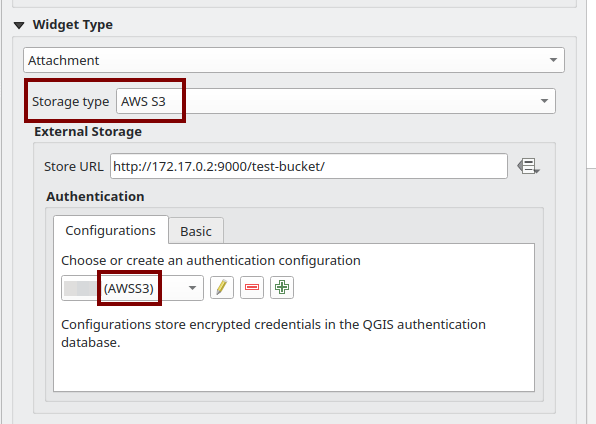
Nouveau type de stockage AWS S3
Stockage d’objet cloud compatibleMinIO est un système de stockage d’objet cloud compatible AWS S3, opensource, et facilement mis en place via Docker par exemple, pour stocker des documents et y accéder via QGIS.
A venirNous cherchons à améliorer cette fonctionnalité pour les prochaines version de QGIS : nous aimerions par exemple :
- ajouter de nouveaux types de stockage,
- améliorer le rendu des photos dans les fonds de carte,
- charger un projet directement à partir d’un stockage externe,
- etc ! on peut imaginer de nombreux usages complémentaires. N’hésitez pas à nous faire part de vos besoins
Si vous souhaitez contribuer ou simplement en savoir plus sur QGIS, n’hésitez pas à nous contacter à infos@oslandia.com et consulter notre proposition de support à QGIS.
-
7:45
Que reste t’il de nos forêts ?
sur Carnet (neo)cartographiqueLe changement climatique, la chaleur suffocante et maintenant, la soudaine tombée du froid. Est-ce que cela pourrait être dû à la baisse du couvert végétal ? Je demande…
A la faveur d’une collaboration en cours avec la FPAE, je suis sortie de ma zone de confort cet été pour essayer de prendre l’air, en m’intéressant aux forêts du Bassin du Congo ; le lien entre les très fortes températures et les épisodes de sécheresse que nous connaissons en Europe de l’ouest, le changement climatique et le lien avec le couvert végétal m’intéressant a priori.
N’étant pas familière avec ces sujets liés aux paysages végétaux, je suis entrée dans le sujet en commençant par me promener au cœur de bases de données librement accessibles en ligne – des bases de données que j’ai d’abord dû identifier. Je ne vais pas entrer dans trop de détail sur les données et les traitements réalisés, juste présenter quelques résultats cartographiques ci-après et probablement dans de prochains billets.Alors, pour commencer sur ce sujet des forêts, intéressons-nous aux forêts « encore intactes ». Cela tombe bien, un groupe de chercheurs à publié différents articles sur le sujet (voir notamment Potapov et al. 2017) qu’ils partagent sur www.intactforests.org, permettant alors de les caractériser et de les cartographier.
Un « paysage forestiers intact (PFI) est une étendue ininterrompue d’écosystèmes naturels à l’intérieur de la forêt actuelle, sans aucun signe d’activité humaine détectée à distance et suffisamment vaste pour que toute la biodiversité autochtone, y compris les populations viables d’espèces à large répétition, puisse être maintenue.
Pour les besoins d’évaluation globale, un PFI est défini [harmonisé au niveau mondial] comme un territoire formé d’écosystèmes forestiers et non forestiers très peu influencés par l’action anthropique, avec (i) une superficie d’au moins 500 km² (50 000 ha), (ii) une largeur minimale de 10 km (mesurée comme le diamètre d’un cercle englobant minimum le territoire concerné), et (iii) une largeur minimale de corridor/appendice de 2 km.
Les zones présentant des traces de certains types d’influence humaine sont considérées comme perturbées ou fragmentées et ne peuvent donc être incluses dans le PIF ».
Greenpeace, 2023 (trad. F. Bahoken),Une base de données disponible à plusieurs dates a également été construite sur ces PFI par un collectif de cartographes : l‘Impact Forest Landscape mapping team appartenant à Greenpeace, WRI, WCS, Département de Géographie de l’Univ. du Maryland, Transparent World et WWF (Russie),
J’ai été très très surprise de voir l’état de l’extension forestière en 2020 (dernière date disponible), particulièrement en Afrique et dans le bassin du Congo. La carte réalisée est littéralement dramatique. Jugez-en par vous mêmes.
Paysages forestiers « encore intacts » en 2020 dans le bassin du Congo
 La forêt a t-elle été réduite rapidement ? Quelle était son emprise en 2000, par exemple ?
La forêt a t-elle été réduite rapidement ? Quelle était son emprise en 2000, par exemple ?Paysages forestiers intacts en 2000 dans le bassin du Congo
 Ce n’est pas vraiment mieux qu’en 2000 et c’est le moins que l’on puisse dire. Pour mieux se rendre compte de l’étendue du désastre, j’ai superposé les deux cartes précédentes sur l’extension historique du couvert forestier
Ce n’est pas vraiment mieux qu’en 2000 et c’est le moins que l’on puisse dire. Pour mieux se rendre compte de l’étendue du désastre, j’ai superposé les deux cartes précédentes sur l’extension historique du couvert forestierÉvolution du couvert forestier dans le bassin du Congo entre 2011 et 2020


Références :
– Potapov, P., Hansen, M. C., Laestadius L., Turubanova S., Yaroshenko A., Thies C., Smith W., Zhuravleva I., Komarova A., Minnemeyer S., Esipova E. “The last frontiers of wilderness: Tracking loss of intact forest landscapes from 2000 to 2013” Science Advances, 2017; 3:e1600821
– Bases de données IFL mapping team Intact Forest Landscapes 2000/2013/2016/2020.
Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.

-
22:41
Les stations de ski fantômes : mythes et réalité d’un angle mort de la géographie du tourisme
sur Les cafés géographiquesPar Pierre-Alexandre Metral
Doctorant en géographe – Université Grenoble AlpesPierre-Alexandre Metral qui réalise actuellement une thèse à l’UGA dans le cadre du Labex Innovations et Transitions Territoriales en Montagne (ITTEM) intitulée « La montagne désarmée, une analyse des trajectoires territoriales des stations de ski abandonnées » est intervenu le 18 avril 2023 à Chambéry dans le cadre d’un Café Géographie.
En guise de préambule, l’intervenant est revenu sur ce « phénomène des stations de ski fermées qui revient de plus en plus fréquemment dans les médias à travers le mythe de la station de ski fantôme ». Selon lui, le terme de « station de ski fantôme » est une dénomination bien particulière qui fait éminemment référence à une activité ancienne qui viendrait marquer l’histoire d’un territoire vécu et qui s’ancrerait comme un traumatisme qui ne passe pas.
Pour ce dernier, la station de ski fantôme renvoie à l’omniprésence des friches constituées d’un certain nombre de bâtiments et d’infrastructures délaissés, qui s’établissent comme des marqueurs de déprises sur les territoires, symbolisés par la rouille de ces installations. Des friches qu’il caractérise comme des espaces en « accès libre pour des pratiques contre culturelles ».
A partir de ce cadrage, Pierre-Alexandre Metral propose la problématique suivante pour ce Café géo : Est-ce que le mythe de la station de ski fantôme est représentatif de la mise à l’arrêt des domaines skiables français ?
1/ La « fin touristique » : normalité ou anomalie ?
Pour l’intervenant, la vie de tout produit économique est marquée par l’idée de cycle de vie allant d’une introduction sur un marché jusqu’à son retrait. Pour transposer ce cycle de vie au cadre du tourisme, il évoque les travaux de Michel Chadefaud pour qui « le tourisme est un bien non durable […] marqué par une activation et une désactivation ». Pour illustrer ses propos, Pierre-Alexandre Metral projette la figure du cycle de vie d’un bien touristique.
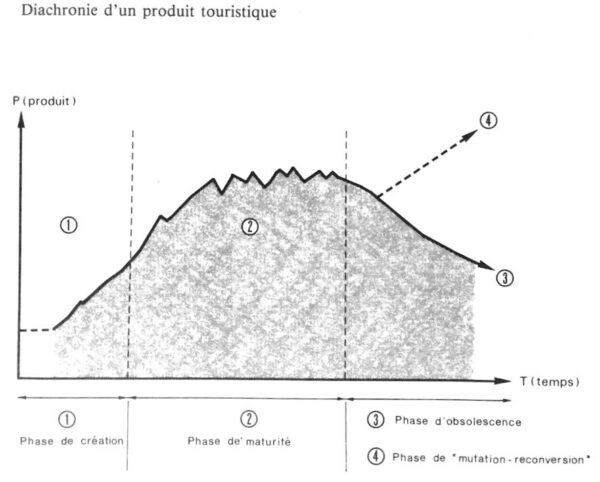
Fig 1 : cycle de vie des produits touristiques – Michel Chadefaud 1988
A l’issue de la présentation de cette figure, le doctorant a proposé une série d’illustrations de proximité au public en présentant diverses « fins touristiques » du bassin chambérien. Il a notamment évoqué le cas de l’abandon du téléphérique du Mont Revard qui a fonctionné jusqu’à la fin de la décennie 1960 en lien avec l’activité thermale de la ville d’Aix-les-Bains.

Fig 2 : La gare de départ en 2022 – P-A Metral
2/ Pourquoi un domaine skiable ferme-t-il ?
En réponse à cette interrogation, Pierre-Alexandre Metral évoque des conditions d’exploitation de plus en plus vulnérables :
– Obsolescence des conditions d’exploitation liée au manque de neige
– Obsolescence face à la concurrence entre petits et grands domaines skiables
– Obsolescence du site d’implantation en raison d’accès routiers complexes
– Obsolescence de l’équipement avec des coûts d’exploitation et de maintenance de plus en plus onéreux corrélé au vieillissement des installations
– Obsolescence de certains modèles de développement en lien avec la disparition des classes de neige par exempleConcrètement, il lui est possible d’identifier 3 causes majeures de fermeture. En premier lieu et principalement, le motif économique avec des domaines skiables non rentables (ex : Pugmal dans les Pyrénées et ses 9,2 millions d’euros d’endettement). Vient ensuite l’épuisement des ressources humaines avec le départ en retraite d’exploitants privés sans transmission du capital touristique. Ce fut par exemple le cas dans le Jura où le petit téléski des Clochettes cessera son exploitation à la suite au décès de son fondateur et exploitant. Enfin, le cas des fermetures stratégiques liées à la mauvaise qualité des sites d’implantation et au redéploiement des activités sur de meilleures pentes. Pierre-Alexandre Metral évoque pour cela l’éphémère domaine de Supervallée à la Bresse (5 années d’exploitation), implanté sur un secteur pluvieux, qui deviendra suite à son déplacement en altitude la station de La Bresse, plus grand domaine skiable du massif vosgien.

Fig 3 : stade de neige du Puigmal en 2020, P-A Metral
3/ Quelle est la géo-histoire du phénomène de fermeture ?
Cette troisième partie est l’occasion pour l’intervenant de mettre en avant l’absence d’inventaire des domaines fermés. Pour remédier à cet écueil, il s’est attaché dans le cadre de sa thèse à réaliser un inventaire exhaustif à partir de différentes sources qu’il présente au public : ouvrages et articles scientifiques anciens sur le ski, articles de presses locales, cartes topographiques, cartes postales et vues aériennes anciennes … Tout cela lui permettant « d’établir une base de données spatialisée des sites fermés en France. S’ensuit la présentation d’une animation cartographique qui présente les ouvertures et les fermetures de stations sur l’hexagone entre 1920 et 2022.
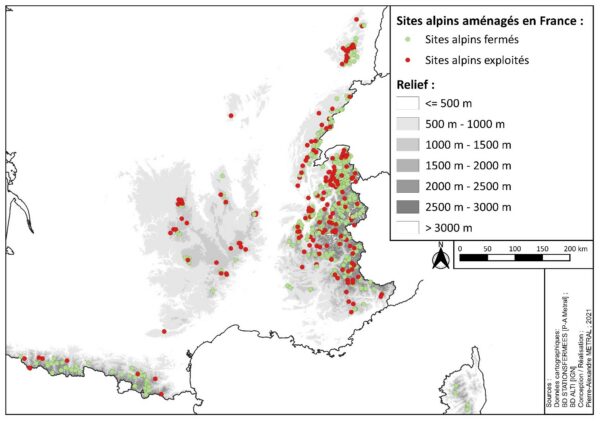
Fig 4 : Carte de localisation des sites français fermés et actuellement actifs en 2022 – BD STATIONSFERMEES, P-A Metral, 2022
A l’issue de cette animation Pierre-Alexandre Metral indique que ce phénomène de fermeture de stations touche tous les massifs montagneux en France (sauf la Corse) avec un épicentre dans les Alpes compte tenu de l’ampleur de ce dernier. Il présente également un taux de fermeture (rapport entre le nombre de sites fermés et actifs) tiré de ces travaux de thèse à hauteur de 31 %. Un taux apparaissant inégal en fonction des massifs de montagne : la moyenne montagne apparaissant en moyenne bien plus marquée par le phénomène de fermeture. Il termine son analyse statistique en cherchant à recontextualiser l’ampleur des fermetures en France : « les petits domaines skiables de basse ou moyenne montagne apparaissent donc les plus fragiles. Ils représentent au total 350 kilomètres de pistes en cumulé, soit une perte sèche de 3,34 % du domaine skiable français actuel ».
4/ Les stations fantômes sont-elles réellement des stations ?
Cette nouvelle interrogation proposée par Pierre-Alexandre Metral, lui permet de faire remarquer qu’un grand nombre de « stations fantômes » sont en réalité : des centres de ski (135/186) , soit des sites mono-spécialisés dans la pratique du ski, parfois rudimentaires, ne comptant uniquement les équipements essentiels à la pratique (parking + remontée mécanique) des stades de neige (43/186) auquel il faut ajouter la fonction de services touristiques in situ (location de ski, petite restauration…) et enfin de toutes petites stations touristiques (8/186) qui comptaient quelques lits marchands pour une offre de séjours. Il conclut ce quatrième temps en indiquant qu’en réalité les sites apparentés à de « petites stations touristiques » sont encore peu concernés par les mises à l’arrêt de leurs domaines skiables. Pour autant, la dynamique de ces 20 dernières années expose que ces sites tendent de plus en plus à être touchés par l’arrêt de l’offre de ski.
5/ Une incarnation de la station fantôme : la friche touristique
Ce cinquième temps proposé par le doctorant lui permet d’évoquer les pistes possibles de reconversion des appareils de remontées mécaniques définitivement mis à l’arrêt. Néanmoins, il avertit d’emblée le public que ces reconversions sont pour beaucoup illusoires : les réactivations des domaines skiables sont risquées, la mono-spécialisation des équipements fait que le réemploi du matériel pour des loisirs d’été est extrêmement rare, que le marché de l’occasion est devenu une niche impénétrable faute à un matériel vieillissant et totalement obsolète.
Toujours en lien avec cette question de la friche touristique, l’intervenant aborde la question du démontage des appareils dont le coût est très élevé (entre 5000 et 20 000 € pour un téléski), avec bien souvent à la sortie des installations laissées en place et qui se détériorent faute de financements et parfois même à l’oubli des appareils le temps passant. Le « bilan comptable » du délaissement des appareils des sites fermés français est ainsi présenté : 92 appareils en friche en France en 2023 répartis en 3 catégories : 87 téléskis, 3 télésièges, 2 téléphériques. Si la majeure partie des appareils délaissés sont issus de fermetures récentes et qu’ils pourront éventuellement être réactivés, 30 appareils ont tout de même été abandonnés il y a plus de 20 ans ; les plus anciens depuis 1951.
6/ Vers la fin des friches touristiques ?
Cet avant-dernier point permet à Pierre-Alexandre Metral de revenir sur les initiatives nouvelles visant à accompagner le démontage et contenir le phénomène de délaissement. Au premier chef, les dispositions de la Loi Montagne II (2016) fixant notamment un échéancier dans le temps pour aboutir à un démontage. Le doctorant dans une posture plus critique pointe cependant ses limites, notamment la non-rétroactivité de ces dispositions faisant que les appareils d’ores et déjà délaissés ne sont pas concernés.
Par la suite, les corps intermédiaires engagés dans le démantèlement sont présentés. D’une part, Mountain Wilderness, l’acteur historique du démontage des installations obsolètes qui depuis 2001) a opéré par la voie bénévole au retrait d’une vingtaine d’appareils. D’autre part, la chambre professionnelle des exploitants de domaines skiables (Domaines Skiables de France) est engagée à l’organisation du démontage de 3 appareils délaissés par ans avec le concours d’opérateurs régionaux encore actifs qui vont réaliser les travaux dans une logique de solidarité.

