
Vous pouvez lire le billet sur le blog La Minute pour plus d'informations sur les RSS !
Canaux
4770 éléments (3 non lus) dans 55 canaux
-
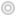 Cybergeo
Cybergeo
-
Revue Internationale de Géomatique (RIG)
-
SIGMAG & SIGTV.FR - Un autre regard sur la géomatique
-
Mappemonde
-
Dans les algorithmes
 Du côté des éditeurs
(1 non lus)
Du côté des éditeurs
(1 non lus)
-
Imagerie Géospatiale
-
Toute l’actualité des Geoservices de l'IGN
-
arcOrama, un blog sur les SIG, ceux d ESRI en particulier (1 non lus)
-
arcOpole - Actualités du Programme
-
Géoclip, le générateur d'observatoires cartographiques
-
Blog GEOCONCEPT FR
Toile géomatique francophone
(2 non lus)
-
Géoblogs (GeoRezo.net)
-
Conseil national de l'information géolocalisée
-
 Geotribu
(1 non lus)
Geotribu
(1 non lus) -
Les cafés géographiques
-
UrbaLine (le blog d'Aline sur l'urba, la géomatique, et l'habitat)
-
Icem7
-
Séries temporelles (CESBIO)
-
Datafoncier, données pour les territoires (Cerema)
-
Cartes et figures du monde
-
SIGEA: actualités des SIG pour l'enseignement agricole
-
Data and GIS tips
-
Neogeo Technologies
(1 non lus)
-
ReLucBlog
-
L'Atelier de Cartographie
-
My Geomatic
-
archeomatic (le blog d'un archéologue à l’INRAP)
-
Cartographies numériques
-
Veille cartographie
-
Makina Corpus
-
Oslandia
-
Camptocamp
-
Carnet (neo)cartographique
-
Le blog de Geomatys
-
GEOMATIQUE
-
Geomatick
-
CartONG (actualités)

Icem7
-
sur La discrétisation “Head/tail” produit des cartes mieux hiérarchisées
Publié: 15 October 2024, 12:00pm CEST par Éric Mauvière
Deux exigences opposées tiraillent le cartographe : schématiser pour mieux imprimer les messages essentiels, ou délivrer le maximum de détails, tant que l’image le permet. Ces exigences ne sont pas forcément contradictoires.
En cartographie thématique, l’art de la coloration repose d’abord sur le découpage en classes, ce que l’on appelle discrétiser. Les bons logiciels proposent plusieurs méthodes automatiques : quantiles, intervalles égaux et Jenks (ou seuils naturels) sont les plus fréquentes.
La discrétisation Head/tail, proposée en 2013 par le géographe Bin Jiang, et récemment mise en lumière en France par Thomas Ansart dessine fort bien les données hiérarchisées, dont la distribution dissymétrique comprend typiquement beaucoup de petites valeurs et quelques valeurs élevées. C’est le cas par exemple de la population des communes, des revenus moyens, ou des loyers.
