
Vous pouvez lire le billet sur le blog La Minute pour plus d'informations sur les RSS !
Canaux
5547 éléments (208 non lus) dans 55 canaux
 Dans la presse
(49 non lus)
Dans la presse
(49 non lus)
-
 Cybergeo
(10 non lus)
Cybergeo
(10 non lus) -
Revue Internationale de Géomatique (RIG)
-
SIGMAG & SIGTV.FR - Un autre regard sur la géomatique
(4 non lus)
-
Mappemonde
(20 non lus)
-
Dans les algorithmes
(15 non lus)
Du côté des éditeurs
(14 non lus)
-
Imagerie Géospatiale
-
Toute l’actualité des Geoservices de l'IGN
(10 non lus)
-
arcOrama, un blog sur les SIG, ceux d ESRI en particulier (4 non lus)
-
arcOpole - Actualités du Programme
-
Géoclip, le générateur d'observatoires cartographiques
-
Blog GEOCONCEPT FR
Toile géomatique francophone
(145 non lus)
-
Géoblogs (GeoRezo.net)
-
Conseil national de l'information géolocalisée
(91 non lus)
-
 Geotribu
(3 non lus)
Geotribu
(3 non lus) -
Les cafés géographiques
(3 non lus)
-
UrbaLine (le blog d'Aline sur l'urba, la géomatique, et l'habitat)
-
Icem7
-
Séries temporelles (CESBIO)
-
Datafoncier, données pour les territoires (Cerema)
(5 non lus)
-
Cartes et figures du monde
(15 non lus)
-
SIGEA: actualités des SIG pour l'enseignement agricole
-
Data and GIS tips
-
Neogeo Technologies
(3 non lus)
-
ReLucBlog
-
L'Atelier de Cartographie
-
My Geomatic
-
archeomatic (le blog d'un archéologue à l’INRAP)
-
Cartographies numériques
(15 non lus)
-
Veille cartographie
(1 non lus)
-
Makina Corpus (5 non lus)
-
Oslandia
(4 non lus)
-
Camptocamp
-
Carnet (neo)cartographique
-
Le blog de Geomatys
-
GEOMATIQUE
-
Geomatick
-
CartONG (actualités)

Neogeo Technologies (3 non lus)
-
 17:44
17:44 Votre chatbot OneGeo Chat : décryptage technique
sur Neogeo TechnologiesLes chatbots sont partout, OneGeo Chat ne se limite pas à des réponses génériques : il exploite vos jeux de données ! Grâce à l’architecture RAG (Retrieval Augmented Generation), il interroge et croise les informations disponibles pour fournir des réponses précises et contextualisées, adaptées à votre domaine.
Un chatbot, mais pas n’importe lequel ! Cet article s’adresse à celles et ceux qui veulent aller plus loin et découvrir l’envers du décor : architecture, choix technologiques, infrastructure… On vous embarque dans les coulisses du développement de OneGeo Chat !
Cet article s’adresse à celles et ceux qui veulent aller plus loin et découvrir l’envers du décor : architecture, choix technologiques, infrastructure… On vous embarque dans les coulisses du développement de OneGeo Chat ! 
 Derrière l’écran : l’équipe aux manettes
Derrière l’écran : l’équipe aux manettes
Derrière OneGeo Chat, c’est nous, l’équipe du service Innovation de Neogeo Toulouse, qui sommes aux manettes : Sébastien Da Rocha et Mathilde Pommier. Passionnés par les avancées en traitement du langage naturel (NLP : Natural Language Processing), nous nous sommes appuyés sur les recherches les plus récentes pour concevoir un chatbot à la fois performant et réellement utile. Plutôt que de développer un assistant générique, nous avons voulu créer un outil capable d’exploiter vos jeux de données, afin de fournir des réponses précises et adaptées à votre contexte métier.
 Pourquoi OneGeo Chat ?
Pourquoi OneGeo Chat ?
L’idée de OneGeo Chat est née de l’observation de certains défis récurrents rencontrés par nos utilisateurs dans leur manière de rechercher des jeux de données. Nous disposons déjà de OneGeo Explorer, un outil performant pour la recherche full-text. Ce dernier présente une limite : si l’utilisateur ne connaît pas précisément les termes exacts présents dans les jeux de données qu’il cherche, il risque de ne pas le trouver. Ce constat a révélé un besoin : celui d’une recherche plus flexible, adaptée à des utilisateurs qui ne savent pas toujours comment formuler leur requête.
Un autre besoin que nous avons identifié est celui de questionner les jeux de données sur des sujets vastes et complexes. Lorsque l’utilisateur se lance dans la recherche d’informations, il n’a pas toujours une idée claire de tous les aspects du sujet qu’il explore. Il manque souvent une interaction dynamique qui permettrait d’approfondir la recherche au fur et à mesure, de poser des questions spécifiques et d’obtenir des réponses contextualisées. C’est pour cela que nous avons choisi le format du chatbot : offrir un échange fluide, comme une conversation, pour guider l’utilisateur dans sa recherche.
Enfin, un autre point important est que, souvent, les utilisateurs effectuent des recherches similaires ou cherchent à retrouver des informations qu’ils ont déjà consultées. Le chatbot permet donc de garder une trace des recherches en les enregistrant dans différentes conversations. Cela permet de classer et de retrouver plus rapidement des données pertinentes, facilitant ainsi les futurs échanges.
C’est en réponse à ces besoins que OneGeo Chat a vu le jour : une solution qui permet non seulement de questionner les jeux de données de manière plus naturelle, mais aussi de garder une trace de ses recherches et de faciliter l’exploration même pour les sujets les plus complexes.
 Une intégration aux petits oignons
Une intégration aux petits oignons
Dès la phase de conception, OneGeo Chat a été pensé pour s’intégrer de manière fluide dans la plateforme OneGeo Suite, afin d’offrir une expérience unifiée aux utilisateurs. Tout comme OneGeo Explorer, l’objectif était de créer un point d’entrée unique où les utilisateurs peuvent gérer, rechercher et visualiser leurs jeux de données, sans avoir à jongler entre plusieurs outils. Cette intégration permet de centraliser l’accès aux données tout en optimisant la fluidité de l’expérience utilisateur.
Cependant, nous avons également pris en compte le besoin de flexibilité. Ainsi, OneGeo Chat a été conçu pour fonctionner en stand-alone, de manière totalement autonome, pour les utilisateurs ayant des besoins plus modestes ou spécifiques. Cette modularité de la solution, à la fois en termes d’intégration dans un environnement plus large ou de déploiement indépendant, permet à OneGeo Chat de s’adapter à différentes configurations et de répondre à une large variété de cas d’usage.
Dans les coulisses du codeC’est ici que ça se corse !
On plonge maintenant au cœur de la technique et des choix qui ont façonné OneGeo Chat. Préparez-vous à découvrir comment ce projet a été conçu, les technologies utilisées et l’infrastructure qui permet à ce chatbot de fonctionner sans accroc. Les fondations du projet
Le principe de RAG (Retrieval Augmented Generation)
Les fondations du projet
Le principe de RAG (Retrieval Augmented Generation)
Au cœur de OneGeo Chat se trouve une architecture puissante qui combine deux technologies : la génération de texte par IA et la récupération d’informations métier. Ce modèle, appelé RAG, permet à notre chatbot d’aller au-delà de la simple génération de réponses. Plutôt que de s’appuyer uniquement sur des connaissances internes, il interroge une base de données vectorielle contenant vos jeux de données pour y chercher des informations pertinentes, puis génère une réponse en fonction de ces données.
Le processus se déroule en deux étapes principales : d’abord, le moissonnage (harvest) des différentes sources de données afin de remplir une base de données vectorielle qui servira au modèle lors de son utilisation (inférence). Puis, l’étape d’inférence où l’utilisateur pose sa question au chatbot et où l’application répond grâce à un modèle d’IA.
Cette seconde étape est elle-même divisée en deux avec, il y a d’abord la phase de récupération des données pertinentes pour la question de l’utilisateur (le retrieval). Ici, le chatbot consulte la base de données vectorielle précédemment remplie dans l’étape de harvest pour récupérer des documents en lien avec la question posée.
Plutôt que de rechercher une correspondance exacte (full-text, comme dans OneGeo Explorer), le modèle se base sur la proximité vectorielle des termes. Autrement dit, il évalue la similarité sémantique entre la question de l’utilisateur et les documents stockés, ce qui lui permet d’identifier des réponses pertinentes même si les termes exacts ne sont pas présents dans les jeux de données. Cela implique donc de vectoriser à la fois les documents en base et la question de l’utilisateur avec un seul et même modèle sémantique.
Une fois les documents pertinents récupérés, ces derniers forment ce qu’on appelle un contexte qui va venir nourrir un LLM (Large Language Model : modèle d’IA générative). En somme, ce contexte offre une base à l’IA et l’oriente dans la bonne direction pour générer une réponse précise à la question de l’utilisateur. Ainsi, la technique utilisée est la même que celle que vous employez quand vous détaillez votre demande dans d’autres chatbots.
C’est donc ainsi que s’achève le modèle de RAG, qui permet donc au modèle d’IA de générer des réponses basées sur les jeux de données de l’utilisateur. Un RAG classique se termine ainsi, mais on verra par la suite que le nôtre comprend une étape supplémentaire.
Le RAG de OneGeo ChatMaintenant que le principe général du RAG est clair, passons aux spécificités de son implémentation dans OneGeo Chat. Notre approche va plus loin qu’un simple Retrieval Augmented Generation classique en intégrant des mécanismes avancés pour optimiser la récupération et l’exploitation des informations.
Lors de la phase de moissonnage, notre base de données vectorielle est enrichie avec les jeux de données issus de la plateforme OneGeo Suite. Cette dernière push (pousse) ses méta-données publiées et celles moissonnées dans la base de données vectorielle de OneGeo Chat. Bien sûr, seules les données accessibles en anonymes sont disponibles. La base vectorielle peut aussi (mais ce n’est pas obligatoire) être alimentée en pull (tirant) des données de notre application de management de projet : Redmine. À l’avenir, d’autres sources de données seront ajoutées, vous pourrez également rajouter les votres. Ainsi, ces deux mécanismes (de push et pull) remplissent ainsi la base de données vectorielle de OneGeo Chat avec vos données.
Plus concrètement, la recherche sémantique n’est réalisable et efficace que sur de petits morceaux de texte de quelques centaines de caractères. De ce fait, les documents ne sont pas conservés tels quels dans la base de données vectorielle de OneGeo Chat. Ces derniers sont donc découpés en phrases avant que celles-ci ne soient indexées grâce à cette représentation vectorielle. Bien sûr, chaque phrase est enregistrée avec un lien vers son document d’origine pour que l’on puisse remonter jusqu’à ce dernier.
De plus, OneGeo Chat ne se limite pas à récupérer les documents les plus pertinents dans une base vectorielle, en effet, ce dernier adopte une approche plus complète et modulaire. Nous avons mis en place un système de chaînage de retrievers, permettant d’agréger plusieurs types d’informations pour former le contexte à envoyer au modèle génératif :
- Une pré instruction codée en dur : avant même de chercher des documents, le chatbot récupère un ensemble de directives définissant son comportement (langue de réponse, citation des sources, etc.).
- L’historique de conversation : pour assurer une réelle continuité dans l’échange, le chatbot prend en compte les messages précédents de la conversation en cours.
- Les titres de documents les plus pertinents : afin d’affiner la recherche, nous utilisons un premier filtre basé sur les titres des documents les plus proches de la requête utilisateur. Cela permet d’orienter efficacement le processus de récupération.
- Les documents les plus pertinents dans la base vectorielle : une fois ces étapes réalisées, le chatbot interroge la base vectorielle pour récupérer les documents les plus en adéquation avec la question posée. On récupère uniquement les données pertinentes d’un point de vue sémantique : le titre, la description et autres métadonnées (mais pas les dates par exemple).
Grâce à cette architecture modulaire, il est possible d’ajouter, d’orchestrer ou de retirer des retrievers à tout moment, offrant ainsi une grande flexibilité pour tester et sélectionner différents algorithmes de récupération et de génération.
Finalement, OneGeo Chat possède une dernière particularité s’ajoutant au RAG classique : un bloc supplémentaire nommé Document Searcher. Ce module intervient une fois la réponse générée par le LLM et se concentre sur le cas d’utilisation de la recherche documentaire. Pour cela, ce module prend en entrée la question initiale ainsi que la réponse générée. Il effectue des recherches sémantiques dans la base de données vectorielle sur ces données d’entrées. À l’issue de ce processus, les cinq documents les plus pertinents sont sélectionnés et présentés à l’utilisateur, accompagnés d’un lien, d’une description et de son score.
Ainsi, le chatbot OneGeo Chat vous permet d’accéder directement aux jeux de données les plus pertinents en lien avec votre question initiale.
Vous trouverez l’ensemble des modules composants OneGeo Chat dans le schéma suivant.
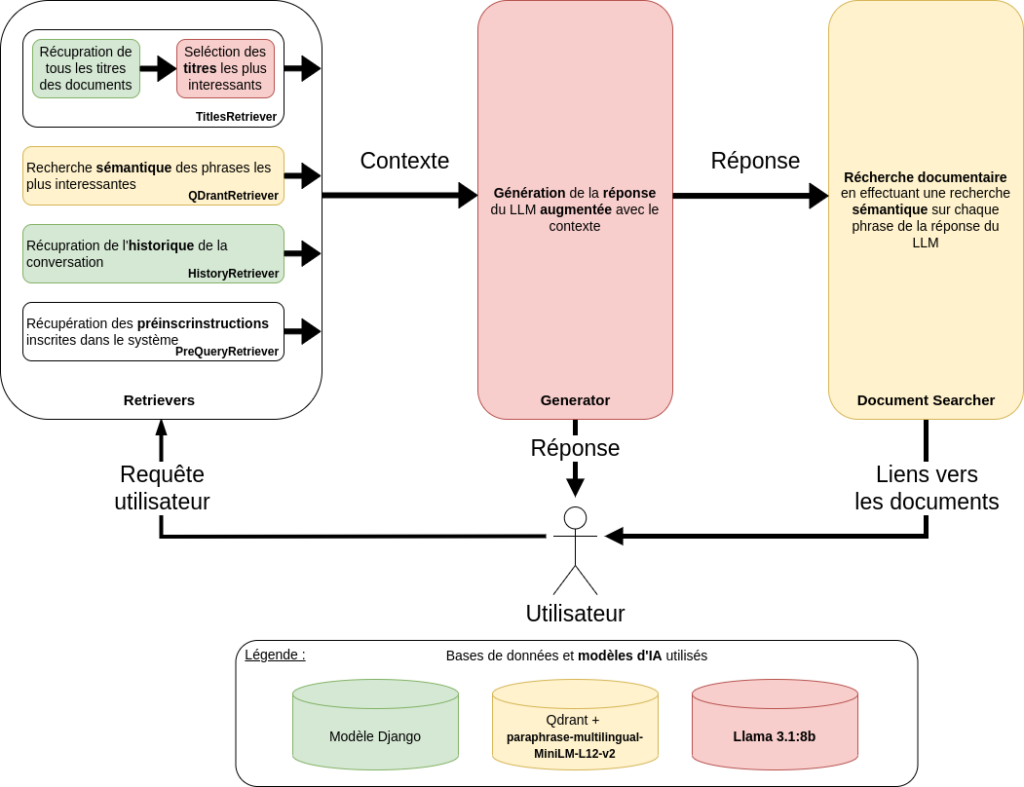
 Un savant mélange de technos libres au cœur de OneGeo Chat
Un savant mélange de technos libres au cœur de OneGeo Chat
OneGeo Chat repose sur plusieurs technologies qui assurent son bon fonctionnement, aussi bien côté intelligence artificielle que sur les aspects backend, frontend et validation.
Pour la partie IA, deux modèles sont utilisés : Llama 3.1:8b pour la génération LLM des réponses et paraphrase-multilingual-MiniLM-L12-v2 pour la recherche sémantique. Vous avez d’ailleurs déjà pu voir ces modèles sur le schéma précédent. Nous avons sélectionné ces modèles non seulement pour leurs performances, mais aussi pour leur taille réduite, ce qui facilite leur exécution (le temps de réponse). De plus, ils sont disponibles via Ollama, une solution qui simplifie la gestion, l’utilisation et l’interchangeabilité des modèles.
Le backend est développé en Python et avec le framework Django. Pour ce qui est de la base de données vectorielles, nous avons fait le choix de QDrant, qui permet d’effectuer facilement les recherches sémantiques. Cette base de données vectorielle est également légère et facilement déployable. Pour gérer la communication en temps réel, nous utilisons Django Channels, qui permet d’intégrer facilement les WebSockets à Django. Cette technologie nous permet de facilement gérer les conversations. Par ailleurs, Django REST Framework (DRF) facilite l’interaction avec la base de données et les échanges entre le frontend et le backend.
Côté frontend, l’interface est construite avec VueJS 3 et TypeScript. On a opté pour TypeScript plutôt que JavaScript afin de bénéficier de ses règles de typage, ce qui permet de limiter les bugs, d’améliorer la clarté du code et de faciliter sa maintenance sur le long terme.
Également, au service innovation de Neogeo, nous accordons une grande importance à la qualité et à la fiabilité de nos développements. Pour garantir un code robuste et maintenir un haut niveau de tests et validation, nous avons mis en place une CI (Intégration Continue) dans le GitLab du projet OneGeo Chat.
Nous utilisons notamment MyPy pour l’analyse statique du code backend Python, ce qui nous permet de détecter les incohérences de typage avant même l’exécution du programme. Pour le suivi de la qualité du code, SonarQube analyse notre code en profondeur afin de détecter d’éventuels bugs, code smells et évaluer notre couverture de code. Quant aux tests en eux-mêmes, Pytest est notre outil principal pour l’exécution des tests unitaires et d’intégration backend. Côté frontend, nous avons quelques tests Cypress, mais ces derniers restent basiques et ne sont pas intégrés dans la CI, mais exécutables manuellement.
Aussi, nous avons l’outil Pip-audit qui nous aide à identifier les vulnérabilités de sécurité dans les dépendances Python et à garantir que notre application repose sur des bibliothèques à jour et sécurisées. Pour finir, puisque OneGeo Chat est open-source, nous utilisons Pylic afin de vérifier que toutes les bibliothèques et API que nous intégrons respectent bien les licences adéquates.
Si vous souhaitez en apprendre plus sur les compatibilités entres licences, je vous invite à consulter notre article sur la licence Affero GPL 3.0
Enfin, le déploiement est géré via Docker, ce qui permet non seulement d’avoir un environnement isolé et reproductible, mais aussi de simplifier la gestion des dépendances et de garantir que OneGeo Chat fonctionne de manière cohérente, peu importe l’environnement. Aussi, Docker simplifie grandement le déploiement et l’exécution des dépendances. En résumé, Docker rend le processus de déploiement de OneGeo Chat rapide, fiable et facile à maintenir, c’est pour cela que nous l’avons adopté.
 Une infrastructure qui tient la route
Une infrastructure qui tient la route
OneGeo Chat a été conçu pour fonctionner aussi bien sur GPU que sur CPU, offrant ainsi une flexibilité en fonction des ressources disponibles. Toutefois, en pratique, les performances sur GPU sont largement supérieures : les temps de génération sont bien plus rapides et l’expérience utilisateur s’en trouve grandement améliorée.
Le mode CPU reste une alternative, mais il demande une quantité importante de RAM et entraîne des temps de réponse nettement plus longs. C’est pourquoi nous recommandons fortement l’utilisation d’un GPU pour tirer pleinement parti de l’application.
Afin de faciliter l’adaptation du déploiement à votre infrastructure, le fichier docker-compose.yml inclut des sections spécifiques pour les GPU. Par défaut, la configuration utilise le CPU pour plus de compatibilité, mais vous pouvez activer la prise en charge des GPU en décommentant les parties correspondantes. Cela permet de tirer parti des capacités de votre matériel tout en maintenant une configuration unique et facile à gérer. Pour pouvoir utiliser le mode GPU, il vous faudra disposer d’un GPU Nvidia avec au moins 8Go de RAM et avoir installé le Nvidia Container Toolkit. Nous n’avons pas testé avec un GPU AMD, même si c’est théoriquement possible. Encore une fois, l’utilisation de conteneurs avec Docker simplifie grandement le déploiement de OneGeo Chat.
D’ailleurs, pour tester localement OneGeo Chat, suivez les instructions détaillées dans la section Run Locally du README du projet. Vous y trouverez toutes les étapes pour configurer et exécuter l’application en local.
Le mot de la finPour conclure, si vous cherchez un moyen simple et rapide pour rechercher et échanger efficacement autour de vos données, géomatiques ou non, alors OneGeo Chat est fait pour vous. Ce projet étant toujours en pleine évolution, nous souhaitons y apporter des améliorations et de nouvelles features.
Nous souhaitons notamment renforcer la validation en ajoutant plus de tests fonctionnels avec Cypress et en intégrant Ragas pour évaluer la pertinence du modèle. Ragas est une bibliothèque qui fournit des outils pour améliorer l’évaluation des applications LLM.
L’optimisation des réponses générées est aussi une priorité afin d’améliorer encore la qualité des résultats. Par ailleurs, nous ambitionnons de faire de OneGeo Chat un pilote de notre plateforme OneGeo Suite.
Enfin, nous aimerions aller plus loin dans l’interprétation des données géomatiques en exploitant non seulement les titres et descriptions des jeux de données, mais aussi les attributs et la géométrie de ces derniers.
Pour rester informé sur l’évolution de OneGeo Chat, vous pouvez consulter le site officiel de Neogeo, poser vos questions et échanger avec la communauté sur notre forum, et suivre notre actualité sur LinkedIn.
Rédactrice : Mathilde Pommier
-
8:57
Les évolutions de Python 3.9 à 3.13 : Typage
sur Neogeo TechnologiesSi on peut dire que la librairie standard Python est stable, on ne peut pas en dire autant de la partie typage qui est en pleine effervescence.
Pour mémoire, le typage en Python est optionnel, et c’est très bien pour les petits projets et les scripts. Dès que le projet prend de l’envergure, le typage des paramètres des fonctions aide à la rigueur et force à se poser les bonnes questions sur les flux de données dans le programme.
Version 3.9Dans la version 3.9 de Python, il y a une seule évolution dans le typage, mais qui va considérablement améliorer la lisibilité et simplifier le code dédié au typage : on peut désormais utiliser les types « built-ins » (list, disc…) pour déclarer notre typage.

