
Vous pouvez lire le billet sur le blog La Minute pour plus d'informations sur les RSS !
Canaux
3531 éléments (4 non lus) dans 55 canaux
-
 Décryptagéo, l'information géographique
Décryptagéo, l'information géographique
-
Cybergeo
-
Revue Internationale de Géomatique (RIG)
-
SIGMAG & SIGTV.FR - Un autre regard sur la géomatique
-
Mappemonde
-
Imagerie Géospatiale
-
Toute l’actualité des Geoservices de l'IGN
-
arcOrama, un blog sur les SIG, ceux d ESRI en particulier
-
arcOpole - Actualités du Programme
-
Géoclip, le générateur d'observatoires cartographiques
-
Blog GEOCONCEPT FR
 Toile géomatique francophone
(4 non lus)
Toile géomatique francophone
(4 non lus)
-
Géoblogs (GeoRezo.net)
-
Conseil national de l'information géolocalisée
-
 Geotribu
(2 non lus)
Geotribu
(2 non lus) -
Les cafés géographiques
-
UrbaLine (le blog d'Aline sur l'urba, la géomatique, et l'habitat)
-
Icem7
-
Séries temporelles (CESBIO)
-
Datafoncier, données pour les territoires (Cerema)
-
Cartes et figures du monde
-
SIGEA: actualités des SIG pour l'enseignement agricole
-
Data and GIS tips
-
Neogeo Technologies
(1 non lus)
-
ReLucBlog
-
L'Atelier de Cartographie
-
My Geomatic
-
archeomatic (le blog d'un archéologue à l’INRAP)
-
Cartographies numériques
-
Veille cartographie
-
Makina Corpus
-
Oslandia
(1 non lus)
-
Camptocamp
-
Carnet (neo)cartographique
-
Le blog de Geomatys
-
GEOMATIQUE
-
Geomatick
-
CartONG (actualités)
Éléments non lus (4)
-
14:00
Journée annuelle Prodige 2024
sur Geotribu Synthèse de la journée annuelle Prodige qui s'est tenue en ligne le 3 juin 2024
Synthèse de la journée annuelle Prodige qui s'est tenue en ligne le 3 juin 2024 -
14:00
GEOS au cœur de QGIS
sur Geotribu Troisième partie du tour d'horizon des SIG sur les dessous des calculs géométriques : GEOS et QGIS, au tableau !
Troisième partie du tour d'horizon des SIG sur les dessous des calculs géométriques : GEOS et QGIS, au tableau !
-
 6:49
6:49 GéoDataDays 2024
sur OslandiaOslandia est cette année encore sponsor des GéoDataDays qui se tiendront les 19 et 20 septembre 2024 à Nantes ! Retrouvez-nous sur notre stand et sur l’espace Démo pour un atelier dédié à Piero, l’application Web 3D SIG/BIM open source !
Venez discuter des dernières avancées de l’open source Geospatial, voir les projets que nous avons réalisés, et découvrir comment nous pouvons répondre à vos problématiques.
Vous y croiserez notamment Bertrand Parpoil, Vincent Picavet, Florent Fougeres et Vincent Bré !
Inscription : [https:]]
-
9:41
NEOGEO et SOGEFI allient leur catalogue de données et leur SIG pour les besoins de leurs utilisateurs
sur Neogeo TechnologiesUne solution mutualisée donnant une gamme complète d’outils pour répondre aux besoins cartographiques des acteurs publics.
Chez NEOGEO, nous avons décidé de nous associer à SOGEFI pour offrir à nos utilisateurs toute la puissance des données. Grâce à cette collaboration, la plateforme OneGeo Suite de NEOGEO est enrichie par les applications métier Mon Territoire de SOGEFI.
Ensemble, nous proposons une solution mutualisée qui fournit une gamme complète d’outils adaptés aux besoins des administrateurs, des gestionnaires de données, des services techniques, des élus et du grand public.


Une réponse adaptée à chaque usage cartographique !
La combinaison de nos deux solutions offre une réponse précise et adaptée aux divers acteurs d’un territoire. Elle repose sur un socle commun robuste solide, structuré et évolutif centré sur les données, ce qui permet de créer un cycle vertueux de gestion de la donnée pour l’ensemble des acteurs de la structure, au bénéfice de leur territoire. Le développement de nos solutions respectives est axé sur l’expérience utilisateur, chaque outil étant conçu pour répondre aux besoins spécifiques des différents profils d’acteurs impliqués.
OneGeo Suite propose aux administrateurs une gamme de modules pour gérer les référentiels métiers et satisfaire aux exigences de publication et de partage des données Open Data. OGS valorise ces données grâce à des modes de publication et de reporting (Dataviz) adaptés aux besoins des utilisateurs et de leurs publics, qu’il s’agisse de partenaires ou du grand public. Avec son module Explorer pour la recherche et la consultation intuitive des jeux de données, son module Maps pour les fonctionnalités cartographiques avancées, et son module Portal pour un portail collaboratif, OneGeo Suite offre une solution complète et innovante. Cette suite est fondée sur des principes de mutualisation et de co-construction d’outils open source.
Mon Territoire propose une gamme complète d’outils métiers prêts à l’emploi pour les services techniques et les collectivités. Couvrant de nombreuses compétences, la gamme Mon Territoire utilise une sélection de données Open Data pour assister les agents responsables de l’urbanisme, de l’habitat, des réseaux, de la voirie et du développement économique.
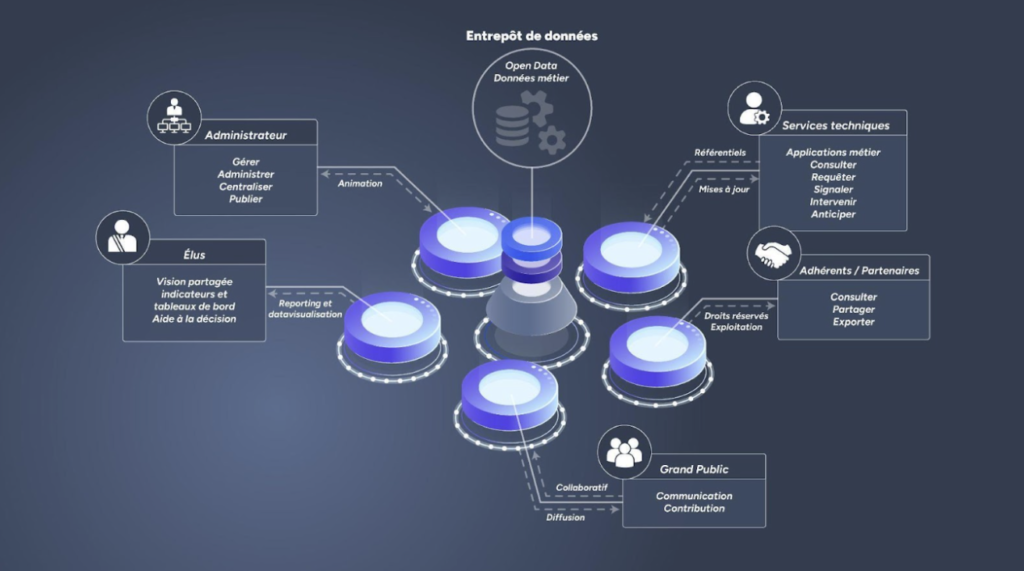
Schéma décrivant les usages et les rôles au travers des applications fusionnées OneGeo Suite et Mon Territoire
Un choix stratégique pour nos entreprises, une décision évidente pour nos clients
Laurent Mer – directeur général de NEOGEO
« La gamme d’outils clé en main proposée par SOGEFI permet de compléter notre solution OneGeo Suite de catalogage et de diffusion de données par des modules métiers opérationnels directement accessibles aux utilisateurs de la plateforme.L’interopérabilité des deux solutions permet de mutualiser l’accès aux référentiels cartographiques et aux bases de données métier et le partage des droits sur les différents jeux de données offre la possibilité de définir une véritable stratégie de gouvernance des données. Enfin l’accès aux API Opendata proposées par SOGEFI et alimentées en temps réel permet d’enrichir l’offre de référentiels proposés dans le catalogue de données mis à disposition ».
Mathilde de Sulzer Wart – directrice générale de SOGEFI
« OneGeo Suite est la réponse idéale pour les structures départementales et régionales qui disposent d’un socle important de données. Les administrateurs de ces dernières disposent alors de tous les outils pour gérer ces importants volumes de données du catalogage à sa publication pour ses adhérents. OneGeo Suite, plateforme complètement Open Source, est totalement interopérable avec notre gamme Mon Territoire, elle apporte une vraie valeur ajoutée pour la diffusion et la valorisation de l’ensemble des données ainsi consolidées au fil du temps par les services et permet à l’IDG la mise en place d’un cycle vertueux de l’information pour l’ensemble de ces acteurs. »
L’un des avantages de notre collaboration est de pouvoir déployer rapidement des solutions prêtes à l’emploi grâce à un accompagnement spécifique par métiers et compétences. Une équipe pluridisciplinaire est mobilisée pour le déploiement de notre offre commune et le planning établi peut mobiliser différentes équipes en parallèle pour le bon avancement du projet. Chacun sur son métier, NEOGEO et SOGEFI ont à cœur de vous accompagner et de vous conseiller sur vos problématiques. Chacun mène une veille permanente sur l’Opendata ainsi que sur les technologies du domaine et vous propose de vous en faire bénéficier au travers des solutions et des services que nous mettons en place depuis plusieurs années. Construit autour de communautés d’utilisateurs, nos deux solutions sont reconnues sur le marché depuis de nombreuses années, elles sont au service de nombreux usagers qui nous font part de leurs besoins d’évolution et idées pour les versions à venir notamment au travers d’espace d’échanges dédiés (forum, page web dédié…). Ces remontées d’informations sont précieuses pour nos équipes afin de définir les feuilles de route de nos produits.
Ce sont bien les produits qui s’adaptent aux besoins des utilisateurs et non les utilisateurs qui s’adaptent au produit.
Le meilleur des arguments, le témoignage de nos clients
Guillaume MALATERRE, directeur Adjoint à l’Informatique et responsable du pôle Gouvernance et Exploitation des Données du SIDEC« Les outils métiers de SOGEFI sont tout à fait en adéquation avec les besoins et les usages des collectivités de toutes tailles dans leurs tâches du quotidien. Les partenariats existants avec Géofoncier sont un vrai plus pour les secrétaires de mairie. Nous pouvons également répondre aux besoins des services techniques des collectivités, des syndicats des eaux, d’assainissement. Les solution OneGeo Suite va nous permettre de maitriser nos données et de les mettre à disposition de nos utilisateurs et partenaires de manière simple et structurée (flux, datavisualisation, carte Web).? Le tout parfaitement intégré à notre SI et répondant à nos exigences en termes d’administration des comptes utilisateurs et des droits sur les données. »

Boris RUELLE, responsable Service de l’Information Géographique de la collectivité territoriale de Guyane« Depuis une douzaine d’année, la plateforme territoriale Guyane-SIG favorise l’accessibilité des données spatiales et la démocratisation de leurs usages sur la Guyane. En 2020, la Collectivité Territoriale de Guyane a initié un travail de modernisation de l’ensemble des composants fonctionnels en deux étapes :
-
-
- Nous avions besoins d’un outil performant pour proposer une lecture facilitée de l’information foncière pour l’ensemble de nos partenaires. Les attentes étaient fortes et avec Mon Territoire Carto, nous avons pu bénéficier rapidement d’un outil ergonomique mobilisant de nombreuses données en Opendata que nous avons pu compléter par des productions endogènes.
- Puis les efforts se sont portés sur les outils collaboratifs de partage et de valorisation des données dans le respect des standards. Avec la suite OneGeo, nos partenaires peuvent désormais publier en quelques clics leurs données.
-
L’accompagnement nous permet également de proposer régulièrement à nos partenaires des webinaires de présentation des évolutions fonctionnelles.
Le partenariat Neogeo et Sogefi qui a commencé avec le projet Géofoncier, le portail de l’Ordre des Géomètres-Experts
NEOGEO et SOGEFI sont ravis de poursuivre et renforcer leur partenariat déjà éprouvé depuis plusieurs années auprès du Portail Géofoncier. Ce portail porté par l’Ordre des Géomètres-Expert est aujourd’hui une référence nationale dans la valorisation de l’information foncière. L’ambition portée par Géofoncier a su s’appuyer sur la complémentarité des expertises de chacun. Les différents projets ont nécessité un travail de coordination et d’enrichissement mutuel des pratiques et technologies mobilisées par les deux sociétés dans un objectif commun. Nos équipes se connaissent, elles ont l’habitude de travailler ensemble et savent mobiliser les ressources en interne pour assurer une couverture élargie des compétences nécessaires aux projets.
Patrick Bezard-Falgas, Directeur général de Géofoncier« Depuis de nombreuses années, NEOGEO et SOGEFI sont nos partenaires privilégiés chez Géofoncier. Leurs expertises complémentaires et incontestées dans le domaine de la diffusion et de la valorisation de la donnée cartographique, associée à leurs écoutes attentives de nos besoins, font de NEOGEO et SOGEFI un groupement pertinent et essentiel à notre réussite. Leur engagement fort au quotidien à fournir en concertation des solutions complètes et pérennes ont grandement contribué au succès de Géofoncier. Nous sommes reconnaissants de pouvoir compter sur ces équipes d’experts aussi fiables et compétentes pour nous accompagner dans notre croissance continue.
NEOGEO possède une expertise avérée dans la mise en œuvre de solutions innovantes de partage, de valorisation et de visualisation de données géographiques auprès d’un large public. NEOGEO développe et met en place depuis sa création en 2008 des infrastructures de données géographiques et des plateformes open-source. NEOGEO a intégré en 2022 le groupe Geofit (leader français dans l’acquisition de données spatiales), permettant ainsi de renforcer ses compétences (équipe de 40 collaborateurs) et ses références (une cinquantaine de plateformes cartographiques majeures déployées en France et à l’étranger). C’est aussi la fusion des savoirs faires technologiques des deux structures qui a permis de donner le jour à la solution OneGeo Suite.
SOGEFI, expert de la data et du webmapping depuis 33 ans propose des solutions pour la gestion et l’exploitation de données par la cartographie. La gamme Mon Territoire est réservée aux collectivités pour la gestion par métier de leur territoire. SOGEFI place l’utilisateur au cœur de ses réflexions et de sa feuille de route et son expertise de la donnée lui permet de proposer des exploitations poussées de la donnée au sein de ses applications. La société équipe aujourd’hui plus de 1000 collectivités et entreprises avec ses solutions web-SIG cadastre, urbanisme, réseaux et voirie. Elle accompagne également le portail Géofoncier sur son expertise de la donnée par la mise à disposition de ses API. »
Pour en savoir plus contactez-nous ! -
Éléments récents
-
13:40
WhereGroup: Erweiterte Geodatenvisualisierung mit MapComponents
sur Planet OSGeoDie MapComponents-Bibliothek ermöglicht die Anzeige und Integration verschiedener Datenformate direkt im Browser. Anhand eines praktischen Beispiels wird gezeigt, wie Benutzer OpenStreetMap-Daten in eine Webanwendung laden und diese anzeigen lassen können. -
11:00
Mappery: Coaster
sur Planet OSGeo