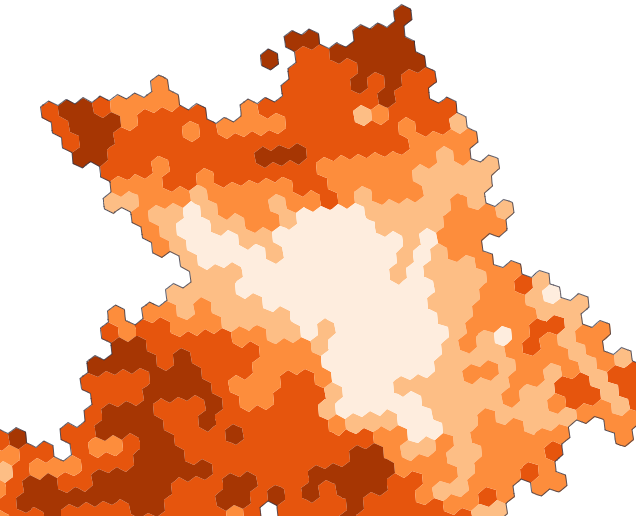
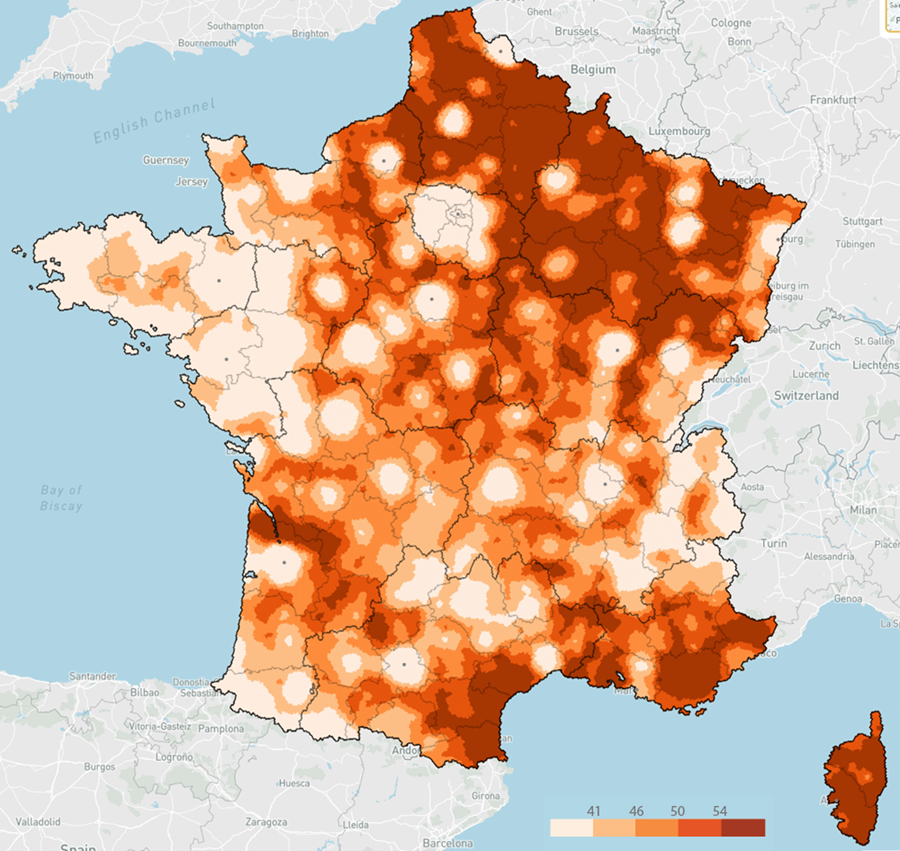
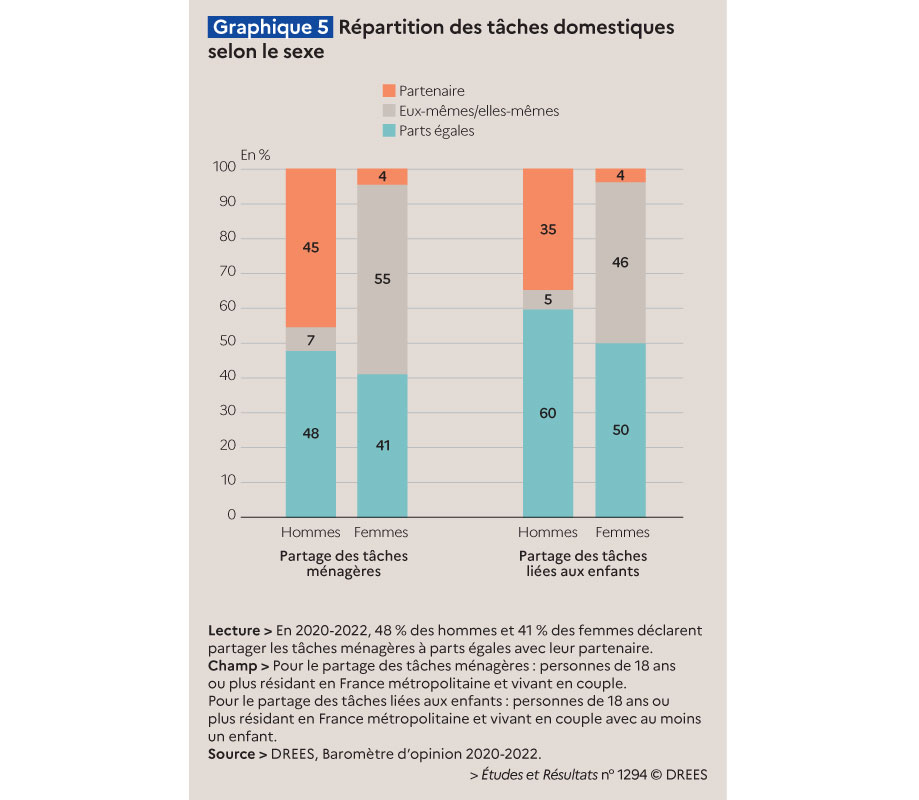
Voici une première illustration, avec le coût par m² du loyer mensuel des appartements par commune et arrondissement en France, en 2023.