class Foo: def add_items(self, items: list[str]) -> None: ...Je ne sais pas pour vous, mais pour moi ça réduit tellement le ticket d’entrée du typage que ça ne me dérangerais pas de l’intégrer même dans des petits scripts.
Version 3.10Depuis la version 3.10 de Python, on peut désormais utiliser l’opérateur | pour déclarer des unions de types (la fonction accepte plusieurs types différents, voir les rendre optionnels) :
class Foo: def set_color(self, color: str|Color|None) -> None: ... def get_color(self) -> Color|None: ...Un gros effort a également été fait dans cette version pour proposer une généricité dans le typage. Par exemple quand on défini un décorateur, on ne connaît pas toujours à l’avance le type de la fonction décorée. Dorénavant, on peut utiliser ParamSpec pour dire que c’est un type qu’on ne connaît pas.
Un peu de clarté a aussi été apportée avec l’ajout de TypeAlias qui permet de donner un nom explicite à un type complexe.
StrCache: TypeAlias = 'Cache[str]'Pour créer des petites fonctions qui vérifient le type (is_bool, is_string, etc…), les TypeGuards ont été introduits. Les TypeGuards sont utilisés pour une pratique assez complexe appelée rétrécissement de type. Cette dernière est utilisée pour les fonctions qui acceptent des variables d’entrée avec plusieurs types possibles. TypeGuard permet alors de mettre en place une vérification de type sur les variables d’entrée de la fonction.
Version 3.11 L’utilisation des TypeGuards n’est pas très simple, je vous invite donc à aller regarder la documentation Python plus en détails si cela vous intéresse.
L’utilisation des TypeGuards n’est pas très simple, je vous invite donc à aller regarder la documentation Python plus en détails si cela vous intéresse. Toujours dans les ajouts complexes, la version 3.11 a introduit des Variadic générique pour gérer des ensembles d’éléments avec une taille fixes (un tenseur avec une taille fixée par exemple).
Un générique permet de préserver un type entre l’entrée et la sortie d’une fonction. Par exemple, si l’on prend la fonction de copie d’une variable, celle-ci prend une variable en entrée et cette dernière peut être de tout type, on la typera donc Any. Comme la fonction retourne une copie de la variable d’entrée, le type de retour de la fonction sera le même que celui de la variable en entrée (Any).
Le problème est qu’avec Any, on a aucun moyen de vérifier que les types de l’entrée et de la sortie sont les mêmes, et c’est ici que le générique entre en jeu.
def copy_of_1(value: Any) -> Any: # Le Any d'entrée et # le Any de sortie # ne sont pas forcés # d'être du même type return deepcopy(value) T = TypeVar("T") def copy_of_2(value: T) -> T: # Les variables en entrée # et en sortie sont forcées # d'être du même type return deepcopy(value)Le Variadic générique, quant à lui, est plus complexe et permet de gérer des types multi-dimensionnels.
Là encore la mise en œuvre est subtile, je vous invite à aller lire la documentation officielle. Par contre dans les petits ajouts qui peuvent servir à tout le monde, il y a les types Required et NotRequired dans les TypedDict :
class Shape(TypedDict): x: Required[int] y: Required[int] color: NotRequired[int]Il y aussi le type Self qui a été ajouté, très pratique pour faire un constructeur :
class Shape: @classmethod def new(cls, x: int, y: int) -> Self: ...Il y a aussi un type LiteralString ajouté. Il peut être utilisé pour indiquer qu’un paramètre de fonction peut être de n’importe quel type de chaîne littérale (chaîne de caractères écrite en dur dans le code, comme « Hello World ! »).
Ce type est principalement utile pour renforcer la sécurité
 car il indique qu’une variable doit être codée en dur. Contrairement à un simple str, ce type garantit donc que la valeur provient directement du code source, sans transformation dynamique. Ainsi, LiteralString établit une distinction importante entre les chaînes définies explicitement dans le code et celles obtenues dynamiquement.
car il indique qu’une variable doit être codée en dur. Contrairement à un simple str, ce type garantit donc que la valeur provient directement du code source, sans transformation dynamique. Ainsi, LiteralString établit une distinction importante entre les chaînes définies explicitement dans le code et celles obtenues dynamiquement. Si vous êtes du genre à aimer creuser (ou que vous êtes simplement têtu·e comme moi), voici ce que j’ai compris sur le fonctionnement de LiteralString :
Si vous êtes du genre à aimer creuser (ou que vous êtes simplement têtu·e comme moi), voici ce que j’ai compris sur le fonctionnement de LiteralString :Le LiteralString vous permet d’ajouter un peu de sécurité et de rigueur dans votre code sans pour autant avoir un typage trop drastique. Pour mieux visualiser, on peut prendre en exemple une fonction d’affichage des logs.
def log(level: str, message: str): if level == "Error": print(message) level = "Error" + "\u200b" # "Error" avec un caractère invisible (Zero Width Space) log(level, "Ce message s'affiche !")Avec cette version de la fonction, on peut voir qu’il y a un problème de sécurité car notre message s’affichera alors que la variable level n’est pas exactement égale à Error. Pas bien grave me direz-vous. Et, en effet, ce n’est pas très important pour une fonction de logs, mais s’il s’agissait de la gestion de vos bases de données …
À l’inverse, on le Literal à l’extrême du typage :
from typing import Literal ERROR: Literal["Error"] = "Error" def log(level: Literal["Error"], message: str): if level == ERROR: print(message) log(ERROR, "Ce message s'affiche !") # Pas d'alert sur le type level = "Error" + "\u200b" # "Erreur" avec un caractère invisible (Zero Width Space) log(level, "Ce message ne s'affichera pas !") # Une erreur de type sera indiquéeAvec cette version de la fonction, on contrôle strictement le type de la variable level en entrée. Par contre, dès lors que l’on augmente le nombre de types possibles en entrée, la syntaxe devient laborieuse. De même, il est possible de ne pas connaître à l’avance tous les types d’entrée possible (dans le cas de composants extérieurs).
from typing import Literal INFO: Literal["Info"] = "Info" WARNING: Literal["Warning"] = "Warning" ERROR: Literal["Error"] = "Error" def log(external_component: ???, # Le type n'est pas connu level: Literal["Info", "Warning", "Error", ...], # On pourrait avoir beaucoup de types possibles message: str): if level == ERROR: print(message)Pour remédier à ces deux situations, on a donc trouvé le compromis du LiteralString :
from typing import LiteralString, Literal INFO: Literal["Info"] = "Info" WARNING: Literal["Warning"] = "Warning" ERROR: Literal["Error"] = "Error" def log(external_component: LiteralString, level: LiteralString, message: str): if level == ERROR: print(message) log(INFO, "Ce message ne s'affichera pas !") # Pas d'alert sur le type log(WARNING, "Ce message ne s'affichera pas !") # Pas d'alert sur le type log(ERROR, "Ce message s'affiche !") # Pas d'alert sur le typeIl est également possible d’utiliser à la fois le Literal et le LiteralString :
from typing import LiteralString, Literal INFO: LiteralString = "Info" # On définit INFO avec un type moins précis WARNING: Literal["Warning"] = "Warning" ERROR: Literal["Error"] = "Error" def log(external_component: LiteralString, level: Literal["Warning", "Error"], # Level est soit du type Literal["Warning"] soit du type Literal["Error"] message: str): if level == ERROR: print(message) log(INFO, "Ce message ne s'affichera pas !") # Alerte sur le type log(WARNING, "Ce message ne s'affichera pas !") # Pas d'alerte sur le type log(ERROR, "Ce message s'affiche !") # Pas d'alerte sur le type log(WARNING+ERROR, "Ce message ne s'affichera pas !") # Pas d'alerte sur le type. Pas très intéressant mais pourquoi pas ...Grâce aux deux exemples précédents, on peut donc en conclure que LiteralString regroupe tous les Literal[<…>] où <…> est une chaîne de caractères. Ainsi, on en déduit que LiteralString est le supertype de tous les types de chaînes littérales.
 Donc, tout « sous-type » de LiteralString (Literal[« Error »] ou bien encore Literal[« Warning »]) est compatible avec LiteralString , mais pas l’inverse (se référer à la variable INFO de l’exemple précédent). De même, le supertype LiteralString est lui-même un str, faisant de str un super supertype. Finalement, avec la même logique que précédemment, on en déduit bien qu’un str n’est pas compatible avec un LiteralString . On entend par là qu’il est possible d’assigner un LiteralString à un str, mais pas l’inverse.
Donc, tout « sous-type » de LiteralString (Literal[« Error »] ou bien encore Literal[« Warning »]) est compatible avec LiteralString , mais pas l’inverse (se référer à la variable INFO de l’exemple précédent). De même, le supertype LiteralString est lui-même un str, faisant de str un super supertype. Finalement, avec la même logique que précédemment, on en déduit bien qu’un str n’est pas compatible avec un LiteralString . On entend par là qu’il est possible d’assigner un LiteralString à un str, mais pas l’inverse. literal_string: LiteralString s: str = literal_string # OK literal_string: LiteralString = s # Erreur : # On attendait un # LiteralString, # on a un str literal_string: LiteralString = "hello" # OKUne chaîne créée en composant des objets typés LiteralString est, quant-à-elle, acceptable en tant que LiteralString (comme pour les Literal).
literal_string_1: LiteralString = "Hello" literal_string_2: LiteralString = " World" composed_string: LiteralString = literal_string_1 + literal_string_2 + " !" # Toujours un LiteralStringCe type est utile pour les API sensibles où des chaînes arbitraires générées par l’utilisateur peuvent générer des problèmes.
Pour plus d’exemples, vous pouvez vous référer à la documentation officielle de Python.Du côté des décorateurs, la version 3.11 ajoute dataclass_transform qui est applicable à une classe, une métaclasse ou un décorateur. Ce décorateur permet de marquer un objet comme offrant un comportement de type dataclass tout en effectuant la vérification des types.
Pour rappel, le décorateur dataclass ajoute des méthodes générées et spéciales à une classe. On aura par exemple des méthodes comme __init__, __repr__ ou encore __eq__.
Version 3.12# Le décorateur create_model est défini par une bibliothèque. @typing.dataclass_transform() def create_model(cls: Type[T]) -> Type[T]: cls.__init__ = ... cls.__eq__ = ... cls.__ne__ = ... return cls # Le décorateur create_model peut désormais être utilisé # pour créer de nouvelles classes de modèles : @create_model class CustomerModel: id: int name: str c = CustomerModel(id=327, name="Eric Idle")La version 3.12 quant à elle introduit l’utilisation du type dictionnaire TypedDict pour avoir un typage plus précis des arguments (**kwargs).
Avant cet ajout, les **kwargs pouvaient être typés à condition que tous les arguments de mot-clé qu’ils spécifient soient du même type. Or, ce comportement était très limitant. Par exemple, annoter **kwargs avec un type str signifie que le type **kwargs est en fait un dict[str, str] et donc que tous les arguments de mot-clé dans foo sont des chaînes de caractères.
def foo(**kwargs: str) -> None: ...Malheureusement, il arrive souvent que les arguments de mots-clés véhiculés par **kwargs aient des types différents qui dépendent du nom du mot-clé. Dans ce cas, il n’était pas possible d’annoter le type des **kwargs.
Maintenant, en utilisant TypedDict pour typer les **kwargs, il est possible d’assigner un dictionnaire comme type des **kwargs. Ainsi, les **kwargs peuvent être typés séparément (par clé du dictionnaire).
from typing import TypedDict, Unpack class Movie(TypedDict): name: str year: int def foo(**kwargs: Unpack[Movie]): ...Pour plus de détails, je vous invite à consulter la documentation officiel de Python. La version 3.12 offre aussi un nouveau décorateur override qui sera sans doute utile pour une grande majorité. Ce dernier indique qu’une méthode dans une sous-classe est destinée à remplacer une méthode (ou un attribut) dans une classe parente.
 Cette version apporte également de nouvelles caractéristiques syntaxiques pour créer des classes génériques et des fonctions de façon explicite et compacte.
Cette version apporte également de nouvelles caractéristiques syntaxiques pour créer des classes génériques et des fonctions de façon explicite et compacte. def max[T](args: Iterable[T]) -> T: ... class list[T]: def __getitem__(self, index: int, /) -> T: ... def append(self, element: T) -> None: ...De plus, une nouvelle façon de déclarer des alias de type est introduite. Comme présenté sur l’exemple suivant, l’instruction type est utilisée, ce qui crée une instance de TypeAliasType et rend la déclaration explicite.
Version 3.13type Point = tuple[float, float]Avec la version 3.13, il est maintenant possible de définir une valeur par défaut pour les paramètres de type (TypeVar, ParamSpec, et TypeVarTuple).
T = TypeVar("T", default=int) # Si aucun type n'est spécifié, # T sera de type int @dataclass class Box(Generic[T]): value: T | None = None reveal_type(Box()) # Le type est Box[int] reveal_type(Box(value="Hello World!")) # Le type est Box[str]Il également possible, depuis cette version, de marquer une classe ou une fonction comme dépréciée à l’aide du nouveau décorateur deprecated. Ainsi, on peut informer les développeurs lorsqu’ils utilisent ces classes et fonctions pour qu’ils mettent en place les migrations nécessaires.
Autre petit ajout très utile, le qualificatif ReadOnly pour le type TypedDict qui permet de définir certaines clés comme étant en lecture seule. L’utilisation correcte de ces clés en lecture seule est destinée à être appliquée uniquement par les vérificateurs de type statique et non pas par Python lui-même au moment de l’exécution.
Finalement, la version 3.13 revient sur son ajout de TypeGuard dans la version 3.10. Cette version propose une alternative plus intuitive à TypeGuard : TypeIs. Cette nouvelle forme permet l’annotation de fonctions pouvant être utilisées pour affiner le type d’une valeur.
from typing import assert_type, final, TypeIs class Parent: pass class Child(Parent): pass @final class Unrelated: pass def is_parent(val: object) -> TypeIs[Parent]: return isinstance(val, Parent) def run(arg: Child | Unrelated): if is_parent(arg): # Le type de ``arg`` est réduit à l'intersection entre # ``Parent`` et ``Child``, # ce qui équivaut à ``Child``. assert_type(arg, Child) else: # Le type de ``arg`` est réduit pour exclure ``Parent``, # de sorte qu'il ne reste que ``Unrelated``. assert_type(arg, Unrelated)Contrairement à la forme spéciale TypeGuard existante, TypeIs peut affiner le type dans les branches if et else d’une condition. Cependant, TypeIs ne peut pas être utilisé lorsque les types d’entrée et de sortie sont incompatibles (par exemple, list[object] vers list[int]), ou lorsque la fonction ne renvoie pas True pour toutes les instances du type rétréci.
ConclusionPour plus de précisions, je vous renvoie vers la documentation officielle.  On constate que le typage en Python est en pleine évolution, avec chaque version apportant son lot d’améliorations pour le rendre plus expressif, plus robuste et plus facile à utiliser.
On constate que le typage en Python est en pleine évolution, avec chaque version apportant son lot d’améliorations pour le rendre plus expressif, plus robuste et plus facile à utiliser. Les ajouts récents, comme Self, LiteralString, TypedDict ou encore override, montrent une volonté de rendre le typage plus intuitif et utile dans des scénarios concrets.
Avec la version 3.13, Python continue sur cette lancée en offrant des outils plus flexibles et en réajustant certaines décisions, comme l’alternative TypeIs pour TypeGuard.
 En résumé, le typage en Python présente des avantages (et aussi, parfois, des inconvénients) qui méritent d’être pris en compte dans vos développements.
En résumé, le typage en Python présente des avantages (et aussi, parfois, des inconvénients) qui méritent d’être pris en compte dans vos développements. D’un côté, il apporte une meilleure sécurité en réduisant le risque de bugs et les attaques. En imposant des types clairs, il permet également une meilleure lisibilité du code, notamment lorsque les structures et les workflows deviennent plus complexes. Cela facilite non seulement la maintenance, mais aussi la reprise du code par d’autres développeurs, rendant ainsi la collaboration plus fluide.
D’un côté, il apporte une meilleure sécurité en réduisant le risque de bugs et les attaques. En imposant des types clairs, il permet également une meilleure lisibilité du code, notamment lorsque les structures et les workflows deviennent plus complexes. Cela facilite non seulement la maintenance, mais aussi la reprise du code par d’autres développeurs, rendant ainsi la collaboration plus fluide. Cependant, le typage en Python présente aussi quelques limites. Certains types ou fonctionnalités, comme TypeGuard, peuvent être difficiles à prendre en main. De plus, certains types, tels que LiteralString, n’apportent pas toujours une réelle valeur ajoutée au regard de leur complexité d’utilisation. Enfin, l’ajout de types peut parfois alourdir visuellement le code, ce qui peut nuire à sa lisibilité.
Cependant, le typage en Python présente aussi quelques limites. Certains types ou fonctionnalités, comme TypeGuard, peuvent être difficiles à prendre en main. De plus, certains types, tels que LiteralString, n’apportent pas toujours une réelle valeur ajoutée au regard de leur complexité d’utilisation. Enfin, l’ajout de types peut parfois alourdir visuellement le code, ce qui peut nuire à sa lisibilité.Pour ma part, je pense qu’il est essentiel de prêter attention au typage. Il contribue grandement à la compréhension et à la maintenance du code, notamment lorsqu’il s’agit de reprendre le travail de quelqu’un d’autre. À mon sens, il est au minimum nécessaire de typer les prototypes de méthodes, en précisant clairement les types des entrées et des sorties. Au final, le plus important reste de discuter des normes de typage avec son équipe afin d’adopter une approche cohérente et adaptée aux besoins du projet.
Quoi qu’il en soit, le langage Python gagne en maturité, mais le typage demeure un terrain d’innovation. Il nous tarde de découvrir ses prochaines évolutions !
P.S. : Pour en apprendre plus sur les évolutions de Python (hors typage), je vous invite à consulter notre article intitulé « Découvrez les évolutions majeures de Python de 3.9 à 3.13 ».
Auteur : Mathilde Pommier
-
9:00
ANITI Days 2024 : une plongée au cœur des innovations en intelligence artificielle
sur Neogeo TechnologiesLes 25 et 26 novembre dernier, j’ai eu la chance de participer aux ANITI Days, organisés à la Cité de Montaudran à Toulouse. Ces journées dédiées à l’intelligence artificielle sont orchestrées par l’ANITI (Artificial and Natural Intelligence Toulouse Institute), un institut de recherche de pointe en Occitanie spécialisé dans l’intelligence artificielle.
Rencontres enrichissantes autour du Retrieval-Augmented Generation (RAG)Parmi les nombreux exposants, j’ai particulièrement apprécié échanger autour des avancées sur le Retrieval-Augmented Generation (RAG), une approche mêlant récupération d’information et génération de contenu.
- Avec les chercheurs de LIEBHERR, j’ai découvert une bibliothèque prometteuse visant à optimiser le RAG en fonction des types de documents à traiter. Une solution qui ouvre des perspectives fascinantes pour améliorer l’adaptabilité et l’efficacité de cette technologie.
- De leur côté, les équipes de Synalinks m’ont présenté leurs travaux sur des agents RAG hybrides combinant IA symbolique et modèles de langage (LLM). Ces agents, capables de s’auto-améliorer, marquent une étape vers des systèmes d’IA toujours plus autonomes et performants.
Plus d’une douzaine de conférences ont rythmé ces deux jours, mettant en lumière les avancées scientifiques majeures dans différents domaines de l’IA. Voici quelques moments forts :
- Ellie Pavlick (en visioconférence) a exploré la compréhension des réseaux de neurones, notamment à travers des heat maps pour visualiser l’influence des neurones sur les réponses. Elle a introduit les notions de fonctions extractives et fonctions abstraites, illustrant les mécanismes par lesquels les modèles génèrent leurs réponses.
- Julie Hunter de Linagora a dévoilé un projet ambitieux : un modèle de langage entièrement libre nommé Lucie. Contrairement à d’autres modèles comme LLaMA, Lucie promet une transparence totale, en fournissant à la fois les poids, les scripts d’entraînement et les données utilisées. Un pas décisif vers une IA éthique et reproductible, essentielle pour garantir la sécurité et la fiabilité des systèmes.
- Chloé Braud a présenté des recherches préliminaires sur l’entraînement de modèles avec peu de données, une approche prometteuse pour réduire les coûts en ressources de calcul tout en maintenant des performances élevées.
- Eliot Chane s’est intéressé au pilotage robotique, utilisant des simulations d’environnements et des vidéos de documentaires animaliers pour former des agents dans un cadre d’apprentissage non supervisé.
- Rufin VanRullen a introduit le concept de Global Latent Workspace, un réseau de neurones multimodal intégrant langage, vision et mouvement. Cette approche innovante montre des résultats impressionnants pour le pilotage de robots.
Le deuxième jour, des thématiques tout aussi captivantes ont été abordées :
- Claire Monteleoni a exploré les applications de l’IA dans le cadre des défis climatiques.
- Vincent Martin a présenté des projets innovants utilisant les données du CNES, avec des applications allant de la météo à la bathymétrie.
- Plusieurs conférences se sont concentrées sur les enjeux de confiance et de garanties dans les réseaux de neurones, avec des interventions remarquées de Matthieu Serrurier, Mélanie Ducoffe et Paul Novello, sur des stratégies pour certifier, valider et encadrer les résultats des modèles.
La journée s’est conclue avec une présentation d’Urtzi Ayesta, démontrant qu’un apprentissage par renforcement pouvait modéliser un système à nombre d’états indéterminés, une avancée significative dans l’étude des systèmes complexes.
Un événement inspirantCes deux jours furent une immersion riche en découvertes, rencontres et échanges, révélant les défis et opportunités qui façonnent l’avenir de l’intelligence artificielle. Que ce soit pour les passionnés, les chercheurs ou les professionnels, les ANITI Days illustrent à quel point l’IA est au cœur des transformations technologiques et sociétales en cours.
J’ai hâte de voir comment ces avancées se concrétiseront dans les années à venir et suis convaincu que l’Occitanie continuera de jouer un rôle clé dans cet écosystème en plein essor.
Auteur : Sébastien Da Rocha (Service Innovation, Neogeo)
-
9:27
Découvrez les évolutions majeures de Python de 3.9 à 3.13
sur Neogeo TechnologiesPython, le langage de programmation dynamique créé par Guido van Rossum, est devenu l’un des outils les plus populaires pour les développeurs en raison de sa simplicité, de sa flexibilité et de sa puissance. À Neogeo, nous l’utilisons pour développer le backend de nos applications, pour faire des scripts d’administration et de la data-science.
Pour marquer la sortie de Python 3.13 le 7 Octobre dernier, nous allons passer en revue les changements importants qui ont été introduits dans les versions 3.9 (dernière version encore maintenue) à 3.13 de Python.
Ces nouvelles versions apportent des améliorations significatives en termes de performances, avec l’optimisation du code JIT et la suppression du GIL, véritable goulot d’étranglement pour les applications multi-thread. Elles offrent également des évolutions syntaxiques comme l’expression « matching ».
Autres nouveautés : la librairie standard de Python a elle aussi été mise à jour. La gestion du typage en Python a également été améliorée, avec l’introduction de types dynamiques. Nous verrons ces changements dans un article dédié.
Dans cet article, nous allons vous guider dans l’exploration des principaux changements apportés par Python 3.9 à 3.13, et nous vous proposerons des exemples pour exploiter ces nouvelles fonctionnalités et améliorer vos applications.
PerformancesDans la version 3.9 de Python, les performances de certaines structures built-in telles que dict, list ou set ont été améliorées. L’accès aux variables Python depuis les modules C a aussi été accéléré (nous n’aborderons pas ce sujet dans cet article).
La version 3.11 a été beaucoup optimisée, la documentation parle de 25% de gain de performances en moyenne, entre 10% et 60% d’amélioration selon le type de tâches.
Les travaux sur le GIL ont porté leurs fruits sur les versions 3.12 et 3.13. Le GIL, Global Interpreter Lock, est un mécanisme de Python qui évite l’accès simultané à une variable par plusieurs threads. Très simple pour le développeur, cela empêche la création de programmes multi-thread efficaces en Python. À une époque où on multiplie les CPU et les cores, c’est un fardeau pour notre petit langage. Les développeurs ont travaillé à retirer ce mécanisme, mais ils doivent procéder par étapes. Dans la version 3.12, Python peut désormais utiliser un GIL par interpréteur, on peut même le désactiver en ligne de commande dans la 3.13.
On peut noter qu’asyncio a été optimisé dans la version 3.12, avec jusqu’à 75% de gains de performances. Cette version de Python bénéficie d’une nouvelle API pour faire du monitoring de façon moins intrusive (impactant moins les performances).
En complément, la version 3.13 bénéficie aussi d’un compilateur JIT expérimental, il est activable en ligne de commande. La documentation indique que les gains de performances sont modestes. On peut imaginer que les versions suivantes de Python intégreront un compilateur JIT plus sophistiqué et plus performant.
Évolutions syntaxiquesLa version 3.9 de Python voit l’introduction d’opérateurs d’union de dictionnaire | et | =. Sans être révolutionnaire, on peut toujours utiliser la fonction update pour faire la même chose, mais c’est plus simple à écrire.