Fig 5a et 5b : Le démantèlement des téléskis de Sainte-Eulalie (07) – P-A Metral, 2020
7/ La reconversion des anciennes stations de ski
Ce dernier temps proposé par l’intervenant est l’occasion de dresser des perspectives en matière de revivification des sites après la fermeture des domaines alpins. Il identifie ainsi un ensemble de trajectoires : le retour à l’état pré-touristique (alpages, forêt) et des activités agro-sylvo-pastorales. La reconversion des sites en bases de loisirs de montagne avec le développement d’activités organisées sur la saison d’été. Le réinvestissement des logements touristiques pour de l’habitat permanent, transformant ainsi les anciennes stations en hameaux de montagne. Enfin, Pierre-Alexandre Metral ne minore pas les pratiques récréatives réalisées en autonomie (ski de randonnée, vtt…), parfois aussi furtives, dissidentes et contre-culturelles (free party, street ski, street art…) qui dans une logique de réappropriation, redonnent de la vie et du sens aux anciens sites abandonnés.
Conclusion :
Pour Pierre-Alexandre Metral « le phénomène de fermeture est important en effectif avec 186 sites concernés », néanmoins la plupart sont de tailles insignifiantes, bien loin de l’image de la station fantôme évoquée en introduction. Ce mythe s’ancre en réalité sur « des cas sensationnels, très visuels et au final peu représentatifs du paysage réel des fermetures françaises ». Ces mises à l’arrêt illustrent, « plus que la fin du ski », la disparition d’un modèle de développement spécifique aujourd’hui presque disparu : les centres de ski. La carte du ski français se voit progressivement amputée des sites « de proximité », dédiés à l’apprentissage ; un ski de village, résolument social, où les tarifs pratiqués étaient aux antipodes des grands domaines alpins qui font la renommée du ski français.
Il termine ce café géo par ces mots « la station fantôme c’est le temps de l’incertitude, l’enjeu demain c’est de pouvoir anticiper en amont des fermetures la question de la remise en état des sites et leurs éventuelles reconversions ».
Par Yannis NACEF
Professeur agrégé de Géographie
Doctorant en Géographie – UMR 5204 EDYTEM – Université Savoie Mont Blanc – CNRS -
19:30
L’épicerie du monde. La mondialisation par les produits alimentaires du XVIIIe siècle à nos jours
sur Les cafés géographiques
Pierre Singaravélou et Sylvain Venayre ont convié à l’écriture « d’une histoire du monde par les produits alimentaires » de très nombreux auteurs. Pas moins de 400 pages qui se dévorent à pleines dents. Vous ne serez pas surpris que le chapitre sur le vin soit confié à Jean-Robert Pitte et que Christian Grataloup vous invite à la consommation du thé et à la dégustation de la baguette de pain tandis que Philippe Pelletier vous propose sushi et saké. Emmanuelle Perez Tisserant offre le chili con carne et le guacamole. Sylvain Venayre nous sert des charcuteries et du ketchup, Pierre Singaravélou opte pour le whisky et le rhum. Une centaine de produits sont proposés, dans un inventaire à la Prévert, où chacun pourra tout à la fois s’instruire gaiement et se mettre l’eau à la bouche. A vous tous, gourmands ou gourmets, ils offrent un savoureux voyage dans la grande « épicerie du monde ». Vous terminerez avec une coupe de champagne proposée par Stéphane Le Bras.
L’épicerie, magasin consacré aux produits alimentaires, se généralise au milieu du XVIIIe siècle. Mais le commerce des épices est bien plus ancien. En Angleterre la guilde des poivriers date de 1180 et l’épicerie est « magasin d’épices » avant de devenir boutique de produits alimentaires. La Révolution industrielle et la révolution des transports vont mondialiser les désirs identitaires, dont ceux liés à la gastronomie. Les expositions universelles apporteront à leur tour une mondialisation des offres. La baguette française, le roquefort et bien sûr les vins français doivent paraître sur les grandes tables, au XXe siècle.
Qui ne connaît à présent le Christmas pudding, emblème de l’empire britannique, la pizza italienne, le saké japonais, la féta grecque ou le ceviche péruvien ! Mais êtes-vous sûrs de connaître la patrie du couscous, du houmous, de la vodka ?L‘accès aux produits alimentaires est vital pour les populations. Des guerres peuvent éclater ici ou là. Les historiens ont noté la destruction du thé britannique par les colons de Boston en 1773. Dans un contexte différent, la guerre entre l’Ukraine et la Russie (ou plus exactement l’invasion de l’Ukraine), enclenchée en février 2022, comporte un volet alimentaire : celui des céréales exportées par l’Ukraine mais à présent retenues par les navires russes. Cela va provoquer des crises alimentaires graves, deux milliards de personnes restant frappés de malnutrition.
Les pratiques sociétales évoluent. Il n’y a pas si longtemps on pouvait rester plusieurs heures à table lors des repas dominicaux ; il y avait l’heure du thé en Angleterre, l’heure du raki en Turquie. Les femmes au foyer préparaient « avec amour » des plats appétissants. Mais la généralisation du travail féminin a conduit à la consommation de boîtes de conserves puis de plats surgelés. La publicité s’est chargée de vous faire acheter du Coca Cola dès 1916 !
Au début du XXIe siècle, la restauration doit être rapide, autour d’une baraque à frites ou à hot-dogs, ou à hamburgers. Le fish and chips eut son heure de gloire, mais s’affirmer végétarien ou vegan, c’est « être tendance » dans les années 2020.Consommer tel ou tel produit pouvait être recommandé par le corps médical. Ainsi le whisky et le vin de Porto facilitaient la digestion ou bien soignaient la goutte. Mais aujourd’hui l’OMS nous met en garde en listant des produits cancérigènes ou favorisant l’obésité… On ne sait plus à quel saint se vouer… Rassurez-vous, les Appellations d’Origine Contrôlée (AOC) vont nous permettre non seulement de choisir les meilleurs produits mais aussi ceux qui bénéficient d’un contrôle sanitaire.
Dans l’introduction de l’ouvrage, on peut lire une citation de Roland Barthes qui déclarait que la nourriture suscitait trois sortes de plaisir : celui de la convivialité, par le fait de partager le même plat ; celui de la réminiscence, qui nous fait retrouver les goûts de notre enfance ; et celui du nouveau, de l’insolite qui nous attire vers celles et ceux que nous ne connaissons pas encore.
Un savoureux voyage à ne rater sous aucun prétexte.Maryse Verfaillie, août 2023
-
16:50
Cartes et données sur les tremblements de terre au Japon depuis 1923
sur Cartographies numériquesA l'occasion du 100e anniversaire du grand tremblement de terre du Kant?, le quotidien japonais Nikkei propose une reconstitution cartographique de la façon dont près de la moitié de la ville de Tokyo a été détruite le 1er septembre 1923. Le séisme qui a touché le centre de la capitale avait une magnitude de 7,9. Frappant vers midi alors que les familles préparaient leurs repas, il a provoqué de nombreux incendies hatisés par des vents violents, particulièrement destructeurs du fait de constructions majoritairement en bois.
« Comment les incendies ont ravagé Tokyo pendant 46 heures » (une storymap proposée par Nikkei)
Tokyo a brûlé pendant 46 heures après le tremblement de terre. À l’époque, la superficie de la ville s’élevait à 79,4 kilomètres carrés. Sur ce total, les incendies ont brûlé 34,7 km², soit plus de 40 % du territoire urbain. À la suite du séisme massif de 2011 dans l'est du Japon, le gouvernement métropolitain de Tokyo a établi un « système de zones spéciales ignifuges » et a encouragé la démolition ou la reconstruction en dur de structures en bois vieillissantes.
Comparaison de trois séismes majeurs au Japon (supérieurs à une magnitude de 7)
Si on compare sur un siècle trois séismes supérieurs à une magnitude de 7, les dégâts humains et matériels ont globalement diminué au Japon. Mais les coûts financiers ont explosé du fait de l'essor urbain et de l'augmentation du nombre et de la valeur des biens. Le gouvernement japonais estime à environ 70 % les chances qu'un séisme de magnitude 7 se produise à nouveau d'ici 30 ans.
Le journal économique Nikkei a également commémoré le 100ème anniversaire du grand tremblement de terre de Kant? en créant une carte interactive qui montre l'épicentre et l'intensité des 13 680 tremblements de terre (supérieurs à une magnitude 5) qui ont frappé le Japon depuis 1923.
Tremblements de terre ayant eu lieu dans l'archipel japonais depuis 1923 (source : Nikkei)
L'épicentre de chaque séisme est représenté par une cercle proportionnel sur la carte. Plus le tremblement de terre est important, plus le cercle est gros. La couleur est modifiée en fonction de la magnitude (couleurs chaudes) et de la profondeur de l'épicentre (couleurs froides) : plus chacune devient grande (plus profonde), plus la couleur devient sombre.Les données utilisées pour réaliser cette carte sont issues du rapport mensuel sur les tremblements de terre (1er septembre 1923 - mars 2022) et la liste des lieux sismiques (avril 2022 - 31 juillet 2023) de l'Agence météorologique du Japon. Les données d'intensité sismique proviennent du rapport mensuel des tremblements de terre et de la base de données sur l’intensité sismique. Les valeurs de la liste des épicentres du séisme et de la base de données d'intensité sismique sont des valeurs provisoires. L'emplacement des limites de plaques tectoniques est basé sur les données publiées par l'Institut de recherche sur les tremblements de terre de l'Université de Tokyo. Les cartes estimant la probabilité de nouvaux tremblements de terre sont accessibles sur le site du Centre de promotion de la recherche sur les tremeblements de terre.
Articles connexes
Cartes-posters sur les tsunamis, tremblements de terre et éruptions volcaniques dans le monde (NOOA, 2022)
Un nouveau modèle de plaques tectoniques pour actualiser notre compréhension de l'architecture de la Terre
Carte-poster des tremblements de terre dans le monde de 1900 à 2018 (USGS)
Cartes et données sur les séismes en Turquie et en Syrie (février 2023)
Cartes et données sur le séisme au Maroc (septembre 2023)
Analyser et discuter les cartes de risques : exemple à partir de l'Indice mondial des risques climatiques
Une anamorphose originale montrant l'exposition accrue des populations au risque volcanique
Les éruptions volcaniques et les tremblements de terre dans le monde depuis 1960
L'incendie de l'usine Lubrizol de Rouen et la cartographie des sites Seveso en France
Comprendre la mégapole japonaise en utilisant le site "To?kyo?, portraits et fictions"

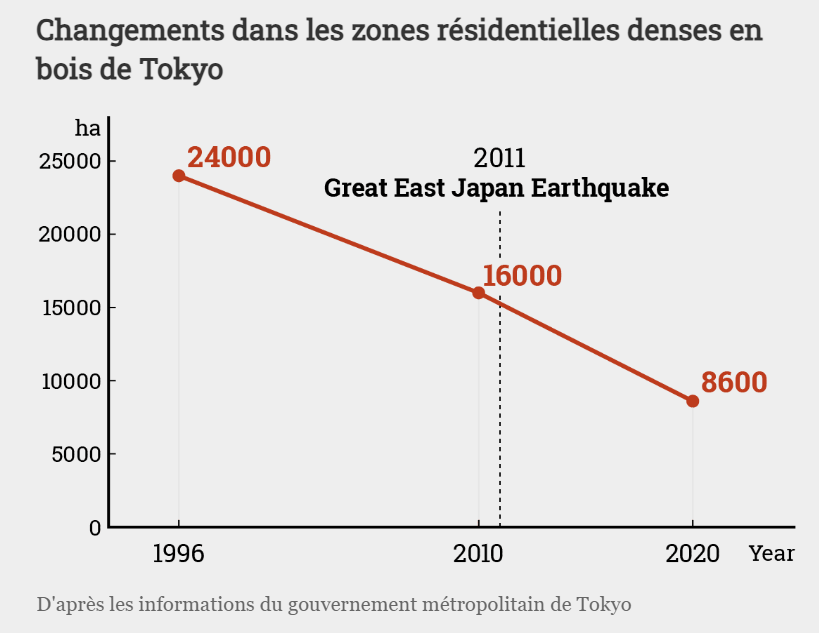

-
12:06
HR TIR DA IRL (High Resolution Thermal Infra-Red Directional Anisotropy In Real Life)
sur Séries temporelles (CESBIO)Dans le cadre de la préparation de la mission Trishna, une question importante concerne la nécessité de corriger les effets directionnels dans les images, ainsi que la méthode à appliquer. Certains d’entre vous sont sans doute familiers de l’effet dit de « hotspot » dans le domaine réflectif, qui a été bien illustré sur notre blog. Dans le domaine de l’Infra-Rouge Thermique, les effets directionnels ne sont pas provoqués par une réflexion directe de la lumière du soleil, mais plutôt par un changement de proportion entre des éléments à l’ombre – donc plus froids – et des éléments au soleil – donc plus chauds – au sein du pixel. Un autre effet, connu sous le nom de gap fraction, est également relié au changement de proportion entre la fraction visible de sol nu et celle de végétation, qui ont des émissivités ou des températures bien différentes. Ces proportions changent continuellement avec les angles de vue du satellite, et quand ces angles sont parfaitement alignés avec les angles solaires, les éléments à l’ombre deviennent invisibles dans le pixel, ce qui cause une température observée plus élevée. Étant donné le champ de vue de +/-34° prévu pour Trishna, ce phénomène se produira régulièrement en fonction de la saison et de la localisation sur le globe.
Il est important de noter que la température de surface (LST pour Land Surface Temperature) n’est pas stable dans le temps comme peut l’être la réflectance de surface (SR pour Surface Réflectance). En effet les facteurs d’évolution principaux de la température de surface sont la météo et le cycle quotidien du soleil. C’est pourquoi, si les effets directionnels dans le domaine Infra-Rouge sont bien modélisés dans des codes de transfert radiatif comme SCOPE ou DART, et parfois observés lors des campagnes terrains instrumentés, ils sont plutôt difficile à observer dans les données satellites réelles, en particulier dans la gamme des Hautes Résolutions (en dessous de 100 mètres). Au CESBIO, nous sommes parti à la chasse (ou plus exactement à la pêche) dans le grand lac des données publiques de télédétection, et – coup de bol – nous avons eu une touche. Vous pouvez trouver notre récit complet ici (ou dans le preprint sur HAL):
Julien Michel, Olivier Hagolle, Simon J. Hook, Jean-Louis Roujean, Philippe Gamet, Quantifying Thermal Infra-Red directional anisotropy using Master and Landsat-8 simultaneous acquisitions, Remote Sensing of Environment, Volume 297, 2023, 113765, ISSN 0034-4257, [https:]] .
En cherchant des acquisitions quasi-simultanées entre Landsat-8 et le capteur aéroporté avec un grand champ de vue MASTER de la NASA (avec l’aide précieuse du JPL), nous avons pu observer la LST quasiment au même moment (à moins de 15 minutes d’intervalle), acquise sous deux angles de vue différents pour 9 scènes en Californie, dont 3 sont proches des conditions de hotspot, comme montré dans la figure ci-dessous (tracks (2), (8) et (12)) :
 Différence de température entre MASTER et Landsat-8, en fonction des angles de visée azimut et zénith de MASTER. La couleur rouge (resp. bleue) signifie que MASTER est plus chaud (resp. plus froid) que Landsat-8. La position du soleil est marquée par une étoile orange.
Différence de température entre MASTER et Landsat-8, en fonction des angles de visée azimut et zénith de MASTER. La couleur rouge (resp. bleue) signifie que MASTER est plus chaud (resp. plus froid) que Landsat-8. La position du soleil est marquée par une étoile orange.
Nous avons observé des différences de LST jusqu’à 4.7K à l’intérieur du champ de vue prévu pur Trishna. En utilisant ces données pour estimer les paramètres de modèles de correction issus de la littérature, nous avons pu ramener cette erreur sous la barre des 2K dans tout les cas, même si nos expériences n’ont pas permis d’identifier le modèle le plus performant. La figure ci-dessous montre à quel point les différents modèles collent aux effets directionnels observés, quand leurs paramètres sont estimés à partir de toutes les observations.
 Estimation aux moindres-carrés des paramètres de cinq modèles directionnels à partir des différences de température observées. L’axe vertical représente le pourcentage de variation de la température entre Landsat (considéré comme Nadir) et MASTER. Dans cette figure, les paramètres conjointement sur l’ensemble des données. Les lignes verticales en pointillés bleus représentent le champ de vue de Trishna.
Estimation aux moindres-carrés des paramètres de cinq modèles directionnels à partir des différences de température observées. L’axe vertical représente le pourcentage de variation de la température entre Landsat (considéré comme Nadir) et MASTER. Dans cette figure, les paramètres conjointement sur l’ensemble des données. Les lignes verticales en pointillés bleus représentent le champ de vue de Trishna.
Un autre constat intéressant concerne la sensibilité des effets directionnels à l’occupation du sol et au stades de croissance de la végétation. En théorie, les paramètres des modèles devraient dépendre de ces facteurs. En effet, le mélange entre parties à l’ombre et au soleil, ainsi qu’entre végétation et sol nu, devrait changer de manière plus importante pour les couverts végétaux intermédiaires. Cependant, nous avons essayé de corréler les différences de températures observées entre MASTER et Landsat-8 avec une combinaison des cartes d’occupation du sol fournies par Copernicus (Copernicus Global Land Service Maps) et du NDVI fourni par Landsat-8. Nous n’avons pas observé de changement significatif des tendances entre les différentes classes et stades végétatifs, comme le montre la figure ci-dessous. Ceci ne veut pas dire que l’occupation du sol et le stade de croissance de la végétation n’est pas important pour la correction des effets directionnels, mais plutôt que les sources de données disponibles pour ces variables sont sans doute trop imprécises pour être utilisées de cette manière.
 Moyenne ± écart-type des différences de température entre MASTER et Landsat-8, en fonction de l’angle de visée zénithal de MASTER, pour les classes principales ( >15% ) de chaque site.
Moyenne ± écart-type des différences de température entre MASTER et Landsat-8, en fonction de l’angle de visée zénithal de MASTER, pour les classes principales ( >15% ) de chaque site.
Même s’il reste beaucoup à faire pour intégrer la correction des effets directionnels dans les segments sols à venir, cette étude montre que sur un ensemble limité d’observations réelles (en Californie), les modèles paramétriques de la littérature avec un paramétrage statique peuvent être utilisés pour diminuer l’impact de ces effets. Cette étude plaide également pour des campagnes aériennes plus importantes dédiées à ce sujet (hors de la Californie), avec des survols simultanées de Landsat-8, afin de pouvoir qualifié et calibrer ces modèles avec un panel plus large de paysages et de conditions d’observations.
-
12:04
HR TIR DA IRL (High Resolution Thermal Infra-Red Directional Anisotropy In Real Life)
sur Séries temporelles (CESBIO) =>
=> 
In the frame of the preparation of the Trishna mission, one important question is : do we have to correct for directional effects, and how should we do it ? Some of you may be familiar with the so-called hotspot effect in the reflective domain, which is well illustrated on our blog. Well in Thermal Infra-Red domain, directional effects are not caused by direct reflection of the sun light, but rather by the change of proportion between shaded, cooler elements and sunlit, hotter elements within the pixel. Another effect, called gap fraction, also relates to a change in proportion between vegetation and ground seen in the pixel, since they have very different emissivities. Those proportions continuously change with the satellite viewing angles, and when the viewing angles of the satellite perfectly align with the sun angles, the shaded elements become invisible in the pixel, resulting in a higher observed temperature. Given the wide field of +/-34° of Trishna sensor, this will be occuring quite often depending on the season and the location.
It is noteworthy that the Land Surface Temperature (LST) is not as stable in time as Land Surface Reflectance (SR), since temperature is mainly driven by meteorological forcing and daily sun cycle. Therefore, if directional effects in TIR domain are well modeled by radiative transfer codes such as SCOPE or DART, and sometimes captured by instrumented field studies, they are quite hard to observe in real satellite data, especially in the High Resolution range (below 100 meter). At CESBIO, we went on a hunt (well actually, more a fishing party) in the wide lake of publicily available remote sensing data, and – luckily – we got a catch. You can read the full story here (or the preprint on HAL):
Julien Michel, Olivier Hagolle, Simon J. Hook, Jean-Louis Roujean, Philippe Gamet, Quantifying Thermal Infra-Red directional anisotropy using Master and Landsat-8 simultaneous acquisitions, Remote Sensing of Environment, Volume 297, 2023, 113765, ISSN 0034-4257, [https:]
By leveraging the MASTER airborne wide field of view sensor from NASA (with the kind support from JPL) and Landsat-8 near simultaneous acquisitions, we were able to observe the LST almost simultaneoulsy (less than 15 minutes appart) acquired under different viewing angles, for 9 scenes in California, 3 of which are close to hotspot conditions, as can be seen in the figure below (tracks (2), (8) and (12)).
Differences in temperature between MASTER and Landsat-8, depending on MASTER azimuth and zenith viewing angles. Red (resp. blue) mean MASTER is hotter (resp. cooler) than Landsat-8. The sun position marked by an orange star.
We observed a LST difference of up to 4.7K within the future viewing angle of Trishna. By fitting parametric models from the litterature, we were able to reduce this error below 2K in all cases, though our experiments did not allow to determine which model should be preferabily used. The figure below shows how well the different models fitted the directional effects, when fitted on all tracks at once.
Least-Square fitting of five TIR directional models on SBT differences. Vertical axis represent the percentage of variation of SBT between Landsat-8 (considered as Nadir) and MASTER. In this figure, each model is jointly fitted on all tracks.Blue dashed vertical lines indicate Trishna field of view.
Another interesting outcome of this study is the sensitivity to land cover and vegetation growing stage. In theory, model parameters should be driven by those factors. Indeed, the mix between shadow/sunlit and vegetation/bare soil should change more dramatically with intermediate vegetation covers. However, when we tried to relate the difference between MASTER and Landsat-8 observed temperature to a combination between a landcover class from Copernicus (Global Land Service maps) and NDVI stratas from Landsat-8 for the growing stage, we did not observe significant trends: all classes behave alike, as shown in the figure below. From this experiment we should not conclude that land-cover and vegetation growth stage is not important for directional effects mitigation, but rather that current available sources of land-cover are probably too coarse and imprecise to be used for the correction of directional effects.
Mean ± standard-deviation of unbiased SBT difference with repect to MASTER signed view zenith angle for the major land-cover classes (> 15%) of each track.
While there is still a lot to do to get operational directional effects corrections in up-coming ground segments, this study shows that on a limited set of real life scenes (from California), parametric models from the litterature with a fixed set of parameter can be used to mitigate the impact of those effects. It also advocates for larger dedicated airborne campaigns (outside of California) with simulatenous flight with Landsat-8, so as to qualify and calibrate those models on a wider range of landscape and conditions.
-
Administrateur systèmes
sur Makina CorpusContrat : CDI
Lieu : Nantes
-
12:42
Rechercher du texte sur les cartes de la collection David Rumsey
sur Cartographies numériquesMis en place en août 2023, le nouvel outil Text-on-Maps permet de rechercher du texte par reconnaissance de caractères sur les cartes de la collection David Rumsey (au total 100 millions de mots indexés sur 57 000 cartes). Jusque là, on ne pouvait interroger que les données et métadonnées du catalogue. Désormais il est possible de chercher des cartes en fonction du texte qu'elles contiennent. Qu'il s'agisse des noms de lieux, de rues, de monuments, de rivières, etc..., les cartes anciennes constituent une source inestimable d'informations historiques et géographiques. La reconnaissance automatique de caractères (OCR) permet d'identifier et d'extraire ces éléments, donnant la possibilité d'étudier et d'analyser l'évolution des paysages, de l'occupation du sol, de l'urbanisme ou des changements géographiques. Une fois le mot saisi et les résultats affichés, il suffit de cliquer sur les étiquettes pour accéder aux cartes correspondantes.
Résultats de recherche avec le mot "Reunion" (507 occurrences) - Source : David Rumsey Collection