-
10:37
Campus interactif
sur SIGMAG & SIGTV.FR - Un autre regard sur la géomatique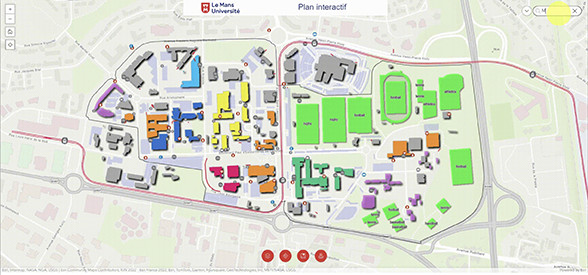 Des étudiants de la Licence Pro ATU Géomatique et E-gouvernance des territoires de Le Mans Université ont réalisés un prototype de plan interactif de leur campus, dans le cadre d’un projet tutoré. Ils ont été soutenus par l’équipe éducation d’Esri France afin de prouver l’utilité de l’usage de la cartographie pour la gestion du site. La suite du projet devrait être à présent organisée avec les services concernés (communication, DATI, DSI, équipe signalétique, etc.). La prochaine promotion pourrait construire sur des bases solides un plan opérationnel en 2025 en vue de sa publication. Ce cas d’usage semble retenir l’attention d’autres universités françaises. Ainsi, l’Université de Rennes a mené un projet similaire et l’Université de Grenoble Alpes a envoyé ses étudiants de Licence Pro sur le terrain pour collecter le mobilier urbain du campus de Saint Martin d’Hères.
Des étudiants de la Licence Pro ATU Géomatique et E-gouvernance des territoires de Le Mans Université ont réalisés un prototype de plan interactif de leur campus, dans le cadre d’un projet tutoré. Ils ont été soutenus par l’équipe éducation d’Esri France afin de prouver l’utilité de l’usage de la cartographie pour la gestion du site. La suite du projet devrait être à présent organisée avec les services concernés (communication, DATI, DSI, équipe signalétique, etc.). La prochaine promotion pourrait construire sur des bases solides un plan opérationnel en 2025 en vue de sa publication. Ce cas d’usage semble retenir l’attention d’autres universités françaises. Ainsi, l’Université de Rennes a mené un projet similaire et l’Université de Grenoble Alpes a envoyé ses étudiants de Licence Pro sur le terrain pour collecter le mobilier urbain du campus de Saint Martin d’Hères.
+ d'infos :
univ-lemans.fr
-
8:24
Tracking American Spies in Germany
sur Google Maps ManiaBayerischer Rundfunk and netzpolitik have carried out a joint investigation into how our location data is for sale across the world. These days nearly everyone voluntarily carries around their own personal tracking device in the form of a smartphone. These devices record our movements all day long. What most people don't know is that their location data is openly being sold by global data
-
11:15
Jorge Sanz: Elastic Volunteering Time Off
sur Planet OSGeo
My employer, Elastic, has a number of philanthropic initiatives but definitely the one I love the most is the Volunteering Time Off (VTO). We are given 40 hours per year from our working hours to contribute to projects and initiatives we care about. Employees have full freedom to choose what they want to do with that time and are encouraged to use it.
In my case, over this almost 5 years I have to admit I haven’t used all that time every year but I tried to get the most of it. During COVID I did some remote work for a local NGO that works for fair trade, giving them a webinar about Open Source among other things (see update from December 2019 and following months). I also spent a few days working on some admin tasks for the Open Source Geospatial Foundation and I’ve already written here about a couple sessions I did for Cibervoluntarios, training seniors and teens about safe browsing and email.
Last week I was showcased in the company blog, along with other colleagues, on different projects to contribute to. In my case, last year I joined the mapping efforts after the Morocco Earthquake and took a full day mapping roads and streets of a rural area, as part of the coordinated efforts from the Humanitarian OpenStreetMap team (reported on my October community update). I’m very happy to have this support from my employer to leave things aside when an emergency like this arises, granted there are no other urgent issues at work.
As a personal call to action, I’d love to get back to Cibervoluntarios activities. This year has been quite busy; let’s see after summer if there’s room for getting out and engaging with them.
I know I haven’t updated this site in a while, I’ll write one soon! ?
-
11:00
Mappery: Geodesic point
sur Planet OSGeo

-
The Retro Gamer's Map
sur Google Maps ManiaThe Retro.Directory is an interactive map which shows the locations of venues related to retro gaming. These include gaming museums, arcades, cafes, bars, clubs and repair services. The map is designed to help retro gaming enthusiasts discover retro-themed locations nearby and around the world.I am so old that I can actually remember a time before computer games. I can remember the amazing
-
9:00
QGIS Blog: Introducing the new QGIS.org website
sur Planet OSGeoWe have a new website!
We recently launched our new website at QGIS.org. It is a ground-up overhaul and provides a fresh take on the first contact point for existing or potential users wishing to engage with the QGIS project and discover its value proposition.

A new strategy for QGIS.org websites
In this blog post, we would like to provide an overview of the goals that we had for building the new QGIS.org website and the bigger picture of how this website update fits into the broader strategy for our website plans for QGIS.
About two years ago, we started experimenting with building a new QGIS.org website based on Hugo. Hugo, as a technology choice, was less important than was our intent to develop a more modern site that addressed our strategic goals.
After some ‘in-house’ (i.e. volunteer-based) work to develop an initial version of the site, we received the go-ahead to use QGIS funds for this and put out a call in October 2023 for a company to support our work. This was ultimately won by Kontur.io, who, together with our volunteers, brought the work into high gear.
 Initial analysis of the questions and actions to be quickly answered by qgis.org
Initial analysis of the questions and actions to be quickly answered by qgis.org
Goal 1: Speak to a new audience
Our primary goal was to speak to a new audience. We are confident that QGIS can compete with all of the commercial vendors providing GIS software. We didn’t convey that well on our old website. We feel that QGIS was too apologetic in how it presented itself. We wanted a website which inspires confidence while addressing the needs of a corporate or organisational decision-maker who is looking at the QGIS project during their GIS software selection process.
The old website was very focused on the developer and contributor community. Obviously, those aspects are important since, without our fantastic community, the QGIS project would not exist. The messaging around open source is also important. Yet these ideas are secondary to the idea that QGIS is one of the best (if not the best) desktop GIS applications out there on the market – open-source or otherwise. We need to present it in this professional perspective.
So, the first goal was to change the messaging to focus on QGIS’s value proposition and take a very professional approach to presenting ourselves on the website.
 User group and requirements analysis for the potential qgis.org visitors
User group and requirements analysis for the potential qgis.org visitors
Goal 2: Harmonisation
The second goal was to start the process of harmonising all of our website properties. QGIS.org, over the years, has built many different web properties. For example, there’s the plugins website, the feed, the changelog, the sustaining members website, the lessons website and the certification website, the new resources hub website, the API documentation, the user documentation, the user manual, the training manual, various other documentation efforts, and more. Some of those are combined in one application, There are also some less well-known resources, like our analytics.qgis.org and another one for plugin analytics. In short, we’ve a lot of resources!
With so many different web properties, they’ve devolved over time: each has its own look and feel, navigation approach and how you interact with it. Some of them were translated, and some of them were not. We want to harmonise all of these sites so that the user does not notice any change in user experience when they move from one QGIS-related site to another.
Goal 3: Harmonising deployment
In the underlying process of these changes, we’re also redeploying all of the websites on new servers, which are more up-to-date and use better security and maintenance practices. Plenty of work is happening in the background to ensure that all of the servers are in a better-maintained state, document how they’re maintained, and so on.
Goal 4: A hub and spokes
The objective of the new site design is to allow quick movement between the QGIS auxiliary sites. The QGIS.org site will form a hub that effortlessly takes visitors to whichever QGIS-related site they need to complete the task they are busy with. If you’re moving between these sites, the experience should be seamless. You should not really even be aware that you’re moving between different websites. Other than looking at the URL bar, the user presentation and experience should be harmonious between all of them.
One way we are planning to achieve this is to have a universal menu bar and footer. You will see that in the new website’s design, there is a menu bar across the top. This menu bar has two levels: the top menu and the second level, where the search bar is.
 The universal menu bar
The universal menu bar
In this second row, auxiliary sites will have their own sub-menu whilst keeping the shared top-level menu. So if you, for example, are moving around in plugins and want to review the plugin list or submit a new plugin, all of that navigation will be on the second line where the search bar is currently. Regardless of which subdomain you are on, the top-level menu bar will be the same, allowing you to easily navigate back to the hub or to another subdomain.
The footer will be unified and shared between all sites, and the cascading style sheets and styling will be unified across all of the QGIS websites.
In the next phase, we will work to achieve this coherence across all the websites, though we still have a few more tweaks to make to the qgis.org site first.
Goal 5: DOTDOTW – do one thing, do one thing well
We plan to break some auxiliary websites apart into separate pieces. So, for example, the changelog management, certification management, sustaining members management, and lessons management are all in one Django app. We will split them into small single-purpose applications using some common UX metaphors so that each is a standalone application that makes it easy for a potential contributor to understand everything the application does. This will also simplify management as we can upgrade each auxiliary site on separate development cycles. We will also finally have semantic URLs, e.g. certification.qgis.org, to take you to the different areas of interest on the site.
The plugins.qgis.org is also going to be refactored so that it just has plugins and not the resource sharing we’ve added in the last few years. The resource sharing will go into its own subdomain. Similarly, the Planet website will get split into its own website (the planet is a blog aggregator or RSS aggregator) that will be in its own managed instance. Some other components (like the analytics) are difficult to split out like this because they’re linked to the same database. We will try to make sure that those are more discoverable and theme them as much as possible to match the rest of the website experience.
Goal 7: Encapsulation

Another goal we had for the QGIS.org makeover was to make the site performant and self-contained. By self-contained, we mean that it should not ‘call’ out to CDN, Google or other platforms for resources like fonts, CSS frameworks, javascript libraries, etc. There were two reasons for this:
- These platforms often use such resources to track users as they move around the Internet, which we want to avoid as much as possible.
- We want to wholly manage our site, be able to fix any issues independently and generally follow a path of self-determination.
Our approach also facilitated the creation of a very performant website, as you can see here. We will try to adhere to these principles for the auxiliary site updates we do in the future, too.
What about translations?The question has come up: Why did we not want to translate the new QGIS.org when it was translated before?
Firstly, we should make it clear that we do not plan to remove translations from the user documentation, the user manual, and so on, where we think they have the most value.
For the main QGIS.org site, we question whether there is a high value in translating it. Here are some reasons why:
1. Lingua franca: If you are an IT manager in a non-English-speaking country and you want to evaluate some software, you’re going to run into a product page that presents itself in English – it is the norm for IT procurement to work in English for reviewing software products and so on.
2. Automation: Automated translations inside browsers are getting better and better. While these translations are still not completely adequate, we think they will be in one or two years’ time.
3. Translation integrity: Our pursuit of Goal 1 means that we would no longer find it acceptable to have partial website translations. We also need to ensure that the wording and phrasing are consistent with the English messaging. We also have concerns about the QA process regarding trust and review – we want to ensure that any translation truly reflects the meaning and intent of the original content and has not been adjusted during the translation process.
4. Cohesion: Our most important point is raised if we go back to this idea of cohesion between the different websites like QGIS.org, plugins.qgis.org and so on. As well as having the same styling, we also don’t want to switch between languages as you hop between the sites. We aim to present them all as one site. If we translate QGIS.org and then take you to our auxiliary sites, e.g., plugins.qgis.org, the feed, or certification pages, which are in English only, the experience is jarring.
So we must either translate everything into all of the same languages, or work in English. Translating everything is a mammoth task for the translators and for us to retrospectively add translation support to each platform. Thus, we prefer the approach of harmonising everything to one language and then focusing our translation efforts on three areas:
- The application itself,
- the user manual and
- the training manuals.
We can leave the rest of the experience in English and instead focus on harmonising, for now, both in terms of look and feel and the technology used.
When we consider everything as one big website and what the bigger plan is, it is hopefully clearer why we didn’t think translating the landing page and QGIS.org was the best approach.
Further funded workWe hope to use more QGIS funding to support this work in the future. We’re also hoping to work again with Kontur to start moving all these auxiliary sites into their own projects, applying our style guidelines to each. Independently of that, Tim (volunteer), Lova (QGIS funded), and others are already getting started with this process.
Helping outDo you have strong opinions about the website? Contact Tim on the PSC mailing list if you would like to get involved as a volunteer. We would love to hear from designers, word smiths, marketers, information architects, SEO specialists, web developers and those who think they can help us achieve our goals.
ConclusionWe hope our goals and process make sense for everybody and that we were able to lay out a clear, logical argument about why we don’t want to translate the new website quite yet. We want to focus on these overarching goals and then return to them later if they are still a priority for people. Everything we have built is Open Source and available at this repo, where you can also find an issue tracker to report issues and share ideas relating to the new website.
Thanks for reading. Go spatial without compromise