Peut-être moins impactant, on peut désormais utiliser des expressions Python comme décorateur. Cela permet de faire des appels de fonctions ou demander un élément d’une liste quand on utilise le décorateur :

Par ailleurs, les chaînes de caractère ont deux nouvelles méthodes pour supprimer les suffixes et préfixes :

Le pattern matching est enfin arrivé en Python dans la version 3.10. C’est l’équivalent du célèbre switch-case existant en C ou en Java. Je reprends l’exemple de la documentation :

Le Structural Pattern Matching est très puissant en Python car on peut faire du unpacking de paramètres, de l’assignation de variables, rajouter des conditions, je vous recommande de parcourir la PEP636 pour plus de détails.
L’autre évolution syntaxique de Python 3.10 est la possibilité d’utiliser des parenthèses dans une clause with, notamment pour pouvoir utiliser plusieurs lignes :

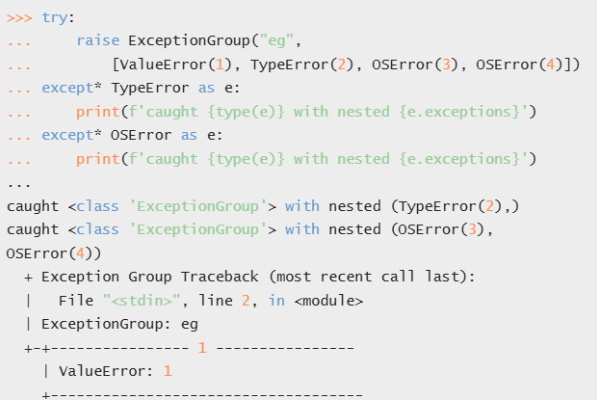
La version 3.11 de Python a vu la création de groupes d’exceptions. On peut désormais envoyer plusieurs exceptions en même temps. Cela peut-être utile pour passer dans plusieurs sections except pour corriger plusieurs problèmes. Voici l’exemple très explicite de la documentation qui permet de comprendre comment s’en servir (encore merci la documentation pour l’exemple) :
L’autre ajout dans les Exceptions qui me semble très utile est la fonction add_note() qui permet d’ajouter des détails lors de l’interception/renvoi d’exception :
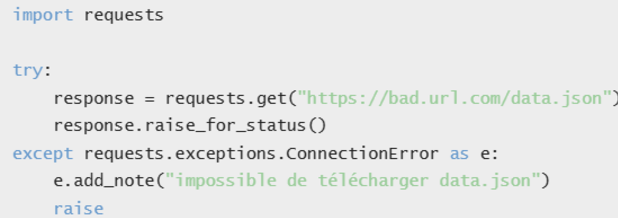
Si vous regardez bien dans les messages d’erreur de Python (dans le traceback notamment), vous verrez désormais que l’interpréteur indique plus précisément où l’erreur se situe dans la ligne et pas seulement dans quelle ligne est l’erreur.
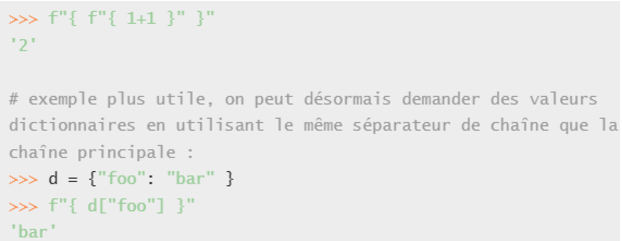
La version 3.12 a vu une petite modification de syntaxe mais qui va simplifier l’utilisation des f-strings : on peut désormais utiliser les mêmes séparateurs de string dans le contexte que celui de la chaîne parente :
Par contre, il n’y a pas de changement syntaxique dans la version 3.13. Il y a tout de même des améliorations dans les messages d’erreurs et l’interpréteur retournera des messages d’erreurs en couleur.
Librairie standardDe moins en moins d’évolutions sont apportées à la bibliothèque standard. Dans la version 3.9 de Python, on note juste l’ajout d’un module zoneinfo pour gérer les fuseaux horaires :

Il y a aussi un nouveau module de tri topologique graphlib.
Dans la version 3.10 de la librairie standard, la fonction zip possède un nouveau paramètre strict qui permet de vérifier que la taille des deux itérateurs en entrée sont identiques.
La version 3.11 de la librairie voit un nouveau module tomllib permettant de lire le format de fichier TOML (mais pas de l’écrire). L’API est similaire à celle du module json :
 Conclusion
Conclusion
On voit que Python est un langage de plus en plus stable, il y a peu de chose à rajouter à sa syntaxe pour améliorer la lisibilité du code. On peut dire la même chose de sa bibliothèque de fonctions standard.
Un gros travail pour améliorer les performances et le nettoyage de la bibliothèque standard a été entrepris et porte petit à petit ses fruits.
Nous avons hâte de profiter des avancées de cette nouvelle version 3.13 dans nos projets.
Ce qui bouge le plus dans Python en ce moment, c’est clairement le typage. Mais ça, ce sera pour un prochain article !
Rédacteurs : Mathilde Pommier et Sébastien Da Rocha
-
10:21
Optimisation simple d’un réseau de neurones
sur Neogeo TechnologiesMaintenant que l’on a appris à entraîner un réseau de neurones (un modèle) et à récupérer / créer des données d’entraînement, faisons un petit point théorique sur l’optimisation de l’entrainement de notre modèle.
Entraîner un modèle est un processus itératif : à chaque itération, le modèle fait une estimation de la sortie, calcule l’erreur dans son estimation (loss), collecte les dérivées de l’erreur par rapport à ses paramètres et optimise ces paramètres à l’aide de la descente de gradient.
Descente de gradient (rappel)La descente de gradient est un algorithme permettant de trouver le minimum d’une fonction.
Approche intuitive :
- De façon intuitive, on peut imaginer être un skieur sur une montagne. On cherche à trouver le point d’altitude la plus basse (donc, un minimum d’altitude).
- L’approche pour trouver ce minimum est de se placer face à la pente descendante et de simplement avancer pendant 5 minutes.
- Donc, 5 minutes plus tard, on se trouve à un autre point et on réitère l’étape précédente.
- Ainsi de suite jusqu’à arriver au point le plus bas.