Il n'est pour l'instant pas possible de rechercher des mots dans des alphabets non latins, mais l'équipe du site travaille à améliorer les performances de l'outil de machine learning mapKurator afin qu'il soit progressivement utilisable dans toutes les langues. Les recherches ne sont pas sensibles à la casse et ne peuvent pas non plus accepter les expressions. Les recherches multi-mots sont toutefois possibles lorsque les mots adjacents se trouvent à une distance de moins de deux caractères par rapport aux deux points les plus éloignés du polygone de délimitation. On peut par exemple repérer les cartes qui utilisent les deux noms "Réunion" et "Bourbon". L'ordre des mots, les différences de graphie et le fait qu'ils soient indiqués (ou non) entre parenthèses apportent des informations intéressantes (pour savoir par exemple combien de temps le nom de Bourbon a été conservé sur les cartes).
Résultats de recherche avec les mots "Reunion" et "Bourbon" (507 occurrences) - Source : David Rumsey Collection

La qualité des résultats varie en fonction des couleurs du fond, des polices de caractères, de la technique d'impression, de la langue, de l'état de conservation de ces cartes anciennes. La graphie d'un même nom a pu également évoluer. Il peut être intéressant par exemple de chercher comment on écrivait et représentait l'Équateur. On peut utiliser Text-on-Maps aussi pour trouver des points d'intérêt, par exemple une mine d'or, un phare, un moulin, une église, un bureau de poste, etc...
Résultats de recherche avec le mot "Equator" (507 occurrences) - Source : David Rumsey Collection

Les utilisateurs de la collection David Rumsey sont invités à corriger les erreurs éventuelles en proposant une meilleure transcription et/ou à un cadre de délimitation plus précis. Il arrive que certaines cartes portent des noms légendaires ou renvoient à des lieux imaginaires, comme par exemple les fameux Monts de Kong en Afrique... qui n'ont j'amais existé ! On peut chercher des lieux mythiques, par exemple l'Eldorado, l'Atlantide, l'Enfer, le Paradis, etc...
Résultats de recherche avec le mot "Kong" (3 133 occurrences) - source : David Rumsey Collection

Il est possible retrouver des cartogrammes et des graphiques contenus dans des Atlas anciens en saisissant par exemple le terme "data"
Résultats de recherche avec le mot "data" (3 133 occurrences) - source : David Rumsey Collection
Si vous souhaitez affiner les résultats de votre requête avec des filtres basés sur les données du catalogue, vous devez utiliser les fonctionnalités de la recherche avancée. Consultez l'aide détaillée de Text-on-Maps pour obtenir des descriptions complètes sur l'utilisation de cette nouvelle fonctionnalité intéressante.
MapKurator est un outil de machine learning développé par le Knowledge Computing Lab de l'Université du Minnesota pour traiter un grand nombre d'images de cartes historiques numérisées. Les sorties incluent les étiquettes de texte, les polygones de délimitation des étiquettes, les étiquettes après correction post-OCR et un identifiant de géo-entité OpenStreetMap.
The mapKurator System : A Complete Pipeline for Extracting and Linking Text from Historical Maps :
[https:]]Pour accéder à mapKurator sur Github :
[https:]]
Pour compléterGoogle Lens, intégré au moteur Google Image, permet également de reconnaître des noms sur une image ou sur une carte, en important le fichier ou en saisissant simplement son URL. Ce qui permet de récupérer de nombreux toponymes et éventuellement de les traduire en français.
Détection automatique de texte sur des images ou des cartes avec Google Lens
Qu'il s'agisse du moteur interne du site David Rumsey ou du moteur de recherche sur Internet Google Lens, ces outils de reconnaissance de caractères à partir d'images numérisées viennent considérablement enrichir les possibilités de recherche, de sélection et d'analyse en utilisant les nomenclatures que l'on peut trouver sur les cartes. La carte, on l'oublie souvent, c'est du texte aussi bien que de l'image !
« De la reconnaissance de caractères au panoptisme historique en toponymie et cartographie ? Questions et premiers enseignements d’une évolution qui vient » (Géographies linguistiques).
Interview de D. Rumsey
— Sylvain Genevois (@mirbole01) September 18, 2023
"Les cartes dépassent les frontières de l’art et de la technologie. La construction de ma base de données en ligne de 125 000 cartes est devenue une œuvre d’art en soi : un collage d’éléments visuels reliés par des chemins menant à des lieux inattendus" [https:]]Articles connexes
Geonames, une base mondiale pour chercher des noms de lieux géographiques
Les nouvelles perspectives offertes par la cartographie des odonoymes et autres toponymes
Une carte des suffixes les plus fréquents par région des noms de villes françaises
Les monts de Kong en Afrique : une légende cartographique qui a duré près d'un siècle !
La Lémurie : le mythe d'un continent englouti. La cartographie entre science et imaginaire
L'histoire de La Réunion par les cartesL'histoire par les cartes : 18 globes interactifs ajoutés à la collection David Rumsey
Des cadres qui parlent : les cartouches sur les premières cartes modernes
Comment géoréférencer une carte disponible dans Gallica ?





-
10:13
Séminaire, octobre 2022
sur Neogeo TechnologiesBrainstorming, ateliers de travail, balade en fat bike sur la plage…
L’air marin a permis aux collaborateurs de faire émerger de nouvelles idées qui confirment la vision commune des deux entreprises.
Retour en images sur le séminaire organisé pour les équipes de GEOFIT GROUP et de NEOGEO.
-
10:13
Atelier avec le SMEAG
sur Neogeo TechnologiesEn janvier dernier s’est déroulé un atelier avec les équipes du SMEAG – Syndicat Mixte d’Études et d’Aménagement de la Garonne.
L’objectif était de présenter la maquette réalisée dans le cadre de la refonte de leur site internet. Le résultat a été très ???????, les personnes présentes ont approuvées le parcours utilisateur et le design associé.
Nos équipes de production travaillent désormais sur la ????????????? et le ?????????????? du site.


-
10:09
OneGeo Suite, interview GIP ATGERI
sur Neogeo TechnologiesLors des Geo Data Days 2022, nous avons eu l’occasion d’interviewer AnneSAGOT Responsable du Pôle PIGMA, et Emeric PROUTEAU, Référent technique, à propos de la mise en place d’une nouvelle plateforme de données en Nouvelle-Aquitaine.
Ce projet, porté par nos équipes et le GIP ATGeRi, s’est passé «?????? ??? ??? ????????? », malgré les contraintes et imprévus que l’on vous laisse découvrir…
-
10:08
L’Open Source
sur Neogeo TechnologiesChez Neogeo, nous marchons à l’Open Source ! Mais qu’est ce que l’Open Source ?
En quelques slides, découvrez l’un de nos domaines d’expertise.




-
10:07
Deviner la Tchéquie
sur Carnet (neo)cartographique
Contexte de la recherche : Préambule : Ce travail s’inscrit dans un axe de recherche du projet Tribute to Tobler – TTT portant sur l’application des méthodes d’algèbre linéaire à l’analyse des matrices origine-destination dans un objectif de cartographie thématique.
Préambule : Ce travail s’inscrit dans un axe de recherche du projet Tribute to Tobler – TTT portant sur l’application des méthodes d’algèbre linéaire à l’analyse des matrices origine-destination dans un objectif de cartographie thématique.
Ce billet contextualise, commente et présente après en français (après une traduction libre) le Notebook Guessing Czechoslovakia [accéder] réalisé par Philippe Rivière (Visions Carto) pour le #30DayMapChallenge de 2021 : Day22-Boundaries.L’objectif dans lequel s’inscrit ce travail consiste à examiner – suite à une demande de Waldo Tobler lui-même – les conditions théoriques et méthodologiques du transfert des méthodes de l’algèbre linéaire, des valeurs propres et autres décompositions spectrales à l’analyse cartographique des interactions territoriales.
Deux objectifs pour l’usage de l’algèbre linéaire pour cartographier des interactions spatiales/territoriales sont définis :- Le premier vise à simplifier la matrice origine-destination à représenter de manière à ce que la carte des interactions territoriales représentées entre des entités ne subisse pas d’effet spaghetti.
Tobler avait lui-même déjà commencé à examiner ce premier objectif, en reprenant l’un des papiers qu’il considérait comme précurseur de ce transfert, l’article de Peter Gould (1967), On the Geographical Interpretation of Eigenvalues, Transactions of the Institute of British Geographers, 42, p. 53-86. Vu l’intérêt de cet article, Laurent Beauguitte et moi-même l’avons traduit en français dans le cadre du groupe fmr (flux, matrices, réseaux) [Voir la présentation]. La version française et commentée par nos soins de ce texte de Peter Gould est disponible dans la collection HAL du groupe fmr : Sur l’interprétation géographique des valeurs propres.
Tobler a mobilisé pour cela les données de flux de dollars construites par S. Pi pour examiner cette méthode et proposer un ensemble de cartes de flux.
Les méthodes de décomposition spectrale utilisées en algèbre linéaire nous étant assez difficiles à comprendre au premier abord, nous avions des doutes quant à l’intérêt de ce transfert, s’il était effectivement pertinent sur le plan thématique de les utiliser pour cartographier des migrations par exemple.
L’investigation menée sur le premier objectif a ainsi conduit à reproduire la méthode sur le cas américain dans le cadre de TTT, et plusieurs collègues s’y sont attelés.
- Le second objectif consiste à révéler des partitions territoriales issues d’une régionalisation/clustering par des flux, c’est-à-dire de mettre en évidence des régions définies par un ensemble de flux observés entre des entités géographiques de niveau inférieur qui échangent plus entres elles, parce qu’elles appartiennent à une même région, qu’avec des entités de même niveau/échelle géographique mais qui appartiennent à une autre région.
C’est ce second objectif qui est examiné ici.
A la recherche d’anciennes partitions territorialesPour investiguer sur la proposition de Tobler, j’avais décidé de la mettre en œuvre sur les données de flux inter districts de l’ex-Tchécoslovaquie (1990). La raison était simple : je connaissais assez bien cette matrice pour l’avoir longuement manipulée dans la première partie de ma thèse et il (me) serait probablement plus facile de (me) (géo)visualiser les résultats obtenus pour évaluer la méthode en première instance, plutôt que d’essayer de comprendre d’emblée les systèmes d’équations sous-jacents. La cartographie servant ici à comprendre les résultats de travaux en cours ou exploratoires comme ceux présentés ici.
L’hypothèse examinée ici est donc de savoir s’il est possible (avec cette méthode qui permettait de partitionner l’espace à partir de valeurs de flux) de retrouver d’anciennes partitions territoriales antérieures à l’ex-Tchécoslovaquie de 1990, en l’occurrence d’anciennes républiques ou d’anciennes régions. La validation de cette hypothèse pourrait alors faire apparaître la méthode comme potentiellement complémentaire à celles plus traditionnelles en SHS de modélisation des interactions qui s’attachaient à mettre en évidence le rôle des frontières en termes d’ajustement des valeurs de flux (voir notamment les travaux de Nadine Cattan, de Claude Grasland et d’Athanase Bopda sur le sujet).
[Le texte qui suit à été rédigé en anglais par Philippe Rivière, mes ajouts ou commentaires à la traduction sont placés entre crochets].
Ce jeu de données – fourni par Françoise Bahoken dans le cadre du projet Tribute to Tobler représente le mouvement des personnes entre les 114 districts de l'(ex-)Tchécoslovaquie. Il s’agit d’une matrice origine/destination, où le CODEi est un identifiant du district d’origine, le CODEj un identifiant du district de destination, et Fij le flux (nombre de personnes qui se sont déplacées) de i à j au cours de l’année 1990.

Source : Pohyb Obyvatelstva, 1990.
Ces données ont été préparées par Claude Grasland.[L’intérêt d’utiliser ces données tient à ce qu’elles représentent un cas d’école pour examiner le rôle des frontière dans l’ajustement des interactions spatiales et/ou dans la différenciation des différentes régions et districts. La répartition géographique de ces districts (okrej) qui date de 1961 signe en effet l’évolution des frontières historiques de l’ex-Tchécoslovaquie de 1990 : les trois anciennes républiques Tchèque, Morave et Slovaque) elles-mêmes subdivisées en dix régions (kraj) au cours du temps sont visibles sur la partition territoriale de 1990.]

Question : Ces informations sont-elles suffisantes pour réaliser une carte [de flux] de la Tchécoslovaquie ?
Parmi les nombreuses méthodes possibles – en suivant, encore une fois, une suggestion de Waldo Tobler – nous pouvons essayer d’utiliser une méthode de réduction de dimension de la matrice. Dans ce cas, nous allons appliquer la méthode UMAP, de Leland McInnes, aisément disponible en JavaScript et empaquetée par René Cutura dans DruidJS.
La matrice brute est passée dans UMAP ; les résultats obtenus correspondent à des positions XY dans un espace virtuel.
Voici ma carte ! OK … mais vous auriez raison de me poser la question suivante : est-ce que cela ressemble vraiment à la Tchécoslovaquie ? Eh bien, voici un tableau de données complémentaires qui identifie les régions/républiques historiques de chacun des districts : la variable “rep” contient C/S pour Tchéquie/Slovaquie, et “his” contient B/M/S pour Bohème/Moravie/Slovaquie.