Source : ministère de la Transition écologique – Cliquez pour zoomerHead/tail à gauche prend la moyenne comme premier seuil, considère les données supérieures (head), puis calcule de façon itérative des moyennes emboitées.
La méthode de Jenks est également itérative. Elle délimite x groupes les plus homogènes possibles, et en même temps les plus distincts les uns des autres. Elle est proche dans l’esprit de la méthode des K-moyennes.
Ces différentes méthodes aspirent à déterminer des « seuils naturels », des ruptures inhérentes aux données plutôt qu’imposées de l’extérieur par des intervalles égaux ou des effectifs égaux (quantiles). Elles sont puissantes et complémentaires.
Head/tail assume de simplifier drastiquement la représentation en neutralisant la première partie de la distribution, celle sous la moyenne (le tail). Ce qui permet de mieux dégager la hiérarchie des valeurs supérieures à la moyenne (head).
J’aime beaucoup ce rendu plus doux, moins agressif, tout en nuances, en particulier pour les loyers dans le bassin parisien. La structure hiérarchique que cette carte dessine, avec une belle séparation de l’avant-plan et de l’arrière-plan, s’imprimera plus durablement dans mon esprit.
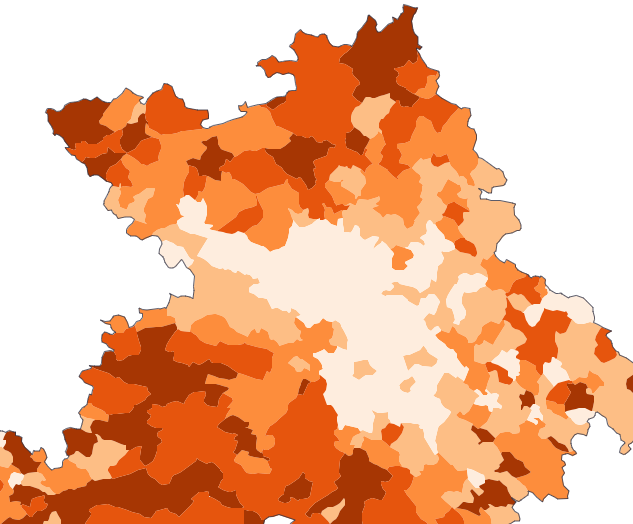
Comparons aussi avec cette version (je suppose par quantile), palette divergente, de Boris Mericskay, avec des données de même origine. L’opposition vert/violet a le mérite de simplifier fortement l’information, divisant la France en deux ou trois, autour d’une classe centrale, d’une moyenne supposée faire sens.

Mais quand la distribution est déséquilibrée comme celle des loyers, une représentation symétrique est moins pertinente. Par exemple, une très faible variation du 1er seuil, intervenant dans la pente abrupte du début de la distribution, fera basculer beaucoup de communes d’une classe verte à l’autre, avec un effet violent sur la répartition colorée des deux premières classes. Et le vert foncé n’est pas le symétrique du violet foncé, il ne traduit pas le même écart à la moyenne.