Approche mathématique :
- La pente de la montagne correspond à la dérivée. Et, la valeur de dérivée correspond à l’inclinaison de la pente en un point donné.
- Donc, une dérivée élevée indique une pente importante. De la même façon, si la dérivée est faible, alors la pente est faible. Finalement, une dérivée nulle correspond à un sol horizontal.
- Pour le signe de la dérivée, on va à l’inverse de la pente. Plus concrètement, une dérivée positive indique une pente qui descend vers la gauche et, une dérivée négative indique une pente qui descend vers la droite.
- Une fois la direction déterminée (gauche ou droite), il reste à déterminer le pas (on se déplace pendant 5 minutes, 10 minutes, … ?). L’idéal serait de faire le pas le plus petit possible pour déterminer si on a trouvé le minimum le plus régulièrement possible. Le problème avec cette approche est le coût calculatoire : le calcul va être très lent. A l’inverse, un pas trop grand nous fera louper le minimum. Il faut donc trouver un juste milieu, ce qui se fait en spécifiant un taux d’apprentissage (learning_rate) que l’on développera par la suite.
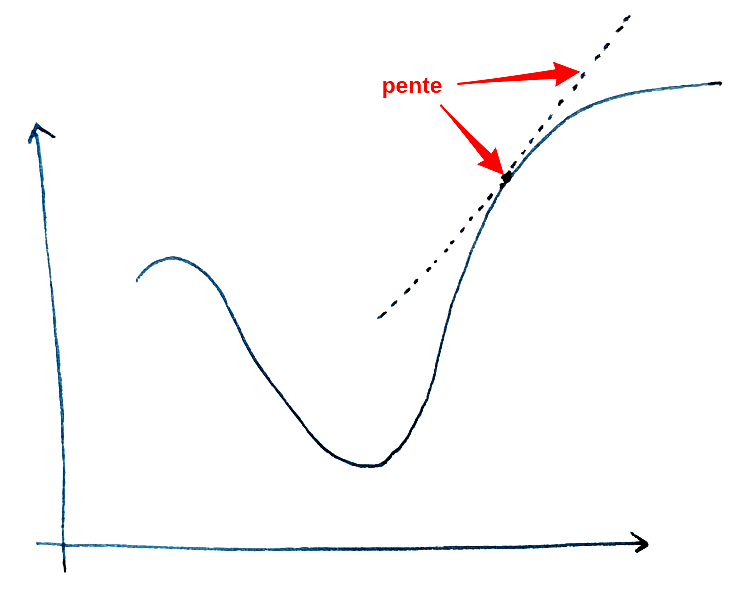
Approches couplées :
- On peut représenter la montagne décrite dans l’approche intuitive par la fonction suivante : f(x) = 2x²cos(x) – 5x. On se restreindra à une étude sur l’intervalle [-5,5].
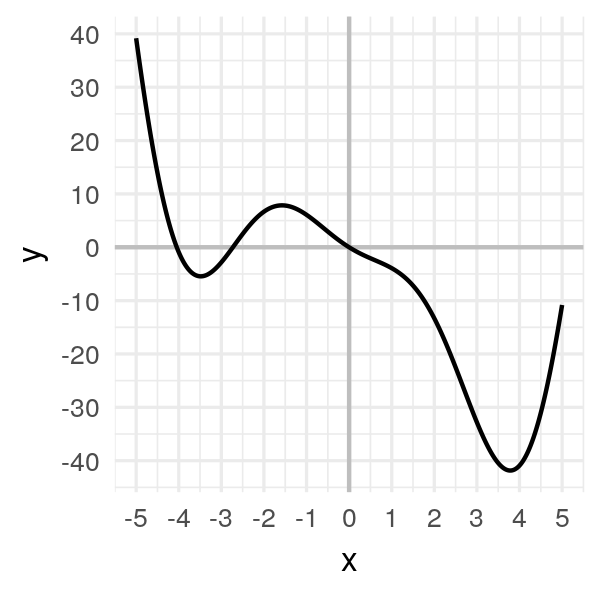
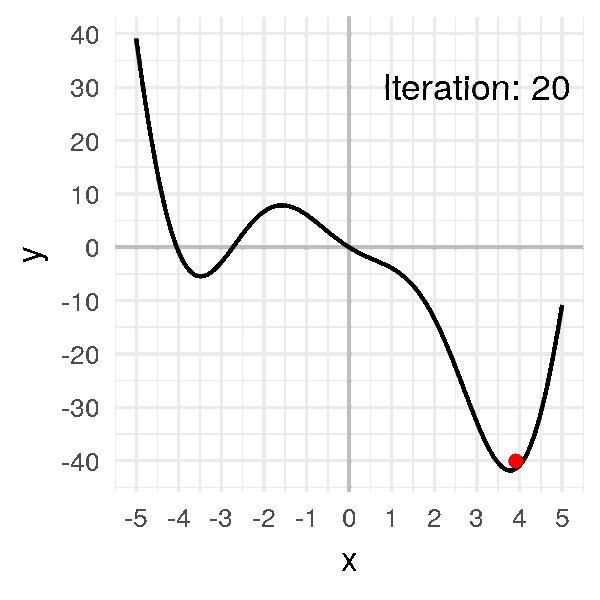
- Visuellement, le minimum est situé vers x ? 3.8 pour une valeur minimale de y ? -42 environ.
- On va donc appliquer la descente de gradient pour trouver ce minimum.
Pour cela, on commence par prendre un premier x (x0) au hasard. x0 = -1 -> f(x0) = 6.08)
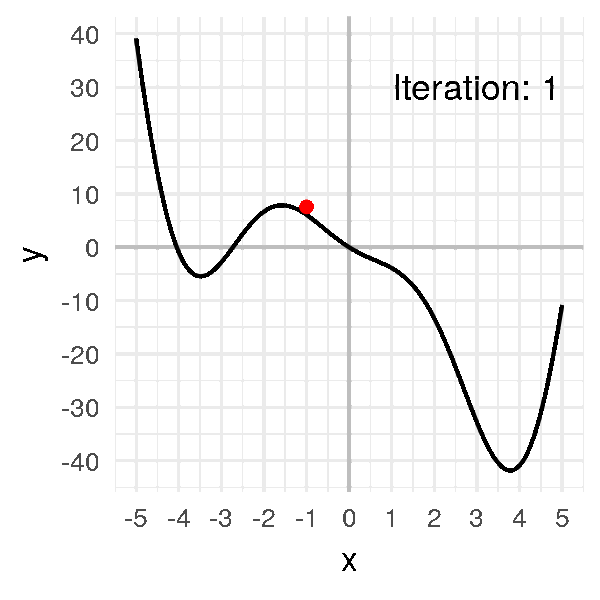
On calcule ensuite la valeur de la pente en ce point (la dérivée f'(x0)). f'(-1) = -2sin(-1)-4cos(-1)-5 ? -5.47827
On « avance » dans la direction opposée à la pente : x1 = x0 ? ?f'(x0) (avec ? = learning_rate = 0.05). x1 ? -0.72609
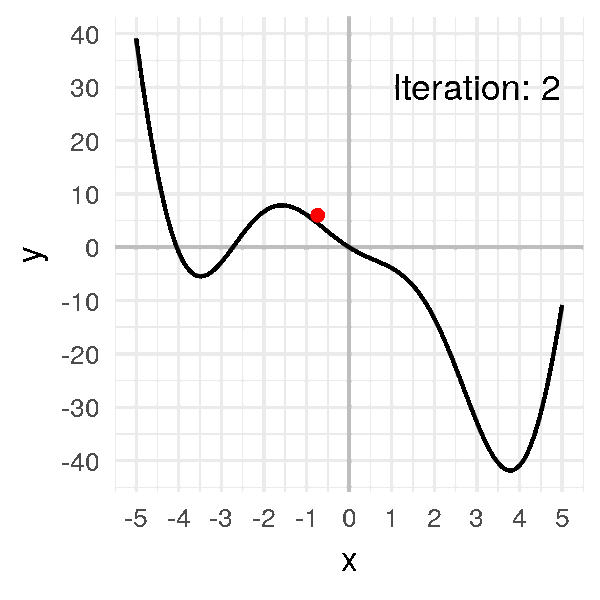
On répète ensuite l’opération jusqu’à trouver xmin. xmin = 3.8
 Hyperparamètres
Hyperparamètres
Ce processus d’optimisation peut être influencé directement par le développeur via le biais des hyperparamètres. Ces hyperparamètres sont des paramètres ajustables qui impactent l’entraînement du modèle et le taux de convergence de ce dernier. Le taux de convergence correspond en combien d’itérations le modèle obtient un résultat optimal.
Pour entraîner le modèle, on dispose de 3 hyperparamètres :
- Nombre d’époques epochs_number : le nombre de fois où l’on parcourt l’ensemble de données
- Taille du lot d’entraînement batch_size : le nombre d’échantillons de données propagés sur le réseau avant la mise à jour des paramètres
- Taux d’apprentissage learning_rate : à quel point les paramètres des modèles doivent être mis à jour à chaque lot/époque. Des valeurs plus petites entraînent une vitesse d’apprentissage lente, tandis que des valeurs plus élevées peuvent entraîner un comportement imprévisible pendant l’apprentissage. (ref. « Descente de gradient »)
Plus concrètement, on possède initialement 2 choses :
- le modèle
- un jeu de données
On commence par découper le jeu de données en sous-jeux de données, tous de même taille. Ces sous-jeux de données sont appelés batch, tous de taille batch_size.
Ensuite, chaque batch est propagé dans le réseau (passé en entrée de celui-ci). Lorsque tous les batch sont passés par le modèle, on a réalisé 1 epoch. Le processus est alors reproduit epochs_number nombre de fois.
Ces étapes peuvent être visualisées sur l’image suivante.
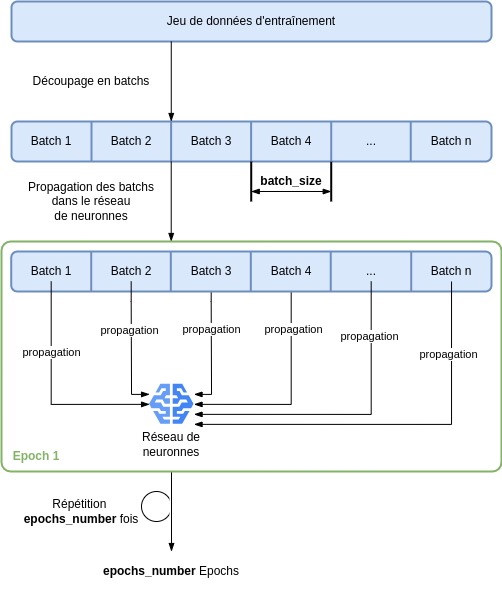 Boucle d’entraînement du modèle
Boucle d’entraînement du modèle
Avant toute chose il faut définir les hyperparamètres. Par exemple :
- learning_rate = 1e-3
- batch_size = 64
- epochs = 5
Une fois les hyperparamètres définis la boucle d’entraînement et d’optimisation du modèle peuvent commencer. Pour rappel, chaque itération de cette boucle est donc une epoch.
De façon plus précise chaque epoch est constituée de 2 phases :
- l’entraînement : itération sur le jeu de données d’entraînement afin de tenter de converger vers des paramètres optimaux.
- la validation : itération sur le jeu de données de validation pour vérifier que le modèle est plus performant et s’améliore.
A la première boucle, comme notre réseau n’a pas encore été entraîné, il a très peu de chance qu’il donne une bonne réponse / un bon résultat. Il faut alors mesurer la distance entre le résultat obtenu et le résultat attendu. Cette distance est calculée à l’aide de la fonction de perte (loss_function).
Le but est donc, au fur et à mesure des itérations de boucle, de minimiser cette loss_function afin d’avoir un résultat obtenu au plus proche du résultat attendu. On notera ici l’utilité de la descente de gradient qui, comme expliqué précédemment, est un algorithme permettant de trouver le minimum d’une fonction, ici, la loss_function.
L’optimisation consiste donc à mettre à jour les paramètres à chaque boucle pour minimiser cette fonction de perte. Cette optimisation est encapsulée dans un objet optimizer qui est appliqué sur le modèle. Ce dernier prend donc en entrée les hyperparamètres du modèle. Dans la boucle d’entrainement, l’optimisation est plus précisément réalisée en 3 étapes :
- Appel à fonction optimizer.zero_grad() : réinitialisation des gradients des paramètres du modèle. Par défaut, les gradients s’additionnent ; pour éviter le double comptage, nous les mettons explicitement à zéro à chaque itération.
- Appel à la fonction loss.backward() : rétropropagation de la prédiction de perte (loss).
- Appel à la fonction optimizer.step() : ajustement des paramètres par les gradients collectés lors de la rétropropagation.
Nous avons révisé comment entraîner un modèle de données en introduisant les concepts de hyperparamètres et touché du doigt l’importance d’un bon optimiseur.
La prochaine fois nous vous proposerons un TP pour coder notre optimiseur et étudier quelques uns des optimiseurs fournis dans pytorch.
Rédacteurs : Mathilde Pommier et Sébastien Da Rocha
-
8:38
Naviguer dans l’Ère des Tuiles Vectorielles : Techniques et Applications
sur Neogeo TechnologiesC’est quoi une tuile ?Pour diffuser des données spatiales sur une carte, il existe différents formats de données dont celui de la tuile vectorielle qui apporte de nouvelles possibilités d’affichage de données (rapidité d’accès à la donnée, facilité de modification du style, interaction directe des utilisateurs avec les objets).
En effet, une carte numérique peut théoriquement afficher des données à n’importe quelle échelle et à n’importe quel endroit, mais cette flexibilité peut poser des problèmes de performance.
La mosaïque de tuiles améliore la vitesse et l’efficacité d’affichage :
- En limitant les échelles disponibles. Chaque échelle est deux fois plus détaillée que la précédente.
- En utilisant une grille fixe. Les zones que l’on souhaite afficher sont composées de collections de tuiles appropriées.
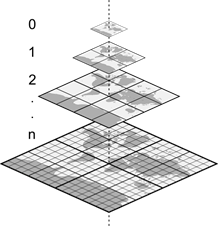
La plupart des systèmes de tuiles commencent avec une seule tuile englobant le monde entier, appelée « niveau de zoom 0 », et chaque niveau de zoom suivant augmente le nombre de tuiles par un facteur de 4, en doublant verticalement et horizontalement.
Coordonnées des tuilesChaque tuile d’une carte en mosaïque est référencée par son niveau de zoom, sa position horizontale et sa position verticale. Le schéma d’adressage couramment utilisé est XYZ.
Voici un exemple au zoom 2 :
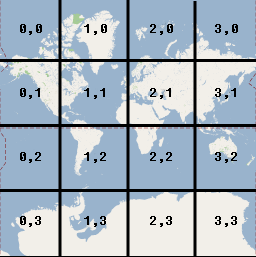
On va récupérer la tuile à l’aide de l’adressage XYZ suivant :
http://server/{z}/{x}/{y}.formatPar exemple, vous pourrez voir la tuile image de l’Australie à l’adresse suivante, c’est le même principe pour les tuiles vectorielles : [https:]]
Principe d’une tuile vectorielleLes tuiles vectorielles ressemblent aux tuiles raster, mais à la place d’une image, elles contiennent des données permettant de décrire les éléments qui la composent avec des tracés vectoriels. Au lieu d’avoir des ensembles de pixels, il y a donc des ensembles de coordonnées de points, auxquels on peut associer plusieurs informations attributaires.
Comme leurs cousines raster, les tuiles vectorielles peuvent être mises en cache, côté serveur et côté navigateur, et permettent de naviguer dans des cartes immenses rapidement, même sur des terminaux légers.
Comment l’utilise-t-on ? Produire des tuiles vectorielles à la volée depuis PostGISIl existe différentes briques pour publier des données à la volée depuis PostGIS, voici notre sélection :
- pg_tileserv => [https:]] : c’est un serveur de tuile codé en GO et produit par Crunchy Data. On va préférer utiliser la version dockerisée dans nos applications => [https:]]
- Martin => [https:]] : très similaire à pg_tileserv, codé en RUST et produit par MapLibre.
- GeoServer : permet également de générer des tuiles vectorielles
Dans le cadre de ce blog, nous resterons sur l’utilisation de pg_tileserv.
pg_tileservPar défaut, pg_tileserv permet de produire des tuiles vectorielles à partir des tables géographiques qui sont dans la base de données.
Tout l’intérêt d’utiliser un outil comme pg_tileserv réside dans la génération de tuiles produites à partir d’une analyse plus fine.
Voici un exemple de requête que l’on peut utiliser pour afficher une donnée cartographique. Cette requête va permettre de simplifier la géométrie en fonction du seuil de zoom et filtrer la donnée en fonction de l’opérateur et de la techno.
CREATE OR REPLACE FUNCTION generate_couvertures_tiles( z integer, x integer, y integer, in_operateur bigint, in_techno character varying) RETURNS bytea LANGUAGE 'plpgsql' COST 100 VOLATILE PARALLEL UNSAFE AS $BODY$ #variable_conflict use_variable begin return ( WITH bounds AS ( SELECT ST_TileEnvelope(z, x, y) AS geom, (CASE when z >= 12 then 0 when z = 11 then 0 when z = 10 then 10 when z = 9 then 100 when z = 8 then 300 when z = 7 then 900 when z = 6 then 1500 when z <= 5 then 3000 ELSE 1 END ) as simplify_tolerance ), mvtgeom AS ( SELECT fid, operateur, date, techno, usage, niveau, dept, filename, ST_AsMVTGeom( ST_Simplify(t.geom,simplify_tolerance), bounds.geom) AS geom FROM couverture_theorique t, bounds WHERE ST_Intersects(t.geom, bounds.geom ) and operateur = in_operateur and techno = in_techno ) SELECT ST_AsMVT(mvtgeom) FROM mvtgeom ); end; $BODY$;Pour appeler cette fonction, on va utiliser l’url formatée de la manière suivante :
https://hostname/tileserv/public.generate_couvertures_tiles/{Z}/{X}/{Y}.pbf?in_operateur=28020&in_techno=3GVous voilà en mesure de faire parler votre imagination pour récupérer les données que vous souhaitez et répondre aux besoins de votre carte.
On peut penser à la création de Cluster, d’analyse thématique, d’agrégation de couche ou que sais-je.
Et la performance dans tout ça ?Toute cette liberté acquise va nous plonger dans des requêtes de plus en plus complexes et donc nous apporter une performance dégradée. Si chaque tuile prend 10 secondes à se générer, l’expérience utilisateur sera mauvaise.
Pour remédier à ce contretemps, rappelons-nous que la tuile vectorielle repose sur une grille fixe. Il est donc possible de générer du cache (mise en cache). Cool ! mais comment fait-on cela ?
C’est parti :
1 – Créer une table de cache de tuiles
CREATE TABLE IF NOT EXISTS tiles_cache ( z integer NOT NULL, x integer NOT NULL, y integer NOT NULL, operateur bigint NOT NULL, techno character varying COLLATE pg_catalog."default" NOT NULL, mvt bytea NOT NULL, CONSTRAINT tiles_pkey PRIMARY KEY (z, x, y, operateur, techno) )2 – Générer le cache
Pour générer le cache, dans un premier temps on récupère les grilles sur lesquelles on a des données. Le seuil de zoom maximum (max_zoom) peut être défini dans la fonction suivante.
CREATE OR REPLACE FUNCTION gettilesintersectinglayer( liste_operateur bigint, liste_techno character varying) RETURNS TABLE(x integer, y integer, z integer) LANGUAGE 'plpgsql' COST 100 VOLATILE PARALLEL UNSAFE ROWS 1000 AS $BODY$ DECLARE tile_bounds public.GEOMETRY; max_zoom INTEGER := 7; BEGIN FOR current_zoom IN 1..max_zoom LOOP FOR _x IN 0..(2 ^ current_zoom - 1) LOOP FOR _y IN 0..(2 ^ current_zoom - 1) LOOP tile_bounds := ST_TileEnvelope(current_zoom, _x, _y); IF EXISTS ( SELECT 1 FROM couverture_theorique WHERE ST_Intersects(geom, tile_bounds) AND operateur = liste_operateur AND techno = liste_techno ) THEN RAISE NOTICE 'Traitement %', current_zoom || ', ' || _x || ', ' || _y; z := current_zoom; x := _x; y := _y; RETURN NEXT; END IF; END LOOP; END LOOP; END LOOP; END; $BODY$;À l’aide de ce tableau de grilles, on va générer l’ensemble des tuiles et les injecter dans la table de cache.
with oper as ( SELECT distinct operateur from couverture_theorique ), techno as ( SELECT distinct techno from couverture_theorique ) insert into tiles_cache_couverture(z, x, y, operateur, techno, mvt) select tile.z, tile.x, tile.y, oper.operateur, techno.techno, generate_couvertures_tiles(tile.z, tile.x, tile.y, oper.operateur, techno.techno) from techno, oper, GetTilesIntersectingLayer(operateur, techno) as tile;3 – Le rendu mixte cache ou requête
Une fois que les tuiles sont insérées dans la table de cache, lorsque l’on va vouloir récupérer la tuile, il va falloir aiguiller la recherche pour que la fonction aille soit récupérer la tuile dans la table de cache ou la générer à la volée.
CREATE FUNCTION couvertures(z integer, x integer, y integer, liste_operateur integer[], liste_techno character varying[]) RETURNS bytea LANGUAGE plpgsql AS $$ #variable_conflict use_variable begin if (z <= 7 and array_length(liste_operateur,1) = 1) then return ( SELECT mvt from tiles_cache_couverture Where tiles_cache_couverture.x=x AND tiles_cache_couverture.y=y AND tiles_cache_couverture.z=z and operateur = any(liste_operateur) and techno = any(liste_techno) ); else return ( WITH bounds AS ( SELECTST_TileEnvelope(z, x, y) AS geom, (CASE when z >= 12 then 0 when z = 11 then 0 when z = 10 then 10 when z = 9 then 100 when z = 8 then 300 when z = 7 then 900 when z = 6 then 1500 when z <= 5 then 3000 ELSE 1 END ) as simplify_tolerance ), mvtgeom AS ( SELECT fid, operateur, date, techno, usage, niveau, dept, filename, public.ST_AsMVTGeom( ST_Simplify(t.geom,simplify_tolerance), bounds.geom) AS geom FROM couverture_theorique t, bounds WHEREST_Intersects(t.geom, bounds.geom ) and operateur = any(liste_operateur) and techno = any(liste_techno) ) SELECTST_AsMVT(mvtgeom) FROM mvtgeom ); end if; end; $$;Maintenant en appelant la couche « couvertures » dans pg_tileserv, sur les zooms les plus petits (inférieur à 8), et donc les plus gourmands pour calculer la simplification géométrique, nous allons utiliser le cache de tuiles. Cependant, lorsque l’on sera relativement proche, on va utiliser la génération des tuiles à la volée car les performances sont bonnes.
Pour les plus ardus, je vous mets un petit bonus. Un exemple de couche cluster générée coté base de données. Le cluster va s’adapter au seuil de zoom, pour clustériser au niveau départemental, puis communal, puis sous forme de cluster naturel (St_ClusterDBSCAN) avec un espacement dynamique pour chaque seuil de zoom, et enfin un affichage par objet quand on est très proche. On aurait pu imaginer un cluster en nid d’abeille que je trouve plus efficace car le problème du cluster de PostGIS, c’est qu’il va être calculé dans l’emprise de chaque tuile. Cela signifie qu’il découpe des clusters de façon arbitraire quand on a une densité importante entre 2 tuiles.
Finalement quels avantages ? Fond de planCREATE FUNCTION cluster_filtres(z integer, x integer, y integer, filtres text[]) RETURNS bytea LANGUAGE plpgsql AS $_$ #variable_conflict use_variable DECLARE query text; result bytea; begin --MISE EN PLACE DES FILTRES if ( z < 9) then --Vue par departement query := ' WITH bounds AS ( SELECT ST_TileEnvelope($1, $2, $3) AS geom ), item_fitler AS ( --On récupère nos données filtrées SELECT distinct t.id FROM table t WHERE ' || filtres || ' ), tot_dept AS ( select code_departement, count(1) as tot_item from departement d INNER JOIN table t ON ST_Intersects(d.geom, t.geom ) INNER JOIN item_fitler ON item_fitler.id = t.id group by code_departement ), mvtgeom AS ( SELECT tot_dept.code_departement, tot_dept.tot_item, ST_AsMVTGeom(ST_PointOnSurface(tot_dept.geom), bounds.geom) AS geom FROM tot_dept INNER JOIN bounds ON ST_Intersects(tot_dept.geom, bounds.geom ) WHERE tot_item is not null ) SELECT ST_AsMVT(mvtgeom) FROM mvtgeom '; --RAISE NOTICE 'Calling query (%)', query; EXECUTE query INTO result USING z, x, y, filtres; return result; elsif ( z <= 10) then --Vue par commune, On ajoute un buffer pour récupérer les items autour de la tuile sans devoir le faire sur la France entière query := ' WITH bounds AS ( SELECT ST_TileEnvelope($1, $2, $3) AS geom ), item_fitler AS ( --On récupère nos données filtrées SELECT distinct t.id FROM table t INNER JOIN bounds ON ST_Intersects(t.geom, ST_Buffer(bounds.geom, 10000) ) WHERE ' || filtres || ' ), tot_com AS ( select insee_com, count(1) as tot_item from commune c INNER JOIN table t ON ST_Intersects(c.geom, t.geom ) INNER JOIN item_fitler ON item_fitler.id = t.id group by insee_com having count(1) > 0 ), mvtgeom AS ( SELECT tot_com.insee_com, tot_com.tot_item, ST_AsMVTGeom(ST_PointOnSurface(tot_com.geom), bounds.geom) AS geom FROM tot_com INNER JOIN bounds ON ST_Intersects(tot_com.geom, bounds.geom ) WHERE tot_item is not null ) SELECT ST_AsMVT(mvtgeom) FROM mvtgeom '; --RAISE NOTICE 'Calling query (%)', query; EXECUTE query INTO result USING z, x, y, filtres; return result; elsif ( z <= 15) then --Vue par cluster query := ' WITH bounds AS ( SELECT ST_TileEnvelope($1, $2, $3) AS geom ), item_fitler AS ( --On récupère nos données filtrées SELECT distinct t.id FROM table t INNER JOIN bounds ON ST_Intersects(t.geom, bounds.geom ) WHERE ' || filtres || ' ), clustered_points AS ( SELECT ST_ClusterDBSCAN(t.geom, eps := (CASE when $1 = 11 then 500 when $1 = 12 then 385 when $1 = 13 then 280 when $1 = 14 then 150 when $1 = 15 then 75 ELSE 1 END ) , minpoints := 1) over() AS cid, t.fid, t.geom FROM table t INNER JOIN item_fitler s ON s.id = t.id group by t.id, t.geom ), mvtgeom AS ( SELECT cid, array_agg(id) as ids, count(1) as tot_item, ST_AsMVTGeom(ST_PointOnSurface(ST_Collect(c.geom)), bounds.geom) AS geom FROM clustered_points c, bounds WHERE ST_Intersects(c.geom, bounds.geom ) group by cid, bounds.geom ) SELECT public.ST_AsMVT(mvtgeom) FROM mvtgeom '; RAISE NOTICE 'Calling query (%)', query; EXECUTE query INTO result USING z, x, y, filtres; return result; else --vue par objet query := ' WITH bounds AS ( SELECT ST_TileEnvelope($1, $2, $3) AS geom ), item_fitler AS ( --On récupère nos données filtrées SELECT distinct t.id FROM table t INNER JOIN bounds ON ST_Intersects(t.geom, bounds.geom ) WHERE ' || filtres || ' ), mvtgeom as ( SELECT ST_AsMVTGeom(t.geom, bounds.geom) AS geom, t.id FROM item_fitler t , bounds WHERE ST_Intersects(t.geom, bounds.geom ) ) SELECT ST_AsMVT(mvtgeom) FROM mvtgeom '; EXECUTE query INTO result USING z, x, y, filtres; return result; end if; end; $_$;Dans les choix des fonds de plan, les avantages sont multiples.