Nous pouvons alors colorer les districts, sur la carte issue de UMAP, en fonction de ces deux variables :
Carte des deux anciennes républiques Tchèque et Slovaque

Carte des trois anciennes républiques : Tchéquie, Moravie et Slovaquie
– UMAP version 1 –
Une erreur évidente est que la carte n’est pas [projetée dans un espace géographique et ni] correctement orientée (la Slovaquie, en rouge, est au sud-est.). À part cela, c’est plutôt bien fait !
[La méthode UMAP permet bien de retrouver le découpage historique en trois républiques de l’ex-Tchécoslovaquie, ce qui valide l’hypothèse de départ. Yes!].Carte des trois anciennes républiques : Tchéquie, Moravie et Slovaquie
– UMAP version 2 –
Il est possible que les trois républiques historiques puissent facilement être identifiées à partir de ces seules données de migrations résidentielles avec un simple algorithme de regroupement (CK-means), appliqué à l’UMAP unidimensionnel de la matrice, [pour retrouver d’anciennes partitions].
Carte des trois anciennes républiques : Tchéquie, Moravie et Slovaquie
– variante clustering K-means –
La méthode fonctionne également !
Enfin, nous devons confronter les coordonnées obtenues aux positions réelles des districts sur le terrain. Pour cela, nous allons simplement colorer les districts en fonction du clustering unidimensionnel UMAP, [en les projetant dans l’espace géographique muni des frontières des deux/trois républiques historiques].
Carte des trois anciennes républiques : Tchéquie, Moravie et Slovaquie
– variante UMAP géolocalisée –

D’accord, [en y regardant de plus près], nous avons un peu de confusion, mais dans l’ensemble, ce n’est pas si mal ! L’utilisation d’une mesure de distance plus appropriée (comme la distance cosinus), le regroupement de l’UMAP dans des dimensions plus élevées, avec une méthode de clustering plus intéressante que CKmeans, pourrait nous aider à résoudre ce problème… mais ce sera pour un autre Notebook.
[Autres variantes présentées dans le notebook, mais non satisfaisantes]


Voir aussi :
TTT dans NeocartoLa collection TTT des travaux en français de et après Tobler : hal.archives-ouvertes.fr/TTT/
L’espace de travail collaboratif de TTT : ./tributetotobler/Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.
-
13:01
La pollution de l'air est la première menace mondiale pour la santé humaine (rapport de l'EPIC, août 2023)
sur Cartographies numériques
« La majeure partie de la planète respire un air insalubre, ce qui réduit de plus de deux ans l'espérance de vie dans le monde » (rapport de l'EPIC, août 2023)Selon un rapport de l'Institut de politique énergétique de l'université de Chicago (EPIC) sur la qualité de l'air au niveau mondial, la pollution aux particules fines – émises par les véhicules motorisés, l'industrie et les incendies – représente « la plus grande menace externe pour la santé publique » mondiale. Ce rapport, publié le 29 août 2023, montre que les régions du monde les plus exposées à la pollution de l’air sont celles qui reçoivent le moins de moyens pour lutter contre ce risque.
« L'essentiel de son impact sur l'espérance de vie mondiale est concentré dans six pays seulement », précise le rapport : le Bangladesh, l'Inde, le Pakistan, la Chine, le Nigeria et l'Indonésie. La capitale de l’Inde, New Delhi, fait figure de « mégalopole la plus polluée du monde », avec un taux moyen annuel de 126,5 ?g /m³. A l’inverse, la Chine, a « fait de remarquables progrès dans sa lutte contre la pollution atmosphérique » initiés en 2014, souligne Christa Hasenkopf, directrice des programmes sur la qualité de l’air de l’EPIC. La pollution moyenne de l’air dans le pays a ainsi diminué de 42,3 % entre 2013 et 2021, mais reste six fois supérieure au seuil recommandé par l’OMS. Si ces progrès se poursuivent dans le temps, la population chinoise devrait gagner en moyenne 2,2 ans d’espérance de vie. De nombreux pays pollués manquent d'infrastructures de base pour lutter contre la pollution de l'air. L'Asie et l'Afrique en sont les deux exemples les plus poignants. Ils représentent 92,7 % des années de vie perdues à cause de la pollution. Pourtant, seuls 6,8 % et 3,7 % des gouvernements d'Asie et d'Afrique, respectivement, fournissent à leurs citoyens des données totalement ouvertes sur la qualité de l'air.
Évolution de la pollution aux particules fines PM 2,5 par région entre 1998 et 2021 (source : rapport de l'EPIC, août 2023)

À côté, l'Europe fait presque figure de bonne élève. « Les habitants sont exposés à environ 23,5 % de pollution en moins qu'en 1998 ». Malgré cette amélioration notable, ce n'est pas suffisant : la presque totalité du continent « ne respecte toujours pas les nouvelles lignes directrices de l'OMS ». De plus, « la pollution est nocive pour la santé humaine, même aux faibles niveaux qui existent aujourd'hui dans la majeure partie des États-Unis et de l'Europe », précise le rapport. Selon les chercheurs américains, l'espérance de vie moyenne dans le monde augmenterait de 2,3 ans si les normes de l'Organisation mondiale de la santé (OMS) - une exposition annuelle inférieure à 5 µg/m3 de PM 2,5 - étaient respectées. Ainsi, l'impact de la pollution aux particules fines sur l'espérance de vie est supérieur au tabac. En comparaison, l'alcool fait trois fois moins de dégâts, les accidents de voiture cinq fois, et le VIH/Sida sept fois.
Outre les rapports publiés sur l'indice d'espérance de vie lié à la qualité de l'air (AQLI) à l'échelle mondiale, le site de l'EPIC propose des cartes et des graphiques interactifs. L'un d'eux porte sur le gain potentiel en espérance de vie si l'on respirait de l'air pur. La carte interactive est assortie d'une chronologie qui permet de mesurer les évolutions dans le temps.
Combien de temps en plus pourriez-vous vivre si vous respiriez de l'air pur ? (voir la carte interactive sur le site de l'EPIC).jpg)
Pour en savoir plus sur la méthodologie utilisée pour mesurer l'Indice d'espérance de vie lié à la qualité de l'air (AQLI), voir : [aqli.epic.uchicago.edu]
Lien ajouté le 20 septembre 2023
Carte interactive pour conduire des comparaisons de la pollution de l'air par région [https:]] pic.twitter.com/yuRIwCPlLv
— Sylvain Genevois (@mirbole01) September 20, 2023Articles connexes
Pollution de l'air et zones urbaines dans le monde
Quels sont les États qui ont le plus contribué au réchauffement climatique dans l’histoire ?
Les plus gros émetteurs directs de CO2 en FranceQuand la carte du dioxyde d'azote (NO2) crée comme une ombre fantomatique de l'humanité
Qualité de l'air et centrales thermiques au charbon en Europe : quelle transition énergétique vraiment possible ?L'empreinte carbone des villes dans le monde selon le modèle GGMCF
Le tourisme international et son impact sur les émissions de CO?
Des cartes pour alerter sur la pollution de l'air autour des écoles à Paris et à Marseille
-
17:33
Photogrammar, une collection de photographies prises aux États-Unis entre 1935 et 1943
sur Cartographies numériquesPhotogrammar fournit une plate-forme de visualisation pour explorer les 170 000 photographies prises entre 1935 et 1943 par les agences Farm Security Administration (FSA) et l’Office of War Information (OWI) du gouvernement fédéral américain. Le projet est maintenu par le Digital Scholarship Lab et le Distant Viewing Lab de l'Université de Richmond.
On y trouve des scènes de la vie quotidienne pendant la Grande Dépression et la Seconde Guerre mondiale. Même si le soutien aux politiques du New Deal était un objectif explicite, les objectifs du projet dépassaient l’opportunisme bureaucratique. Stimulés par l'intérêt des sciences sociales contemporaines pour la compréhension de la vie quotidienne des gens ainsi que par leur intérêt pour l'élaboration des archives historiques de l'époque, Stryker et les photographes de l'unité ont élargi le projet pour en faire un projet de documentation de l'Amérique.
Interface de navigation de la plateforme Photogrammar

L'interface du site permet différents parcours de découverte en utilisant la carte ou la chronologie, ou encore en effectuant des recherches par thèmes, par photographes, par Etats ou par villes.
Accès par thèmes aux photographies de Photogrammar

On y trouve notamment le travail de Dorothea Lange, dont les photographies poignantes des sans-abris a attiré l'attention de la Resettlement Administration devenue plus tard la Farm Security Administration, qui la recrute comme photographe officielle en 1935. Mais les photos de Walker Evans, l'une des plus grandes figures humanistes de la photographie du XXe siècle.Articles connexes
Plus de 400 000 photographies aériennes mises en ligne par les archives historiques de l'Angleterre
L'histoire par les cartes : les photographies de la Commission du Vieux Paris
Pour aider à géolocaliser des photographies, Bellingcat propose un outil de recherche simplifié à partir d'OpenStreetMap
Des images aériennes déclassifiées prises par des avions-espions U2 dans les années 1950 ouvrent une nouvelle fenêtre pour l'étude du Proche-Orient
Annoter et partager des images et des cartes numériques en haute résolution en utilisant des outils IIIF
Manga Map, une application qui transforme vos vues aériennes en images de type bande dessinée

.jpg)


-
14:57
Les dernières nouveautés Giro3D
sur OslandiaDans un précédent article, nous vous présentions les dernières évolutions et la roadmap de Giro3D. Dans cet article, nous vous présentons les dernières nouveautés du projet.
Quoi de neuf dans Giro3D ?La dernière version de Giro3D ajoute de nombreuses fonctionnalités, améliorations et correctifs. Voici un aperçu des principales additions.
Effets de nuages de points ( Essayer en ligne)
Un élément important de la roadmap concerne l’amélioration du rendu des nuages de points. L’ajout d’effets comme l’Eye Dome Lighting (EDL) et inpainting améliore grandement la lisibilité et l’aspect visuel des nuages de points. Ces effets font désormais partie du coeur de Giro3D et peuvent être activés à la demande au runtime.

Eye dome lighting sur un nuage de points
Reprojection des couches images ( Essayer en ligne)
L’entité Map peut désormais contenir des couches dont la projection diffère de celle de la scène. Dans ce cas, les images produites par les couches sont automatiquement reprojetées pour correspondre au système de coordonnées de la scène.
C’est particulièrement utile dans le cas où vous ne pouvez pas changer le système de coordonnées de la scène, (par exemple si la scène contient d’autres entités non reprojetables), ou pour mélanger des couches de fournisseurs différents (et de projections différentes).
Nouvelle entité: FeatureCollection (Essayer en ligne)
FeatureCollection permet d’afficher des données vectorielles directement sous forme 3D, sans passer par un drapage sur la Map. Les types de vecteurs supportés sont : points, polylignes et (multi-)polygones.
Nous travaillons actuellement au support des polygones extrudés pour l’affichage de bâtiments en 3D.
2 couches WFS (arrêts de bus et lignes de bus) affichés sous forme de meshes 3D.
Support des plans de coupes ( Essayer en ligne)
Les entités supportent désormais nativement les plans de coupes (clipping planes) de three.js. Vous pouvez activer les plans de coupe pour la scène entière, ou bien par entité, grâce à la nouvelle propriété clippingPlanes. Un nombre illimité de plans de coupes peuvent être ajoutés, par exemple pour définir un volume.
A box volume made of 6 clipping planes
Côté technique Migration vers TypeScriptLa codebase de Giro3D migre vers TypeScript pour une meilleure gestion de la complexité du projet et réduire les erreurs de typages qui représentent une part importante de bugs dans les librairies web.
TypeScript offre de nombreux avantages, comme la migration progressive: pas besoin de migrer tous les fichiers d’un coup, il est possible de mélanger Javascript et Typescript dans le même projet sans problème. Cela nous permet de cibler en priorité les fichiers et modules critiques, tels que ceux qui exposent une API.
Les paquets publiés par Giro3D sur npm.js ne changent pas de contenu: ils resent en Javascript (accompagnés de déclaration de type). De fait, aucun changement n’est nécessaire du côté des utilisateurs de Giro3D et cette migration devrait être transparente.
Une meilleure intégration three.js Giro3D est construit sur le moteur three.js. Notre objectif est une intégration maximale du moteur, afin de bénéficier automatiquement des fonctionnalités de three.js (comme les plans de coupe). Nous souhaitons également laisser les utilisateurs modifier ou adapter Giro3D en accédant directement au moteur sous-jacent et à la scène. Concrètement, cela signifie que les shaders et materials spécifiques à Giro3D sont maintenant bien mieux intégrés aux mécanismes de three.js afin de bénéficier autant que possible des fonctionnalités three.js et éviter la duplication de code. Nouveau document de gouvernanceLa gouvernance de Giro3D est désormais formalisée via un document et une page dédiée. Notre objectif est d’être aussi inclusif que possible et d’accueillir toutes sortes de contributeurs.
-
13:23
Le pointillisme dans l’art pictural et cartographique
sur Carnet (neo)cartographiqueSaviez-vous que le motif en « semis de points » caractérise à la fois le pointillisme, un mouvement pictural néo-impressionniste et un type de carte statistique, la carte par (densités de) points ? Moi je ne ne le savais pas, avant de me plonger pendant le premier confinement, dans les méthodes de cartographie par points avec Nicolas Lambert.
Il est en effet passionnant de noter la proximité qu’il peut y avoir entre le rendu du motif formé de points mis en œuvre dans différents arts graphiques, en l’occurrence picturaux et cartographiques depuis le début du XXème siècle. Le tableau néo impressionniste et la carte par densités de points peuvent en effet être similaires, toutes proportions gardées, dans leur rendu mais aussi dans les méthodes mobilisées et dans la justification de leur usage qui conduisent, dans les deux cas, à des abstractions graphiques de la réalité sous la forme de points, ailleurs ce serait de lignes, comme le souligne Wassily Kandinsky (1923), pour asseoir une posture technique, scientifique.
Le point, dans l’œuvre peinte et cartographiéeL’usage pictural du point s’inscrit dans le pointillisme, un mouvement néo-impressionniste introduit avec le tableau du peintre Seurat (1859-1891) intitulé « Un dimanche à la Grande Jatte en 1886 ».
Un dimanche à la Grande Jatte en 1886 (Seurat, 1886)

Source : Google Art Project/Wikipedia, voir.
Le pointillisme est définit par le Larousse, comme un « […] mouvement dont les adeptes eurent en commun une technique fondée sur la division systématique du ton », c’est en ce sens qu’il s’apparente au processus de cartographie par densités de points qui est fondé sur une division systématique de la quantité représentée, qu’elle soit teintée ou non.
Le pointillisme, tel que mobilisé initialement dans la peinture et dans la cartographie par densités de points est une méthode mise au point pour assurer leur caractère scientifique. Pour la cartographie, il s’agissait de représenter des données statistiques sur la démographie (quantités discrètes de populations).
La volonté de remédier aux effets de flou dans la peinture impressionniste rappelle en effet celle du « refus » d’une vision agrégée de la population humaine, c’est-à-dire d’une représentation de la distribution de la population au sein de mailles symbolisant des zones administratives.
Aparté. Le terme « refus » ci-dessus est à prendre avec des pincettes, un autre terme conviendrait peut-être mieux, mais lequel ?. Ce refus d’une présentation agrégée de données de populations m’évoque un refus similaire appliqué cette fois aux lignes : le « problème de la flèche », qui correspond au « refus » de la cartographie de migrations humaines sous une forme agrégée…
Aux rendus des œuvres impressionnistes plus classiques considérés comme brumeux par les spécialistes peuvent ainsi être associés ceux des signes proportionnels et des aplats opaques typiques des cartes choroplèthes ; ces deux procédés étant les modes de représentation privilégiés des quantités agrégées de population, la cartographie par points ayant eu du mal à s’imposer comme l’explique Gilles Palsky (1984).
La carte en densité de points (Montizon, 1830)La cartographie par points est une grande famille de carte statistique qui mobilise le point en implantation spatiale graphique et/ou géométrique/géographique pt(X,Y), pour représenter des quantités absolues ou discrètes. Si le point peut être mobilisé en cartographie selon différentes modalités, l’une d’entre elles correspond à la « carte en densités de points », une méthode de représentation introduite vers 1830 par Armand Joseph Frère de Montizon (1790-1859), pour représenter la répartition de la population française à l’échelle des départements.
Carte philosophique de la population de la France (Montizon, 1830)

Le motif perçu sur la carte de Montizon, comme sur le tableau de Seurat, est un semis de points présentant des densités de points variables selon les zones.
Sur la carte, le nombre de points représentés par zone est fonction d’une relation d’équivalence individus-points, de type un-à-plusieurs (1-à-n). Dit autrement, un point sur la carte correspond à un ou plusieurs individus, en l’occurrence à une ou plusieurs personnes recensées dans les départements de l’époque. Sur la carte de Montizon, un point symbolise dix mille personnes, deux points correspondent à vint mille personnes et ainsi de suite.
Toujours sur la carte de Montizon, le placement des points ne correspond pas à un ordre particulier, dans cette version historique de la méthode. Sur la carte ci-dessous (déjà présentée ici), la répartition de la population mondiale s’appuie sur un point-équivalent 3 millions de personnes par défaut, une valeur qu’il vous est possible de paramétrer dans Observable.
Carte en densités de points de la population du monde (Lambert, 2021)
Dans la version historique de la méthode, l’ensemble des points d’une zone y est entièrement inclus (l’appartenance d’un point à une zone étant exclusive).
A noter qu’il est aujourd’hui possible avec Bertin.JS (fonction dotdensity) d’autoriser les débordements des points d’une zone sur une autre zone, comme illustré sur la carte suivante.
Carte en densités de points de la population américaine (Lambert, 2022)
- sans débordements