 Distribution du loyer des appartements en France (en € par m²) en 2023
Distribution du loyer des appartements en France (en € par m²) en 2023
Voici 3 autres illustrations statistiques et cartographiques de l’intérêt de la méthode Head/tail, appliquée toujours à des distributions dissymétriques, avec beaucoup de petites valeurs et peu de grandes valeurs.
1 – La densité de population (2021) – source Insee
Avec Head/tail, Paris, puis Lyon, sont distinguées du groupe des autres villes moyennes (Toulouse, Bordeaux, Nantes, Nice, etc.).
2 – La médiane du niveau de vie (2021) – source Insee
La frontière suisse, une partie de la frontière luxembourgeoise, l’ouest de l’Île-de-France et le sud de l’Oise sautent davantage aux yeux, du fait d’un meilleur contraste.
3 – La part des diplômés d’un BAC+5 ou plus dans la pop. non scolarisée de 15 ans ou plus (2021)
Pour un plus large usage de Head/tail
– source InseeBin Jiang rappelle que dans la nature, le monde du vivant, les organisations humaines, les phénomènes observés se présentent rarement sous forme d’une distribution symétrique autour d’une « moyenne ». Il y a en général plus de petites valeurs que de grandes.
Mais la hiérarchie déroulée à partir des grandes valeurs est ce qui frappe tout d’abord l’esprit, ce qui donne une première idée d’une structure d’ensemble : hiérarchie des villes, des longueurs de rues dans une ville, des entreprises dans un secteur donné, des intensités de tremblements de terre, de répartition des richesses, de popularité des sites web, de fréquence des mots dans un texte, etc.
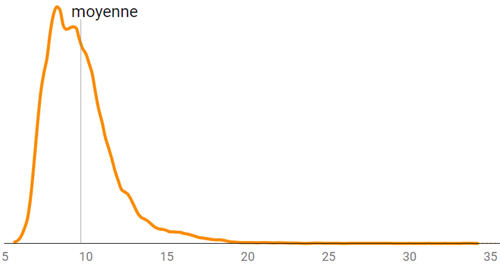
Ou les niveaux successifs d’organisation d’une feuille, de ses nervures :
 Une feuille (a) décomposée en 5 niveaux d'organisation, jusqu'au réseau le plus fin de ses nervures - Source : Jiang, 2020
Une feuille (a) décomposée en 5 niveaux d'organisation, jusqu'au réseau le plus fin de ses nervures - Source : Jiang, 2020
Pour employer un langage plus technique, les phénomènes naturels ou géographiques sont peu souvent gaussiens (symétriques), plus souvent « paretiens » (de Pareto et sa fameuse loi des 80/20 – 20 % des causes expliquent 80 % des effets), ou « log-normaux » (leur logarithme est gaussien).
Pour Jiang, le nombre de seuils calculés par la méthode Head/tail (dénommé ht index) est un indicateur de la profondeur organisationnelle du phénomène étudié (il le rapproche même du concept de dimension fractale, posé par Benoît Mandelbrot).
Pour une distribution symétrique, idéale, quasi-gaussienne, le ht index sera souvent faible, 2 par exemple. À l’inverse, un ht-index > 5 caractérisera un phénomène étagé, où parfois même, d’un niveau à l’autre, l’on retrouve les mêmes rapports d’échelle.
Description de l'algorithme Head/TailPour découvrir l’algorithme en action (JavaScript et SQL/DuckDB), rendez-vous sur ce classeur Observable.
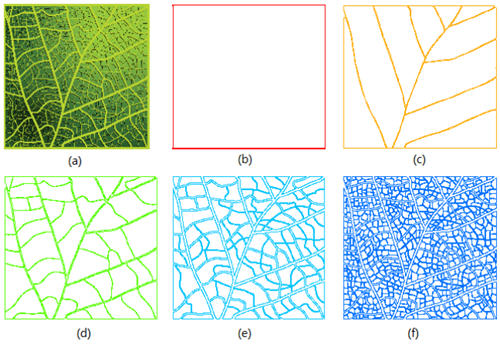
Considérons par exemple 10 nombres [1, 1/2, 1/3…1/10] (ou [1, 0.5, 0.333…0.1]) qui suivent cette règle de proposer plus de petites valeurs que de grandes.