On peut assez facilement personnaliser un fond de plan en modifiant les paramètres d’affichage que l’on souhaite utiliser pour chaque élément. Pour faire cela, on peut s’appuyer sur des fichiers de style comme ceux proposés par Etalab : [https:]] .
Si l’on héberge soit même les fichiers de style, on peut les modifier pour choisir le style des éléments. Voici à quoi ressemble le paramétrage d’un élément issu d’une tuile vectorielle :
{ "id": "landuse-commercial", "type": "fill", "source": "openmaptiles", "source-layer": "landuse", "filter": [ "all", ["==", "$type", "Polygon"], ["==", "class", "commercial"] ], "layout": { "visibility": "visible" }, "paint": { "fill-color": "hsla(0, 60%, 87%, 0.23)" } },Il est par exemple possible d’extruder les bâtiments si on souhaite obtenir un rendu 3D
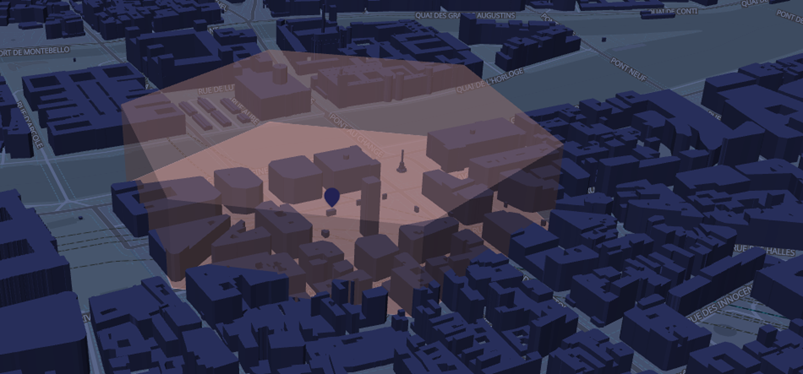
L’affichage vectorielle permet également d’afficher les libellés / icônes toujours dans le bon sens de lecture.
Choix de l’ordre d’affichage des couchesEnsuite il est intéressant de rappeler qu’il est possible de modifier l’ordre d’affichage des couches qui sont issues du fond de plan et des couches métiers, ce qui n’est pas possible avec les fonds de plan de type WTMS. On peut donc faire ressortir les libellés des communes sur une couche métier.
 Couche vectorielle
Couche vectorielle
La couche étant vectorielle, il est également possible de récupérer des attributs de celle-ci.
Outil de d’édition du styleIl existe plusieurs outils permettant de modifier le style des données vectorielles. Cependant je vous conseille maputnik qui est très complet et accessible => [https:]]
ConclusionEn conclusion, les tuiles vectorielles représentent une avancée significative dans la diffusion et l’affichage de données spatiales, et permettent de créer des applications cartographiques avancées. Encore faut-il les intégrer dans des outils robustes et des méthodologies performantes, afin de répondre aux besoins croissants de précision et de réactivité. La technologie des tuiles vectorielles est essentielle pour le futur de la cartographie numérique, offrant un équilibre entre performance, flexibilité et interactivité.
Pistes futures ?L’authentification et les rôles à travers pg_tileserv. On pourrait imaginer dans un futur blog, comment fusionner l’authentification via un token, le service pg_tileserv et la sécurité de PostgreSQL avec le Row Level Sécurity. Cela permettrait de gérer les droits au niveau de l’objet et nativement dans PostgreSQL.
Rédacteur : Matthieu Etourneau
-
16:45
Neogeo est ravie d’annoncer la date de ...
sur Neogeo TechnologiesNeogeo est ravie d’annoncer la date de son tout premier séminaire dédié à OneGeo Suite, la solution web open source permettant de partager, diffuser et valoriser les données cartographiques d’un territoire.
Il s’agit d’une opportunité unique aussi bien pour les utilisateurs, que pour ceux qui contribuent aux développements mais aussi les passionnés qui veulent découvrir la solution, les dernières fonctionnalités mises en œuvre, d’approfondir leurs connaissances, et de se connecter avec les différents membres de la communauté.
Cet événement promet d’être un véritable catalyseur pour ceux qui souhaitent exploiter tout le potentiel OneGeo Suite.
Ce séminaire a pour but de :- Présenter les nouvelles fonctionnalités : Découvrez les innovations et mises à jour récentes de OneGeo Suite,
- Favoriser les échanges : Échangez avec les autres utilisateurs, les développeurs, et experts du domaine,
- Inspirer et motiver : Bénéficier et partager de retours d’expériences des utilisateurs et des cas d’utilisation inspirants,
- Fournir des échanges approfondis : Au travers d’ateliers sur les nouveaux usages, services, connecteurs, la visualisation des données, les performances et limites actuelles des plateformes OGS…
 Pourquoi Participer ?
Pourquoi Participer ?
Participer à ce séminaire vous permettra de :
- Accéder à des informations exclusives : Soyez parmi les premiers à découvrir les dernières fonctionnalités et la road map de la solution,
- Améliorer vos connaissances : Grâce aux présentations et aux ateliers,
- Réseauter avec les membres de la communauté du secteur : Élargissez votre réseau et partagez des idées avec d’autres utilisateurs et experts.
- Obtenir des réponses à vos questions : Interagissez directement avec les développeurs et les formateurs de la solution.
Pour participer à ce séminaire exceptionnel, inscrivez-vous dès maintenant –> lien.
Les inscriptions sont gratuites et obligatoires, ne tardez pas à réserver votre place.
En conclusionNe manquez pas cette occasion, en amont des Géodatadays 2024, afin de consolider vos connaissances et de renforcer votre utilisation de OneGeo Suite. Rejoignez-nous pour une journée riche en apprentissage, en échanges et en inspiration.
Nous sommes impatients de vous accueillir et de partager ce premier séminaire OneGeo Suite à vos côtés.
L’équipe OneGeo Suite
-
10:17
Mon premier réseau de neurones
sur Neogeo TechnologiesPour mieux comprendre l’article sur les réseaux de neurones, cette semaine nous vous proposons de coder un petit réseau de neurones de façon à mieux comprendre ce que sont les poids, le feed forward et les autres notions introduites dans l’article précédent.
Nous allons réaliser un réseau de neurones à 1 neurone et essayer de lui faire prédire des données placées sur une droite. Cet exercice est trivial, on peut le résoudre sans utiliser d’IA mais restons un peu humble pour commencer.
Préparation du projetUtilisons Jupyter qui reste l’outil de prédilection pour tester et développer une IA.
# On crée un environnement virtuelle python, et on l'active python3 -m venv test_ia cd test_ia . bin/activate # On installe jupyter et on le lance pip install jupyter jupyter notebookCette dernière commande ouvrira Jupyter dans votre navigateur.
Vous pourrez aller dans “File” -> “New” -> “Notebook” pour créer un nouveau fichier et copier/tester notre programme.
De quoi avons-nous besoin ?
Numpy, c’est une bibliothèque Python optimisée pour la gestion de listes.
NB : il y a un point d’exclamation en début de ligne, ce qui signifie que la commande sera lancée dans le shell. Ici elle permettra d’installer les dépendances dans notre environnement virtuel.
!pip install numpy import numpy as np Requirement already satisfied: numpy in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (1.26.4)Pandas, la bibliothèque Python star de la data-science, basée elle-même sur Numpy.
!pip install pandas import pandas as pd Requirement already satisfied: pandas in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (2.2.2) Requirement already satisfied: numpy>=1.23.2 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from pandas) (1.26.4) Requirement already satisfied: python-dateutil>=2.8.2 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from pandas) (2.9.0.post0) Requirement already satisfied: pytz>=2020.1 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from pandas) (2024.1) Requirement already satisfied: tzdata>=2022.7 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from pandas) (2024.1) Requirement already satisfied: six>=1.5 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas) (1.16.0)Pytorch, une des principales bibliothèques Python pour faire des réseaux de neurones. Ici on n’installe que la version CPU, la version de base fonctionne avec CUDA, la bibliothèque de calcul scientifique de Nvidia, mais celle-ci prend beaucoup de place sur le disque dur, restons frugaux.
!pip3 install torch --index-url [https:] import torch import torch.nn.functional as F Looking in indexes: [https:] Collecting torch Downloading [https:] (190.4 MB) [2K [38;2;114;156;31m??????????????????????????????????????[0m [32m190.4/190.4 MB[0m [31m26.4 MB/s[0m eta [36m0:00:00[0mm eta [36m0:00:01[0m[36m0:00:01[0m [?25hCollecting filelock Downloading [https:] (11 kB) Requirement already satisfied: typing-extensions>=4.8.0 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from torch) (4.12.2) Collecting sympy Downloading [https:] (5.7 MB) [2K [38;2;114;156;31m????????????????????????????????????????[0m [32m5.7/5.7 MB[0m [31m57.2 MB/s[0m eta [36m0:00:00[0m MB/s[0m eta [36m0:00:01[0m [?25hCollecting networkx Downloading [https:] (1.6 MB) [2K [38;2;114;156;31m????????????????????????????????????????[0m [32m1.6/1.6 MB[0m [31m58.6 MB/s[0m eta [36m0:00:00[0m [?25hRequirement already satisfied: jinja2 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from torch) (3.1.4) Collecting fsspec Downloading [https:] (170 kB) [2K [38;2;114;156;31m??????????????????????????????????????[0m [32m170.9/170.9 kB[0m [31m18.5 MB/s[0m eta [36m0:00:00[0m [?25hRequirement already satisfied: MarkupSafe>=2.0 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from jinja2->torch) (2.1.5) Collecting mpmath>=0.19 Downloading [https:] (536 kB) [2K [38;2;114;156;31m??????????????????????????????????????[0m [32m536.2/536.2 kB[0m [31m42.9 MB/s[0m eta [36m0:00:00[0m [?25hInstalling collected packages: mpmath, sympy, networkx, fsspec, filelock, torch Successfully installed filelock-3.13.1 fsspec-2024.2.0 mpmath-1.3.0 networkx-3.2.1 sympy-1.12 torch-2.3.1+cpuMatplotlib, pour faire de jolis graphiques.
Création d’un jeu de données simple!pip install matplotlib from matplotlib import pyplot as plt %matplotlib inline Collecting matplotlib Downloading matplotlib-3.9.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (8.3 MB) [2K [38;2;114;156;31m????????????????????????????????????????[0m [32m8.3/8.3 MB[0m [31m44.0 MB/s[0m eta [36m0:00:00[0mm eta [36m0:00:01[0m0:01[0m:01[0m [?25hCollecting contourpy>=1.0.1 Using cached contourpy-1.2.1-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (306 kB) Collecting cycler>=0.10 Using cached cycler-0.12.1-py3-none-any.whl (8.3 kB) Collecting fonttools>=4.22.0 Downloading fonttools-4.53.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (4.9 MB) [2K [38;2;114;156;31m????????????????????????????????????????[0m [32m4.9/4.9 MB[0m [31m57.3 MB/s[0m eta [36m0:00:00[0m31m72.7 MB/s[0m eta [36m0:00:01[0m [?25hCollecting kiwisolver>=1.3.1 Using cached kiwisolver-1.4.5-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.4 MB) Requirement already satisfied: numpy>=1.23 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from matplotlib) (1.26.4) Requirement already satisfied: packaging>=20.0 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from matplotlib) (24.1) Collecting pillow>=8 Using cached pillow-10.3.0-cp311-cp311-manylinux_2_28_x86_64.whl (4.5 MB) Collecting pyparsing>=2.3.1 Using cached pyparsing-3.1.2-py3-none-any.whl (103 kB) Requirement already satisfied: python-dateutil>=2.7 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from matplotlib) (2.9.0.post0) Requirement already satisfied: six>=1.5 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0) Installing collected packages: pyparsing, pillow, kiwisolver, fonttools, cycler, contourpy, matplotlib Successfully installed contourpy-1.2.1 cycler-0.12.1 fonttools-4.53.0 kiwisolver-1.4.5 matplotlib-3.9.0 pillow-10.3.0 pyparsing-3.1.2 from random import randint, seedPour le principe de la démonstration, on va créer un jeu de données parfaitement linéaire f(x) = 2*x
On pourra contrôler facilement que les prévisions du réseau sont bien sur cette droite.
data = pd.DataFrame(columns=["x", "y"], data=[(x, x*2) for x in range(10)], ) data["x"] = data["x"].astype(float) data["y"] = data["y"].astype(float) data.plot.scatter(x="x", y="y") <Axes: xlabel='x', ylabel='y'>
data Démarrage
Démarrage
Préparons quelques variables pour le projet. Nous initions aussi le modèle M, si vous voulez tester des évolutions dans le code, relancez cette cellule pour réinitialiser le modèle.
Algorithme général# On fait en sorte que pytorch tire toujours la même suite de nombres aléatoires # Comme ça vous devriez avoir les mêmes résultats que moi. torch.manual_seed(1337) seed(1337) # Je crée mon réseau d’un neurone avec une valeur aléatoire M = torch.randn((1,1)) # On active le calcul du gradient dans le réseau M.requires_grad = True print(M) # On garde une liste de pertes pour plus tard losses = list() tensor([[-2.0260]], requires_grad=True)Pour que notre réseau apprenne des données, il nous faut une phase de feed forward et une back propagation.
En quoi ça consiste ?
Prenons un exemple dans notre jeu de données, la ligne x=9 et y=18.
# on prend un échantillon ix = randint(0, len(data)-1) # Indice de X x = data.iloc[ix]["x"] y = data.iloc[ix]["y"] print(f"{x=},{y=}") x=9.0,y=18.0La phase de feed forward consiste à demander au modèle ce qu’il prévoit comme donnée pour x=9. On utilise l’opérateur “@” qui multiplie des tenseurs.
X = torch.tensor([x]) y_prevision = M @ X --------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) Cell In[10], line 2 1 X = torch.tensor([x]) ----> 2 y_prevision = M @ X RuntimeError: expected scalar type Float but found DoubleAh oui, Numpy convertit notre Float (32bits) en Double (64 bits) en interne. Transformons notre tenseur en Float dans ce cas.
X = torch.tensor([x]).float() y_prevision = M @ X print(f"{y_prevision=}") y_prevision=tensor([-18.2339], grad_fn=<MvBackward0>)Notre modèle prédit donc “-18.2339”, alors que notre y vaut 18.
C’est normal puisque l’on a initialisé notre modèle avec des valeurs complètement aléatoires.
Il nous faut donc corriger notre modèle, mais d’abord nous allons utiliser une fonction de perte, ici l1_loss pour voir à quel point on se trompe.
Y = torch.Tensor([y]) loss = F.l1_loss(y_prevision, Y) print("loss", loss.item()) loss 36.23392868041992On se trompe de 36 (c’est à dire 18 – 18,23), c’est beaucoup.
Pour corriger le modèle nous allons faire la phase de back propagation (ou rétro-propagation ou backward pass).
Nous allons demander à Pytorch de calculer l’impact des poids du modèle dans cette décision. C’est le calcul du gradient. Cette opération, sans être très compliqué car il s’agit de dériver toutes les opérations effectuées, mérite un article à part entière et ne sera pas traitée dans celui-ci.
# backward pass M.grad = None loss.backward()Attention, il faut toujours réinitialiser le gradient avant de lancer le back propagation.
Maintenant que nous avons un gradient, nous allons mettre à jour notre modèle en y appliquant une fraction de ce tenseur.
Pourquoi qu’une fraction ? Ici nous avons une fonction linéaire très simple à modéliser. En appliquant le gradient, on corrigerait tout de suite le modèle. Le problème est que, dans la vraie vie, la situation n’est jamais aussi simple. En réalité, les données sont hétérogènes et donc, appliquer le gradient à une donnée améliore le résultat pour celle-ci mais donnerait un très mauvais gradient pour les autres données.
Nous allons donc appliquer une fraction du gradient et essayer de trouver le meilleur compromis. On pourra déterminer celui-ci grâce à la fonction de perte.
Nous allons donc appliquer une modification de 0,1 fois le gradient sur notre modèle, ce 0.1 s’appelle le learning rate.
# update lr = 0.1 M.data += -lr * M.grad print(f"{M.grad=}, {M.data=}") M.grad=tensor([[-9.]]), M.data=tensor([[-1.1260]])Nous verrons lors d’un autre article comment choisir le learning rate.
Voyons ce que ça donne :
# forward pass y_prevision = M @ X print(f"{y_prevision=}") y_prevision=tensor([-10.1339], grad_fn=<MvBackward0>)Pas si mal, on passe de -18 à -10. Ça reste très mauvais mais on n’a exécuté qu’une seule fois notre cycle feed forward / back propagation.
Faisons en sorte d’appeler plusieurs fois notre algorithme.
for i in range(1000): # on prend un échantillon ix = randint(0, len(data)-1) x = data.iloc[ix]["x"] y = data.iloc[ix]["y"] # forward pass y_prevision = M @ torch.tensor([x]).float() loss = F.l1_loss(y_prevision, torch.Tensor([y])) # backward pass M.grad = None loss.backward() # update lr = 0.01 M.data += -lr * M.grad # stats losses.append(loss.item())Voyons ce que donne notre prévision dans un graphique. En rouge les points de données, en bleu la courbe de prévision.
ax = data.plot.scatter(x="x", y="y", color="red") prevision = pd.DataFrame(np.arange(10), columns=["x"]) m = M.detach() prevision["y_prevision"] = prevision["x"].apply(lambda x: (m @ torch.tensor([float(x)]))[0].numpy()) #torch.tensor([4.]) prevision.plot(y="y_prevision", ax=ax, x="x") <Axes: xlabel='x', ylabel='y'>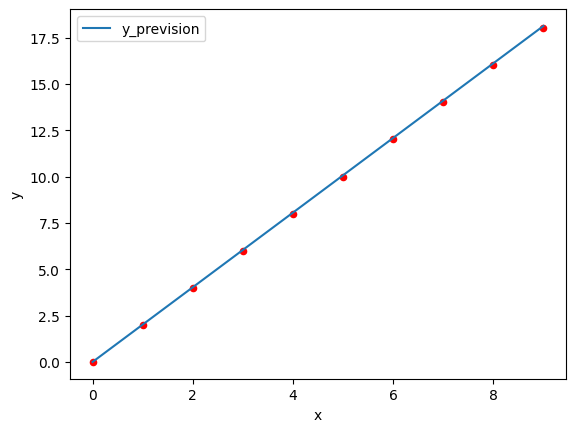
Et si nous sortons du cadre des données avec un X de 2000 ?
m @ torch.tensor([float(2000)]) tensor([4028.0156])Pas mal, on devrait avoir 4000 mais c’est déjà mieux.
Et par rapport à nos données de base ?
prevision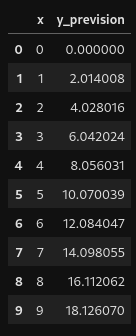
Bon, que ce passe-t-il ? Regardons un peu l’évolution de notre perte en fonction des itérations ?
pd.DataFrame(losses, columns=["loss"]).plot() <Axes: >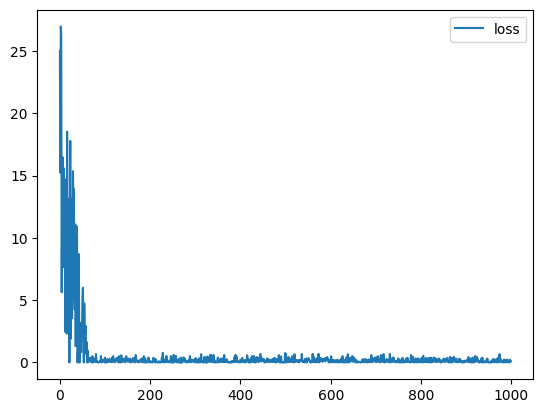
On voit que les pertes sont importantes pendant 100 itérations et ensuite elles se stabilisent un peu entre 0 et 0.8.
Est-ce qu’on peut améliorer ça ? Oui très facilement, nous verrons cela ensemble lors d’un prochain article.
ConclusionNous avons appris comment créer un modèle et faire un apprentissage avec les phases de feed forward et back propagation. Ensuite nous avons vu que le learning rate et gradient permettent de corriger le modèle petit à petit. En faisant quelques centaines d’itérations nous avons un bon modèle de régression.
J’espère que cette petite introduction vous a donné envie d’aller plus loin.
Rédacteur : Sébastien Da Rocha
-
9:41
NEOGEO et SOGEFI allient leur catalogue de données et leur SIG pour les besoins de leurs utilisateurs
sur Neogeo TechnologiesUne solution mutualisée donnant une gamme complète d’outils pour répondre aux besoins cartographiques des acteurs publics.
Chez NEOGEO, nous avons décidé de nous associer à SOGEFI pour offrir à nos utilisateurs toute la puissance des données. Grâce à cette collaboration, la plateforme OneGeo Suite de NEOGEO est enrichie par les applications métier Mon Territoire de SOGEFI.
Ensemble, nous proposons une solution mutualisée qui fournit une gamme complète d’outils adaptés aux besoins des administrateurs, des gestionnaires de données, des services techniques, des élus et du grand public.