- avec débordements
La carte en densité de points colorés (Jenks, 1953)
Plusieurs décennies après cette première initiative de Montizon, Georges Frederick Jenks (1916-1996), un célèbre cartographe américain (bien connu pour ses innovations en cartographie statistique parmi lesquelles la méthode de seuillage naturel des données continues fondée sur la variance [voir]), mobilise la cartographie par densité de points pour représenter des quantités discrètes et typées/catégorielles.
Pour cela, Jenks va s’inspirer du pointillisme, qu’il érige d’ailleurs comme méthode cartographique dans un article publié en 1953, et, entreprend de l’appliquer pour cartographier la répartition des récoltes de 1949 aux États-Unis. Il justifie ce choix par le besoin de disposer d’une « une présentation plus réaliste de la distribution des cultures » que celles précédemment cartographiées par Marshner (1950).
Jenks affirme que les éléments clés de la conception de sa carte sont le choix des couleurs puis l’arbitrage entre la taille et la valeur du point à représenter et cela, en fonction de l’extension des surfaces cultivées.
« Les couleurs ont été attribuées en tenant compte des éléments suivants :
1. Les couleurs doivent rappeler au lecteur de la carte la culture qu’elles représentent.
2. Les cultures de grande valeur et de petite superficie, telles que le tabac ou les camions, doivent être colorées plus intensément que les cultures plus étendues et plus vastes.
Les cultures de grande valeur et de faible superficie, telles que le tabac ou les camions, doivent être colorées plus intensément que les cultures plus étendues et cultivées à grande échelle.
3. Les cultures mineures sélectionnées, telles que les arachides ou le soja, qui tendent à modifier le caractère des cultures cultivées dans des zones plus étendues, devraient avoir des couleurs plus intenses que les cultures plus étendues.
Les cultures qui ont tendance à modifier le caractère des cultures dans des zones plus étendues doivent avoir des couleurs d’une intensité modérée.» Jenks, 1953.Jenks sélectionne alors une série de teintes pour colorer les différentes types de cultures, ce qui conduit à une nouvelle carte par densité de points colorés. On notera que cette méthode est plus souvent utilisée aujourd’hui pour cartographier la distribution ethnique dans les pays qui en font l’usage (racial dotmaps).
Sur ces cartes par densité de points, qu’ils soient colorés ou non, il est important de noter que leur répartition spatiale au sein de chaque zone est aléatoire et relativement à chacune d’elles. Cette précision sur le placement des points n’est pas anodine, car il est désormais possible de jouer sur les possibilités de spatialisation des points d’un semis au sein des zones. Ces possibilités sont proposées dans le cadre d’une nouvelle carte par points dénommée …
à suivre !
[l’article introduisant cette carte étant actuellement sous presse, la phrase sera complétée ultérieurement]Références :
Jenks G. F. (1953), « Pointillism » as a cartographic technique, in: The Professional geographer, pp. 4-6.
Kandinsky W. (1923) Point et ligne sur plan. version .pdf sur le site www.holybooks.com
Montizon F. A. J. (1830), Carte philosophique figurant la population de la France, Disponible en .jpeg sur BNF/Gallica.
Palsky G. (1984), La naissance de la démocartographie. Analyse historique et sémiologique, in: Espace, populations, sociétés. Université des Sciences et Technologies de Lille. 2 (2), 25–34.
Billets liés :
Voir aussi :
Bertin.JS : dot density map
[R] Transformer des quantités aréales en densité de points
Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.
- sans débordements
-
12:45
Publication d'un Atlas complet en open data sur Budapest
sur Cartographies numériques
L'équipe de journalisme visuel et de données Alto.Team, basée à Budapest, commémore le 150e anniversaire de l'unification de Buda, Pest et Óbuda avec une série de 50 cartes alternatives produites à partir de données open source. Les cartes couvrent le passé et le présent récents de Budapest, depuis ses caractéristiques physiques jusqu'aux activités humaines et aux réalités sociales de la capitale hongroise. L'objectif est de fournir une perspective différente de la vision traditionnelle. En cliquant sur les images, les cartes individuelles peuvent être visualisées en grande résolution. Les données sont téléchargeables gratuitement au format geojson, afin que chacun puisse en créer sa propre version.Atlas de Budapest avec 50 cartes a télécharger en open data (source : Alto.Team)
Sommaire (cliquez pour accéder au chapitre) :1. Budapest vue à vol d'oiseau2. Climat et météo3. Géographie et hydrographie4. Faits sociaux5. Traces d'activités humaines6. Méthodologie et notesAnnexe I. – CouchesAnnexe II. – Méthodes de représentationAnnexe III. - Comparaison
Les données et cartes peuvent être librement utilisées et modifiées à des fins pédagogiques, informatives et scientifiques avec référence à la source. Leur utilisation commerciale et lucrative n'est pas autorisée. Référence à citer : Attila Bátorfy, Budapest Open Data Atlasza, Budapest, 2023. URL : [https:]]
Les limites administratives de Budapest sont disponibles en open data sur le site d'OpenStreetMap qui fournit en outre des données sur le réseau routier, les chemins de fer, les bâtiments et l'utilisation du sol à l'échelle de la Hongrie.
Articles connexes
L'histoire par les cartes : comment le continent européen s'est pensé et construit du 16e au 20e siècle (BnF - Gallica)
La carte, objet éminemment politique. La vision réciproque de la Russie et de l'Europe à travers la guerre en Ukraine
Cartes et données sur l'enseignement et la formation en Europe (source Eurostat)
Le vieillissement de la population européenne et ses conséquences
Rubrique fonds de cartes SIG

-
10:20
Geotribu dans le terminal
sur Geotribu Consultez Geotribu en ligne de commande : rechercher et afficher nos contenus directement dans votre terminal.
Consultez Geotribu en ligne de commande : rechercher et afficher nos contenus directement dans votre terminal.
-
7:52
Mapping China's Strategic Space : un site d'analyse géopolitique à base de cartes
sur Cartographies numériques
« Cartographie de l'espace stratégique de la Chine. Explorer comment Pékin envisage sa place dans un environnement géopolitique en évolution ».
Le projet Mapping China's Strategic Space s'appuie sur les travaux menés par le National Bureau of Asian Research visant à appréhender les tentatives des élites intellectuelles et politiques chinoises pour définir une vision de leur pays comme grande puissance sur la scène internationale. L'objectif du projet est de mieux comprendre ce qui constitue l'espace imaginé au-delà des frontières nationales de la Chine, que ses dirigeants considèrent comme vital pour poursuivre ses objectifs politiques, économiques et sécuritaires nationaux, et réaliser son ascension.Page d'accueil du site Mapping China's Strategic Space

Lancé en août 2023, le site s'organise autour de quatre rubriques principales :- Apprendre de l'histoire : cette section présente une collection d’études de cas historiques, utilisées à des fins comparatives, qui examinent comment les grandes puissances émergentes, dont la Chine, ont défini dans le passé leur espace stratégique et les facteurs qui les ont amenées à envisager de l’élargir au-delà des strictes délimitations de l'espace stratégique de leur territoire national.
- Géopolitique : un ensemble de contributions explore les fondements géopolitiques, les représentations spatiales et les nouvelles frontières de l'espace stratégique chinois.
- Multimédia : ressources vidéos et audios, témoignages et interviews d'experts et d'analystes
- Experts : présentation du groupe d'experts participant au projet Mapping China's Strategic Space
Parmi les articles déjà mis en ligne :- Comment les puissances terrestres et maritimes voient la carte par Jakub Grygiel
- La culture politique de l’impérialisme dans le Reich allemand par Woodruff D. Smith
- Cartes mentales, imagerie territoriale et stratégie : penser l'empire japonais par Alexis Dudden
Vidéos et podcasts à découvrir :- Le Myanmar et la frontière fluide de la Chine par Kelley Currie
- Conceptions de l’espace stratégique dans la Chine républicaine par Bill Hayton
La carte, objet éminemment politique : la Chine au coeur de la "guerre des cartes"
La carte, objet éminemment politique. Les tensions géopolitiques entre Taïwan et la Chine
Comment la Chine finance des méga-projets dans le monde
Utiliser les cartes du CSIS pour étudier les grandes questions géopolitiques du monde contemporain
Les investissements de la Chine dans les secteurs de l'Intelligence artificielle et de la surveillance
Tentative de "caviardage cartographique" à l'avantage de la Chine dans OpenStreetMap
Trois anciennes cartes de la Chine au XVIIIe siècle numérisées par l'Université de Leiden
Etudier les densités en Chine en variant les modes de représentation cartographique

-
11:31
Du 23 au 25 janvier 2024 à Lille : formation "savoir utiliser les Fichiers fonciers"
sur Datafoncier, données pour les territoires (Cerema)Publié le 08 novembre 2023Une session de formation "Savoir utiliser les Fichiers fonciers" se tiendra du 23 au 25 janvier 2024 dans les locaux du Cerema Hauts-de-France à Lille. Cette session est à destination des bénéficiaires des Fichiers fonciers et des bureaux d'études. Vous trouverez le contenu et le coût de la formation dans la rubrique Accompagnement Inscription jusqu'au 22 décembre (…)
Lire la suite -
11:31
Du 12 au 14 décembre 2023 à Lille : formation "savoir utiliser les Fichiers fonciers"
sur Datafoncier, données pour les territoires (Cerema)Publié le 09 novembre 2023Une session de formation "Savoir utiliser les Fichiers fonciers" se tiendra du 12 au 14 décembre 2023 dans les locaux du Cerema Hauts-de-France à Lille. Cette session est à destination des bénéficiaires des Fichiers fonciers et des bureaux d'études. Vous trouverez le contenu et le coût de la formation dans la rubrique Accompagnement Inscription jusqu'au 15 novembre (…)
Lire la suite
-
12:08
Décret n° 2023-767 du 11 août 2023 relatif à la mise à disposition par les communes des données relatives à la dénomination des voies et à la numérotation des maisons et autres constructions
sur Conseil national de l'information géolocaliséeDécret n° 2023-767 du 11 août 2023 relatif à la mise à disposition par les communes des données relatives à la dénomination des voies et à la numérotation des maisons et autres constructions
-
16:00
Cartographier les particularismes régionaux de la langue française
sur Cartographies numériques1) L'Atlas sonore des langues régionales de France, une référence incontournable
Il existe une trentaine de langues régionales en France métropolitaine et dans les Outre-mer, sans compter les nombreux patois. Des chercheurs au CNRS les ont fidèlement répertoriées sur une carte interactive que l'on peut découvrir sur le site de l'Atlas sonore des langues régionales de France. Une fable d'Esope a été enregistrée dans 307 patois différents, révélant la grande richesse linguistique de la France. On peut aussi découvrir, dans le voisinage de la France, les langues et dialectes d'Italie, de Belgique, de Suisse, de la Péninsule ibérique et de l'Allemagne.
Souce : Atlas sonore des langues régionales de France
Pour compléter : Carte linguistique de la France au XXe siècle (Archives nationales), établie à partir du plan de classement de la Bibliographie des dictionnaires de patois galloromans publiée en 1969 par le linguiste Walther von Wartburg qui, dans son introduction, détaille le contour des aires selon lesquelles sont répartis les dictionnaires et glossaires dialectaux recensés.2) Les régionalismes cartographiés par Mathieu Avanzi
Le linguiste Mathieu Avanzi (@MathieuAvanzi) s'intéresse depuis plusieurs années aux régionalismes, ces mots qui désignent un même objet mais varient en fonction des régions. L'auteur étudie ces variations du langage en réalisant des cartes qu’il partage sur les réseaux sociaux. Il a créé, en octobre 2021, une application intitulée Français de nos régions . « Gratuite puis disponible sur l’Apple Store et Google Play, elle permet de s’exercer de manière ludique et interactive sur les expressions régionales, et de répondre aux enquêtes qui viendront nourrir de futures cartes. La géolinguistique devient ainsi une vraie science participative »
Après avoir été maître de conférences à Sorbonne Université (Paris IV) au sein de la chaire Francophonie et variété des français, Mathieu Avanzi a été nommé professeur ordinaire à l'université de Neuchâtel, où il dirige le Centre de dialectologie et d'étude du français régional. Ses travaux portent sur la géographie linguistique du français, sujet auquel il a consacré plusieurs articles et ouvrages.
Pour en savoir plus : Mathieu Avanzi, le chercheur qui décortique les mots du quotidien et les expressions de nos régions (Interview pour Ouest-France).
Pochon, poche, cornet… Comment appelle-t-on un « sac » dans votre région ? Répone ici [https:]] pic.twitter.com/9XtZ0gmqTm
— Mathieu Avanzi (@MathieuAvanzi) August 15, 2023Parmi les nombreux exemples de régionalismes qu'il a étudiés à travers des enquêtes, en voici quelques-uns célèbres (et d'autres moins connus) qui concernent la France, mais aussi la Belgique, la Suisse ou le Canada :
- Pain au chocolat vs chocolatine… Fight ! (voir son interview pour Brut fr)
- Pochon, poche, cornet… Comment appelle-t-on un « sac » dans votre région ? (voir son interview pour Brut fr)
- Faire l'école buissonnière, sécher ou faire péter les cours
- Les pâtisseries du mardi-gras : bugnes, merveilles, oreillettes, etc.
- Avoir un pantalon trop court, aller à la pêche aux moules, aller aux fraises...
- Les dénominations sur l'extrêmité du pain : cul, croûton, quignon...
- Dénomination de la fête patronale : fête, vogue, pardon...
- Petit billet utilisé pour tricher à l'école : pompe, carotte, antisèche...
- Etendoir, séchoir ou tancarville ?
- Serpillère, patte ou panosse ?
- Variations sur le pot d'eau : pot, cruche ou carafe ?
- Escargot, cagouille ou lima ?
- Le y dit neutre, un régionalisme de la grande région lyonnaise
- Remarques sur la prononciation du mot ‘foot’ en Suisse romande
- Taisez ce -p- que je ne saurais entendre, part. 1: ‘septembre’
- D’où viennent les gens qui disent cent-Z-euros ?
- Tu veux d'autres pâtes ?
Voir l'index des articles publiés sur le blog francaisdenosregions.com depuis sa création.
Articles connexes
Délimiter le Nord et le Sud en France : une affaire de représentations ?
Étudier la répartition géographique des noms de famille en France et en Europe
Répartition géographique et sociologie des prénoms en France
Geonames, une base mondiale pour chercher des noms de lieux géographiques
Les nouvelles perspectives offertes par la cartographie des odonoymes et autres toponymes
Cartographie des noms qui servent à désigner les couleurs en Europe (Mapologies)
Pourquoi il n'y a que deux mots pour dire "thé" dans le monde
-
19:14
L'histoire par les cartes : le mouvement des enclosures en Grande Bretagne aux XVIIIe et XIXe siècles
sur Cartographies numériquesL'enclosure désigne un processus juridique visant à clôturer les champs ouverts et les terres communes ou en restreindre l'utilisation à un seul propriétaire. Le mouvement remonte à la fin du Moyen Age, mais s'accèlère à partir du XVIIe siècle. Selon Géoconfluences, « l’enclosure est un mouvement cumulatif : chaque nouvel enclos tend à faire reculer les droits d'usage au profit du droit de propriété, et incite finalement à enclore de nouvelles parcelles ; à terme, la réduction des surfaces exploitables pour les paysans a nourri un premier exode rural et un transfert de main d’œuvre précoce de l’agriculture vers la manufacture. Le mouvement des enclosures est en ce sens l'une des racines de la première révolution agraire et industrielle ». Karl Marx considère que ce bouleversement économique et juridique est un point de départ du capitalisme. Pour Marc Bloch c'est « le mouvement révolutionnaire des enclosures qui a établi une séparation majeure entre l'Angleterre rurale passée et présente ».
Enclosure des terres communes de la paroisse de Snaith dans le nord du Yorkshire en 1751
(source : Howdenshire history). A comparer à cette carte de 1821.Les lois d'enclosure de 1801, 1836 et 1845 rendirent le processus plus facile, beaucoup d'enclosures datant de cette période. Ce "mouvement des enclosures parlementaires" (Inclosure Acts) concerne une grande partie de l'Angleterre.
Carte des communs enclos par actes du Parlement anglais
(source : The English Peasantry and the Enclosure of Common Fields par Gilbert Slater, 1907)Ces divisions parcellaires nécessitaient d'importantes opérations d'arpentage sur le terrain. Ce qui explique que l'échelle de ces plans d'enclosure soit souvent la chaîne d'arpentage elle-même, devenue unité de mesure officielle en Angleterre. Inventée au XVIIe siècle, la chaine de Gunter du nom d'un mathématicien britannique, mesurait 66 pieds soit environ 20 mètres.
La chaîne d'arpentage de Gunter (source : Wikipedia)
Certains plans fonciers reportent dans leur échelle l'unité de mesure en nombre de chaînes avec leur équivalence en pouces sur la carte : "6 Chains in 1 Inch" ou "3 Chains in 1 Inch". Voir par exemple cette barre d'échelle très décorative sur un plan d'enclosure de 1813 :
Plan d'une succession de William Chaytor par G Thornton, 1813
(source : Archives du comté du Nord Yorkshire)Les actes d'enclosure contiennent généralement le nom du propriétaire, l'étendue des parcelles et la nature du régime foncier (en pleine propriété, en fermage, etc...). Les plans et actes d'enclosure sont utiles pour suivre l'évolution de la propriété foncière, l'organisation du parcellaire, l'histoire rurale, etc. Les parcelles encloses (indiquées en général en vert) marquent la division des zones de communs.
Plan du canton de Wombleton et Harome Common par John Tuke, 1816
(source : Enclos et paysage : une étude de cas à Harome par Gail Falkingham)Le mouvement historique des enclosures concerne aussi le Pays de Galles. Le projet pilote Deep Mapping Estate Archives s'est concentré sur une petite zone du nord-est du Pays de Galles pour laquelle les cartes ont été vectorisées et superposées de manière à montrer la progression du mouvement des enclosures entre la fin du XVIIIe et le début du XIXe siècle.
Évolution des enclosures au Pays de Galles (source : Historic Enclosure Mapping - 1800-1830)
L'étude du mouvement des enclosures connaît aujourd'hui un regain d'intérêt, notamment par rapport à la question de la défense des Communs numériques face aux géants privés d'Internet. Ce « second mouvement des enclosures » à l'ère du numérique constituerait un emprunt trompeur selon Allan Greer qui montre, dans un article publié sur la Vie des idées, les points communs et les différences par rapport aux luttes agraires des siècles passés.
Pour aller plus loin
« Mouvement des enclosures ». Article de Wikipédia en version française.
« Enclosure ». Article de Wikipédia en version anglaise.
Les terres en jouissance collective en Angleterre 1700-1850 par Jeanette M. Neeson. In Demélas & Vivier, Les propriétés collectives face aux attaques libérales (1750-1914).
Les communautés villageoises dans l'évolution rurale britannique à la fin du XVIIIe siècle par Kate Tiller. Annales Historiques de la Révolution française - 1999
Guide des actes et des cartes d'enclosure au Royaume Uni (The National Archives).
Common Right and Private Interest. Rutland’s Common Fields and their Enclosure par Ian E Ryder (ouvrage à télécharger)
Cartes du village de Helpston montrant l'évolution du parcellaire avant et après enclosure (John Steane, The Northamptonshire Landscape, 1974).
Carte d'enclosure de Pirton (1818) avec base de données des parcelles.
« Des barbelés sur la prairie Internet : contre les nouvelles enclosures, les communs numériques comme leviers de souveraineté » (France Diplomatie).
« Confusion sur les Communs » par Allan Greer (La Vie des Idées).
Articles connexes
La grille de Jefferson ou comment arpenter le territoire américain
L'histoire par les cartes : la mappe sarde du XVIIIe siècle
Etudier les formes urbaines à partir de plans cadastraux
La parcelle dans tous ses états (ouvrage en open access)
Mise à disposition de la base Demandes de valeurs foncières (DVF) en open data
Fichiers des locaux et parcelles des personnes morales en open data (données MAJIC)
OneSoil, la carte interactive des parcelles et des cultures en Europe et aux Etats-Unis
EuroCrops, un ensemble de données harmonisées et en open data sur les parcelles cultivées au sein de l'UE