Cheers, Tim, Marco and Anita





-
6:55
[1’Tech by Oslandia] open data
sur OslandiaDans cette minute Tech, nos collaborateurs vous proposent d’expliquer une technologie, une méthodologie, un concept. Après open source, LiDAR, webGL, réversibilité, TCO et même télétravail, on a brainstormé sur GitLab pour donner notre meilleure définition de l’open data
L’open data ( « Donnée ouverte » ), est la donnée librement accessible. Elle concerne notamment toutes les données publiques accessibles aux usagers : citoyens, entreprises, collectivités, … Elles peuvent être d’origine privée mais sont la plupart du temps mises à disposition par une collectivité ou un établissement public.
L’Open Knowledge Foundation en 2005 donnent les critères essentiels de l’open data : la disponibilité, la réutilisation et la distribution, et la participation universelle. En France, il existe un cadre légal obligeant à l’ouverture de certaines données.
Ces ressources ouvertes accessibles dans des catalogues de données, permettent de construire des outils comme des observatoires pour lesquels la représentation cartographique est utilisée.Oslandia a travaillé sur de nombreux projets mobilisant de l’open data, c’est le cas de Terristory®, un outil partenarial d’aide au pilotage de la transition des territoires ou sur des projets avec Bruxelles Environnement. Nous avons également une connaissance approfondie de la donnée OpenStreetMap.
L’open data permet d’alimenter ces outils numériques avec de la donnée de qualité permettant ainsi des services de qualité.
OpenData et OpenSource forment le combo libre et efficient !
-
2:00
SourcePole: Adding external WMS to the QGIS Cloud Web Map
sur Planet OSGeoThe use of WMS/WMTS layers in a QGIS Cloud map project can significantly degrade the performance of the map display. I have already discussed how to counter this problem in an earlier post. One of the solutions is to load external WMS as background layers. The problem with this approach, however, is that only one WMS background layer can be loaded at a time. If further WMS layers are to be loaded into the map at the same time, this approach cannot be used. -
11:00
Mappery: Wallpaper
sur Planet OSGeo