Une réponse adaptée à chaque usage cartographique !
La combinaison de nos deux solutions offre une réponse précise et adaptée aux divers acteurs d’un territoire. Elle repose sur un socle commun robuste solide, structuré et évolutif centré sur les données, ce qui permet de créer un cycle vertueux de gestion de la donnée pour l’ensemble des acteurs de la structure, au bénéfice de leur territoire. Le développement de nos solutions respectives est axé sur l’expérience utilisateur, chaque outil étant conçu pour répondre aux besoins spécifiques des différents profils d’acteurs impliqués.
OneGeo Suite propose aux administrateurs une gamme de modules pour gérer les référentiels métiers et satisfaire aux exigences de publication et de partage des données Open Data. OGS valorise ces données grâce à des modes de publication et de reporting (Dataviz) adaptés aux besoins des utilisateurs et de leurs publics, qu’il s’agisse de partenaires ou du grand public. Avec son module Explorer pour la recherche et la consultation intuitive des jeux de données, son module Maps pour les fonctionnalités cartographiques avancées, et son module Portal pour un portail collaboratif, OneGeo Suite offre une solution complète et innovante. Cette suite est fondée sur des principes de mutualisation et de co-construction d’outils open source.
Mon Territoire propose une gamme complète d’outils métiers prêts à l’emploi pour les services techniques et les collectivités. Couvrant de nombreuses compétences, la gamme Mon Territoire utilise une sélection de données Open Data pour assister les agents responsables de l’urbanisme, de l’habitat, des réseaux, de la voirie et du développement économique.
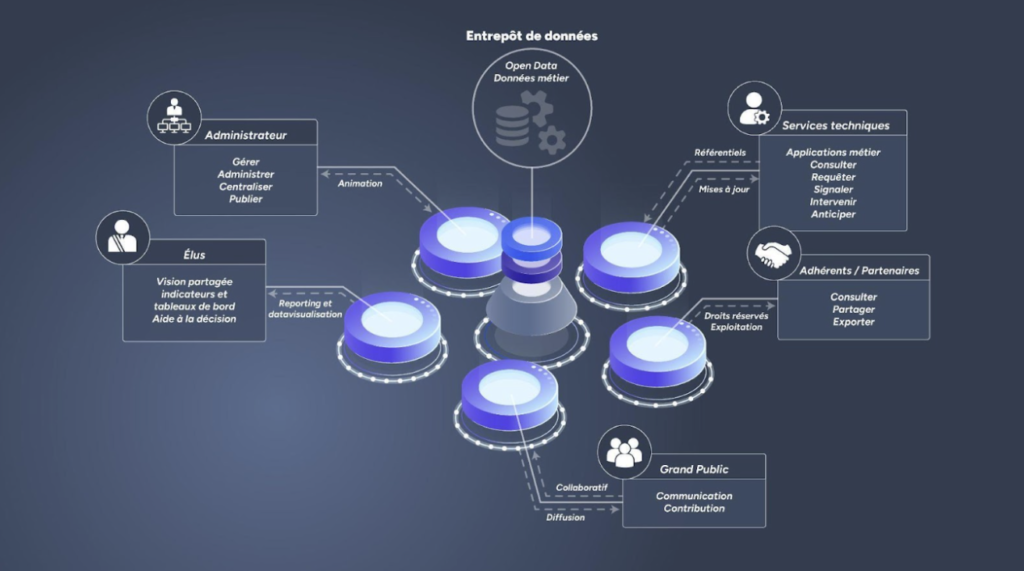
Schéma décrivant les usages et les rôles au travers des applications fusionnées OneGeo Suite et Mon Territoire
Un choix stratégique pour nos entreprises, une décision évidente pour nos clients
Laurent Mer – directeur général de NEOGEO
« La gamme d’outils clé en main proposée par SOGEFI permet de compléter notre solution OneGeo Suite de catalogage et de diffusion de données par des modules métiers opérationnels directement accessibles aux utilisateurs de la plateforme.L’interopérabilité des deux solutions permet de mutualiser l’accès aux référentiels cartographiques et aux bases de données métier et le partage des droits sur les différents jeux de données offre la possibilité de définir une véritable stratégie de gouvernance des données. Enfin l’accès aux API Opendata proposées par SOGEFI et alimentées en temps réel permet d’enrichir l’offre de référentiels proposés dans le catalogue de données mis à disposition ».
Mathilde de Sulzer Wart – directrice générale de SOGEFI
« OneGeo Suite est la réponse idéale pour les structures départementales et régionales qui disposent d’un socle important de données. Les administrateurs de ces dernières disposent alors de tous les outils pour gérer ces importants volumes de données du catalogage à sa publication pour ses adhérents. OneGeo Suite, plateforme complètement Open Source, est totalement interopérable avec notre gamme Mon Territoire, elle apporte une vraie valeur ajoutée pour la diffusion et la valorisation de l’ensemble des données ainsi consolidées au fil du temps par les services et permet à l’IDG la mise en place d’un cycle vertueux de l’information pour l’ensemble de ces acteurs. »
L’un des avantages de notre collaboration est de pouvoir déployer rapidement des solutions prêtes à l’emploi grâce à un accompagnement spécifique par métiers et compétences. Une équipe pluridisciplinaire est mobilisée pour le déploiement de notre offre commune et le planning établi peut mobiliser différentes équipes en parallèle pour le bon avancement du projet. Chacun sur son métier, NEOGEO et SOGEFI ont à cœur de vous accompagner et de vous conseiller sur vos problématiques. Chacun mène une veille permanente sur l’Opendata ainsi que sur les technologies du domaine et vous propose de vous en faire bénéficier au travers des solutions et des services que nous mettons en place depuis plusieurs années. Construit autour de communautés d’utilisateurs, nos deux solutions sont reconnues sur le marché depuis de nombreuses années, elles sont au service de nombreux usagers qui nous font part de leurs besoins d’évolution et idées pour les versions à venir notamment au travers d’espace d’échanges dédiés (forum, page web dédié…). Ces remontées d’informations sont précieuses pour nos équipes afin de définir les feuilles de route de nos produits.
Ce sont bien les produits qui s’adaptent aux besoins des utilisateurs et non les utilisateurs qui s’adaptent au produit.
Le meilleur des arguments, le témoignage de nos clients
Guillaume MALATERRE, directeur Adjoint à l’Informatique et responsable du pôle Gouvernance et Exploitation des Données du SIDEC« Les outils métiers de SOGEFI sont tout à fait en adéquation avec les besoins et les usages des collectivités de toutes tailles dans leurs tâches du quotidien. Les partenariats existants avec Géofoncier sont un vrai plus pour les secrétaires de mairie. Nous pouvons également répondre aux besoins des services techniques des collectivités, des syndicats des eaux, d’assainissement. Les solution OneGeo Suite va nous permettre de maitriser nos données et de les mettre à disposition de nos utilisateurs et partenaires de manière simple et structurée (flux, datavisualisation, carte Web).? Le tout parfaitement intégré à notre SI et répondant à nos exigences en termes d’administration des comptes utilisateurs et des droits sur les données. »