-
13:57
Récréation – recréation sémiologique*
sur Icem7Les publications statistiques de la Drees sont très intéressantes sur le fond, mais j’ai parfois un peu de mal à comprendre rapidement le message des graphiques qu’elles présentent…
Cet article de juillet 2023 sur « les mesures socio-fiscales 2017-2022 » évoque un sujet majeur, celui du pouvoir d’achat, et la contribution des prestations sociales comme le RSA, les aides au logement ou la prime d’activité, à son évolution récente. Les impôts et les taxes sont également pris en compte : quand ils baissent, ils augmentent le « revenu disponible ».
Nous allons examiner deux graphiques de cette publication et voir comment les reconstruire de façon plus expressive.
Ce premier diagramme expose les différentes composantes du revenu disponible : salaire (quand la personne travaille), prestations sociales, impôts et taxes. Le graphique considère un « cas-type », celui de personnes seules locataires, à différents niveaux de salaire, y compris celles sans activité (pas de salaire).
Bien qu’évoquant une « décomposition », le graphique de la Drees met surtout l’accent, par des aplats de couleur tranchés, sur la différence entre salaire (ligne rouge) et revenu disponible (ligne noire). Cette représentation dérivée élève d’emblée le niveau d’exigence requis pour la bonne compréhension des concepts et de leur articulation.
La zone de croisement des courbes est un peu floue, il faut saisir que la surface bleue (impôts) vient se soustraire du salaire pour aboutir au revenu disponible.
Reconstruire posément avec un outil simple type DatawrapperCommençons par mettre à plat, de façon homogène, toutes les composantes du revenu disponible :
La Drees fournit les données détaillées avec l’article (elles vont même jusqu’à 2 smic), et j’utilise l’outil web Datawrapper dans sa version gratuite, par copier/coller du jeu de données.
Les aires (colorées de façon plus douce) traduisent clairement toutes les contributions, positives (salaire et prestations) ou négatives (impôt). Les trois grandes catégories se distinguent aisément par leur opposition chromatique (oranges, vert, gris).
Le seul tracé linéaire dessine la résultante, le revenu disponible. L’on devine intuitivement qu’il exprime la soustraction entre contributions positives et négative.
L’impôt apparait un peu avant (1,1 smic) que les prestations ne s’effacent (1,45 smic).
En inversant le placement de la prime d’activité et des aides au logement (AL), je mets mieux en évidence la quasi-constance des AL de 0 à 0,4 smic.
D’une façon générale, ramenant à une base horizontale un maximum de contributions (salaire, RSA, AL et impôt), leur évolution devient précisément perceptible.
Légende intégrée (les aires sont nommées au plus près), suppression du grisé d’arrière-plan, atténuation des grillages contribuent à la hiérarchisation des éléments du graphique, et donc à la lisibilité d’ensemble.
Pour parfaire le résultat, je réintègre les mentions obligatoires (source, définitions), ajoute un titre informatif et annote quelques points clés.
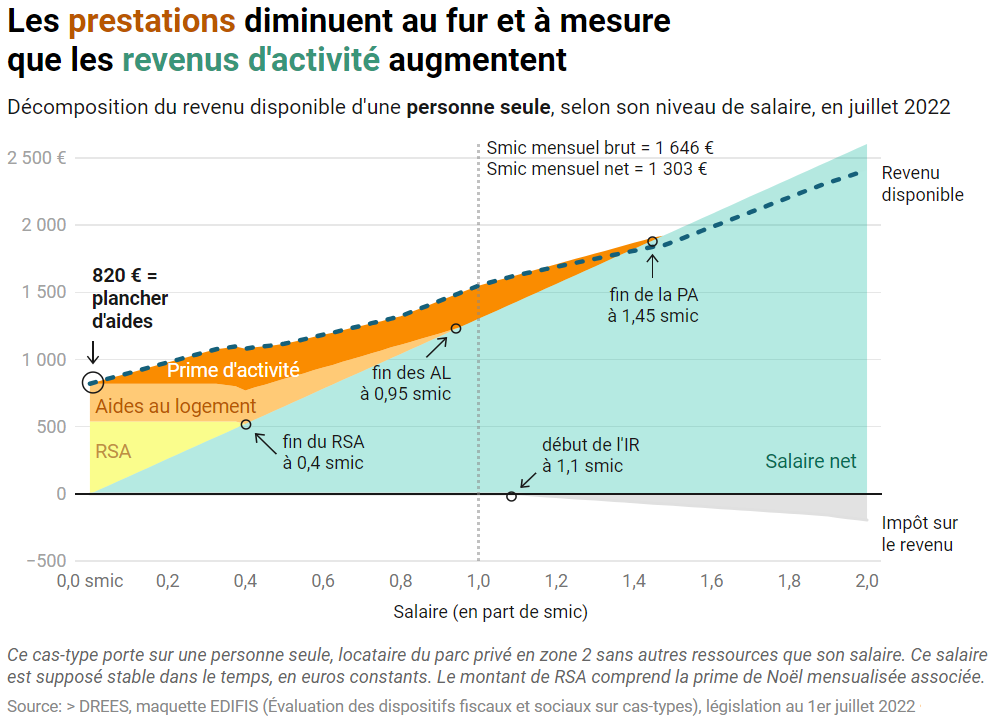
Ce graphique de synthèse traduit l’essentiel à retenir des mécanismes de compensation et d’amortissement à l’œuvre. Il est plus facile à mémoriser.
En réalisant ce travail sémiologique, j’ai enfin saisi l’articulation de concepts que je n’avais compris que partiellement jusqu’alors. Ces vagues qui se déploient et se succèdent deviennent tout naturellement esthétiques : la beauté nait de l’évidence.
C’est un autre graphique que la Drees a mis en avant sur les réseaux sociaux, car il relaie le titre et donc le message essentiel de l’étude : comment le pouvoir d’achat a-t-il évolué ces 5 dernières années selon le niveau de salaire ?
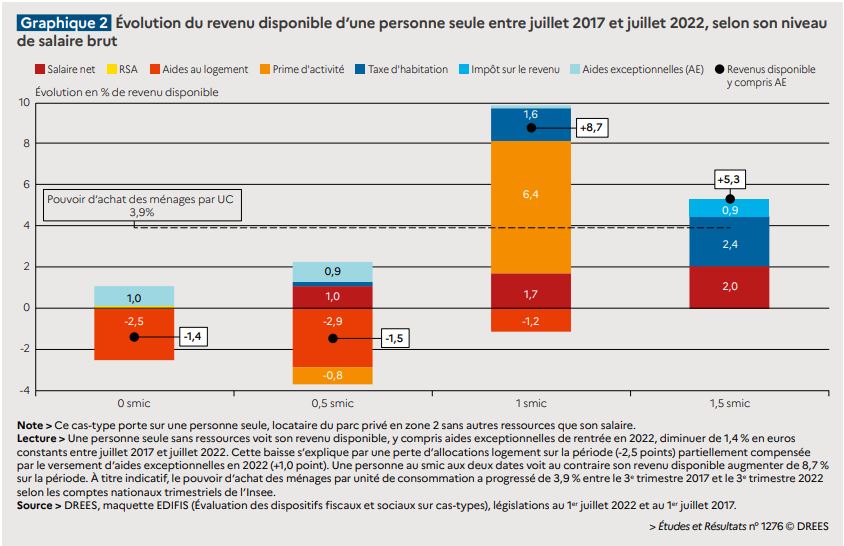
Si j’ai assez vite épinglé ce graphique dans mes « favoris », c’est qu’au bout de 10 secondes je n’avais toujours rien saisi, même pas un début de fil à tirer ! Ces empilements colorés flottaient devant mes yeux sans qu’aucune porte ne s’ouvre.
J’ai donc suivi la même démarche que précédemment, partant des données détaillées et jouant avec Datawrapper. La première action clarifiante consiste à ramener les données à comparer à une base (verticale) commune : les éléments ne flottent plus, le diagramme gagne en structure.

Après transposition, cette représentation quasi-brute proposée par l’outil graphique a commencé à me parler, des motifs et des regroupements naturels se laissent deviner.
Jacques Bertin : « Comprendre, c'est catégoriser »Ainsi, suivant le précepte bertinien du reclassement optimal des colonnes (les lignes sont déjà naturellement ordonnées), j’aboutis après quelques permutations à ceci :
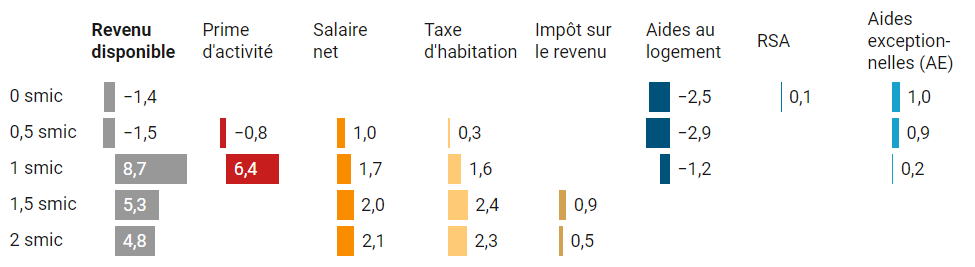
Je place en premier l’indicateur de synthèse, l’évolution du revenu disponible. Ensuite, deux groupes de composantes s’ordonnent dans un sens que le choix des couleurs rehausse.
Il est d’abord manifeste que le revenu disponible a évolué en 5 ans de façon fort différente sous le smic et à partir d’un smic :
- Le maximum, près de 9 % de progression, s’observe pour les personnes seules au niveau du smic ; il est porté par la prime d’activité (forte revalorisation du bonus individuel en 2019).
- Au-dessus du smic, la progression du salaire net et surtout la diminution de la taxe d’habitation et de l’impôt sur le revenu prennent le relais : elles assurent une augmentation de près de 5 %.
- Sous le smic, la baisse sensible des aides au logement n’a pas été compensée par les « aides exceptionnelles » : il en résulte une diminution de pouvoir d’achat de l’ordre de -1,5 %.
Ces trois constats sont bien plus aisément perceptibles qu’avec le graphique originel. Un titre informatif peut les introduire, dans cette version finale :
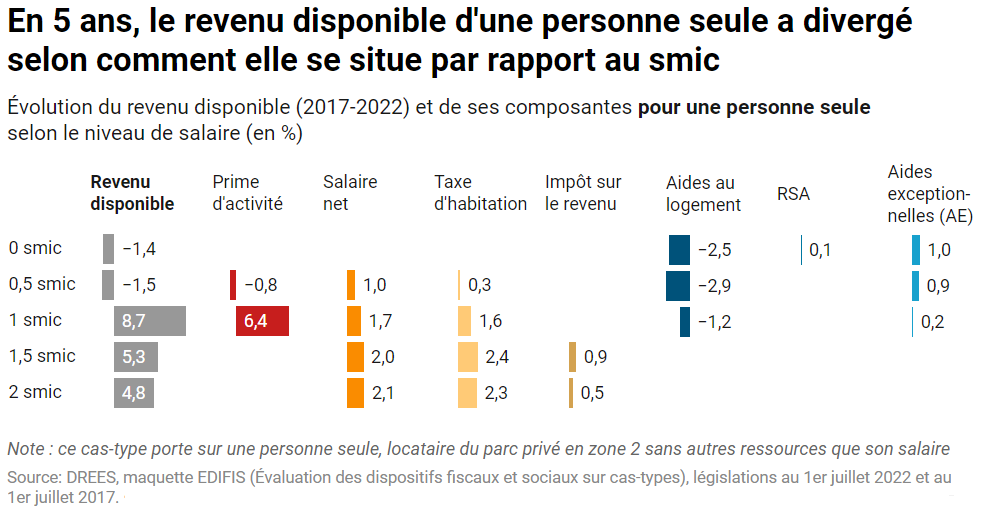 Pour aller plus loin* : comme quoi parfois un accent fait toute la différence
Pour aller plus loin* : comme quoi parfois un accent fait toute la différence 
L’article Récréation – recréation sémiologique* est apparu en premier sur Icem7.
-
CUMA GRP : guide des prix de revient du matériel
sur Makina CorpusUne CUMA (Coopérative d’Utilisation de Matériel Agricole) est une structure agricole locale où les agriculteurs mutualisent leurs moyens : le matériel, la main-d’œuvre, les ateliers, etc.
-
16:24
Global map of irrigated areas
sur Séries temporelles (CESBIO)It’s not easy to find a good cartographic representation of the global irrigated land, therefore I made my own map using data from Meier et al. (2018).
The raw resolution of the above product is 30 arcsec, i.e. 1 pixel covers about 1 km by 1 km at equator. Here, I aim to represent the entire world in a single picture of say 1000 pixels wide, which means that 1 pixel would span about 40 km of land at the equator. Therefore I need to aggregate the original data to a lower resolution. Many people don’t realize that cartographic software like QGIS or ArcGIS will do this resampling under the hood with a default anti-aliasing method that may not work well with the data to represent, as shown below:

I like to aggregate data with hexagon grids because « hexagons are the most circular-shaped polygon that can tessellate to form an evenly spaced grid « . Thanks to the MMQGIS plugin it’s easy to generate a shapefile of continuous hexagons covering the Meier et al. layer. Here I worked in the Equal Earth projection because it retains the relative size of areas. Hence I first resampled the Meier et al. layer to Equal Earth at 800 m resolution using the nearest neighbor method. Then, I used the zonal statistics tool in QGIS to compute the « count » of irrigated pixels in every hexagon. Finally I computed the percentage of irrigated area by hexagon using the $area function in the field calculator available from the attribute table menu (percent irrigated = 100*800*800* « _count » / $area).


Using the same method we can aggregate the data by country.

Countries with the highest percentage of irrigated land:
- Bangladesh (38%)
- India (28%)
- Pakistan (22%)
Countries with the largest irrigated area:
- India (876’000 km²)
- China (746’000 km²)
- USA (287’000 km²)
Reference: Meier, J., Zabel, F., and Mauser, W.: A global approach to estimate irrigated areas – a comparison between different data and statistics, Hydrol. Earth Syst. Sci., 22, 1119–1133, [https:] 2018.



-
Développement d'une passerelle Apidae vers Geotrek pour les itinéraires de randonnées
sur Makina CorpusGeotrek est aujourd'hui un logiciel de référence pour la gestion et la présentation d'activités de pleine nature sur un territoire.
-
14:20
Revue de presse du 28 juillet 2023
sur Geotribu Une GeoRDP à mettre dans la valise pour vos vacances ;)
Une GeoRDP à mettre dans la valise pour vos vacances ;) -
14:20
Revue de presse du 28 juillet 2023
sur GeotribuUne GeoRDP à mettre dans la valise pour vos vacances ;)
-
9:12
Le service civique pour renforcer la localisation de nos projets
sur CartONG (actualités)Depuis plusieurs années, CartONG propose des services civiques pour soutenir les activités de cartographie collaborative, notamment les mapathons. Cette année, CartONG a pour la première fois participé au dispositif de service civique de réciprocité. Une démarche qui s'avère être un véritable levier pour renforcer la localisation de nos projets tout en favorisant l'échange et le partage de connaissances. Découvrez comment cette collaboration nourrit notre travail au quotidien.
-
La formation Python éligible au CPF est enfin arrivée
sur Makina CorpusMakina Corpus propose un nouvelle formation Python éligible au CPF. Grâce à cette certification, cette formation peut être entièrement financée par votre compte Compte Personnel de Formation.
-
10:20
Obtenir la version de PROJ installée en Python
sur GeotribuMémo technique : comment récupérer la version de PROJ installée depuis un script Python, avec GDAL, PyProj ou le binaire proj. -
10:20
Obtenir la version de PROJ installée en Python
sur Geotribu Mémo technique : comment récupérer la version de PROJ installée depuis un script Python, avec GDAL, PyProj ou le binaire proj.
Mémo technique : comment récupérer la version de PROJ installée depuis un script Python, avec GDAL, PyProj ou le binaire proj.
-
0:00
As to why Life Technology and Technology Companies Use Virtual Data Rooms
sur Veille cartographieCet article As to why Life Technology and Technology Companies Use Virtual Data Rooms est apparu en premier sur Veille cartographique 2.0.
Many companies rely on electronic data rooms to store and promote critical and sensitive corporate documents. Although they can be used by any company seeking to protect proprietary information, life science and technology firms make up the heaviest users of VDRs. A virtual data room is known as a secure and easy-to-use device that simplifies […]
Cet article As to why Life Technology and Technology Companies Use Virtual Data Rooms est apparu en premier sur Veille cartographique 2.0.
-
16:42
An update on the use of CAMS 48r1
sur Séries temporelles (CESBIO)As announced in a previous post, the aerosol definition of the new 48r1 release of the CAMS auxiliary data has changed as compared to the former 47r1. At that time, we recommended to disable the use of CAMS data with MAJA before we adapt the code. Meanwhile, we have also tested the actual impact on the performance of the current version of MAJA, and found that reflectances estimates based on 48r1 are significantly closer to those with 47r1 than without using CAMS. Here are some more information.
To properly use the CAMS auxiliary data, MAJA relies on Look-up tables (LUT) computed with a radiative transfer model (RTM) to adequately account for aerosols optical properties, ie. their size distribution, their refractive index, and for the hydrophilic ones their growth factor along the relative humidity. With the latest CAMS release 48r1, the definition of Organic Matter species changed slightly, with a new Secondary Organic aerosol, and with new optical properties for Dust. To adapt and to test MAJA for such new definitions takes some time, but in the meantime one may ask : “What if I keep using my version of MAJA with the latest 48r1 CAMS data ?”. The short answer is “it’s pretty much as good”, but let’s have a look a little closer.
Using a CAMS 47r1 compliant version of MAJA (4.x) with 48r1 CAMS means :
- To keep downloading the Atmospheric Optical Depth (AOD) of the 7 previous species, without the new Secondary Organic Aerosol variables ;
- To keep using the 7-species LUT definitions.
From a technical point of view, it works seamlessly, since the IDs of the CAMS variables did not changed. Therefore, we performed a few runs of MAJA (version 4.6 here) using the 48r1 test data for the month of April 2023 on the tiles of La Crau (31TFJ), Gobabeb (33KWP) and Milan (32TNR), with each 12 L1C products. The same products were then computed with the 47r1 CAMS products, and without any CAMS data.
The following comparisons were performed on the surface reflectances of valid pixels (cloud-free, shadow-free, snow-free) between :
- 47r1-based reflectances against 48r1-based ones ;
- 47r1-based reflectances against “no CAMS data”-based ones.
The Figure below synthesises the obtained Root Mean Square Errors (RMSE) for Sentinel-2 bands 2, 3, 4 and 8, stacked for all valid pixels of all the L2A products of all sites.