-
10:30
Philippe Valette, Albane Burens, Laurent Carozza, Cristian Micu (dir.), 2024, Géohistoire des zones humides. Trajectoires d’artificialisation et de conservation, Toulouse, Presses universitaires du Midi, 382 p.
sur CybergeoLes zones humides, notamment celles associées aux cours d’eau, sont des objets privilégiés de la géohistoire (Lestel et al., 2018 ; Jacob-Rousseau, 2020 ; Piovan, 2020). Dans Géohistoire des zones humides. Trajectoires d’artificialisation et de conservation, paru en 2024 aux Presses universitaires du Midi, Valette et al. explorent l’intérêt scientifique de ces milieux, qui réside selon leurs mots dans "la double inconstance de leurs modes de valorisation et de leurs perceptions qui a conduit, pour [chacun d’entre eux], à des successions d’usages et fonctionnement biophysiques très disparates" (2024, p.349). L’analyse des vestiges conservés dans leurs sédiments permet en effet de reconstituer sur le temps long les interactions entre les sociétés et leur environnement. En outre, les milieux humides ont souvent été abondamment décrits et cartographiés, en lien avec leur exploitation et leur aménagement précoces. Archives sédimentaires et historiques fournissent ainsi à la communauté sc...
-
10:30
Cartographier les pressions qui s’exercent sur la biodiversité : éléments de réflexion autour des pratiques utilisées
sur CybergeoPour mieux orienter les politiques de conservation, il est crucial de comprendre les mécanismes responsables de la perte de biodiversité. Les cartes illustrant les pressions anthropiques sur la biodiversité représentent une solution technique en plein développement face à cet enjeu. Cet article, fondé sur une revue bibliographique, éclaire les diverses étapes de leur élaboration et interroge la pertinence des choix méthodologiques envisageables. La définition des notions mobilisées pour élaborer ces cartes, en particulier celle de la pression, représente un premier défi. La pression se trouve précisément à la jonction entre les facteurs de détérioration et leurs répercussions. Cependant, les indicateurs à notre disposition pour la localiser géographiquement sont généralement axés soit sur les causes, soit sur les conséquences de la dégradation. Cet écueil peut être surmonté si la nature des indicateurs utilisés est bien définie. À cet effet, nous proposons une catégorisation des ind...
-
10:30
Exploring human appreciation and perception of spontaneous urban fauna in Paris, France
sur CybergeoCity-dwellers are often confronted with the presence of many spontaneous animal species which they either like or dislike. Using a questionnaire, we assessed the appreciation and perception of the pigeon (Columba livia), the rat (Rattus norvegicus), and the hedgehog (Erinaceus europaeus) by people in parks, train stations, tourist sites, community gardens, and cemeteries in Paris, France. Two hundred individuals were interviewed between May 2017 and March 2018. While factors such as age, gender, level of education or place or location of the survey did not appear to be decisive in analyzing the differential appreciation of these species by individuals, there was a clear difference in appreciation based on the species and the perceived usefulness of the animal, which is often poorly understood. The rat was disliked (with an average appreciation score of 2.2/10), and the hedgehog was liked (with an average appreciation score of 7.7/10). The case of the pigeon is more complex, with som...
-
10:30
From "Bioeconomy Strategy" to the "Long-term Vision" of European Commission: which sustainability for rural areas?
sur CybergeoThe aim of this paper is to analyze the current and long-term effects of the European Commission Bioeconomy Strategy in order to outline possible scenarios for rural areas and evaluate their sustainability. The focus is on the main economic sectors, with particular reference to employment and turnover, in order to understand what kind of economy and jobs are intended for rural areas, as well as their territorial impacts. For this purpose, we have analyzed the main European Commission documents and datasets concerning the bioeconomy and long-term planning for rural areas, as well as the recent scientific data to verify the impact on forests. The result is that European rural areas are intended to be converted initially into large-scale biomass producers for energy and bio-based industry, according to the digitization process, and subsequently into biorefinery sites, with severe damage to landscape, environment, biodiversity, land use and local economy. Scenarios for rural areas don’t...
-
10:30
Impact du numérique sur la relation entre les systèmes de gestion de crise et les citoyens, analyse empirique en Île-de-France et en Région de Bruxelles-Capitale
sur CybergeoDepuis une dizaine d’année, les systèmes de gestion de crise utilisent les canaux de communication apportés par le numérique. D'un côté, le recours aux plateformes numériques et aux applications smartphones permet une plus grande visibilité des connaissances sur le risque. De l’autre, les réseaux sociaux numériques apparaissent comme un levier idéal pour combler le manque d'implication citoyenne dans la gestion de crise. Pourtant, jusqu'à la crise sanitaire qui a débuté en 2020, rien ne semble avoir été fait pour impliquer les citoyens au cours du processus de gestion de crise. Dans cet article, nous posons la question de l'apport du numérique dans la transformation de la communication sur les risques et dans l'implication citoyenne dans la gestion de crise. En 2018, nous avons diffusé un questionnaire en Île-de-France et dans la région de Bruxelles-Capitale afin de comprendre les attentes des citoyens et les effets des stratégies de communication territoriale sur la perception des ...
-
10:30
La fabrique publique/privée des données de planification urbaine en France : entre logique gestionnaire et approche territorialisée de la règle
sur CybergeoLa question des données territoriales revêt une importance croissante pour l’État, qui entend orienter leur production, leur circulation et leur condition d’usage. Cet article examine les modalités du repositionnement de l’État vis-à-vis des collectivités locales en matière d’urbanisme règlementaire dans le cadre de la standardisation et de la numérisation des données des Plans Locaux d’Urbanisme. Il explore également l’intégration de ces données dans une géoplateforme unique. Nous montrons que ce projet de construction d’un outil commun à l’échelle nationale s’inscrit dans le cadre d’une reprise en main par le pouvoir central des données de planification urbaine à travers l’intégration partielle de méthodes privées, développées par des sociétés commerciales au cours des années 2010 grâce au processus d’open data. L’étude de la fabrique publique/privée des données de l’urbanisme règlementaire permet de mettre en exergue deux points clés de la reconfiguration de l’action de l’État pa...
-
10:30
Le territoire est toujours vivant. Une analyse transversale de la littérature sur un concept central de la géographie
sur CybergeoLe concept de territoire fait l’objet d’une très abondante littérature en sciences humaines et sociales, qui alimente des sens et des usages apparemment très différents. Cet article dresse un état de l’art multidisciplinaire qui situe les uns par rapport aux autres les différents courants sur le concept de territoire. Dans le format synthétique qui est le sien, le but n’est pas d’approfondir chacune des discussions théoriques. Le premier objectif est plutôt de structurer, à travers un corpus d’environ 120 références, un panorama de la très abondante littérature francophone, anglophone et hispanophone sur le territoire. Le deuxième objectif est de tenter des rapprochements entre ces arènes de discussions qui échangent peu entre elles, autour de trois problématiques qui pourraient leur être communes. Enfin, en approfondissant la lecture transversale de la littérature et l’effort de synthèse, le troisième objectif est de soumettre à la discussion des caractéristiques fondamentales qui ...
-
10:30
Vers une transition des systèmes agricoles en France métropolitaine ? Une géographie contrastée et en mouvement (2010 et 2020)
sur CybergeoFace aux objectifs de décarbonation de l’agriculture, de préservation de l’environnement et aux enjeux de viabilité économique et de sécurité alimentaire qui en découlent, les politiques européennes (Farm to fork) et françaises encouragent une transition en profondeur des systèmes agri-alimentaires. Dans ce contexte, la transformation des modes de production agricole devient une nécessité. Cet article présente une géographie des exploitations agricoles en transition en France métropolitaine. Il repose sur une typologie des exploitations agricoles combinant mode de production agricole (biologique ou conventionnel) et mode de commercialisation des produits (circuit court ou filière longue) à partir des données des recensements agricoles de 2010 et 2020. L’analyse propose une cartographie à échelle fine (canton INSEE) des trajectoires d’évolution sur la période 2010-2020 des agricultures en transition, ouvrant la voie à discussion sur les facteurs favorables à l’émergence certains type...
-
10:30
Explorer la répartition spatiotemporelle des piqûres de tiques sur les humains en France : la température moyenne comme indicateur du risque acarologique
sur CybergeoParmi les maladies à transmissions vectorielles, les maladies à tiques (dont la Borréliose de Lyme) sont celles dont la fréquence des cas est en constante augmentation. L’Europe et l’Amérique du Nord sont particulièrement concernées dans les régions tempérées. Comme il existe une saisonnalité des piqûres de tiques, plus de signalement en été, moins en hiver, nous nous sommes demandés s’il existait des marqueurs climatiques permettant de connaître le début de la saison du risque acarologique pour en informer le public. Grâce à programme de sciences participatives de l’INRAe, CiTIQUE, 22 000 cas géolocalisés en France de piqûres de tiques sur des humains ont été collectés, entre juillet 2017 et avril 2020. Ces signalements ont été appairés avec les conditions météorologiques (issues des bases Météo-France et Dark Sky) qui régnaient au lieu et à la date de chacune des piqûres signalées. Parmi toutes les variables analysées, la température quotidienne moyenne est le meilleur indicateur....
-
10:30
Bernard Lahire, 2023, Les structures fondamentales des sociétés humaines, Paris, La Découverte, Collection sciences sociales du vivant, 970 p.
sur CybergeoL’ouvrage de Bernard Lahire est d’importance, par son volume, par son érudition qui en fait une véritable "somme" scientifique, et par sa position originale réaffirmant en la substantialisant la liaison entre les sciences sociales et les sciences de la nature. Il faut admirer le courage de l’auteur, qui mobilise un vaste corpus de données pour aller souvent à contre-courant des idées plus fréquemment reçues en sciences sociales, et identifier des éléments de savoirs cumulables pour construire une sociologie faite d’universaux et de lois. Je ne prétends pas faire ici la recension que mérite cet ouvrage, quant à ce qu’il représente en termes d’apport à la science sociologique, d’autres plus qualifiés s’en chargeront, et sa dimension et sa construction rendraient difficile autant qu’injuste une proposition de résumé. Chacune de ses trois grandes parties offre cependant une lecture qui sera du plus grand intérêt pour les géographes. La première partie "Des sciences sociales et des lois"...
-
9:30
Appropriations de l’espace et répression du mouvement des Gilets jaunes à Caen
sur MappemondeEn mobilisant différentes méthodologies de recherche issues principalement de la géographie sociale et de la sociologie politique, le présent article souhaite esquisser quelques pistes d’analyse et répondre à la question suivante : comment rendre compte par la cartographie des espaces de lutte du mouvement des Gilets jaunes dans l’agglomération caennaise ? En explorant ainsi sa dimension spatiale, nous désirons contribuer aux débats méthodologiques et analytiques qui ont accompagné ce mouvement qui s’est distingué par ses revendications et sa durée, mais aussi par sa géographie.
-
9:30
Les cartes dans l’analyse politique de l’espace : de l’outil à l’objet de recherche
sur MappemondeLa publication de la carte répertoriant les trajets d’utilisateurs de l’application de sport Strava, en 2017, a rendu identifiables des bases militaires dont les membres utilisaient Strava lors de leurs entraînements (Six, 2018). Cet exemple souligne à la fois l’omniprésence de l’outil cartographique dans nos vies et sa dimension stratégique. Aucune carte n’est anodine, quand bien même son objet semble l’être. Nos sociétés sont aujourd’hui confrontées à de nouveaux enjeux, liés à l’abondance des cartes sur Internet, dans les médias, au travail, que celles-ci soient réalisées de manière artisanale ou par le traitement automatisé de données géolocalisées. L’usage de la cartographie, y compris produite en temps réel, s’est généralisé à de nombreux secteurs d’activités, sans que l’ensemble des nouveaux usagers ne soit véritablement formé à la lecture de ce type de représentation, ni à leur remise en question. Dans ce cadre, le rôle du géographe ne se limite pas à la production de cartes...
-
9:30
Les stratégies cartographiques des membres de la plateforme Technopolice.fr
sur MappemondeConséquence de la transformation des cadres institutionnels du contrôle et de la sécurité, le déploiement de la vidéosurveillance dans l’espace public est aujourd’hui contesté par plusieurs collectifs militants qui s’organisent à travers des modes d’action cartographiques. Leurs pratiques entendent dénoncer, en la visibilisant, une nouvelle dimension techno-sécuritaire des rapports de pouvoir qui structurent l’espace. Grâce aux résultats d’une enquête de terrain menée auprès des membres de la plateforme Technopolice, nous montrons que le rôle stratégique de la cartographie collaborative dans leurs actions politiques réside dans ses fonctions agrégatives et multiscalaires. La diffusion de cartes et leur production apparaissent alors comme des moyens complémentaires, analytiques et symboliques, utilisés par les militants pour mieux appréhender et sensibiliser le public au phénomène auquel ils s’opposent.
-
9:30
La végétalisation de Paris vue au travers d’une carte : une capitale verte ?
sur MappemondeCet article s’intéresse à un dispositif cartographique en ligne proposant de visualiser les projets de végétalisation urbaine entrant dans la politique municipale parisienne. Avec une approche de cartographie critique, nous montrons comment la construction de la carte, et en particulier le choix des figurés et la récolte des données, participe à donner à la capitale française une image de ville verte. Le mélange de données institutionnelles et de données contributives composant la carte du site web Végétalisons Paris traduit l’ambiguïté de la politique de végétalisation parisienne, entre participation citoyenne et instrumentalisation politique.
-
9:30
Géopolitique de l’intégration régionale gazière en Europe centrale et orientale : l’impact du Nord Stream 2
sur MappemondeDépendante des importations de gaz russe, l’Union européenne tente de diversifier ses approvisionnements depuis la crise gazière russo-ukrainienne de 2009. En Europe centrale et orientale, cette politique se traduit par un processus d’intégration régionale des réseaux gaziers. Planifié depuis 2013, ce processus n’a pas connu le développement prévu à cause des divisions engendrées par le lancement du projet de gazoduc Nord Stream 2 porté par Gazprom et plusieurs entreprises énergétiques européennes. Ainsi la dimension externe de la politique énergétique des États membres a un impact sur la dimension interne de la politique énergétique européenne.
-
9:30
Les Petites Cartes du web
sur MappemondeLes Petites Cartes du web est un ouvrage de 70 pages de Matthieu Noucher, chargé de recherche au laboratoire Passages (Bordeaux). Il s’adresse à un public universitaire ainsi qu’à toute personne intéressée par la cartographie. Son objet est l’analyse des « petites cartes du web », ces cartes diffusées sur internet et réalisées ou réutilisées par des non-professionnel?les. Elles sont définies de trois manières :
-
historique, comme des cartes en rupture avec les « grands récits » de la discipline ;
-
politique, comme des cartes « mineures », produites hors des sphères étatiques et dominantes ;
-
technique, en référence aux « petites formes du web » d’É. Candel, V. Jeanne-Perrier et E. Souchier (2012), participant à un « renouvellement des formes d’écriture géographique ».
Ce bref ouvrage, préfacé par Gilles Palsky, comprend trois chapitres. Les deux premiers, théoriques, portent l’un sur la « profusion des “petites cartes” » et l’autre sur l’actualisation de la critique de la cartographie. L...
-
-
9:30
L’Amérique latine
sur MappemondeEn choisissant de commencer son ouvrage par la définition du terme « latine », Sébastien Velut donne le ton d’une approche culturelle et géopolitique de cette région centrale et méridionale du continent américain. Grâce à une riche expérience, il présente ce « grand ensemble flou » (p. 11), ce continent imprévu qui s’est forgé depuis cinq siècles par une constante ouverture au Monde. L’ouvrage, destiné à la préparation des concours de l’enseignement, offre une riche analyse géographique, nourrie de travaux récents en géographie et en sciences sociales, soutenue par une bibliographie essentielle en fin de chaque partie. L’exercice est difficile mais le propos est clair, explicite et pédagogique pour documenter l’organisation des territoires de l’Amérique latine. En ouverture de chaque partie et chapitre, l’auteur pose de précieuses définitions et mises en contexte des concepts utilisés pour décrire les processus en œuvre dans les relations entre environnement et sociétés.
En presque 3...
-
9:30
Les cartes de l’action publique. Pouvoirs, territoires, résistances
sur MappemondeLes cartes de l’action publique, ouvrage issu du colloque du même nom qui s’est déroulé en avril 2018 à Paris, se présente comme une recension de cas d’étude provenant de plusieurs disciplines des sciences sociales. Sociologues, politistes et géographes proposent au cours des 14 chapitres de l’ouvrage (scindé en quatre parties) une série d’analyses critiques de cartes dont il est résolument admis, notamment depuis J. B. Harley (1989), qu’elles ne sont pas neutres et dénuées d’intentionnalités. Cette position, assumée dès l’introduction, sert de postulat général pour une exploration de « l’usage politique des cartes, dans l’action publique et dans l’action collective » (p. 12).
Les auteurs de la première partie, intitulée « Représenter et instituer », approchent tout d’abord les cartes de l’action publique par leur capacité à instituer et à administrer des territoires.
Dans un premier chapitre, Antoine Courmont traite des systèmes d’information géographique (SIG) sous l’angle des scien...
-
9:30
Vulnérabilités à l’érosion littorale : cartographie de quatre cas antillais et métropolitains
sur MappemondeL’érosion littorale est un phénomène naturel tangible dont la préoccupation croissante, compte tenu du changement climatique, nous a menées à travailler sur la problématique de la cartographie de certaines composantes du risque d’érosion comprenant l’étude de l’aléa et de la vulnérabilité. Les terrains guadeloupéens (Capesterre-Belle-Eau et Deshaies) et métropolitains (Lacanau et Biarritz) ont été choisis, présentant une grande diversité d’enjeux. À partir d’un assortiment de facteurs, puis de variables associées à ces notions, la spatialisation d’indices à partir de données dédiées permettrait d’aider les décideurs locaux dans leurs choix de priorisation des enjeux et de mener une réflexion plus globale sur la gestion des risques.
-
9:30
La construction d’une exception territoriale : L’éducation à la nature par les classes de mer finistériennes
sur MappemondeLes classes de mer, inventées en 1964 dans le Finistère, restent encore aujourd’hui très implantées localement. Dépassant la seule sphère éducative, ce dispositif est soutenu par des acteurs touristiques et politiques qui ont participé à positionner le territoire comme pionnier puis modèle de référence en la matière à l’échelle nationale. Tout en continuant à répondre aux injonctions institutionnelles, poussant à la construction d’un rapport normalisé à la nature (développement durable, éco-citoyenneté), cette territorialisation du dispositif singularise la nature à laquelle les élèves sont éduqués.
-
Virtual Reality OpenStreetMap
sur Google Maps Maniaosm4vr is a virtual reality world built using OpenStreetMap map tiles and building footprints. Using osm4vr with a VR headset you can explore the world in virtual reality. Alternatively, if you don't have access to a headset you can simply fly around the world in your browser instead.Most of the 3d buildings are created using OSM building footprints with building heights, so the graphics can be
-
2:00
GeoServer Team: GeoServer 2024 Q3 Developer Update
sur Planet OSGeoThis is a follow up to 2024 roadmap post outlining development opportunities.
First of all thanks to developers and organisations that have responded with offers of in-kind contributions. This blog post is assessing current progress and outlines a way forward to complete the Java 17/Jakarta EE/Spring 6 upgrades.
This post highlights development activities that are available to be worked on today, along with interested developers and commercial support providers available to work on GeoServer roadmap items.
Spring Framework 6 TasksThe key challenge we are building towards is a spring-framework 6 update, ideally by the end of 2024 when the version we use now reaches end-of-life.
The tasks below are steps towards this goal.
Wicket 9 upgradeInterested Parties:
- Brad has been doing amazing work with the Wicket 9 upgrade and is in need of assistance.
- GeoCat has offered to do manual A/B testing when PR is ready for testing.
Activity:
- [GEOS-11275] Wicket 9 upgrade
- geoserver#7154
Spring Security 5.8 provides a safe stepping stone ahead of the complete spring-framework 6 upgrade and is an activity that can be worked on immediately.
Interested parties:
- Andreas Watermeyer (ITS Digital Solutions) offered to work on this activity in during the initial January call out, and has indicated they are now ready to start.
Activity:
- [GEOS-11271] Upgrade spring-security to 5.8
The spring-security-oauth client has reached end-of-life and a GeoServer OAuth2 support must be rewritten or migrated as a result.
There are two paths to migrate to spring-security-core implementation:
-
Option: Migrate the existing community module implementations to spring-security-core in place; with as little loss of functionality as possible. This has the advantage of using existing test coverage to maintain a consistent set of functionality during migration.
-
Option: Setup a community module alongside the existing implementation with the goal of making a full supported etension. This approach has the advantages of allowing organisations the ability to do A/B testing as both the old and new implementation would be available alongside each other. This has the advantage of allowing stakeholders to only fund, implement, test functionality as required without disrupting existing use.
Security integrations often require infrastructure to develop and test against, which the core GeoServer team does not have access to for automated tests. We would like to see organisations review their security integration requirements and be on hand to support this development activity.
The initial priority will support for OAuth2 and Open ID Connect (OIDC), parties interested in maintaining support for Google, GeoNode, GitHub are welcome to participate.
Interested Parties:
- Andreas Watermeyer (ITS Digital Solutions) offered to work on this activity, or test as needed.
- GeoCat is interested in this work also, with the goal of bringing the OIDC plugin up to full extension status (if financing is available).
Activity: not started
- [GEOS-11272] spring-security-oauth replacement, with spring-security 5.8
The image processing library used by GeoServer has been donated to the open source community under the name ImageN.
The immediate goal has been to add test cases to this codebase and make an ImageN 1.0 release. Andrea has come up with the amazing idea of integrating with JAI-Ext project immediately, to benefit from the improved operators, and jumpstart test coverage.
Interested Parties:
- Jody (GeoCat) is available to support this activity, or take lead if funding is available.
- Andrea (GeoSolutions) has had a deep dive into the implications for the JAI-EXT project outlining a roadmap for project integration
We would like to see organisations that depend on GeoServer for earth observation and imagery to step forward with funding for this activity.
2024 Financial support and sponsorshipThus far 2024 has not had a strong enough sponsorship response to support the project goals above. As a point of comparison we established a budget of $15,000 with OSGeo last year to take on an low-level API change that affected several projects.
This year GeoServer sponsorship has raised between $1,000 and $2,000 which is not enough to plan with or coordinate in-kind contributions offered thus far.
Jody has worked with the OSGeo board to make adjustments to the sponsorship:
- Guidance has been provided for appropriate sponsorship levels for individual consultants, small organisation, companies and public institutions of different sizes.
- There are clear examples of how to sponsor and donate, along with the the perks and publicity associated with financial support
- GeoServer has a new sponsorship page on our website collecting this information
- GeoServer now lists sponsors logos on our home page, alongside core contributors.
We would like to thank everyone who has responded thus far:
- Sponsors: How 2 Map, illustreets
- Individual Donations: Peter Rushforth, Marco Lucarelli, Gabriel Roldan, Jody Garnett, Manuel Timita, Andrea Aime
-
13:00
From GIS to Remote Sensing: Semi-Automatic Classification Plugin version 8.3 release date
sur Planet OSGeoThis post is to announce that the new version 8.3 of the Semi-Automatic Classification Plugin (SCP) for QGIS will be released the 3rd of August 2024.This new version will require the new version 0.4 of the Python processing framework Remotior Sensus, and will include several new features such as such as clustering, raster editing and raster zonal stats.
For any comment or question, join the Facebook group or GitHub discussions about the Semi-Automatic Classification Plugin.
-
11:00
Mappery: Which projection is this?
sur Planet OSGeo
I found this nice geo license plate walking by the River Thames. Very geo-nerdy. Happy Sunday!
MapsintheWild Which projection is this?
-
15:41
From GIS to Remote Sensing: Remotior Sensus Update: Version 0.4
sur Planet OSGeo I'm glad to announce the update of Remotior Sensus to version 0.4.This new version add several new features such as clustering, raster editing and raster zonal stats. Following the complete changelog:
I'm glad to announce the update of Remotior Sensus to version 0.4.This new version add several new features such as clustering, raster editing and raster zonal stats. Following the complete changelog:- Added tool "Band clustering" for unsupervised K-means classification of bandset
- Added tool "Raster edit" for direct editing of pixel values based on vector
- Added tool "Raster zonal stats" for calculating statistics of a raster intersecting a vector.
- Improved the NoData handling for multiprocess calculation
- In "Band clip", "Band dilation", "Band erosion", "Band sieve", "Band neighbor", "Band resample" added the option multiple_resolution to keep original resolution of individual rasters, or use the resolution of the first raster for all the bands
- In "Cross classification" fixed area based accuracy and added kappa hat metric
- In "Band combination" added option no_raster_output to avoid the creation of output raster, producing only the table of combinations
- In "Band calc" replaced nanpercentile with optimized calculation function
- Improved extraction of ROIs in "Band classification"
- Minor bug fixing and removed Requests dependency
-
11:00
Mappery: Corsica
sur Planet OSGeo