Boris RUELLE, responsable Service de l’Information Géographique de la collectivité territoriale de Guyane« Depuis une douzaine d’année, la plateforme territoriale Guyane-SIG favorise l’accessibilité des données spatiales et la démocratisation de leurs usages sur la Guyane. En 2020, la Collectivité Territoriale de Guyane a initié un travail de modernisation de l’ensemble des composants fonctionnels en deux étapes :
-
-
- Nous avions besoins d’un outil performant pour proposer une lecture facilitée de l’information foncière pour l’ensemble de nos partenaires. Les attentes étaient fortes et avec Mon Territoire Carto, nous avons pu bénéficier rapidement d’un outil ergonomique mobilisant de nombreuses données en Opendata que nous avons pu compléter par des productions endogènes.
- Puis les efforts se sont portés sur les outils collaboratifs de partage et de valorisation des données dans le respect des standards. Avec la suite OneGeo, nos partenaires peuvent désormais publier en quelques clics leurs données.
-
L’accompagnement nous permet également de proposer régulièrement à nos partenaires des webinaires de présentation des évolutions fonctionnelles.
Le partenariat Neogeo et Sogefi qui a commencé avec le projet Géofoncier, le portail de l’Ordre des Géomètres-Experts
NEOGEO et SOGEFI sont ravis de poursuivre et renforcer leur partenariat déjà éprouvé depuis plusieurs années auprès du Portail Géofoncier. Ce portail porté par l’Ordre des Géomètres-Expert est aujourd’hui une référence nationale dans la valorisation de l’information foncière. L’ambition portée par Géofoncier a su s’appuyer sur la complémentarité des expertises de chacun. Les différents projets ont nécessité un travail de coordination et d’enrichissement mutuel des pratiques et technologies mobilisées par les deux sociétés dans un objectif commun. Nos équipes se connaissent, elles ont l’habitude de travailler ensemble et savent mobiliser les ressources en interne pour assurer une couverture élargie des compétences nécessaires aux projets.
Patrick Bezard-Falgas, Directeur général de Géofoncier« Depuis de nombreuses années, NEOGEO et SOGEFI sont nos partenaires privilégiés chez Géofoncier. Leurs expertises complémentaires et incontestées dans le domaine de la diffusion et de la valorisation de la donnée cartographique, associée à leurs écoutes attentives de nos besoins, font de NEOGEO et SOGEFI un groupement pertinent et essentiel à notre réussite. Leur engagement fort au quotidien à fournir en concertation des solutions complètes et pérennes ont grandement contribué au succès de Géofoncier. Nous sommes reconnaissants de pouvoir compter sur ces équipes d’experts aussi fiables et compétentes pour nous accompagner dans notre croissance continue.
NEOGEO possède une expertise avérée dans la mise en œuvre de solutions innovantes de partage, de valorisation et de visualisation de données géographiques auprès d’un large public. NEOGEO développe et met en place depuis sa création en 2008 des infrastructures de données géographiques et des plateformes open-source. NEOGEO a intégré en 2022 le groupe Geofit (leader français dans l’acquisition de données spatiales), permettant ainsi de renforcer ses compétences (équipe de 40 collaborateurs) et ses références (une cinquantaine de plateformes cartographiques majeures déployées en France et à l’étranger). C’est aussi la fusion des savoirs faires technologiques des deux structures qui a permis de donner le jour à la solution OneGeo Suite.
SOGEFI, expert de la data et du webmapping depuis 33 ans propose des solutions pour la gestion et l’exploitation de données par la cartographie. La gamme Mon Territoire est réservée aux collectivités pour la gestion par métier de leur territoire. SOGEFI place l’utilisateur au cœur de ses réflexions et de sa feuille de route et son expertise de la donnée lui permet de proposer des exploitations poussées de la donnée au sein de ses applications. La société équipe aujourd’hui plus de 1000 collectivités et entreprises avec ses solutions web-SIG cadastre, urbanisme, réseaux et voirie. Elle accompagne également le portail Géofoncier sur son expertise de la donnée par la mise à disposition de ses API. »
Pour en savoir plus contactez-nous ! -
-
10:09
Séminaire, juin 2024
sur Neogeo Technologies
Le séminaire annuel de Neogeo réalisé cette année dans les locaux de GEOFIT à Nantes s’est achevé avec succès.
Ces quelques jours ont été remplis de moments partagés donnant lieu à des discussions passionnantes, d’ateliers interactifs et d’échanges inspirants.
Nous tenons à remercier chaleureusement tous les participants pour leur présence et leur engagement le tout dans la bonne humeur. Un immense merci également à nos intervenants (TEICEE) pour leurs présentations éclairantes et leur expertise.
Ce séminaire a été une formidable opportunité pour renforcer le lien entre les équipes, nos connaissances, élargir nos horizons et créer de nouvelles connexions professionnelles.
Nous sommes impatients de mettre en pratique les idées et les stratégies discutées.Publié le 07/06/2024