What stands out of this Figure is that the surface reflectances obtained using the 48r1 CAMS data are significantly closer to the ones using the 47r1 CAMS data than those resulting from deactivating the CAMS option, whatever the band under consideration.
How can it be so ?
- The overall occurrence of Organic Matter in the aerosol mix may limit the impact of a change of its definition (in terms of optical properties and sub-species partitioning) ;
- The new optical properties of Dust are actually very close from the ones we used until now.
While the first point is an hypothesis than needs further investigation, the second is clearly documented. At the time of the implementation of the use of CAMS in MAJA, our former colleague B. Rouquié demonstrated that the use of the refractive index values for Dust from Woodward [1] lead to better estimates of the AOD than the values used by CAMS. The comparison was published in [2] and summarized in the following table:

Therefore, the MAJA Look-up Tables for Dust were computed using the Woodward refractive index. And the new Dust refractive index used in the CAMS 48r1 (1.53-0.0057 at 500nm) [3] is actually very close from the one we used in MAJA until now.
If we compare the AOD at 550nm computed by MAJA with the values measured at the ROSAS station of Gobabeb [4], we obtain the following :
MAJA configuration
RMSE on AOD no CAMS 0.021 47r1 CAMS 0.054 48r1 CAMS 0.014 Table 1 : Root Mean Square Errors (RMSE) of the estimates of the Atmospheric Optical Depth (AOD) at 550nm using the in-situ ROSAS station of Gobabeb (Namibia) operated by the CNES [4]. The corresponding reference measurements of the La Crau ROSAS station are not yet available at the time of writing.
It’s worth keeping in mind that these later RMSEs on AOD are computed from only 11 values (the AOD value of the MAJA L2A product is taken at the location of the ROSAS station in each of the 11 cloud-free products). But it still tends to confirm that the existing Look-up Table for Dust is well suited to the latest CAMS products.
To conclude :
- The presented results are based on a short period of time where the CAMS 47r1 and 48r1 product overlap, and for a limited number of locations. We will further refine the analysis once we accumulate in-situ AERONET and ROSAS data and increase the number of locations ;
- MAJA will anyway be adapted to the new aerosols definitions in a future release expected by the end of September ;
- This first analysis suggest than it’s worth using the 48r1 CAMS auxiliary data rather than deactivating the CAMS option with the current version of MAJA. Therefore, we reconsider our former recommendation to deactivate the use of CAMS ;
References :
[1] Woodward, S. Modeling the atmospheric life cycle and radiative impact of mineral dust in the Hadley Centre climate model. J. Geophys. Res. 2001, 106, 18155–18166.
[2] B. Rouquié, O. Hagolle, F.-M. Bréon, O. Boucher, C. Desjardins, and S. Rémy, ‘Using Copernicus Atmosphere Monitoring Service Products to Constrain the Aerosol Type in the Atmospheric Correction Processor MAJA’, Remote Sensing, vol. 9, no. 12, p. 1230, Dec. 2017, doi: 10.3390/rs9121230.
[3] IFS Documentation CY48R1 – Part VIII: Atmospheric Composition, ECMWF, DOI: [https:]]
[4] S. Marcq et al., ‘New Radcalnet Site at Gobabeb, Namibia: Installation of the Instrumentation and First Satellite Calibration Results’, in IGARSS 2018 – 2018 IEEE International Geoscience and Remote Sensing Symposium, Jul. 2018, pp. 6444–6447. doi: 10.1109/IGARSS.2018.8517716.
-
CANARI Europe, un service climatique innovant pour adapter l'agriculture européenne
sur Makina CorpusAprès un lancement réussi de CANARI l'application de projections climatiques dédiée à l'agriculture en France, CANARI s’étend à toute L’Europe et au nord du M
-
0:00
What sort of Boardroom Software Can Improve your Meetings
sur Veille cartographieCet article What sort of Boardroom Software Can Improve your Meetings est apparu en premier sur Veille cartographique 2.0.
Whether you happen to be looking for a boardroom table or possibly a room to hold an exec meeting, the right space will make all the difference. The best boardrooms are well-equipped with large display screen televisions and other presentation products, as well as Bloomberg terminals or perhaps other state of the art quotation devices […]
Cet article What sort of Boardroom Software Can Improve your Meetings est apparu en premier sur Veille cartographique 2.0.
-
0:00
Where to get the Best Info Room Installer
sur Veille cartographieCet article Where to get the Best Info Room Installer est apparu en premier sur Veille cartographique 2.0.
When searching for the best data space provider, it is best to pay attention to the consumer feedback about renowned assessment platforms. Choose a vendor having a high consumer rating, as this is a sign of reliability as well as the ability to focus on the clientele. Check as well what alternative the vendor provides […]
Cet article Where to get the Best Info Room Installer est apparu en premier sur Veille cartographique 2.0.
-
0:00
Powerful Corporate Governance Software
sur Veille cartographieCet article Powerful Corporate Governance Software est apparu en premier sur Veille cartographique 2.0.
Effective company governance application enables stakeholders and personnel www.boardroomplace.info/how-to-continue-work-with-data-room-for-real-estate to collaborate, discuss information, and monitor organization processes. This may also provide a protected, centralized platform for stroage and handling corporate governance documents, including charters, rules, bylaws, get together minutes, and regulatory filings. In addition , these kinds of systems often offer features that let stakeholders […]
Cet article Powerful Corporate Governance Software est apparu en premier sur Veille cartographique 2.0.
-
0:00
Malwarebytes Web Coverage Review
sur Veille cartographieCet article Malwarebytes Web Coverage Review est apparu en premier sur Veille cartographique 2.0.
Malwarebytes shields you against all types of threats. These types of threats try to invade your device and steal info, or even seize control for the device’s surgical treatments. They www.techentricks.net/data-room-and-how-to-use-it can also destruction or demolish your documents and systems. They are also very stealthy, because they may cover inside files and courses. Thankfully, malwarebytes […]
Cet article Malwarebytes Web Coverage Review est apparu en premier sur Veille cartographique 2.0.
-
10:17
vulkan vegas 651 581
sur Veille cartographieCet article vulkan vegas 651 581 est apparu en premier sur Veille cartographique 2.0.
Równie? w tym przypadku nie stosuje si? op?at transakcyjnych ani prowizji. Czas realizacji przelewu zale?y od operatora, jednak nie mo?e trwa? d?u?ej ni? 24 godziny, ewentualnie 3 dni robocze. Obiecujemy zapewni? naszym klientom najwy?szej jako?ci obs?ug? klienta i z tego powodu jeste?my dost?pni 24/7, aby odpowiedzie? na wszelkie pytania i problemy. Istnieje wiele sposobów, aby […]
Cet article vulkan vegas 651 581 est apparu en premier sur Veille cartographique 2.0.
-
10:17
Vulkan Vegas kod promocyjny ? do 30% 6 Aktywnych Lipiec 2023
sur Veille cartographieCet article Vulkan Vegas kod promocyjny ? do 30% 6 Aktywnych Lipiec 2023 est apparu en premier sur Veille cartographique 2.0.
Tak, strona internetowa kasyna jest dost?pna w j?zyku polskim – podobnie, jak i pomoc konsultantów na czacie online. Na HotDeals.com oferowane s? ró?ne rabaty dla ró?nych grup osób. Kody rabatowe Vulkan Vegas przyci?gaj? uwag? ka?dego. Nie przegap okazji do skorzystania z kodów Kod Rabatowy Vulkan Vegas 40, które automatycznie zostan? zastosowane przy p?atno?ci za produkty […]
Cet article Vulkan Vegas kod promocyjny ? do 30% 6 Aktywnych Lipiec 2023 est apparu en premier sur Veille cartographique 2.0.
-
10:17
Graj w kasyno za darmo lub na pieni?dze
sur Veille cartographieCet article Graj w kasyno za darmo lub na pieni?dze est apparu en premier sur Veille cartographique 2.0.
Polecamy te? zwróci? uwag? na pole „Mam kod promocyjny”, które znajduje si? na dole formularza rejestracyjnego. Warto je zaznaczy?, je?li ma si? taki specjalny Vulkan Vegas kod promocyjny aktywuj?cy dodatkowe bonusy. W ten sposób ka?dy u?ytkownik kasyna ma dost?p do pe?ni mo?liwo?ci naszego serwisu i to z dowolnego miejsca z dost?pem do sieci. Wystarczy wyj?? […]
Cet article Graj w kasyno za darmo lub na pieni?dze est apparu en premier sur Veille cartographique 2.0.
-
0:00
Exactly what are Virtual Info Rooms?
sur Veille cartographieCet article Exactly what are Virtual Info Rooms? est apparu en premier sur Veille cartographique 2.0.
A online data room is a secure online repository that supports the secure sharing of critical paperwork and documents with multiple parties concurrently. These are generally applied during M & A, loan syndications, licensing and equity bargains, where firms share data that is private or that might be damaging to them or perhaps their consumers […]
Cet article Exactly what are Virtual Info Rooms? est apparu en premier sur Veille cartographique 2.0.
-
0:00
Selecting the best Virtual Data Room Service provider
sur Veille cartographieCet article Selecting the best Virtual Data Room Service provider est apparu en premier sur Veille cartographique 2.0.
A virtual data space is a protect online platform where multiple parties may upload, conserve and deal with files and files. Typically accustomed to streamline and accelerate homework, www.dataroomzone.info/top-7-tips-for-working-with-virtual-file-cabinet/ M&A and other transaction-related processes, these platforms provide users web-site and get easily promote and gain access to information via anywhere, whenever they want. While many […]
Cet article Selecting the best Virtual Data Room Service provider est apparu en premier sur Veille cartographique 2.0.
-
16:54
Impact du changement climatique sur le niveau des nappes d'eau souterraines en 2100
sur Cartographies numériques
Source : Impact du changement climatique sur le niveau des nappes d'eau souterraines en 2100 (CNRS, 13 juillet 2023).
Seules 30 % des réserves d’eau douce de la planète sont accessibles, les 70 % restant sont sous forme de glace dans les glaciers. Cette eau douce exploitable est principalement constituée d’eaux souterraines contenues dans les aquifères (29 %), loin devant les eaux de surfaces (1 %) formant les rivières, les lacs, ou les zones humides. Comprendre l’impact du changement climatique à venir sur les eaux souterraines est donc essentiel pour améliorer les plans d'adaptation de la gestion de la ressource en eau à l’échelle mondiale.Dans une nouvelle étude réalisée dans un laboratoire rattaché au CNRS-INSU, une équipe de scientifiques a analysé, selon l'évolution climatique à l’horizon 2100, l’évolution du niveau des nappes souterraines dans les 218 principaux bassins aquifères non-confinés du monde, en suivant les derniers scénarios de changement climatique utilisés par le GIEC. Cette étude a été réalisée avec les deux modèles de climat du CNRM (CNRM-CM6-1 et CNRM-ESM2-1), capables de représenter les rétroactions entre le climat, le changement d’utilisation des terres et les processus liés aux eaux souterraines, mais pas les prélèvements anthropiques. Selon le scénario considéré, ces modèles simulent une hausse du niveau des nappes d’eau souterraines à la fin du 21ème siècle sur 33 % à 42 % des régions couvertes par les principaux bassins aquifères du monde, et une baisse du niveau de ces nappes sur 26 % à 37 % de ces régions. Ces estimations sont ensuite croisées avec des projections de densité de population afin de tenir compte des possibles effets liés aux prélèvements d’eau par les activités humaines.
L’équipe estime alors que 31 % à 43 % de la population mondiale en 2100 pourrait être affectée par ces modifications du niveau des nappes. La majorité (29 % à 40 % de la population mondiale), serait alors plus fréquemment confrontée à des problèmes de pénurie d'eau, liés à l’évolution du climat et/ou de la consommation d’eau par les activités humaines, alors que seulement 1,7 % à 2,2 % de la population mondiale verrait sa ressource en eau augmenter, entrainant un risque accru d’inondations.
Changements simulés de la profondeur des nappes d’eau souterraines (en %) entre la période historique (1985-2014) et la fin du 21ème siècle (2071-2100) - Source : Costantini & al., 2023
Légende
Changements simulés de la profondeur des nappes d’eau souterraines (en %) entre la période historique (1985-2014) et la fin du 21ème siècle (2071-2100) dans le scénario SSP370 mis en place pour le 6e rapport du GIEC. Les régions bleues et rouges correspondent à une hausse ou une baisse du niveau des nappes, respectivement. Les régions blanches correspondent aux zones où les changements simulés ne sont pas statistiquement significatifs à un niveau de confiance de 95 %. Ces estimations ne prennent en compte que les facteurs climatiques, l’impact des prélèvements anthropiques sont discutés dans l’étude.
Pour en savoir plus
Costantini, M., Colin, J., & Decharme, B. (2023). Projected climate-driven changes of water table depth in the world's major groundwater basins. Earth's Future, 11, e2022EF003068.
L'évaporation des lacs dans le monde : une tendance à la hausse
Articles connexes
Rapport mondial des Nations Unies 2019 sur la mise en valeur des ressources en eau
Etudier les risques de pénurie d'eau dans le monde avec l'Atlas Aqueduct du WRI
Rapport 2021 du Giec : le changement climatique actuel est « sans précédent »
La France est-elle préparée aux dérèglements climatiques à l'horizon 2050 ?
Aborder la question de l'inégalité des pays face au changement climatique
Les barrages vieillissants constituent une menace croissante dans le monde (rapport de l'ONU)
Conflits liés à l'eau : les prévisions du site Water, Peace and Security
Un jeu de données SIG sur les fleuves qui servent de frontières dans le monde
-
8:07
Cet article est apparu en ...
sur Veille cartographieCet article est apparu en premier sur Veille cartographique 2.0.
Content Sonuç Mostbet Tr Durante I?yi Bahis Siteleri ®? Mostbet Kay?t Ol Mostbet Casino Mostbet Para Yat?rma Sorunu Mostbet I?ncelemesi Mostbet Casino Pra Yat?rma S?k?nt?s? Mostbet Kumarhanesi Mostbet ? Bahisçi Türkiye, Giri?, 2500 Lira Seviyesine Bonus Empieza Mobil Uygulama Mostbet Casino Mostbet De?il Alternativ Keçid Vasit?si Il? – 1win Giri? Mostbet Türkiye Bahisçi Ofisinde Kay?t: […]
Cet article est apparu en premier sur Veille cartographique 2.0.
-
15:58
Codere casino » opiniones y experiencia
sur Veille cartographieCet article Codere casino » opiniones y experiencia est apparu en premier sur Veille cartographique 2.0.
Content This website uses cookies Codere Casino Review – Initial Impressions What live casino games does Codere offer? Is This Online Casino Safe? COMO REGISTRARSE EN CODERE CASINO Software & Games Codere Casino: Overview of the Most Important Areas CODERE CASINO: INTRODUCCIÓN Where is Codere Casino available? RANKING DE CODERE CASINO Y NUESTRAS OPINIONES PROVEEDORES […]
Cet article Codere casino » opiniones y experiencia est apparu en premier sur Veille cartographique 2.0.
-
15:58
Trabajar en CODERE
sur Veille cartographieCet article Trabajar en CODERE est apparu en premier sur Veille cartographique 2.0.
Content Codere Webs del grupo ¿Cómo es trabajar en CODERE? Top Empresas Qué hay que hacer para trabajar en Codere Ayúdanos a proteger Glassdoor ÚNETE A CODERE Acerca de CODERE opiniones sobre Codere Últimas ofertas de empleo de Codere NUESTRO EQUIPO Descripción de la empresa Otras empresas del sector Empresas populares por sector CODERE cuenta […]
Cet article Trabajar en CODERE est apparu en premier sur Veille cartographique 2.0.
-
15:58
Codere, casa de apuestas oficial del Real Madrid por cinco temporadas Deporte y Negocio
sur Veille cartographieCet article Codere, casa de apuestas oficial del Real Madrid por cinco temporadas Deporte y Negocio est apparu en premier sur Veille cartographique 2.0.
Content ¿Qué premio recibirán los campeones de la Copa Codere 2023? El laboratorio de la nueva narrativa del fútbol Información relevante para hacer tu pronóstico sobre el partido Eldense vs Real Madrid Castilla Apuestas Eldense vs Real Madrid Castilla: pronóstico Ascenso a Segunda Pronóstico Eldense vs Real Madrid Castilla: apuestas y las mejores cuotas REAL […]
Cet article Codere, casa de apuestas oficial del Real Madrid por cinco temporadas Deporte y Negocio est apparu en premier sur Veille cartographique 2.0.
-
15:33
Onlayn Rulet oyna Pulsuz v? ya real pul il? Roulette77 Azerbaijan
sur Veille cartographieCet article Onlayn Rulet oyna Pulsuz v? ya real pul il? Roulette77 Azerbaijan est apparu en premier sur Veille cartographique 2.0.
Content Mostbet Affiliate program, betting on sports and esports ?????????? ???????? ??????? ??? ????????? Sportbet Mostbet ??????? ?????????? ???????? ????? Xo? G?lmisiniz Bonusu Mostbet az bu gün üçün i?l?y?n güzgül?r Posts in Mostbet Casino Mostbet promo kod ? Bonuslar? v? Promo-Aksiyalar Mostbet casino AZ Bonus endirimler MostBet Partners Affiliate Program Review 2023 Upto 60% Revshare […]
Cet article Onlayn Rulet oyna Pulsuz v? ya real pul il? Roulette77 Azerbaijan est apparu en premier sur Veille cartographique 2.0.
-
15:33
Azeri bukmeker saytlari: onlayn m?rc saytlar? Az?rbaycanda
sur Veille cartographieCet article Azeri bukmeker saytlari: onlayn m?rc saytlar? Az?rbaycanda est apparu en premier sur Veille cartographique 2.0.
Content Az?rbaycanda mehmanxanalar 90 milyon manata yax?n g?lir ?ld? edib in aviator oyununda nec? qalib g?lm?k olar? Gamers Can Place Wagers On Esports eManat il? Az?rbaycanda qumar biznesinin inki?af? in sistemind? nec? qeydiyyatdan keçm?k olar Çempionlar Liqas?nda ?n çox oyun keçir?n oyunçular Üst bukmeker saytlari üzr? seçim ed?rk?n ?sas laz?m olanlar Az?rbaycanda Yar??da kim qalacaq: […]
Cet article Azeri bukmeker saytlari: onlayn m?rc saytlar? Az?rbaycanda est apparu en premier sur Veille cartographique 2.0.
-
15:33
T?yyar? Oyunu Mostbet Mostbet Aviator game
sur Veille cartographieCet article T?yyar? Oyunu Mostbet Mostbet Aviator game est apparu en premier sur Veille cartographique 2.0.
Content ?randan qay?qlarla Az?rbaycana narkotik g?tir?n müt???kkil d?st? üzvl?ri saxlan?l?b MostBet-? nec? daxil olmaq olar? Mobil telefon istifad?çil?ri üçün t?tbiql?r « ??-??bab »?n liderl?rind?n biri Somalid? hücum n?tic?sind? yaralan?b MostBet Az?rbaycan bukmeker kontoru haqq?nda ümumi bax??-icmal MostBet sayt?nda nec? qeydiyyatdan keçm?k olar? iOS t?tbiq v? yükl?nilm?si What are the Peculiarities of the Mostbet Partnership? ?sveçr? Milli Xokkey […]
Cet article T?yyar? Oyunu Mostbet Mostbet Aviator game est apparu en premier sur Veille cartographique 2.0.
-
12:08
Pin-Up Casino kontorunun t?sviri, pin up az
sur Veille cartographieCet article Pin-Up Casino kontorunun t?sviri, pin up az est apparu en premier sur Veille cartographique 2.0.
Content Pin Up bukmeker kontorunda idman m?rcl?ri haqq?nda r?yl?r ?n yax?? slot ma??nlar? Pin-Up bet r?smi bukmeyker ?irk?ti Promo kodu nec? ?ld? etm?k olar ? Pin-Up kazinosunun r?smi sayt?, idmana nec? m?rc etm?k olar Pin Up r?yl?rind? n? faydal?d?r? cü ild? Pin Up kazino cari bonus R?smi sayt Pin Up ?dmana hans? valyutada m?rc ed? […]
Cet article Pin-Up Casino kontorunun t?sviri, pin up az est apparu en premier sur Veille cartographique 2.0.
-
12:07
Pin Up yükl? Android cihazlar? üçün Pin Up bet indir
sur Veille cartographieCet article Pin Up yükl? Android cihazlar? üçün Pin Up bet indir est apparu en premier sur Veille cartographique 2.0.
Content Pin Up Bet t?tbiqind? idman m?rcl?ri Pin Up-da oyunçu r?yl?ri Pin Up Casino-da Oyunlar v? Slotlar Pin Up Yükl? – Android t?tbiqi ? Pin Up Bet t?tbiqini Android-? yükl?m?k üçün minimum t?l?bl?r hans?lard?r? Casino Pin Up Azerbaycan Pin Up Casino yukle nu Android-d? nec? olar ? Pin Up Bet t?tbiqini cihaz?n?za yükl?m?k t?hlük?sizdirmi? ? […]
Cet article Pin Up yükl? Android cihazlar? üçün Pin Up bet indir est apparu en premier sur Veille cartographique 2.0.
-
12:06
Pin-Up bet r?smi bukmeyker ?irk?ti
sur Veille cartographieCet article Pin-Up bet r?smi bukmeyker ?irk?ti est apparu en premier sur Veille cartographique 2.0.
Content Pin up Casino Az?rbaycan r?smi sayt?. Pin-up bet bahis bukmeyker icmal? Pin Up casino slot ma??n? – pulla v? ya pulsuz oynay?n R?smi sayt Pin Up ??xsi hesab Kazino proqram?nda bukmeker Müsb?t v? m?nfi c?h?tl?ri Pin-Up Bet ??xsi kabinetin? qeydiyyat v? giri? Android üçün kazino v? proqram?n mobil versiyas? Pin Up bukmeker kontorunda idman […]
Cet article Pin-Up bet r?smi bukmeyker ?irk?ti est apparu en premier sur Veille cartographique 2.0.
-
16:56
Ces pays qui bloquent les réseaux sociaux (Statista)
sur Cartographies numériques
En réponse aux violences urbaines qui ont enflammé les banlieues françaises fin juin 2023, le président Emmanuel Macron a évoqué de potentielles mesures visant à bloquer l'accès aux réseaux sociaux en cas d'épisode de crise dans le pays. Ce genre de mesures, si elles venaient à être mises en place, constitueraient une première au sein des démocraties occidentales.
Source : « Ces pays qui bloquent les réseaux sociaux » par Tristan Gaudiaut (Statista, 10 juillet 2023).Depuis 2015, 62 pays ont bloqué l'accès à des réseaux sociaux ou des applications de messagerie selon une étude de Surfshark. Ces restrictions sont principalement le fait de gouvernements non démocratiques. Si l'on comptabilise les coupures et autres restrictions d'accès à Internet, ce chiffre grimpe à 77. C'est ce qui ressort d'une étude couvrant 196 pays réalisée par la société Surfshark, spécialisée dans la protection de la vie privée et la sécurité des données en ligne.
Ces restrictions sont principalement le fait de gouvernements non démocratiques. Comme le montre notre carte, la grande majorité des pays ayant bloqué l'accès à des réseaux sociaux ou messageries ces dernières années sont situés en Afrique et en Asie. Dans la plupart des cas, les restrictions sont temporaires et visent à limiter ou contrôler les flux d'informations lors de troubles et d'événements politiques (élections, manifestations, guerres, conflits, coups d'État, etc.). Parmi les cas les plus récents, on peut citer le Sénégal, où des coupures de plusieurs plateformes, dont Facebook, Twitter, Instagram, WhatsApp et Telegram, ont été rapportées le mois dernier lors des protestations contre la condamnation du leader de l'opposition Ousmane Sonko. L'accès à depuis été rétabli.
Selon Surfshark, des restrictions sont toujours en vigueur dans une vingtaine de pays (au 4 juillet 2023). En Chine, en Russie, en Corée du Nord, en Iran, au Myanmar et au Turkménistan, ce sont principalement les réseaux sociaux étrangers qui ont été bannis par les autorités, comme Twitter, Facebook et Instagram. Il convient de noter que la Chine a en parallèle développé son propre écosystème national d'applications, avec par exemple WeChat, Weibo et QQ. Quant aux pays de la péninsule Arabique - Émirats arabes unis, Qatar, Oman, Yemen - ils restreignent l'utilisation de WhatsApp, Telegram et plus généralement des appels passés via Internet (voix sur IP).
Source : « Ces pays qui bloquent les réseaux sociaux » (Statista, Licence Creative Commons CC BY-ND 3.0)