-
10 Million Street Views
sur Google Maps ManiaStreet-level imagery such as Google Maps Street View panoramas has become a pivotal resource for many researchers as it can provide a unique perspective on built environments. The ability to access and analyse comprehensive street-level imagery provides researchers with a powerful tool for exploring and understanding urban environments. Accessing comprehensive street level imagery at
-
17:43
GeoNode: Docs For Devs
sur Planet OSGeoGeoNode: Docs For Devs -
17:43
GeoNode: Translate
sur Planet OSGeoGeoNode: Translate -
17:43
GeoNode: Improve
sur Planet OSGeoGeoNode: Improve -
17:43
GeoNode: Future
sur Planet OSGeoGeoNode: Future -
17:43
GeoNode: Patches
sur Planet OSGeoGeoNode: Patches -
17:43
GeoNode: Contribute
sur Planet OSGeoGeoNode: Contribute -
17:43
GeoNode: Extend
sur Planet OSGeoGeoNode: Extend -
17:43
GeoNode: Arch
sur Planet OSGeoGeoNode: Arch -
17:43
GeoNode: Testing
sur Planet OSGeoGeoNode: Testing -
17:43
GeoNode: Env Dev
sur Planet OSGeoGeoNode: Env Dev -
17:43
GeoNode: Management Commands
sur Planet OSGeoGeoNode: Management Commands -
17:43
GeoNode: Backups
sur Planet OSGeoGeoNode: Backups -
17:43
GeoNode: Other Languages
sur Planet OSGeoGeoNode: Other Languages -
17:43
GeoNode: Ssl
sur Planet OSGeoGeoNode: Ssl -
17:43
GeoNode: Troubleshoot
sur Planet OSGeoGeoNode: Troubleshoot -
17:43
GeoNode: Customize Geonode
sur Planet OSGeoGeoNode: Customize Geonode -
17:43
GeoNode: Production Geonode
sur Planet OSGeoGeoNode: Production Geonode -
17:43
GeoNode: Install Geonode
sur Planet OSGeoGeoNode: Install Geonode -
17:43
GeoNode: Share Map
sur Planet OSGeoGeoNode: Share Map -
17:43
GeoNode: Find Map
sur Planet OSGeoGeoNode: Find Map -
17:43
GeoNode: Create Map
sur Planet OSGeoGeoNode: Create Map -
17:43
GeoNode: Add Data
sur Planet OSGeoGeoNode: Add Data -
17:43
GeoNode: New Account
sur Planet OSGeoGeoNode: New Account -
17:43
GeoNode: Tutorials
sur Planet OSGeoGeoNode: Tutorials -
14:27
GeoTools Team: GeoTools 31.3 released
sur Planet OSGeo GeoTools 31.3 released The GeoTools team is pleased to announce the release of the latest maintenance version of GeoTools 31.3: geotools-31.3-bin.zip geotools-31.3-doc.zip geotools-31.3-userguide.zip geotools-31.3-project.zip This release is also available from the OSGeo Maven Repository and is made in conjunction with GeoServer 2.25.3 We -
13:17
Adam Steer: Mapping a small farm part 3: using an aerial orthophoto
sur Planet OSGeoPart 1 of this series looked at how to fly drones and collect imagery for mapping over a small property. Part 2 showed use cases for a digital elevation model. This story focusses on the georeferenced imagery produced in the process. It will look at three use cases – and explain some of the limitations:… Read More »Mapping a small farm part 3: using an aerial orthophoto
-
30 Days of Crashes in New York City
sur Google Maps ManiaBetween June 16th and July 15th, 149 people were injured by cars in the planned New York congestion zone and 4 people were killed.At the beginning of June New York Governor Kathy Hochul canceled New York City’s planned congestion zone. Under the planned congestion zone vehicles traveling into or within the central business district of Manhattan would have been charged a fee. In response to
-
11:00
Mappery: Armchair
sur Planet OSGeo

It is a bit unusual, but we found this one on LinkedIn. Chris Chambers received this armchair as a birthday gift.
MapsintheWild Armchair
-
Les données Overture Maps dans ArcGIS
sur arcOrama, un blog sur les SIG, ceux d ESRI en particulierEn début d'année 2023, je vous annonçais qu'Esri avait rejoint la fondation Overture Maps pour supporter ses travaux de création de données cartographiques plus complètes, précises et extensible dans le cadre d'une licence Open Data. Depuis, Overture Maps a accueillis beaucoup de nouveaux membres et a pu proposer plusieurs itérations de ses schémas de données et de ses données Open Data. En avril dernier, Overture Maps a publié des versions beta des schémas et des thèmes de données (base, building, division, places et transportation). Ces thèmes de données vont être disponibles officiellement dans les semaines à venir.
Depuis qu'Esri a rejoint Overture, les équipes du Living Atlas ont contribué en apportant des données sur différents thèmes, notamment sur les bâtiments et les unités administratives (divisions). Esri collabore également sur la création de nouveaux thèmes notamment les adresses. Dans le même temps, Esri travaille sur l'exploitation de ces données dans ArcGIS pour améliorer les contenus existants mais aussi pour proposer de nouveaux contenus. Dans cet article, je vous présente comment ces nouvelles données vont être mis à disposition des utilisateurs ArcGIS dès qu'ils seront officiellement disponibles.
Evolution des fonds de carte 2D
Depuis plusieurs années, Esri développe et héberge une série de fonds de carte basés sur la distribution Daylight d'OpenStreetMap (OSM). Meta a récemment annoncé que cette distribution Daylight entrera en support mature dans les prochains mois. En conséquence, Esri annonce que le fond de carte vectoriel OpenStreetMap entrera en support en décembre 2024, ce qui signifie qu'elle ne sera plus mise à jour même si elle restera disponible au minimum jusqu'en 2026 (et probablement au-delà). Pour le remplacer, Esri va introduire un nouveau fond de carte intégrant des données Open Data dont OpenStreetMap.
Plus tard dans l'année, Esri proposera un nouveau fond de carte ouvert qui sera construit sur les données Overture Maps. Ce nouveau fond de carte "Open Basemap" sera conçu et délivré sous la forme d'une couche de tuiles vectorielles avec différents styles de rendu. Ces styles pourront facilement être personnalisés. Ce fond "Open Basemap" intégrera les couches de chaque thème des données Overture et tire profit du schéma de données structurées qui permettra un personnalisation plus simple des styles de ce fond de carte. Le fond de carte "Open Basemap" sera disponible en beta d'ici quelques mois et sera mise à jour de manière mensuelle.Version alpha du futur fond de carte "Open Basemap" en préparation pour unn usage dans ArcGIS
Au-delà de ce nouveau fond de carte, Esri utilisera également les données Overture pour mettre à jour certaines parties du fond de carte vectoriel Esri (Esri Vector Basemap) lorsque ces dernières seront les meilleures données disponibles. Le fond de carte Esri est le fond de carte par défaut dans ArcGIS, il est élaboré par Esri à partir de données commerciales, communautaire et Open Data. Cependant, dans certaines parties du monde (par exemple certaines zone sen Afrique, Asie et Amérique Latine), Esri utilisera les données Overture pour plusieurs couches (bâtiments, Transports et Lieux). Dans d'autres zones du globe, Esri pourra améliorer la couverture existante sur des couches spécifiques (notamment pour les bâtiments).
Evolution des fonds de carte 3D
En 2023, Esri a introduit une série de fonds de carte 3D qui, eux aussi, sont élaborés à partir de la distribution OSM Daylight de Meta et amélioré avec des données de la carte communautaire Esri. Depuis la mise en ligne de ces fonds de carte 3D, Esri a commencé à travailler avec d'autres membres de la fondation Overture Maps pour intégrer plus de bâtiments avec des attributs 3D dans les données Overture, notamment les hauteurs de bâtiments provenant de LiDAR Open Data et les données des contributeurs d'Esri Community Maps.
Esri proposera de nouvelles couches de scène 3D pour les bâtiments, les arbres et les étiquettes de lieux, créées à partir des données Overture Maps et utilisées pour mettre à jour les fonds de carte 3D existants dans la galerie de fonds de carte. Ces couches de scène incluront des données ouvertes d'OpenStreetMap, des cartes communautaires Esri, ainsi que d'autres données ouvertes de Microsoft et de Google.Version alpha de la couche de scène de bâtiments 3D en cours de préparation pour ArcGIS.
En outre, on notera qu'Esri utilisera également les données Overture pour mettre à jour une grande parties de la nouvelle couche de scène de bâtiments 3D Esri, désormais disponible en version beta. Cette couche de bâtiments 3D Esri est construite à partir de données provenant de sources de données commerciales, communautaires et ouvertes. Esri utilisera les données des bâtiments Overture pour ajouter une couverture là où les données commerciales ou communautaires ne sont pas disponibles.
Couches d'entités
Les offres décrites ci-dessus prennent en charge la visualisation 2D et 3D et contribuent à fournir une base solide pour votre travail, mais les données Overture sont conçues pour être utilisées à d'autres fins que la simple visualisation à travers des fonds de carte. Les données Overture sont destinées à prendre en charge d'autres cas d'utilisation, notamment l'enrichissement des données et l'analyse spatiale. Les données Overture incluent un système de référence d'entité globale (GERS) qui attribue un identifiant persistant à chaque entité de la base de données, qui peut être utilisé pour faire correspondre d'autres entités de différents jeux de données.
Esri anticipe que de nombreux utilisateurs d'ArcGIS souhaiteront publier des données Overture sous forme de couches d'entités hébergées, à la fois dans ArcGIS Online et ArcGIS Enterprise. Les utilisateurs peuvent vouloir publier des thèmes de données spécifiques (par exemple, des bâtiments, des routes, des limites) pour leur zone d'intérêt (par exemple, une ville, un département, un pays,...), puis utiliser les outils d'analyse spatiale d'ArcGIS pour joindre les données Overture à leurs propres données afin de les utiliser dans des cartes et des applications web. Étant donné que les données Overture sont ouvertes, les utilisateurs peuvent les intégrer dans leurs propres systèmes d'enregistrement pour les utiliser à des fins de cartographie, d'analyse et de création de contenu.Bâtiments Overture pour les États-Unis (CONUS) symbolisés par la classe
Esri contribuera à fournir un accès aux données Overture dans son environnement de stockage cloud ArcGIS Online afin qu'elles soient prêtes à l'emploi dans le logiciel ArcGIS. Bien qu'Esri assure la publication de ces données Overture sous forme de couches d'entités hébergées pour certains thèmes de données et domaines d'intérêt populaires (comme ci-dessus), les utilisateurs sont encouragés à publier leurs propres couches d'entités hébergées pour leurs domaines d'intérêt afin qu'ils aient un contrôle total sur l'utilisation des données ouvertes selon leurs besoins dans leurs systèmes.
Je reviendrai, bien entendu, sur ce sujet lors de la publication effective de ces nouveaux fonds de carte 2D et 3D ainsi que sur les couches d'entités hébergées sur le Living Atlas.