Séminaire annuel NEOGEO c’est parti…

Rien de mieux qu’une formation DevOps pour mettre les équipes autour d’une table et discuter de l’amélioration continue de nos processus de développement
C’est aussi l’occasion de découvrir les salles de réunion du nouveau siège du groupe GEOFIT à Nantes.Publié le 05/06/2024
-
9:10
Découvrez les Réseaux de Neurones – Le Cerveau de l’IA
sur Neogeo TechnologiesMais, bien plus encore, ces réseaux de neurones sont également utilisés pour classifier des données ou bien effectuer des prévisions. Ils sont également très utilisés dans le domaine du traitement du langage ou bien celui de la vision par ordinateur, notamment en robotique. Les réseaux de neurones sont donc présents partout autour de nous.
Cependant, vous ne savez peut-être pas ce qui se cache derrière ces réseaux qui peuvent paraître très obscurs et complexes. Si vous souhaitez comprendre et utiliser ces systèmes de détection, classification et prédiction, il vous faudra d’abord appréhender la notion de réseaux de neurones. Pour cela, nous allons développer un exemple concret.
Exemple concret – Classification d’une imageUn réseau de neurones peut par exemple être utilisé pour classer une image dans telle ou telle catégorie. Un exemple concret pourrait être l’application de cette technologie à la détection et la classification des sols sur des images satellites.
L’idée est donc de donner une image en entrée du réseau de neurones et que celui-ci classe cette image dans la catégorie “urbain” ou bien « rural” par exemple. Le problème revient donc à se poser la question suivante : « Mon image représente-t-elle une zone urbaine ? »
Si l’on crée le réseau et qu’on donne tout de suite notre image en entrée, on aura un résultat aléatoire, aberrant et très peu exact. Il faut donc entraîner notre réseau avec un jeu de données pour lui apprendre à bien classifier les images. On lui donne donc beaucoup d’images de zones urbaines et rurales pour lui apprendre à les différencier correctement.
Il existe différentes méthodes d’apprentissage mais la plus répandue (et simple à la compréhension) est l’apprentissage supervisé. Cela consiste à donner le résultat attendu en même temps que la donnée d’entrée. Plus concrètement, chaque image est annotée avec la catégorie “urbain” ou “rural” afin que le réseau puisse confirmer ses résultats et ainsi apprendre de ses erreurs. C’est cette méthode d’apprentissage qui sera expliquée par la suite.
Un réseau de neurones est basé sur le fonctionnement du cerveau humain. Il est donc composé de plusieurs neurones reliés entre eux de la façon suivante :
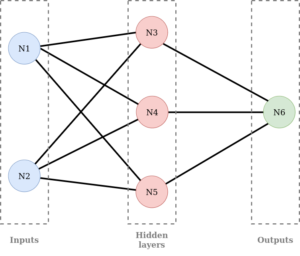
Comme on peut le voir, les neurones sont divisés en 3 familles :
– les entrées : inputs
– les neurones des couches cachées : hidden layers
– les sorties : outputs
Dans notre réseau nous avons : 2 inputs, 1 hidden layer avec 3 neurones et 1 output.
Il est cependant possible d’avoir autant de neurones que l’on veut dans chaque famille ; on peut également avoir plusieurs couches cachées.
Une fois le réseau créé, on peut maintenant s’intéresser à son fonctionnement qui consiste en deux phases : la phase de feed forward et celle de back propagation.
La phase de feed forward consiste à introduire les données en entrée du réseau et de les propager à travers celui-ci. Pour résumer, à chaque couche on calcule la somme pondérée des entrées puis cette valeur est transmise via une fonction d’activation. On reproduit ensuite le processus jusqu’à la couche de sortie. Cette phase est donc celle de prédiction et est utilisée pour l’inférence.
La phase de back propagation arrive une fois la prédiction effectuée. On calcule alors l’erreur entre la sortie prédite et la sortie réelle. Puis cette dernière est propagée dans le réseau et les poids sont ajustés au fur et à mesure pour minimiser cette erreur.
L’apprentissage consiste donc en une multitude de cycles : feed forward + back propagation.
Nous allons maintenant observer la phase de feed forward plus en détails. Cette étape commence par donner une première fois des données en entrée de notre réseau. Chaque neurone de la couche inputs se voit donc affecté d’une valeur. Dans notre cas “Mon image représente-t-elle une zone urbaine ?” on aura des valeurs numériques entre 0 et 1 (probabilité que l’image présente une zone rurale) :
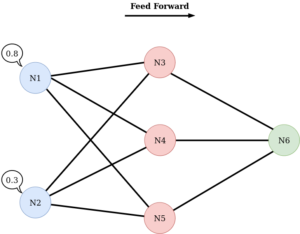
Les valeurs sont ensuite transmises aux neurones de la couche suivante par les connexions :
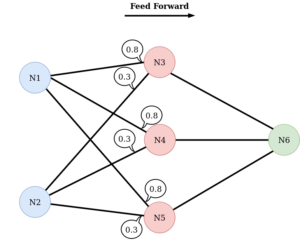
Les neurones de la deuxième couche fusionnent donc les valeurs des neurones de la couche précédente. La valeur fusionnée obtenue peut ensuite être modifiée en interne par le neurone :
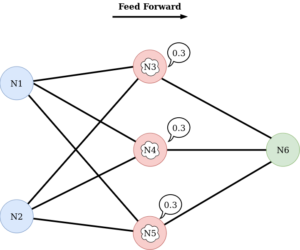
Puis les neurones de la deuxième couche transmettent à leur tour la valeur modifiée à la couche suivante :
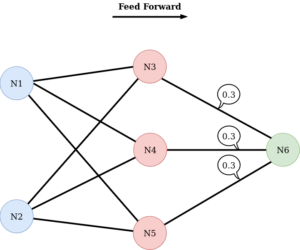
De la même façon, le(s) neurone(s) de la couche finale (outputs), peu(ven)t modifier en interne la valeur reçue avant de la retourner :
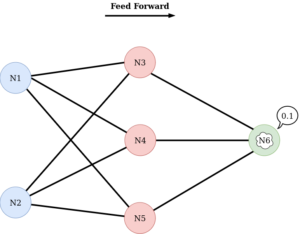
Une fois la valeur finale obtenue, on a fini la passe de feed forward.
En réalité, la transmission des valeurs est un peu plus complexe. C’est ce qu’on va détailler par la suite. Pour bien comprendre la transmission, on va se limiter à 3 neurones.
La transmission des valeurs va dépendre de « l’épaisseur » du lien entre les neurones. Plus le lien est épais, plus la valeur passe dans son intégralité et inversement. Cette épaisseur est appelée poids ou weight et est différente pour chaque lien, comme visible sur l’image suivante :
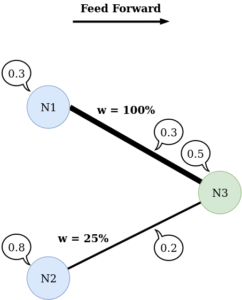
Ainsi, chaque neurone n’a pas le même poids / la même importance dans le réseau.
On va maintenant voir comment le neurone peut changer en interne la valeur qu’il reçoit avant de la transmettre. Concrètement, le neurone possède une fonction, dite fonction d’activation, qui sert à déterminer si la valeur doit ou non passer au prochain neurone. Si le résultat de la fonction est proche de 1, la valeur passera et s’il est proche de 0, la valeur ne passera pas.
Il existe une multitude de fonctions d’activation mais les plus utilisées sont :
– Sigmoid
– Unité linéaire rectifiée (Rectified Linear Unit : ReLU)
– Tangente Hyperbolique (tanh)
– Linear
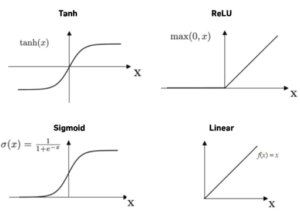
Le neurone a également la possibilité d’ajouter un biais en entrée de la fonction d’activation, ce qui permet au neurone d’avoir de l’influence sur l’activation :
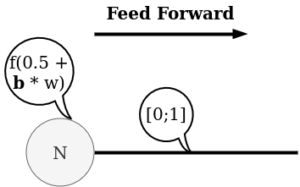
Pour résumer :
– on a un ensemble de neurones
– on entre les données dans les neurones inputs
– on lie les couches de neurones avec un certain poids
– on ajoute des biais, qui sont multipliés par leur propre poids
– on ajoute les valeurs pour avoir les nouvelles valeurs
– on fait passer les nouvelles valeurs dans la fonction d’activation
– on récapitule pour le dernier neurone
On obtient finalement le résultat.
Cependant, comme on initialise les biais et les poids aléatoirement, il y a peu de chance pour que le réseau soit performant.
On va alors passer notre résultat dans une fonction d’erreur. Cette fonction prend en entrée notre résultat et la valeur attendue. Cela nous permet de déterminer la précision de notre réseau.
On va ensuite réaliser la deuxième étape : la passe de back propagation. De manière très simple, cette étape consiste à déterminer comment on doit modifier les poids de notre réseau pour faire diminuer au maximum notre erreur. Dans la pratique, on modifie un poids à la fois et très peu pour déterminer l’influence de chaque poids sur notre réseau en fonction de son impact sur l’erreur. Cette étape est réalisée par les dérivées de tous les calculs fait lors de la phase de feed forward.
ConclusionNous avons découvert ce qui se cache derrière un réseau de neurones, son fonctionnement basique ainsi que ses applications diverses. Les réseaux de neurones offrent de nombreuses possibilités pour le domaine de la géomatique avec l’analyse et l’interprétation des données spatiales. La capacité de ces derniers à apprendre à partir de données brutes en fait un outil puissant pour la prédiction, la classification, et même la génération de nouvelles données géospatiales. Cependant, il est essentiel de se rappeler que, malgré leur potentiel, les réseaux de neurones ne sont pas une solution miracle et peuvent présenter des défis en pratique. Il est notamment important de rappeler que la qualité et la quantité des données sont primordiales afin d’obtenir des résultats fiables et significatifs. Finalement, il est également essentiel de noter que l’utilisation efficace des réseaux de neurones nécessite souvent des capacités de calcul élevées et des ensembles de données volumineux.
Rédactrice : Mathilde POMMIER
-
9:00
Votre application est-elle compatible avec la licence Affero GPL 3.0???
sur Neogeo TechnologiesLors du changement de licence sur OneGeo Suite, il est important d’examiner la compatibilité des dépendances avec Affero GPL. Au vu des implications qui en découlent, est-il surtout possible de vérifier que nos dépendances aient toujours une licence conforme ?
La compatibilité entre les licences?La compatibilité de licences inclut deux éléments clé à prendre en compte :
- Le projet en lui-même (ex : un module Python, une bibliothèque de fonctions, etc.) ;
- Un travail dérivé (ex : un logiciel complet comme FireFox). Les travaux dérivés d’un projet, quant à eux, peuvent être des modifications du code du projet ou des produits intégrant le projet.
Une compatibilité des licences sera possible lorsque le travail dérivé possède une licence qui n’enfreint pas les règles de la licence du projet.
Les licences « copyleft » obligent à redistribuer les travaux dérivés sous la même licence (ou une compatible) pour protéger les libertés du code et de l’utilisateur. A contrario, les licences permissives autorisent le changement de licence, et il est également possible de faire un produit propriétaire, en intégrant des composants sous ce type de licence. Par exemple, Sony base son système d’exploitation propriétaire de la Playstation sur FreeBSD, qui est un logiciel libre sous licence FreeBSD.?
 Source : [https:] (Creative Commons BY-SA-3.0)?
Source : [https:] (Creative Commons BY-SA-3.0)?
Dans ce schéma, le code en domaine public est intégrable dans un produit MIT, lui-même dans un produit sous licence BSD, lui-même dans un produit licence Apache 2.0, et ainsi de suite jusqu’à la licence Affero GPL 3.
Deux catégories supplémentaires sont introduites par ce schéma?:
- Weakly protective (faiblement protectrice)?: elle implique qu’une modification du code doit être sous la même licence (donc rester libre). Néanmoins, l’intégration du projet peut se faire dans un produit sous une autre licence (même propriétaire).
- Network Protective (protectrice des utilisateurs réseau)?: la licence GPL protège les utilisateurs de la machine. Dans le cadre d’applications client-serveur, la partie serveur protège l’utilisateur du serveur, donc l’administrateur système. Une conformité à la GPL existe dans le cas où l’administrateur système de OneGeo Suite a accès aux sources modifiées du produit, mais pas l’utilisateur de la partie client. Les licences Network Protective permet aussi de protéger la liberté des utilisateurs du client.
Notez bien les versions des licences : par exemple la licence Apache 2.0 est compatible avec la licence LGPL, alors que la version 1.1 ne l’est pas.
Pour vous aiguiller, voici quelques incompatibilités à souligner?:
- Apache 1.1 ou MPL 1.1 (Mozilla Public Licence) ne sont pas compatibles avec les licences GPL, alors qu’une clause explicite de compatibilité existe dans les versions 2.0 de ces mêmes licences ;
- CC-BY-3.0?empêche de changer la licence, donc impossible à changer en AGPL. La version 4.0 permet explicitement de changer la licence en GPL 3.0 et donc en AGPL 3.0 ;
- Licence originelle BSD?: elle forçait à indiquer une notice de copyright dans la documentation du produit final, ce qui peut poser problème quand il y a de nombreux composants avec cette licence dans un produit.
En pratique, la conformité de licence peut se vérifier grâce au DevOps.
Pour illustrer nos projets, essentiellement en Python et Javascript, nous vous présentons deux outils simples qui pourront vous aider. Dans ces exemples, nous nous en servirons en ligne de commande, afin de comparer les licences des dépendances avec une liste validée de licences.?
Vérification des licences en Python?L’outil « pylic » analyse tous les modules Python installés dans l’environnement virtuel et compare leurs licences avec une section du pyproject.toml. S’il trouve un module avec une licence non validée, il sort en émettant erreur que l’on pourra exploiter dans une CI.
Commençons par installer le programme?:?
$ pip install pylic?Ensuite, nous indiquons à “pylic” les licences compatibles avec notre logiciel, en lui donnant une liste de licences compatibles AGPL 3.0, dans la section tool.pylic de notre pyproject.toml :
$ cat << EOF >> pyproject.toml? [tool.pylic]? safe_licenses = [? "Apache Software License", "BSD License",? "BSD",? "MIT License",? "MIT",? "Mozilla Public License 2.0 (MPL 2.0)",? "GNU Library or Lesser General Public License (LGPL)",? "GNU Lesser General Public License v3 or later (LGPLv3+)",? ? "Python Software Foundation License",? "Historical Permission Notice and Disclaimer (HPND)"? ? ]? EOF?Vous remarquerez que ces licences ont parfois des noms très similaires. En effet, “pylic” s’appuie sur le nom déclaré par le mainteneur du module python (dans le setup.cfg/setup.py…) qui n’est pas normalisé. Nous devons déclarer comme « safe » les deux identifiants « MIT » et « MIT License », alors que nous aurions pu utiliser les identifiants de licence SPDX dans la configuration du module Python.
Revenons à “pylic” et lançons une vérification :
$ pylic check? ✨ All licenses ok ✨?Comment peut-on faire en cas de non-conformité ?
En commentant la licence « Apache Software License » de pyproject.toml, nous obtenons ce message :
$ pylic check? Found unsafe licenses:? ? nltk (3.8.1): Apache Software License? ? phonenumbers (8.13.8): Apache Software License? ? importlib-metadata (6.1.0): Apache Software License ? bleach (6.0.0): Apache Software License? ? cryptography (42.0.1): Apache Software License? ? regex (2023.12.25): Apache Software License? ? django-onegeo-suite (1.0.2): Apache Software License? ? requests (2.31.0): Apache Software License? ? packaging (23.2): Apache Software License? ? pyOpenSSL (24.0.0): Apache Software License? ? tzdata (2023.4): Apache Software License? ? elasticsearch (7.17.9): Apache Software License? ? async-timeout (4.0.3): Apache Software License? ? josepy (1.14.0): Apache Software License? ? django-onegeo-rproxy-mapstore2 (1.0.0b2): Apache Software License?Plutôt simple, non???
Vérification des licences en Javascript?De la même façon, on peut vérifier les licences des projets javascript avec license-checker. ilIl n’est toujours pas au courant des licences qui existent donc il faudra construire la liste à la main.?
L’utilisation est plutôt simple?:?
$ npx license-checker --onlyAllow "CC-BY-4.0;ISC;Apache-2.0;BSD-3-Clause;Custom: [https:] Domain;CC0-1.0;MPL-2.0" --production??Package « @fortawesome/fontawesome-common-types@0.2.36 » is licensed under « MIT » which is not permitted by the –onlyAllow flag. Exiting.?
?On obtient des erreurs pour chaque licence non autorisée.?
L’option «?–onlyAllow?» permet de lister les licences autorisées séparées par des point virgules «?;?». Tandis que l’option «?–production?» permet d’écarter les licences des modules de la section «?devDependencies?» du package.json.?
Pensez aussi à corriger la section «?license?» du package.json pour ne pas perturber l’outil?:?
? "license": "AGPL-3.0-only",?Je vous conseille aussi d’ajouter un script dans le package.json pour automatiser les vérifications?:?
cat package.json?? {? [...]? ? "scripts": {? [...]??? "lint": "vue-cli-service lint",? ??? "license-checker": "license-checker --onlyAllow \"MIT;CC-BY-4.0;ISC;Apache-2.0;BSD-3-Clause;Custom: [https:] Domain;CC0-1.0;MPL-2.0\" --production" ? },?On peut ainsi lancer simplement?:?
$ npm run? license-checker?
Conclusion?Il existe probablement des outils plus sophistiqués pour vérifier la compatibilité des licences des bibliothèque externes utilisées par votre projet, notamment en utilisant la matrice de compatibilité des licences de l’OSADL?: [https:]] ?
Mais pour une utilisation légère et rapide dans une CI, ces deux outils feront l’affaire, en investissant néanmoins un peu de temps pour vérifier les nouvelles licences qui peuvent apparaître pendant la vie de votre projet.? ?
Sources?:?[https:]] ?: image compatibilité?
[https:]] ?: informations sur les compatibilités avec la GPL?
[https:]] : compatibilité Apache 2.0 et GPL?
[https:]] : utilisation de license-checker?
Rédacteur : Sébastien DA ROCHA
-
8:00
Le changement de licence OneGeo Suite
sur Neogeo TechnologiesAujourd’hui, l’implication de NEOGEO dans la communauté géomatique prend une autre dimension. En adoptant la licence Affero GPL pour nos logiciels OneGeo Suite et GeoContrib, nous souhaitons renforcer cet engagement.
Pourquoi ce changement ?À travers l’adoption de cette nouvelle licence, l’objectif est double :
1. Protéger les innovations : Nous souhaitons garantir que les développements réalisés par Neogeo et nos clients demeurent libres. Cette démarche permet de préserver la richesse et la valeur ajoutée de notre travail.
2. Partager et collaborer : Lorsqu’un acteur, issu ou non du monde de la géomatique, décide de s’appuyer sur nos travaux, ses contributions seront accessibles à toute la communauté. C’est un cercle vertueux : plus nous collaborons, plus le logiciel s’enrichit pour le bénéfice de tous.
Ce changement sera effectif à partir de la version OneGeo Suite 1.1 et pour la version stable GeoContrib 5.4.
Les 4 libertés du logiciel libre : Un rappel essentielLa notion de logiciel libre repose sur 4 libertés fondamentales :
- Le droit d’utiliser le logiciel sans restriction
- Le droit d’étudier le logiciel
- Le droit de diffuser le logiciel
- Le droit de modifier le logiciel et de diffuser les modifications
Le Copyleftt : En la matière, le copyleft est un gage d’égalité et de liberté qui vise à empêcher la restriction des droits des utilisateurs.
Le logiciel peut être modifié mais sa licence doit rester compatible, tout en conservant notamment le droit de copier le code source. Le copyleft garantit donc que les logiciels libres le restent.
 Les licences libres en un coup d’œil
Les licences libres en un coup d’œil
Il existe actuellement plusieurs licences libres :
- Apache : Une licence permissive qui autorise la modification de la licence des fichiers modifiés exclusivement.
- GPL : Sans doute la licence libre la plus populaire et le pilier du copyleft. Elle exige que les produits dérivés et programmes associés adoptent une licence compatible, garantissant les mêmes droits aux utilisateurs.
- LGPL : Une variante de la GPL, la LGPL offre plus de flexibilité sur l’intégration du code dans un produit sous une autre licence (même non libre) tout en restant compatible avec la GPL.
- Affero GPL : La principale différence entre la GPL et l’AGPL réside dans la façon dont elles traitent l’utilisation du logiciel sur des serveurs distants. L’AGPL a été créée pour s’assurer que les services Web basés sur des logiciels libres donnent accès au code source aux utilisateurs distants (même s’ils n’ont pas téléchargé le logiciel).
D’autres licences sont également disponibles mais plus contraignantes en matière de libertés :
- SSPL (Server Side Public License) : utilisée par MongoDB et ElasticSearch, la licence limite la mise à disposition d’un logiciel sur des hébergeurs Cloud. Elle vise essentiellement les géants du cloud comme AWS. La plupart des utilisateurs peuvent continuer d’utiliser MongoDB et ElasticSearch comme avant. Cette licence n’est pas reconnue par l’OSI (Open Source Initiative) comme « open source » et celle-ci est parfois critiquée pour ses exigences jugées excessives ;
- Freemium (ou shareware) : les logiciels sont gratuits mais le plus souvent non modifiables
- CLAs (Contributor License Agreements) : À l’instar d’une NDA (Non Disclosure Agreement), l’agrément doit être signé par les contributeurs afin de céder leurs droits. Cette licence permet également à l’entreprise d’utiliser les contributions d’une manière qui ne serait pas permise par la licence open source sous laquelle le logiciel est publié (ex : changer de licence).
Le passage des solutions sur cette nouvelle licence traduit notre volonté de renforcer la liberté, la collaboration et l’innovation dans le domaine géomatique. Nous souhaitons également que ce changement profite à toute la communauté, ainsi que les évolutions qui en découleront.
Rédacteur : Sébastien DA ROCHA
-
16:12
GPT, capturez-les tous !
sur Neogeo TechnologiesChatGPT est un agent conversationnel qui peut vous aider au quotidien. Néanmoins, vous ne savez pas réellement ce que OpenAI, son créateur, fait de vos conversations. Il n’est, d’ailleurs, pas conseillé de lui parler de sujets confidentiels.
Si vous souhaitez l’utiliser dans vos produits, l’API peut rapidement coûter très cher (compter environ 3 centimes pour le traitement de cet article par exemple, multiplié par le nombre de requêtes par utilisateur, multiplié par les demandes de chaque utilisateur…). Heureusement, la communauté Open Source propose petit à petit des alternatives.
La première étape était la publication de Llama par Meta (Facebook). Il s’agit d’un modèle d’intelligence presque libre et limité à 500 millions d’utilisateurs. Au-delà, il faut les contacter pour avoir le droit de l’utiliser. Il est également possible de le récupérer sur nos ordinateurs et de s’en servir de façon strictement privée.
Pour télécharger le modèle, il faut néanmoins montrer patte blanche en remplissant un formulaire et recevoir un lien, par mail, avec une durée de vie limité. En cas d’expérimentation, cela peut vite devenir contraignant.
Démocratisation techniqueLes développeurs de llama.cpp (surtout Georgi GERGANOV) ont optimisé ce moteur qui vous permet de discuter avec les modèles Llama2.
Les modèles de Llama2Llama2 est disponible en plusieurs tailles (nombre de paramètres) : 7B, 13B et 70B. L’unité « B » correspond à des milliards de paramètres.
Sachant que chaque paramètre est stocké sur 2 octets (des flottants de demi-précision), il faut au moins 16Go de RAM pour charger le petit modèle 7B. Les gros modèles sont plus pertinents, mais beaucoup plus lents.
Les optimisationsLes développeurs de LLama.cpp ont travaillé sur 2 optimisations :
-
- Pouvoir lancer les calculs (appelés «?inférence?») sur le CPU en utilisant au maximum ses capacités (optimisation M1, AVX-512 ou AVX2…) et en codant le moteur d’inférence en C++ et sûrement des morceaux en assembleur? ;
- Compresser le modèle sans trop perdre de pertinence.
Pour ce dernier point, ils ont développé un codage flottant du 4bits : q4_0 (d’autres variantes avec plus de bits existent). Nous pouvons désormais utiliser un modèle 7B avec 4Go de RAM?! À noter que l’on peut tout de même un peu perdre en pertinence.
Le travail de llama.cpp est prodigieux mais difficile à utiliser : il arrive que le modèle réponde de manière erronée ou ne rende pas la main après la réponse.
OllamaDésormais la relève existe : Ollama !
Considéré comme le docker des LLM, il nous permet de télécharger, questionner, supprimer des modèles en une ligne de commande. Concernant les performances, Ollama est une surcouche en Go et utilise llama.cpp.
Les instructions d’installation sont disponibles ici : [https:]
Une fois installé, vous pouvez télécharger un modèle aussi simplement que :
ollama pull llama2Une fois téléchargé, vous pouvez le questionner comme ceci :
ollama run llama2 >>> comment faire une jointure entre 2 dataframes Pandas ? There are several ways to join two pandas DataFrames. Here are a few methods: 1. `merge()`: This is the most common method for joining two DataFrames. It joins the two DataFrames based on a common column, called the "join key". The joined DataFrame will have the columns from both DataFrames. "` df_left = pd.read_csv('left_data.csv') ...Attention, Ollama installe aussi un service Systemd en arrière plan. Si vous préférez le lancer à la main, au hasard pour contrôler la RAM de disponible sur votre machine :
Quel modèle ?# désactiver le démarrage auto avec la machine sudo systemctl disable ollama.service # Couper réellement le service sudo systemctl stop ollama.serviceLlama a apporté son lot de révolutions, mais d’autres équipes de chercheurs ont repris le flambeau, notamment Mistral AI qui a réussi à créer des petits modèles très efficaces.
Récemment, Hugging Face (l’équivalent de Github dans la sphère IA) a encore amélioré Mistral en créant Zephyr, un petit modèle qui a de très bons résultats pour parler dans plusieurs langues.
$ ollama run zephyr:7b >>> comment faire une jointure entre 2 dataframes Pandas ? Pour joindre deux DataFrames en Pandas, vous pouvez utiliser la méthode `merge()`. Ci-dessous une explication de comment utiliser cette méthode : 1. Assurez-vous que les deux DataFrames ont une colonne commune sur laquelle joindre les données. Soit df1 et df2, on appellera cette colonne 'common_column'. ...Zephyr n’a pas de clause de restriction à 500 millions d’utilisateurs (licence Apache 2.0), il répond en français et sera plus économe en ressources.
Ci-dessous, une liste de quelques modèles :
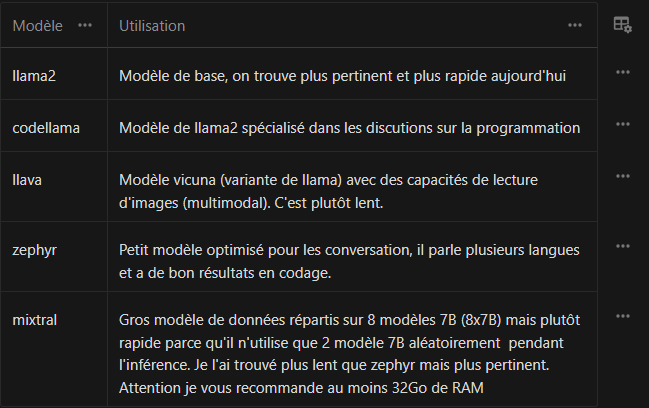
S’il en détecte un, Ollama va automatiquement utiliser le GPU. Sinon, il se rabat sur le CPU en essayant de tirer parti des instructions disponibles (AVX2, AVX512, NEON pour les M1/M2…)
DockerSi vous utilisez l’image docker de Ollama, il faut penser à couper le service Ollama ou à changer de port TCP d’écoute dans le docker-compose.yaml.
Voici un docker-compose minimaliste :
--- version: '3.8' services: ollama: image: ollama/ollama:latest ports: - "11434:11434" volumes: - ollama:/root/.ollama restart: unless-stopped volumes: ollama:Ensuite, un petit
docker compose up -dpour lancer le serveur.Comment pouvons-nous lancer une inférence ?
$ docker compose exec ollama ollama run zephyr:7b >>> Salut Bonjour, Je suis heureux d'aider quelqu'un aujourd'hui. Votre expression "Salut" est une forme courante de salutation en français. En France, c'est souvent utilisé entre amis ou entre personnes qui connaissent déjà l'un l'autre. Dans les situations où vous souhaitez être plus formel ou professionnel, vous pouvez utiliser "Bonjour" ou "Bonsoir" suivi du prénom de la personne ou simplement "Madame" ou "Monsieur" si vous ne connaissez pas le prénom. J'espère que cela vous a été utile. Si vous avez d'autres questions, n'hésitez pas à me contacter. Bien à vous, [Votre nom] >>>En revanche, utiliser la console de l’image n’est pas pratique, sauf si vous souhaitez télécharger une image et plus jamais y retoucher. Et surtout, nous pouvons utiliser l’API HTTP :
$ curl -X POST [localhost:11435] -d '{ "model": "zephyr:7b", "prompt": "raconte moi une courte histoire drôle"}' {"model":"zephyr:7b","created_at":"2024-01-11T15:27:47.516708062Z","response":"Il","done":false} {"model":"zephyr:7b","created_at":"2024-01-11T15:27:47.534749456Z","response":" y","done":false} ...Pour faciliter la lecture de l’inférence, vous pouvez afficher le texte token par token dans notre app. Il est également possible de s’en servir en python. Voici un exemple de client inclut dans le dépôt :
Il est toujours possible d’utiliser le client installé précédemment ollama en ligne de commande, pour requêter le serveur à distance :
Docker et l’accélération avec une carte graphique Nvidia$ OLLAMA_HOST=127.0.0.1:11435 ollama run zephyr:7b-beta-q6_K "raconte moi une courte histoire drôle"Vous remarquerez que l’inférence dans le docker n’est pas très rapide. En effet, docker ne laisse pas le container accéder à la carte graphique, par conséquent l’inférence se fait sur le CPU.
Pour cela, il faut installer un paquet fourni par Nvidia afin de configurer le docker proprement :
$ curl -fsSL [https:] | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L [https:] | \ sed 's#deb [https:] [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] [https:] | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list $ apt update $ apt install -y nvidia-container-toolkitUne fois ce paquet installé, il faut utiliser l’outil fournit pour configurer docker :
$ nvidia-ctk runtime configure --runtime=dockerCela va modifier votre configuration de docker
/etc/docker/daemon.jsonpour activer un runtime nvidia :{ "runtimes": { "nvidia": { "args": [], "path": "nvidia-container-runtime" } } }Ensuite, il suffit de redémarrer docker :
$ systemctl restart dockerDésormais, vous devriez pouvoir accéder à votre GPU Nvidia depuis le container :
$ docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi Unable to find image 'ubuntu:latest' locally latest: Pulling from library/ubuntu a48641193673: Already exists Digest: sha256:6042500cf4b44023ea1894effe7890666b0c5c7871ed83a97c36c76ae560bb9b Status: Downloaded newer image for ubuntu:latest Thu Jan 11 15:46:38 2024 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 525.147.05 Driver Version: 525.147.05 CUDA Version: 12.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA GeForce ... On | 00000000:2D:00.0 On | N/A | | 31% 33C P5 32W / 225W | 1778MiB / 8192MiB | 2% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| +-----------------------------------------------------------------------------+Une fois cela terminé, l’accès doit être donné à votre container en modifiant le docker-compose.yaml:
--- version: '3.8' services: ollama: image: ollama/ollama:latest ports: - "11435:11434" volumes: - ollama:/root/.ollama restart: unless-stopped deploy: resources: reservations: devices: - driver: nvidia capabilities: [gpu] count: all volumes: ollama:Grâce au
Conclusiondocker compose up -d, notre inférence est désormais beaucoup plus rapide.Nous avons découvert comment utiliser les LLM libre, avec des projets comme Ollama et Zephyr, qui rendent l’IA plus démocratique et accessible à un plus grand nombre. Plus besoin de se soucier des coûts prohibitifs de l’API OpenAI, lorsque vous pouvez exploiter ces modèles de langage gratuits et Open source.
Que vous soyez un développeur, un chercheur ou un professionnel de l’IA, Ollama offre des opportunités passionnantes pour innover, créer et résoudre des problèmes. Le monde de l’IA est désormais entre vos mains.
SourcesRédacteur : Sébastien DA ROCHA
-
-
9:00
GPT, capturez-les tous !
sur Neogeo TechnologiesChatGPT est un agent conversationnel qui peut vous aider au quotidien. Néanmoins, vous ne savez pas réellement ce que OpenAI, son créateur, fait de vos conversations. Il n’est, d’ailleurs, pas conseillé de lui parler de sujets confidentiels.
Si vous souhaitez l’utiliser dans vos produits, l’API peut rapidement coûter très cher (compter environ 3 centimes pour le traitement de cet article par exemple, multiplié par le nombre de requêtes par utilisateur, multiplié par les demandes de chaque utilisateur…). Heureusement, la communauté Open Source propose petit à petit des alternatives.
La première étape était la publication de Llama par Meta (Facebook). Il s’agit d’un modèle d’intelligence presque libre et limité à 500 millions d’utilisateurs. Au-delà, il faut les contacter pour avoir le droit de l’utiliser. Il est également possible de le récupérer sur nos ordinateurs et de s’en servir de façon strictement privée.
Pour télécharger le modèle, il faut néanmoins montrer patte blanche en remplissant un formulaire et recevoir un lien, par mail, avec une durée de vie limité. En cas d’expérimentation, cela peut vite devenir contraignant.
Démocratisation techniqueLes développeurs de llama.cpp (surtout Georgi GERGANOV) ont optimisé ce moteur qui vous permet de discuter avec les modèles Llama2.
Les modèles de Llama2Llama2 est disponible en plusieurs tailles (nombre de paramètres) : 7B, 13B et 70B. L’unité « B » correspond à des milliards de paramètres.
Sachant que chaque paramètre est stocké sur 2 octets (des flottants de demi-précision), il faut au moins 16Go de RAM pour charger le petit modèle 7B. Les gros modèles sont plus pertinents, mais beaucoup plus lents.
Les optimisationsLes développeurs de LLama.cpp ont travaillé sur 2 optimisations :
- Pouvoir lancer les calculs (appelés « inférence ») sur le CPU en utilisant au maximum ses capacités (optimisation M1, AVX-512 ou AVX2…) et en codant le moteur d’inférence en C++ et sûrement des morceaux en assembleur ;
- Compresser le modèle sans trop perdre de pertinence.
Pour ce dernier point, ils ont développé un codage flottant du 4bits : q4_0 (d’autres variantes avec plus de bits existent). Nous pouvons désormais utiliser un modèle 7B avec 4Go de RAM ! À noter que l’on peut tout de même un peu perdre en pertinence.
Le travail de llama.cpp est prodigieux mais difficile à utiliser : il arrive que le modèle réponde de manière erronée ou ne rende pas la main après la réponse.
OllamaDésormais la relève existe : Ollama !
Considéré comme le docker des LLM, il nous permet de télécharger, questionner, supprimer des modèles en une ligne de commande. Concernant les performances, Ollama est une surcouche en Go et utilise llama.cpp.
Les instructions d’installation sont disponibles ici : [https:]] .
Une fois installé, vous pouvez télécharger un modèle aussi simplement que :
ollama pull llama2Une fois téléchargé, vous pouvez le questionner comme ceci :
ollama run llama2 >>> comment faire une jointure entre 2 dataframes Pandas ? There are several ways to join two pandas DataFrames. Here are a few methods: 1. `merge()`: This is the most common method for joining two DataFrames. It joins the two DataFrames based on a common column, called the "join key". The joined DataFrame will have the columns from both DataFrames. ``` df_left = pd.read_csv('left_data.csv') ...Attention, Ollama installe aussi un service Systemd en arrière-plan. Si vous préférez le lancer manuellement, au hasard pour contrôler la RAM de disponible sur votre machine, vous devez :
Quel modèle ?# désactiver le démarrage auto avec la machine sudo systemctl disable ollama.service # Couper réellement le service sudo systemctl stop ollama.serviceLlama a apporté son lot de révolutions, mais d’autres équipes de chercheurs ont repris le flambeau, notamment Mistral AI qui a réussi à créer des petits modèles très efficaces.
Récemment, Hugging Face (l’équivalent de Github dans la sphère IA) a encore amélioré Mistral en créant Zephyr, un petit modèle qui a de très bon résultats pour parler dans plusieurs langues.
ollama run zephyr:7b >>> comment faire une jointure entre 2 dataframes Pandas ? Pour joindre deux DataFrames en Pandas, vous pouvez utiliser la méthode `merge()`. Ci-dessous une explication de comment utiliser cette méthode : 1. Assurez-vous que les deux DataFrames ont une colonne commune sur laquelle joindre les données. Soit df1 et df2, on appellera cette colonne 'common_column'. ...Zephyr n’a pas de clause de restriction à 500 millions d’utilisateurs (licence Apache 2.0), il répond en français et sera plus économe en ressources.
Ci-dessous, une liste de quelques modèles :
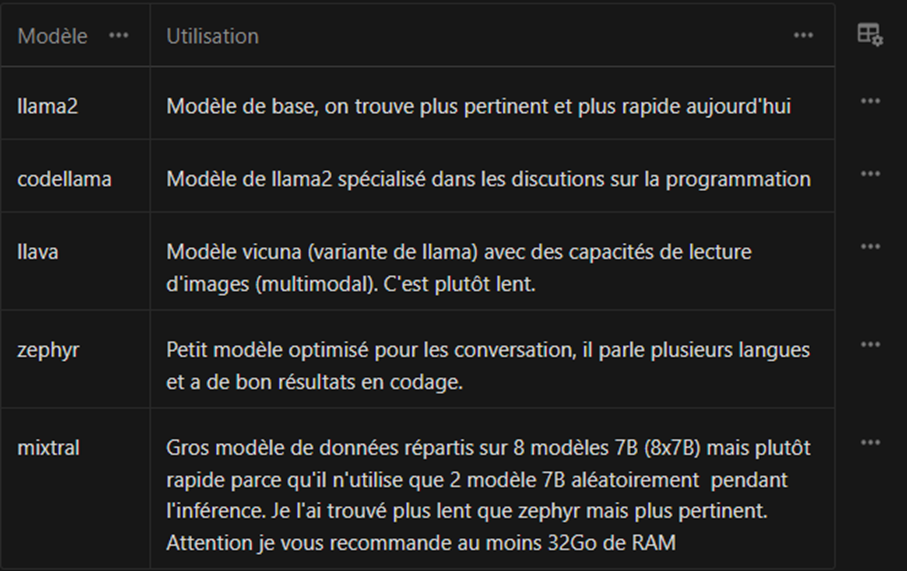
S’il en détecte un, Ollama va automatiquement utiliser le GPU. Sinon, il se rabat sur le CPU en essayant de tirer parti des instructions disponibles (AVX2, AVX512, NEON pour les M1/M2…)
DockerSi vous utilisez l’image docker de Ollama, il faut penser à couper le service Ollama ou à changer de port TCP d’écoute dans le docker-compose.yaml.
Voici un docker-compose minimaliste :
--- version: '3.8' services: ollama: image: ollama/ollama:latest ports: - "11434:11434" volumes: - ollama:/root/.ollama restart: unless-stopped volumes: ollama:Ensuite, un petit docker compose up -d pour lancer le serveur.
Comment pouvons-nous alors lancer une inférence ?
$ docker compose exec ollama ollama run zephyr:7b >>> Salut Bonjour, Je suis heureux d'aider quelqu'un aujourd'hui. Votre expression "Salut" est une forme courante de salutation en français. En France, c'est souvent utilisé entre amis ou entre personnes qui connaissent déjà l'un l'autre. Dans les situations où vous souhaitez être plus formel ou professionnel, vous pouvez utiliser "Bonjour" ou "Bonsoir" suivi du prénom de la personne ou simplement "Madame" ou "Monsieur" si vous ne connaissez pas le prénom. J'espère que cela vous a été utile. Si vous avez d'autres questions, n'hésitez pas à me contacter. Bien à vous, [Votre nom] >>>En revanche, utiliser la console de l’image n’est pas pratique, sauf si vous souhaitez télécharger une image et plus jamais y retoucher. Et surtout, nous pouvons utiliser l’API HTTP :
curl -X POST [localhost:11435] -d '{ "model": "zephyr:7b", "prompt": "raconte moi une courte histoire drôle"}' {"model":"zephyr:7b","created_at":"2024-01-11T15:27:47.516708062Z","response":"Il","done":false} {"model":"zephyr:7b","created_at":"2024-01-11T15:27:47.534749456Z","response":" y","done":false} ...Pour faciliter la lecture de l’inférence, vous pouvez afficher le texte token par token dans notre app. Il est également possible de s’en servir en python. Voici un exemple de client inclut dans le dépôt :
Il est toujours possible d’utiliser le client installé précédemment ollama en ligne de commande, pour requêter le serveur à distance :
Docker et l’accélération avec une carte graphique NvidiaOLLAMA_HOST=127.0.0.1:11435 ollama run zephyr:7b-beta-q6_K "raconte moi une courte histoire drôle"Vous remarquerez que l’inférence dans le docker n’est pas très rapide. En effet, docker ne laisse pas le container accéder à la carte graphique, par conséquent l’inférence se fait sur le CPU.
Pour cela, il faut installer un paquet fourni par Nvidia afin de configurer le docker proprement :
curl -fsSL [https:] | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L [https:] | \ sed 's#deb [https:] [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] [https:] | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list apt update apt install -y nvidia-container-toolkitUne fois ce paquet installé, il faut utiliser l’outil fournit pour configurer docker :
sudo nvidia-ctk runtime configure --runtime=dockerCela va modifier votre configuration de docker /etc/docker/daemon.json pour activer un runtime nvidia :
{ "runtimes": { "nvidia": { "args": [], "path": "nvidia-container-runtime" } } }Ensuite, il suffit de redémarrer docker :
systemctl restart dockerDésormais, vous devriez pouvoir accéder à votre GPU Nvidia depuis le container :
$ docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi Unable to find image 'ubuntu:latest' locally latest: Pulling from library/ubuntu a48641193673: Already exists Digest: sha256:6042500cf4b44023ea1894effe7890666b0c5c7871ed83a97c36c76ae560bb9b Status: Downloaded newer image for ubuntu:latest Thu Jan 11 15:46:38 2024 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 525.147.05 Driver Version: 525.147.05 CUDA Version: 12.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA GeForce ... On | 00000000:2D:00.0 On | N/A | | 31% 33C P5 32W / 225W | 1778MiB / 8192MiB | 2% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| +-----------------------------------------------------------------------------+Une fois cela terminé, l’accès doit être donnée à votre container en modifiant le docker-compose.yaml:
--- version: '3.8' services: ollama: image: ollama/ollama:latest ports: - "11435:11434" volumes: - ollama:/root/.ollama restart: unless-stopped deploy: resources: reservations: devices: - driver: nvidia capabilities: [gpu] count: all volumes: ollama:Grâce au docker compose up -d, notre inférence est désormais beaucoup plus rapide.
ConclusionNous avons découvert comment utiliser les LLM libre, avec des projets comme Ollama et Zephyr, qui rendent l’IA plus démocratique et accessible à un plus grand nombre. Plus besoin de se soucier des coûts prohibitifs de l’API OpenAI, lorsque vous pouvez exploiter ces modèles de langage gratuits et Open source.
Que vous soyez un développeur, un chercheur ou un professionnel de l’IA, Ollama offre des opportunités passionnantes pour innover, créer et résoudre des problèmes. Le monde de l’IA est désormais entre vos mains.
Sources :Rédacteur : Sébastien DA ROCHA
-
10:13
Séminaire, octobre 2022
sur Neogeo TechnologiesBrainstorming, ateliers de travail, balade en fat bike sur la plage…
L’air marin a permis aux collaborateurs de faire émerger de nouvelles idées qui confirment la vision commune des deux entreprises.
Retour en images sur le séminaire organisé pour les équipes de GEOFIT GROUP et de NEOGEO.
-
10:13
Atelier avec le SMEAG
sur Neogeo TechnologiesEn janvier dernier s’est déroulé un atelier avec les équipes du SMEAG – Syndicat Mixte d’Études et d’Aménagement de la Garonne.
L’objectif était de présenter la maquette réalisée dans le cadre de la refonte de leur site internet. Le résultat a été très ???????, les personnes présentes ont approuvées le parcours utilisateur et le design associé.
Nos équipes de production travaillent désormais sur la ????????????? et le ?????????????? du site.


-
10:09
OneGeo Suite, interview GIP ATGERI
sur Neogeo TechnologiesLors des Geo Data Days 2022, nous avons eu l’occasion d’interviewer AnneSAGOT Responsable du Pôle PIGMA, et Emeric PROUTEAU, Référent technique, à propos de la mise en place d’une nouvelle plateforme de données en Nouvelle-Aquitaine.
Ce projet, porté par nos équipes et le GIP ATGeRi, s’est passé «?????? ??? ??? ????????? », malgré les contraintes et imprévus que l’on vous laisse découvrir…
-
10:08
L’Open Source
sur Neogeo TechnologiesChez Neogeo, nous marchons à l’Open Source ! Mais qu’est ce que l’Open Source ?
En quelques slides, découvrez l’un de nos domaines d’expertise.




{kind=link}