Pour compléter
La France pourrait-elle couper les réseaux sociaux ? Comprendre en trois minutes (Le Monde).
Violences après la mort de Nahel : pourquoi interdire les réseaux sociaux est une mauvaise idée (France 3)
Répression d'internet : la carte des coupures politiques (France Culture)
La cartographie d’une semaine d’émeutes en France (Le Monde - Les décodeurs)
La crise contre le mouvement : comprendre les émeutes en France (Le Grand Continent)
Les émeutes françaises montrent à quel point les inégalités sont enracinées (Financial Times)
Articles connexes
Mesurer la liberté de la presse dans le monde en 2022. Reporters Sans Frontières modifie sa méthodologie
La liberté de la presse dans le monde selon Reporters sans frontières
Cartographie des journalistes tués ou emprisonnés dans le monde
Carte de l'indice de perception de la corruption (Transparency International)
L'indice de perception de la démocratie selon Dalia Research
Géographies de l'exclusion numérique par Mark Graham et Martin Dittus
Quand Facebook révèle nos liens de proximité
Cartographie du réseau social Mastodon
-
16:49
Appel à communications pour la 30e conférence internationale en histoire de la cartographie (ICHC), Lyon 1-5 juillet 2024
sur Cartes et figures du mondeVous trouverez ci-dessous l’appel à communications pour la 30e ICHC qui se tiendra à Lyon l’année prochaine du 1er au 5 juillet 2024, avec une pré-conférence à Paris le 29 juin.
Toute personne (chercheur confirmé, doctorant, conservateur, etc.) effectuant des recherches sur les cartes en tant qu’objet d’étude est invitée à y répondre.L’appel est bilingue, mais les réponses sont attendues en anglais et les communications seront, elles-aussi, présentées en anglais.
Pour soumettre une proposition de communications, se connecter à : [https:]
L’appel est ouvert du 1er septembre au 20 novembre 2023.Vous trouverez le calendrier de la conférence ici : [https:]
 Confluences
Interdisciplinarity and New Challenges in the History of Cartography
Confluences
Interdisciplinarity and New Challenges in the History of Cartography
1-5 July 2024 – Université de Lyon – France
The ICHC is the only academic conference solely dedicated to advancing knowledge of the history of maps and mapmaking, regardless of geographical region, language, period or topic. The conference promotes free and unfettered global cooperation and collaboration among cartographic scholars from many academic disciplines, curators, collectors, dealers and institutions through illustrated lectures, presentations, exhibitions, and a social program. In order to expand awareness of issues and resources, each conference is sponsored by a leading educational and cultural institution. Conferences are held biannually and are administered by local organizers in conjunction with Imago Mundi Ltd. In 2024, the University of Lyon welcomes the conference with the support of the research unit UMR 5600 – EVS (Environment, City, Society).
The 30th ICHC will take the opportunity to present the following themes:
- Mapping travels, voyage and encounters in cartography
Encompasses the production of maps to help travellers and tourists meet their goals, organize accommodation and transportation, and the way territories are highlighted.
- Maps and networks – Uses, exchanges and circulation of maps
Explores the interrelations between map producers, bearing in mind diffusion of new fields of interest, new uses, the introduction of new techniques and sharing networks
- Mapping nature, wilderness and agriculture
Aims at a new understanding of how spaces of nature, wilderness and agriculture were dealt with, including vegetation, mountains, water expanses, agricultural productions, city surroundings, and natural hazards.
- The development of urban planning and cartography
Planning implies or supposes a precise knowledge of the topographic reality, which led to improvements in cartography, both in measuring techniques and conceptualization, and recently to the introduction of digital mapping
- New perspectives on the digital transition
Investigates the way dematerialization introduces new issues: breaking down in vector layers to put together and organize for new uses, new relationships between data and graphic expression, big data, conservation (or discarding) of historical/outdated data and digital maps.
- Any other aspects of the history of cartography.
The call for papers proposes 4 types of interventions:
- Oral communication: 15 to 20 minutes presentation on a research in progress
- Posters: presentation dedicated to showing an analysis of visual devices accompanied by short texts
- Workshops: possibilities to integrate a technical demonstration of the possibilities of analysis associated with the history of cartography
- Thematic session: proposal for an oral paper session (abstracts of individual papers to be provided to the scientific committee)
The official language of the conference will be English, and all presentations must be in that language. There will be no simultaneous translation.
Important dates: call for papers from 01/09/2023 to 20/11/2023
Scientific Committee response: January 2024
Registration for participants – Feb/April 2024: early bird / May/July 2024: full prices
Confluences Interdisciplinarité et nouveaux défis dans l’histoire de la cartographie1-5 juillet 2024 – Lyon – France
L’ICHC est la seule conférence universitaire entièrement consacrée à l’avancement des connaissances sur l’histoire des cartes et de la cartographie, indépendamment de la région géographique, de la langue, de la période ou du sujet. La conférence encourage la coopération et la collaboration libres et sans entraves entre les spécialistes de la cartographie de nombreuses disciplines universitaires, les conservateurs, les collectionneurs, les marchands et les institutions par le biais de conférences illustrées, de présentations, d’expositions et d’un programme social. Afin de mieux faire connaître les enjeux et les ressources, chaque conférence est parrainée par une institution éducative et culturelle de premier plan.
Les conférences ont lieu tous les deux ans et sont gérées par des organisateurs locaux en collaboration avec Imago Mundi Ltd. En 2024, l’Université de Lyon accueille la conférence avec le soutien de l’unité de recherche UMR 5600 – EVS (Environnement, Ville, Société).
La 30e édition de l’ICHC sera l’occasion de présenter les thèmes suivants :
- Cartographie des déplacements, voyages et rencontres en cartographie.
Englobe la production de cartes pour aider les voyageurs et les touristes à atteindre leurs objectifs, à organiser l’hébergement et le transport, et la manière dont les territoires sont mis en valeur.
- Cartes et réseaux – Utilisation, échange et circulation des cartes
Explore les interrelations entre les producteurs de cartes, en tenant compte de la diffusion de nouveaux champs d’intérêt, de nouvelles utilisations, de l’introduction de nouvelles techniques et des réseaux de partage.
- Cartographie de la nature, des espaces sauvages et de l’agriculture
Vise une nouvelle compréhension de la manière dont les espaces naturels, sauvages et agricoles ont été traités, y compris la végétation, les montagnes, les étendues d’eau, les productions agricoles, les environs des villes et les risques naturels.
- Le développement de l’urbanisme et de la cartographie
La planification implique ou suppose une connaissance précise de la réalité topographique, ce qui a conduit à des améliorations de la cartographie, tant au niveau des techniques de mesure que de la conceptualisation, et récemment à l’introduction de la cartographie numérique.
- Nouvelles perspectives sur la transition numérique
Étudie la manière dont la dématérialisation introduit de nouvelles problématiques : décomposition en couches vectorielles à assembler et organiser pour de nouveaux usages, nouveaux rapports entre données et expression graphique, big data, conservation (ou mise au rebut) des données historiques/anciennes et des cartes numériques.
Et tout autre aspect de l’histoire de la cartographie.
L’appel à communications propose 4 types d’interventions :
- Communication orale : présentation de 15 à 20 minutes sur une recherche en cours
- Posters : présentation dédiée à montrer une analyse de dispositifs visuels accompagnées de textes succincts
- Ateliers/Workshops : possibilités d’intégrer une démonstration technique des possibilités d’analyse associées à l’histoire de la cartographie
- Session thématique : proposition d’une séance de communications orales (les résumés des différentes interventions doivent être communiqués au comité scientifique)
Dates importantes : appel à communications/ateliers/posters – du 01/09/2023 au 20/11/2023

-
OpenIG : Webinaire GeoRivière le replay
sur Makina CorpusVisualisez le replay du webinaire OpenIG sur l'application de suivi et de gestion des cours d'eau GeoRivière. Découvrez la présentation et le compte-rendu de l'événement.
-
10:30
Créer ses propres palettes de couleurs avec Dicopal
sur Cartographies numériques
Dicopal est une bibliothèque JavaScript qui fournit des centaines de palettes de couleurs. Elle est basée sur Colorbrewer2, CARTOColors, cmocean, Matplotlib, MyCarta, Tableau et bien d'autres palettes. Nicolas Lambert a intégré Dicopal dans Observable et montre comment l'utiliser pour l'appliquer à des cartes. Même sans passer par Observable, il est possible de récupérer les codes couleurs de ces palettes et de les utiliser dans d'autres applications cartographiques.I) Découvrir Dicopal.js
Dicopal (Discrete color palettes) est une bibliothèque javascript qui intègre de nombreuses palettes de couleurs :
- Colorbrewer2
- Fabio Crameri's Scientific Colour Maps
- CARTOColors
- cmocean
- Light & Bartlein
- Matplotlib
- MyCarta
- Tableau
- The Wes Anderson Palettes blog
- Masataka Okabe and Kei Ito's Color Universal Design (CUD) palette
2) Combiner Dicopal.js et Bertin.js
Nicolas Lambert montre sur la plateforme Observable comment combiner les bibliothèques javascript Dicopal.js et Bertin.js. L'application interactive est très pratique : elle permet de jouer à la fois sur le choix de palette et le nombre de couleurs. Le rendu s'affiche directement sur la carte :
Outre la discrétisation, Dicopal peut être utilisé également pour créer des typologies avec des couleurs contrastées :
3) Récupérer les codes couleurs de DicopalNicolas Lambert donne la possibilité de copier directement les codes html des palettes que l'on a choisies.
Articles connexes
Utiliser l'application Observable pour créer ses propres visualisations de données
Reproduire des cartes et des graphiques à la manière de Jacques Bertin
Pas de stocks en aplat ni de taux en symboles proportionnels !
Quand les couleurs révèlent le contenu et la matérialité des cartes
Quand la couleur rencontre la carte (catalogue d'exposition à télécharger)
Cartographie des noms qui servent à désigner les couleurs en Europe (Mapologies)Donnez-moi la couleur de votre passeport, je vous dirai où vous avez le droit d'aller (Neocarto)
Les nouvelles façons de « faire mentir les cartes » à l’ère numérique
La cartographie du monde musulman et ses nombreux "map fails"

{kind=link}
{kind=link}
-
12:31
Save the Date - Cloned
sur Datafoncier, données pour les territoires (Cerema)Publié le 07 juillet 2023Organisée par la DGALN et le Cerema, cette journée a pour ambition de favoriser les échanges, de partager plus largement encore les pratiques approfondies des données et d’en multiplier les usages. Elle est l’occasion de rassembler les divers utilisateurs des données foncières (Fichiers fonciers, DV3F, Lovac et RFP), qu’ils soient confirmés ou novices, autour des pratiques et leurs usages. C’est votre communauté d’utilisateurs qui fait vivre les données foncières, et les journées nationales constituent des moments privilégiés qui nous permettent de progresser (…)
Lire la suite -
12:31
Save the Date
sur Datafoncier, données pour les territoires (Cerema)Publié le 07 juillet 2023Organisée par la DGALN et le Cerema, cette journée a pour ambition de favoriser les échanges, de partager plus largement encore les pratiques approfondies des données et d’en multiplier les usages. Elle est l’occasion de rassembler les divers utilisateurs des données foncières (Fichiers fonciers, DV3F, Lovac et RFP), qu’ils soient confirmés ou novices, autour des pratiques et leurs usages. C’est votre communauté d’utilisateurs qui fait vivre les données foncières, et les journées nationales constituent des moments privilégiés qui nous permettent de progresser (…)
Lire la suite