-
2:00
Camptocamp: Optimizing Trail Management: Mergin Maps for Greater Annecy
sur Planet OSGeoPièce jointe: [télécharger]
Grand Annecy turned to Camptocamp to find the tool best suited to their needs.
-
DbToolsBundle : sortie de la version 1.2
sur Makina CorpusDécouvrez les nouveautés de cette nouvelle version ainsi que les fonctionnalités à venir de la prochaine version majeure.
-
14:00
Le constat : les calculs géométriques ne sont pas bons
sur Geotribu Deuxième partie du tour d'horizon des SIG sur la précision des calculs géométriques : analyse des opérations de superposition et de leurs limites.
Deuxième partie du tour d'horizon des SIG sur la précision des calculs géométriques : analyse des opérations de superposition et de leurs limites.
-
The 2024 European Election Map
sur Google Maps ManiaZeit has created an interactive map which visualizes the results in the 2024 European Union elections in 83,000 municipalities. The map in Explore Europe's Most Detailed Electoral Map colors each electoral area in Europe based on the politics of the leading candidate in the election.The map allows you to compare the 2024 European Union election results with the results from 2014 and 2019. By
-
7:30
[Équipe Oslandia] Jean-Marie, développeur C++ / Python
sur OslandiaJean-Marie a toujours aimé l’électronique et tout ce qui touche au traitement du signal. Il rejoint l’INSA Rennes, une école d’ingénieur généraliste en spécialité ESC – Electronique et Systèmes de Communication (aujourd’hui E&T) sur les problématiques télécommunications.
Il réalise son stage de fin d’étude chez Silicom à Rennes sur le sujet « Modélisation de systèmes de communication » sous Matlab avant d’être embauché par la même entreprise mais pour une toute autre mission …le développement d’une application informatique de simulation de réseaux télécom pour la DGA avec QT en C++ !
« Je ne connaissais pas trop l’informatique, quelques notions pendant mes études, mais j’aimais bien, ça me plaisait de pouvoir me lancer là dedans. J’ai acquis des connaissances en pratiquant, c’est comme ça qu’on apprend ! »
Ensuite, Jean-Marie saisit l’opportunité de travailler sur le passage au tout numérique via la TNT. « J’ai travaillé pendant 2 ans et demi au CSA, j’ai réalisé des études sur la planification de fréquences, étudié les couvertures des émetteurs TNT. C’était une super expérience, j’ai travaillé sur un projet qui a impacté les français au quotidien ! »
De retour à Rennes, il reprend le développement en C++ avec QT, notamment pour un projet d’analyse de signaux sismiques du CEA et découvre QGIS. Une nouvelle compétence qu’il mobilise pour la DGA et le développement d’un outil basé sur QGIS pour l’affichage de données relatives à l’aide à la planification de missions satellites.
« 14 ans chez Silicom, il était temps de passer à autre chose »
Jean-Marie rejoint Oslandia en novembre 2021 en tant que développeur C++ / Python où il réalise des missions de développement et DevOps, notamment pour Viamichelin sur la refonte du calcul d’itinéraire de l’outil en ligne ou pour l’IGN pour la mise en place du calcul d’itinéraire sur la nouvelle Géoplateforme.
Projet emblématiqueJean-Marie a produit 80% du code d’OpenLog, un outil de visualisation de données de sondage open source porté par Apeiron (filiale d’Oslandia).
« Ce projet m’a permis de mobiliser mes connaissances sur la représentation de données »
Technologies de prédilectionPython et C++
Ta philosophieLe partage ! Ce qu’on produit peut être utilisé par d’autres, nous partageons nos connaissances et notre travail !
Oslandia en 1 motOuverture par rapport à l’open source et dans le sens où tout est transparent dans l’entreprise, tout le monde peut donner son avis, les décisions sont prises collectivement.
-
19:47
SIG Libre Uruguay: Va una más…
sur Planet OSGeo -
19:45
gvSIG Batoví: edición 2024 del concurso: Proyectos de Geografía con estudiantes y gvSIG Batoví
sur Planet OSGeo
Habiendo finalizado con éxito la etapa de capacitación de la iniciativa Geoalfabetización mediante la utilización de Tecnologías de la Información Geográfica, lanzamos la convocatoria a participar de la edición 2024 del concurso: Proyectos de Geografía con estudiantes y gvSIG Batoví. Organizan Ceibal, la Dirección Nacional de Topografía del Ministerio de Transporte y Obras Públicas (MTOP), la Inspección Nacional de Geografía y Geología de la Dirección General de Educación Secundaria (DGES), junto con la Universidad Politécnica de Madrid (UPM). Pueden acceder aquí a la convocatoria y bases.
Este año contamos con la colaboración de la Dirección General de Educación Técnica Profesional (DGETP), la Asociación Nacional de Profesores de Geografía (ANPG) y la Universidad Central “Marta Abreu” de Las Villas (Cuba).
Agradecemos el apoyo de todas las instituciones que hacen posible la realización de esta propuesta.

-
13:57
Publication du rapport annuel du CNIG 2023
sur Conseil national de l'information géolocaliséeLe rapport annuel du CNIG est sorti : le CNIG dans toutes ses dimensions
-
11:00
Mappery: The Cure for Anything is Salt Water
sur Planet OSGeo
Darrell Fuhriman sent me these pics from the Salt Pub in Ilwaco, Washington.
“They decorated with old nautical charts, including a lamp shade and wallpaper on the stairs and entryway. “

The stairs reference a quote by author Isak Dinesen. “The cure for anything is salt water — sweat, tears, or the sea.”
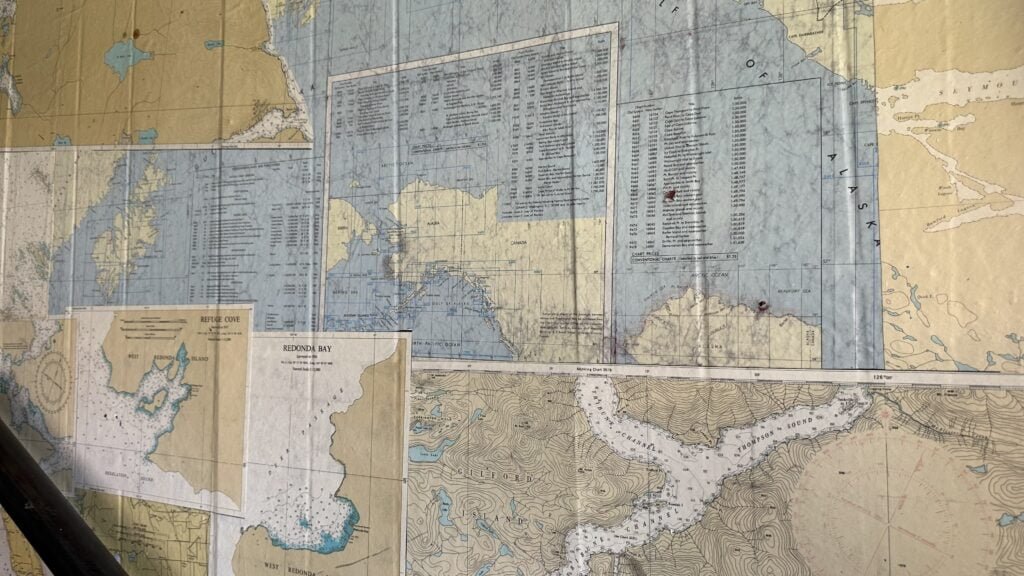
MapsintheWild The Cure for Anything is Salt Water
-
Battles of World War II & American Wars
sur Google Maps ManiaHistoryMaps has been very busy in the last few weeks, releasing new interactive maps visualizing the:Battles of World War IIBattles of the American RevolutionBattles of the American Civil War Nono Umasy's HistoryMaps website is a fantastic resource for anyone interested in world history, offering hundreds of interactive timelines and maps that explore historical events across the scope of
-
ArcGIS CityEngine 2024.0 est disponible
sur arcOrama, un blog sur les SIG, ceux d ESRI en particulier
ArcGIS CityEngine 2024.0 est désormais disponible et cette nouvelle version est vraiment très intéressante, notamment avec la sortie de la phase beta du Visual CGA (VCGA), des améliorations dans la collaboration avec ArcGIS Urban ou encore le nouveau workflow de création rapide de scènes web. Cette version est truffée de petites améliorations qui, je l'espère, vous aiderons dans vos tâches de génération d'environnements urbains... Voyons cela plus en détails.
Editeur visuel de règles CGA
L'éditeur "Visual CGA" n'est désormais plus en beta, il est officiellement supporté et désormais disponible pour tous. Cet outil simplifie les flux de travail et va changer la donne pour les utilisateurs qui n'ont pas de compétences approfondies dans la rédaction de règle avec du code CGA : les architectes, les urbanistes et les concepteurs pourront explorer les modèles plus facilement que jamais. La bibliothèque intégrée de contenus introduit également un ensemble de composants avancés pour le partitionnement et le regroupement de sites dans cette version.

Pour en savoir plus, vous pouvez consulter cette playlist de tutoriels.
Intégration avec ArcGIS Urban
Cette version de CityEngine, ainsi que la version actuelle d'ArcGIS Urban, permettent désormais aux utilisateurs d'ArcGIS Urban de modifier l'altitude ou la couche d'altitude d'un plan dans ArcGIS Urban. Lors de l'import d'un plan ArcGIS Urban dans CityEngine, ces couches sont automatiquement importées en tant que couches de terrain distinctes, une par scénario. Vous pouvez ensuite modifier le terrain à l'aide des outils de modification de MNT intuitifs de CityEngine afin qu'il corresponde parfaitement à votre scénario. Après avoir modifié le terrain, vous pouvez facilement le télécharger à nouveau dans votre scénario ArcGIS Urban.

Partager en tant que scènes web
Une solution simple de partage direct depuis CityEngine vers ArcGIS Online est désormais disponible, vous permettant d'exporter et de visualiser rapidement votre scène 3D dans des application comme ArcGIS Scene Viewer, ArcGIS Dashboards, ArcGIS Experience Builder ou encore ArcGIS Earth. La fonctionnalité "PShare as Web Scene" facilite plus que jamais le partage, l'export et l'organisation de plusieurs scénarios dans ArcGIS Online.

Collection et navigateur de matériaux
Les utilisateurs ont désormais accès à une nouvelle collection complète de matériaux de haute qualité qui peuvent être utilisés pour ajouter de la texture à vos bâtiments, aux espaces ouverts tels que les jardins, et bien plus encore. Vous y accéderez via un navigateur dédié...

CityEngine est désormais inclus dans les types d'utilisateurs ArcGIS
Dernière évolution majeure, et pas des moindres, CityEngine est désormais inclus dans le nouveau type d'utilisateur "Professional Plus" (anciennement appelé ArcGIS Profesionnal Advanced) et disponible en option pour les types d'utilisateur "Creator" et "Professional" (anciennement appelé ArcGIS Profesionnal Standard).
Pour un aperçu complet des autres nouveautés et améliorations de CityEngine, vous pouvez consulter les notes de version.






-
14:34
GeoSolutions: FOSS4G North America: GeoSolutions Sponsoring FOSS4GNA – Workshops, and Presentations
sur Planet OSGeoYou must be logged into the site to view this content.
-
14:00
De la tolérance en SIG
sur Geotribu Un tour d'horizon des SIG sur la précision des calculs géométriques.
Un tour d'horizon des SIG sur la précision des calculs géométriques.
-
11:00
Mappery: Origin of the Species
sur Planet OSGeo
Reinder took this pic in a neighbourhood orchard “. along the river Saône in Lyon, named after a local heroine Mere Guy”
“In the 2nd arrondissement, the orchard created at Place Général Delfosse was named in honor of Mere Guy. A pioneer of the Meres de Lyon, she opened her restaurant in 1759 on the banks of the Rhône at Mulatière. She serves fish provided by her husband, a traditional fisherman, including her signature dish: eel matelote.” (Apologies for my translation)
[https:]The map shows the origins of the various species in the orchard
MapsintheWild Origin of the Species
-
10:27
Une vision multiscalaire des rapports de force politiques
sur Carnet (neo)cartographiqueCamarades cartographes, nous sortons d’une séquence politique inédite. Le pays semble fracturé en trois blocs avec une extrême droite au plus haut. Mais comment rendre compte cartographiquement des clivages géographiques qui fracturent le pays ?
Dans un billet réalisé avec Antoine Beroud et Ronan Ysebaert pour le journal l’Humanité (voir), nous proposons une série de cartes avec des représentations continues à plusieurs échelles. La méthode d’interpolation spatiale utilisée ici est connue sous le nom de potentiel, de potentiel gravitationnel ou d’accessibilité gravitationnelle. Le concept a été développé dans les années 1940 par le physicien John Q. Stewart à partir d’une analogie avec le modèle gravitationnel. Ce potentiel est défini comme un stock – un nombre de voix – pondéré par une distance définie ici par une fonction gaussienne (courbe en cloche). En faisant varier la portée de cette fonction, l’algorithme permet de dessiner des cartes plus ou moins généralisées pour montrer les grandes structures spatiales selon différentes échelles d’analyse, en faisant abstraction des irrégularités du maillage sous-jacent.
In fine, la méthode permet de rendre compte avec différents filtres d’observation, des lignes de force des différents blocs politiques qui structurent géographiquement le pays.
Bloc de gauche

Bloc de droite

Bloc d’extrême droite

Des comparaisons deux à deux sont également possibles.

Article initial et explications méthodologiques : [https:]]
Code source : [https:]] & [https:]]
Ingénieur de recherche CNRS en sciences de l'information géographique. Membre de l'UMS RIATE et du réseau MIGREUROP / CNRS research engineer in geographical information sciences. Member of UMS RIATE and the MIGREUROP network.
Follow Me:


-
10:20
Incident en cours sur le téléchargement
sur Toute l’actualité des Geoservices de l'IGN Incident en cours sur le téléchargement
Incident en cours sur le téléchargement -
10:20
Incident en cours sur le téléchargement (résolu)
sur Toute l’actualité des Geoservices de l'IGN
Incident en cours sur le téléchargement (résolu)
-
Nouveautés Geotrek : le volet éditorial s'étoffe pour répondre à tous vos besoins
sur Makina CorpusLe Parc National des Écrins a modernisé son portail Rando Pays des Écrins avec de nouvelles fonctionnalités éditoriales et de navigation.
-
Your Urban Heat Island Score
sur Google Maps ManiaClimate Central has mapped out the urban heat island hot-spots in 65 major U.S. cities. Each city map on Climate Central's Urban Heat Hot Spots shows an Urban Heat Island (UHI) Index score for each census tract, revealing where UHI boosts temperatures the most and least in each city.As well as providing individual UHI maps for 65 cities Climate Central has also released a national interactive
-
7:10
Adam Steer: Mapping a small farm part 2: microhydrology
sur Planet OSGeoThis is the first sequel to Mapping a small farm part 1. To summarise the first story, it walks through flight planning and practice, then data processing to get some first cut products, and a bit of mapping to show ideas about how accurate we think the product is. The products we’re interested in now… Read More »Mapping a small farm part 2: microhydrology
-
7:04
TerriSTORY® – Une histoire de territoires OpenSource
sur OslandiaLorsque nous avons commencé à travailler sur Terristory en 2018, c’était alors un POC (Proof Of Concept) commandé par AURA-EE, Auvergne Rhône-Alpes Énergie Environnement. Le premier sprint devait convaincre de la faisabilité et projeter les ambitions de l’association. 6 ans plus tard, la plateforme devenue publique est un projet OpenSource maintenu de façon autonome directement par AURA-EE.
Le développement de la plateforme s’est déroulé sur plusieurs années. Au départ Oslandia était le prestataire chargé de réaliser et conseiller l’AURA-EE sur le projet, mais il était prévu aussi de former petit à petit les équipes côté association et de transmettre le savoir pour un jour permettre une totale autonomie. En parallèle, il y avait une volonté forte de la part d’Oslandia d’arriver à terme à une ouverture du code source de l’application, ce qui était également une volonté d’AURA-EE dès le départ.
Publier le code source d’une application (ici un site web) n’est pas forcément une tâche difficile en apparence. On pourrait penser qu’il s’agit juste de créer un répertoire gitlab et d’y déposer le code. Dans les faits, c’est ce qui se passe. Néanmoins, une bonne préparation en amont est nécessaire si on souhaite une ouverture de qualité.
De nombreuses questions se bousculent alorsQuand doit-on publier ? Est-ce que la documentation est prête ? Dois-je traduire en anglais ? A-t-on résolu tous les bugs critiques ? Comment va se passer la publicité ? Y-a-t il un formalisme à respecter ? Les aspects juridiques sont-ils couverts ? Est-on prêt à recevoir les retours de la communauté ?
Les étapesLa première chose à faire était de choisir la licence. Dans le cas de Terristory c’est la GNU Affero (ou AGPL) version 3 qui a été sélectionnée, après étude des tenants et des aboutissants. Ici il s’agit d’un outil serveur, sur lequel AURA-EE et les différents partenaires impliqués au sein d’un consortium national voulaient que les modifications faites par les utilisateurs soient reversées.
Un premier travail de documentation et de structuration du code a été entrepris par AURA-EE. Avoir une bonne documentation, des guidelines sont essentiels pour s’assurer que toute personne intéressée par la réutilisation ou par la contribution au code puisse aisément installer, tester et ajouter de nouvelles fonctionnalités.
Le code de Terristory a également connu de nombreuses phases de refactoring, c’est à dire de réécriture de certaines parties parce qu’obsolète, pas assez efficaces ou suite à des changements de librairies utilisées. Outre les évolutions fonctionnelle d’une telle application, le refactoring constitue une partie importante de la vie du logiciel. D’autant plus sur les applications Web où les avancées technologiques sont rapides. Il faut maintenir le code, et suivre l’évolution des librairies sous-jacentes si on veut pouvoir faire évoluer le site plus facilement et par un maximum de personnes. Côté Oslandia, nous anticipons au mieux ces phases de développement pour éviter le jour J de devoir faire une revue totale et potentiellement complexe du code juste avant la publication.
Oslandia a accompagné AURA-EE sur toutes ces années, et a réussi à lui transmettre la culture de l’OpenSource, aussi bien techniquement que dans les méthodes de travail. Ainsi, les collaborateurs d’AURA-EE sont vite devenus des utilisateurs experts de Gitlab, des utilisateurs experts de la solution, puis des développeurs de l’application, pour enfin procéder eux-même à la libération publique du code. En tant qu’ancien développeur principal de l’application pendant plusieurs années, je suis personnellement assez fier du travail accompli et de la manière dont les choses se sont déroulées.
[Témoignage]Pierrick Yalamas, Directeur intelligence territoriale et observatoires à Auvergne-Rhône-Alpes Énergie Environnement :
Notre vision
« Oslandia a su nous accompagner durant les premières années du projet TerriSTORY® : des premiers développements à l’appui juridique (choix de la licence) pour l’ouverture du code. L’équipe est maintenant complètement autonome. L’ouverture du code début 2023 a déjà donné lieu (mi-2024) à plusieurs réutilisations, qui permettent d’enrichir les fonctionnalités de TerriSTORY®. »Le projet TerriSTORY® et la manière dont il s’est déroulé correspond à la vision d’Oslandia de la relation client : notre objectif est de fournir les outils et les méthodes permettant aux organisations que nous accompagnons d’être le plus efficace et le plus autonome possible. Et ce, sur tous les aspects d’un projet logiciel : technique, mais aussi organisationnel, juridique, sur l’infrastructure de développement et les process mis en place. Voir des solutions que nous avons ébauchées prendre leur propre autonomie, dans le respect de l’esprit du logiciel libre est une satisfaction et une fierté pour toute l’équipe, et nous sommes reconnaissants à l’AURA-EE de nous avoir fait confiance pour cela.
-
Autorisation de décollage pour ArcGIS Flight !
sur arcOrama, un blog sur les SIG, ceux d ESRI en particulierDepuis plusieurs années maintenant, le système ArcGIS dispose d'une technologie de photogrammétrie numérique de pointe nommée Reality Engine que vous retrouvez dans les solutions Drone2Map, Site Scan et ArcGIS Reality. Cette dernière permet, entre autres, d'utiliser des prises de vue de drones pour générer des produits cartographiques de hautes qualités (MNT, MNE, Orthophoto haute-résolution, Photomaillage 3D, Nuage de points, ...). Pour obtenir les meilleures données géographiques à partir de vos prises de vue drones, il est indispensable de planifier de manière optimum son plan de vol. Pour cette raison, Esri fournit depuis plusieurs années une application de planification de vol qui, aujourd'hui, évolue pour une expérience simplifiée et une intégration plus étroite au système ArcGIS.
La nouvelle application ArcGIS Flight est une nouvelle application mobile qui révolutionne la façon dont les vols de drones sont planifiés et exécutés pour la cartographie et l'inspection de vos territoires avec une intégration au coeur du système ArcGIS. Les opérateurs de drones peuvent accéder en toute simplicité à leur contenu SIG durant la planification du vol, offrant ainsi un contexte métier précieux et une meilleure connaissance du contexte d'opération.
L'application propose différents modes de vol adaptés aux besoins spécifiques de la collecte autour de vos équipements, qu'il s'agisse de cartographier de vastes zones ou d'inspecter des infrastructures plus locales notamment des équipements verticaux (antennes, tours, phares, piles de ponts,...). L'exécution du vol est entièrement automatisée et rejouable, garantissant que l'imagerie collectée est cohérente et de haute qualité. Après le vol, l'application permet un contrôle qualité sur le terrain et une intégration facile des images dans ArcGIS pour le traitement et l'analyse, y compris pour la génération de photomaillage 3D à l'aide du logiciel ArcGIS Reality, ArcGIS Drone2Map ou Site Scan for ArcGIS.
Avec ArcGIS Flight, vous pouvez :
- Choisir parmi différents modes de vol adaptés à différents types de collecte attendus.
- Planifier des vols en s'appuyant sur un contexte 2D ou 3D issu de vos couche SIG.
- Effectuer automatiquement les contrôles sur les aéronefs et exécuter des vols.
- Utiliser la fonction de suivi du terrain pour maintenir la sécurité et une résolution d'image cohérente.
- Effectuer le contrôle de la qualité de l’image en direct sur le site.
- Enregistrer des vidéos et les métadonnées géospatiales associées.
- Intégrer de manière très simple les images ainsi capturées dans ArcGIS pour des traitements et des analyses ultérieurs.
Les nouveautés
ArcGIS Flight est destiné à remplacer les apps existantes "Site Scan Flight" et "Site Scan Flight LE" et marque ainsi une mise à niveau significative de l'offre d'Esri en termes de Reality Capture. Cette application simplifie le processus de planification des missions de drones et de capture des données.
Les nouvelles fonctionnalités et améliorations sont les suivante :
- Une expérience de connexion unifiée : votre compte ArcGIS ou votre compte Site Scan peuvent désormais être utilisés pour s'authentifier.
- Possibilité pour les utilisateurs de type ArcGIS "Mobile Worker", "Creator", "Professional" et "Professional Plus" d'utiliser les pleines capacités de l'application.
- Import de multiples missions.
- Nouvelle expérience de paramétrage.
- Fonctionnalités RTK améliorées avec, notamment, la possibilité d'ajouter de nouveaux fournisseurs de réseau RTK.
- Prise en charge du contrôleur "Pilot Pro" de Freefly.
- Téléchargement automatique de la mission après l'import (nécessite une licence "Site Scan Operator")
- Téléchargement rapide de la mission (nécessite une licence "Site Scan Operator")
Exemple de workflow de vol de base avec ArcGIS Flight
Pour ceux qui ne connaissent pas ArcGIS Flight ou les drones en général, ce flux de travail démontrera les capacités de l'application avec un exemple simple de collecte d'images de drone.
-
Téléchargez l'application ArcGIS Flight depuis l'Apple App Store puis lancez l'application.
-
Connectez-vous en utilisant l’un des types d’utilisateurs sous licence
mentionnés précédemment.
-
Créer ou sélectionner un projet.
-
Connectez votre drone à la tablette exécutant ArcGIS Flight et
sélectionnez le drone avec lequel vous souhaitez voler dans le menu
déroulant en haut à droite.

-
Sélectionnez le plan de vol "Area Survey". Ce plan de vol est le plus
accessible aux débutants pour comprendre le comportement du drone lors
d'un vol autonome.
-
Ajoutez un titre descriptif à votre mission dans la zone "Mission Name".
Les titres efficaces incluent généralement des informations sur la zone
géographique, l'objectif, le client ou le calendrier de votre mission
(par exemple : Wetland_Monitoring_ClientName_June2024).
-
Spécifiez la zone géographique la plus proche de votre site en tapant
dans la boîte de dialogue "Mission Location" et sélectionnez "Next"
.
-
Utilisez l'onglet "Mission Settings" pour personnaliser les
paramètres régissant le vol de votre drone (hauteur de vol, mode vidéo).
Faites glisser et déplacez l'un des sommets du polygone de vol pour
modifier la forme de la zone de mission.
-
Lorsque vous êtes prêt à décoller, sélectionnez "Fly". Cette fonction
effectuera automatiquement des vérifications sur le système de caméra de
votre drone et sur les niveaux de batterie pour garantir un vol en toute
sécurité tout au long de votre mission. Si toutes les vérifications ont
été effectuées avec succès, faites glisser la flèche verte vers la
droite pour lancer le lancement.

-
Vous pouvez désormais observer en temps réel la trajectoire de vol de
votre drone, en collectant des images aériennes pour générer des
orthomosaïques, des nuages ??de points et des maillages 3D. La zone de
carte principale indique l'emplacement réel de votre drone, et le flux
vidéo dans le coin montre un flux en direct du point de vue de votre
drone.
-
Une fois votre mission terminée, votre drone reviendra au-dessus du
point de décollage et descendra automatiquement pour effectuer un
atterrissage en toute sécurité.
-
Pour collecter les images recueillies pendant le vol, sélectionnez le
bouton "Get Images" dans la fenêtre de fin de mission.
-
Les images peuvent être importées du drone vers la tablette à l'aide
d'une connexion WiFi avec l'option "Wireless Import", ou
directement en retirant la carte SD du drone du véhicule et en copiant
les images de la carte avec l'option "Memory Card Import".
-
Choisissez la méthode souhaitée et sélectionnez "Import". La
progression de l'importation de chaque image collectée sera visible dans
la fenêtre inférieure. Une fois importées, les images apparaîtront dans
la fenêtre de carte supérieure à leur emplacement réel.
- Si vous êtes connecté avec un compte Site Scan, les images importées sur l'appareil peuvent être téléchargées sur Site Scan en sélectionnant "Upload Images".
Voilà, vous avez planifié et exécuté une mission de drone simple au-dessus d'une zone choisie à l'aide d'ArcGIS Flight. Les vols de drones collectent des images haute fidélité sur de vastes zones de manière minimalement invasive, ce qui est utile dans de nombreux secteurs, notamment l'AEC, l'exploitation minière, les transports, les services publics et les ressources naturelles et le gouvernement. Pour plus d'informations sur ArcGIS Flight, restez en contact avec l'équipe en rejoignant la page Esri Community dédiée à ArcGIS Flight.

{kind=link}
-
2:00
Ian Turton's Blog: Adding a spell check to QGIS
sur Planet OSGeoAdding a Spell Check to QGIS(Or what to do on a rainy bank holiday in Glasgow)
This Monday was a local bank holiday in Glasgow (or at least the university) as a remnant of when the whole town took a train to Blackpool in the same two weeks so that the ship builders and steel works could stop in a coordinated fashion. As is required in the UK the weather was awful so I stayed in and being bored looked at my long list of possible projects. I picked one that has been kicking around on the list for a while adding a spell checker for QGIS. As a dyslexic I have spell checking turned on in nearly every program I enter text into including
vim,InteliJand my browser. So I have always felt that what QGIS really needed was a way to spell check maps before I printed them at A3 and put them on the wall.Back in 2019 North Road wrote a iblog post about custom layout checks and ended it with a throw away comment “It’d even be possible to hook into one of the available Python spell checking libraries to write a spelling check!”. I came across this when I was trying to see if there was an easy way for my students (many of whom have English as a second language) to avoid handing in projects with glaring (i.e. I can see them) spelling errors in the title. So I stuck the link on my backlog, until the proverbial rainy day came along.
ImplementationObviously I’m the last person who should be allowed to write spell checking software, but the joy of open source is that for things like this someone else has almost certainly already done it. So a quick duck-duck-go found me installing
pyspellcheckwhich seemed like it would do what I want. It has a pretty easy interface in that once you’ve created a spell checker object, you can just pass in a list of words and it will return a list of (probably) misspelled words and a method to give the most likely correction and another method to give you list of other possibilities. Armed with this I could create a method to find and check all the text elements of a print layout.@check.register(type=QgsAbstractValidityCheck.TypeLayoutCheck) def layout_check_spelling(context, feedback): layout = context.layout results = [] checker = SpellChecker() for i in layout.items(): if isinstance(i, QgsLayoutItemLabel): text = i.currentText() tokens = [word.strip(string.punctuation) for word in text.split()] misspelled = checker.unknown(tokens) for word in misspelled: res = QgsValidityCheckResult() res.type = QgsValidityCheckResult.Warning res.title = 'Spelling Error?' template = f""" <strong>'{word}</strong>' may be misspelled, would '<strong>{checker.correction(word)}</strong>' be a better choice? """ possibles = checker.candidates(word) if len(possibles) > 1: template += """ Or one of:<br/> <ul> """ for t in possibles: template += f"<li>{t}</li>\n" template += '</ul>' res.detailedDescription = template results.append(res) return resultsAnd in theory, that was that! But I’m pretty sure that my students (and everyone else) probably didn’t want to cut and paste that into the console every time they wanted to spell check a map. So, I looked at how to package this up for QGIS. I built a plugin (using the plugin builder tool), but then things got a little tricky as I can’t see any way for a plugin to add itself to the print layout rather than the main QGIS window (please let me know if it is possible), and it seemed unintuitive to make people press a button in one window to effect another one, besides the whole point of being a
QgsAbstractValidityCheckwas that the method is automatically run on print. So I didn’t need most of the plugin code or did I? On further thought I did, there is a need for some GUI as the user can pick which language they want to use in the spell check.pyspellcheckcan spell check English, Spanish, French, Portuguese, German, Italian, Russian, Arabic, Basque, Latvian and Dutch (so if those are your language then please test this for me). I also thought that providing the option to supply a different to the default personal dictionary might be useful. So that made use of the dialog that pops up when you hit the plugin.But it turns out you can’t register a class method as as a
QgsAbstractValidityChecksince it gets confused when QGIS calls it later. So I had to move my checker method outside the plugin class. But then I couldn’t access the language and dictionary that was set in the GUI! Some more searching gave me the following code:_instance = plugins['qgis-spellcheck'] checker = _instance.checkerWhereby I can pull out the named plugin and grab it’s spell checker, which was created in the plugin’s
Future Work__init__method. I seem to have a small issue that the user’s profile is not set when that runs which messes up where the personal dictionary is put (again if you know how to fix this let me know).Ideally, I’d like the spell checker to scan and highlight the text in the boxes as I typed but I fear that is beyond my understanding of the QGIS/Qt interface. Next highest on my wish list is for the list of spelling issues to be non-modal so I can cut and paste fixes into the text box, rather than having to memorise the correct spelling, close the window and then type it in (again answers on a github issue).
I’m sure all sorts of things will come up once people start using it, so as usual issues and PRs are welcome at [https:]
-
11:00
OCS GE Nouvelle Génération, une couverture complète sous deux millésimes d’ici fin T3-2025
sur Toute l’actualité des Geoservices de l'IGN L’objectif du programme – financé par la Direction Générale de l'Aménagement, du Logement et de la Nature (DGALN) du Ministère de la Transition écologique et de la Cohésion des territoires – est de fournir, d’ici fin T3-2025, une couverture complète du territoire sous deux millésimes (i.e. deux années de référence). Cette base de données sera cruciale pour le suivi de l’artificialisation des sols et l’atteinte de la zéro artificialisation nette à horizon 2050 fixé par la loi « Climat et résilience » du 22 août 2021.
L’objectif du programme – financé par la Direction Générale de l'Aménagement, du Logement et de la Nature (DGALN) du Ministère de la Transition écologique et de la Cohésion des territoires – est de fournir, d’ici fin T3-2025, une couverture complète du territoire sous deux millésimes (i.e. deux années de référence). Cette base de données sera cruciale pour le suivi de l’artificialisation des sols et l’atteinte de la zéro artificialisation nette à horizon 2050 fixé par la loi « Climat et résilience » du 22 août 2021.
-
11:00
Mappery: Mitchell Library, Sydney
sur Planet OSGeo
Another one from Anna Barca
“From the map room in First floor in the Mitchell Library building in the State Library of Sydney. I love looking at those historical art works and think about how maps were made in “the old days” and what was then the focus of the drawings.” (Me too!)
MapsintheWild Mitchell Library, Sydney
-
10:30
Philippe Valette, Albane Burens, Laurent Carozza, Cristian Micu (dir.), 2024, Géohistoire des zones humides. Trajectoires d’artificialisation et de conservation, Toulouse, Presses universitaires du Midi, 382 p.
sur CybergeoLes zones humides, notamment celles associées aux cours d’eau, sont des objets privilégiés de la géohistoire (Lestel et al., 2018 ; Jacob-Rousseau, 2020 ; Piovan, 2020). Dans Géohistoire des zones humides. Trajectoires d’artificialisation et de conservation, paru en 2024 aux Presses universitaires du Midi, Valette et al. explorent l’intérêt scientifique de ces milieux, qui réside selon leurs mots dans "la double inconstance de leurs modes de valorisation et de leurs perceptions qui a conduit, pour [chacun d’entre eux], à des successions d’usages et fonctionnement biophysiques très disparates" (2024, p.349). L’analyse des vestiges conservés dans leurs sédiments permet en effet de reconstituer sur le temps long les interactions entre les sociétés et leur environnement. En outre, les milieux humides ont souvent été abondamment décrits et cartographiés, en lien avec leur exploitation et leur aménagement précoces. Archives sédimentaires et historiques fournissent ainsi à la communauté sc...
-
10:30
Cartographier les pressions qui s’exercent sur la biodiversité : éléments de réflexion autour des pratiques utilisées
sur CybergeoPour mieux orienter les politiques de conservation, il est crucial de comprendre les mécanismes responsables de la perte de biodiversité. Les cartes illustrant les pressions anthropiques sur la biodiversité représentent une solution technique en plein développement face à cet enjeu. Cet article, fondé sur une revue bibliographique, éclaire les diverses étapes de leur élaboration et interroge la pertinence des choix méthodologiques envisageables. La définition des notions mobilisées pour élaborer ces cartes, en particulier celle de la pression, représente un premier défi. La pression se trouve précisément à la jonction entre les facteurs de détérioration et leurs répercussions. Cependant, les indicateurs à notre disposition pour la localiser géographiquement sont généralement axés soit sur les causes, soit sur les conséquences de la dégradation. Cet écueil peut être surmonté si la nature des indicateurs utilisés est bien définie. À cet effet, nous proposons une catégorisation des ind...
-
10:30
Exploring human appreciation and perception of spontaneous urban fauna in Paris, France
sur CybergeoCity-dwellers are often confronted with the presence of many spontaneous animal species which they either like or dislike. Using a questionnaire, we assessed the appreciation and perception of the pigeon (Columba livia), the rat (Rattus norvegicus), and the hedgehog (Erinaceus europaeus) by people in parks, train stations, tourist sites, community gardens, and cemeteries in Paris, France. Two hundred individuals were interviewed between May 2017 and March 2018. While factors such as age, gender, level of education or place or location of the survey did not appear to be decisive in analyzing the differential appreciation of these species by individuals, there was a clear difference in appreciation based on the species and the perceived usefulness of the animal, which is often poorly understood. The rat was disliked (with an average appreciation score of 2.2/10), and the hedgehog was liked (with an average appreciation score of 7.7/10). The case of the pigeon is more complex, with som...
-
10:30
From "Bioeconomy Strategy" to the "Long-term Vision" of European Commission: which sustainability for rural areas?
sur CybergeoThe aim of this paper is to analyze the current and long-term effects of the European Commission Bioeconomy Strategy in order to outline possible scenarios for rural areas and evaluate their sustainability. The focus is on the main economic sectors, with particular reference to employment and turnover, in order to understand what kind of economy and jobs are intended for rural areas, as well as their territorial impacts. For this purpose, we have analyzed the main European Commission documents and datasets concerning the bioeconomy and long-term planning for rural areas, as well as the recent scientific data to verify the impact on forests. The result is that European rural areas are intended to be converted initially into large-scale biomass producers for energy and bio-based industry, according to the digitization process, and subsequently into biorefinery sites, with severe damage to landscape, environment, biodiversity, land use and local economy. Scenarios for rural areas don’t...
-
10:30
Impact du numérique sur la relation entre les systèmes de gestion de crise et les citoyens, analyse empirique en Île-de-France et en Région de Bruxelles-Capitale
sur CybergeoDepuis une dizaine d’année, les systèmes de gestion de crise utilisent les canaux de communication apportés par le numérique. D'un côté, le recours aux plateformes numériques et aux applications smartphones permet une plus grande visibilité des connaissances sur le risque. De l’autre, les réseaux sociaux numériques apparaissent comme un levier idéal pour combler le manque d'implication citoyenne dans la gestion de crise. Pourtant, jusqu'à la crise sanitaire qui a débuté en 2020, rien ne semble avoir été fait pour impliquer les citoyens au cours du processus de gestion de crise. Dans cet article, nous posons la question de l'apport du numérique dans la transformation de la communication sur les risques et dans l'implication citoyenne dans la gestion de crise. En 2018, nous avons diffusé un questionnaire en Île-de-France et dans la région de Bruxelles-Capitale afin de comprendre les attentes des citoyens et les effets des stratégies de communication territoriale sur la perception des ...
-
10:30
La fabrique publique/privée des données de planification urbaine en France : entre logique gestionnaire et approche territorialisée de la règle
sur CybergeoLa question des données territoriales revêt une importance croissante pour l’État, qui entend orienter leur production, leur circulation et leur condition d’usage. Cet article examine les modalités du repositionnement de l’État vis-à-vis des collectivités locales en matière d’urbanisme règlementaire dans le cadre de la standardisation et de la numérisation des données des Plans Locaux d’Urbanisme. Il explore également l’intégration de ces données dans une géoplateforme unique. Nous montrons que ce projet de construction d’un outil commun à l’échelle nationale s’inscrit dans le cadre d’une reprise en main par le pouvoir central des données de planification urbaine à travers l’intégration partielle de méthodes privées, développées par des sociétés commerciales au cours des années 2010 grâce au processus d’open data. L’étude de la fabrique publique/privée des données de l’urbanisme règlementaire permet de mettre en exergue deux points clés de la reconfiguration de l’action de l’État pa...
-
10:30
Le territoire est toujours vivant. Une analyse transversale de la littérature sur un concept central de la géographie
sur CybergeoLe concept de territoire fait l’objet d’une très abondante littérature en sciences humaines et sociales, qui alimente des sens et des usages apparemment très différents. Cet article dresse un état de l’art multidisciplinaire qui situe les uns par rapport aux autres les différents courants sur le concept de territoire. Dans le format synthétique qui est le sien, le but n’est pas d’approfondir chacune des discussions théoriques. Le premier objectif est plutôt de structurer, à travers un corpus d’environ 120 références, un panorama de la très abondante littérature francophone, anglophone et hispanophone sur le territoire. Le deuxième objectif est de tenter des rapprochements entre ces arènes de discussions qui échangent peu entre elles, autour de trois problématiques qui pourraient leur être communes. Enfin, en approfondissant la lecture transversale de la littérature et l’effort de synthèse, le troisième objectif est de soumettre à la discussion des caractéristiques fondamentales qui ...
-
10:30
Vers une transition des systèmes agricoles en France métropolitaine ? Une géographie contrastée et en mouvement (2010 et 2020)
sur CybergeoFace aux objectifs de décarbonation de l’agriculture, de préservation de l’environnement et aux enjeux de viabilité économique et de sécurité alimentaire qui en découlent, les politiques européennes (Farm to fork) et françaises encouragent une transition en profondeur des systèmes agri-alimentaires. Dans ce contexte, la transformation des modes de production agricole devient une nécessité. Cet article présente une géographie des exploitations agricoles en transition en France métropolitaine. Il repose sur une typologie des exploitations agricoles combinant mode de production agricole (biologique ou conventionnel) et mode de commercialisation des produits (circuit court ou filière longue) à partir des données des recensements agricoles de 2010 et 2020. L’analyse propose une cartographie à échelle fine (canton INSEE) des trajectoires d’évolution sur la période 2010-2020 des agricultures en transition, ouvrant la voie à discussion sur les facteurs favorables à l’émergence certains type...