La somme de cette série fait 2,93, la moyenne 0,293. 1, 1/2 et 1/3 lui sont supérieurs.
Si l’on divise la série en deux morceaux autour de la moyenne (« Head » au-dessus, « Tail » en dessous), on obtient donc l’itération 1 de cette figure :
 Source : Bin Jiang - A new approach to detecting and designing living structure of urban environments
Source : Bin Jiang - A new approach to detecting and designing living structure of urban environments
L’algorithme Head/tail itère jusqu’à ce que cette division par la moyenne s’arrête, par exemple parce que le dernier « head » n’a plus qu’un élément ; ou que le dernier « head » a un effectif supérieur à son « tail », signe que la division n’est plus pertinente.
Head/tail fournit une alternative à la méthode de discrétisation de Jenks, bien plus rapide à calculer et, pour son concepteur, mieux apte à rendre compte d’une hiérarchie, d’une structure fractale, caractéristique fréquemment rencontrée dans la nature et le « vivant ».
Pour rappel, la méthode de Jenks – dite aussi des « seuils naturels » – conduit à délimiter x groupes les plus homogènes possibles, et en même temps les plus distincts les uns des autres. x est un paramètre fourni à l’algorithme de Jenks. Cet algorithme est de complexité O(n2), c’est-à-dire que son coût est proportionnel au carré de l’effectif de la distribution à classifier ; il devient difficile à calculer en JavaScript quand n dépasse 10 000 observations.
À l’inverse, la méthode Head/tail est de complexité O(n), et s’exécute en moins d’une seconde avec plusieurs millions d’observations. De plus, elle détermine – intelligemment – son propre nombre de classes, indicateur de la profondeur de la hiérarchie détectée (nombre que l’on peut toutefois réduire en ne retenant que les x premiers seuils).
Pour aller plus loin- Page Wikipedia avec une liste d’implémentations dans divers langages (R, Python…)
- Jiang, B. (2013). « Head/tail breaks: A new classification scheme for data with a heavy-tailed distribution », The Professional Geographer, 65 (3), 482 – 494.
- Jiang, B. (2019). « A recursive definition of goodness of space for bridging the concepts of space and place for sustainability ». Sustainability, 11(15), 4091.
- Jiang, B. (2013) Geospatial Analysis Requires a Different Way of Thinking: The Problem of Spatial Heterogeneity
- Denise Pumain, Hierarchy in Natural and Social Sciences, Springer, 2006
- Thomas Ansart, Atelier de cartographie de Sciences-Po. Head/Tail breaks
- Éric Mauvière, classeur Observable Head/tail breaks
- L’outil Magrit et la librairie JS statsbreaks supportent Head/Tail
- Jean de La Fontaine, La tête et la queue du Serpent
L’article La discrétisation « Head/tail » produit des cartes mieux hiérarchisées est apparu en premier sur Icem7.
-
sur Barres empilées : comment s’en débarrasser ?
Publié: 1 September 2024, 1:10pm CEST par Éric Mauvière
C’est l’un des graphiques les plus utilisés dans la production statistique française, mais aussi le plus paresseux et le moins efficace pour comprendre et surtout mémoriser. La plupart des responsables éditoriaux le savent, formés qu’ils/elles le sont à la sémiologie graphique. Pour autant, pas moyen de remiser ces empilements : ils collent aux publications statistiques comme le sparadrap au capitaine Haddock !
Prenons comme premier exemple ce graphique sur l’évolution des crimes en France, classés par type. Le diagramme en barres empilées traduit tel quel le tableau croisé des données, y intégrant un total. Et c’est la principale raison de son emploi : on voit en même temps l’évolution d’ensemble et le détail des catégories.
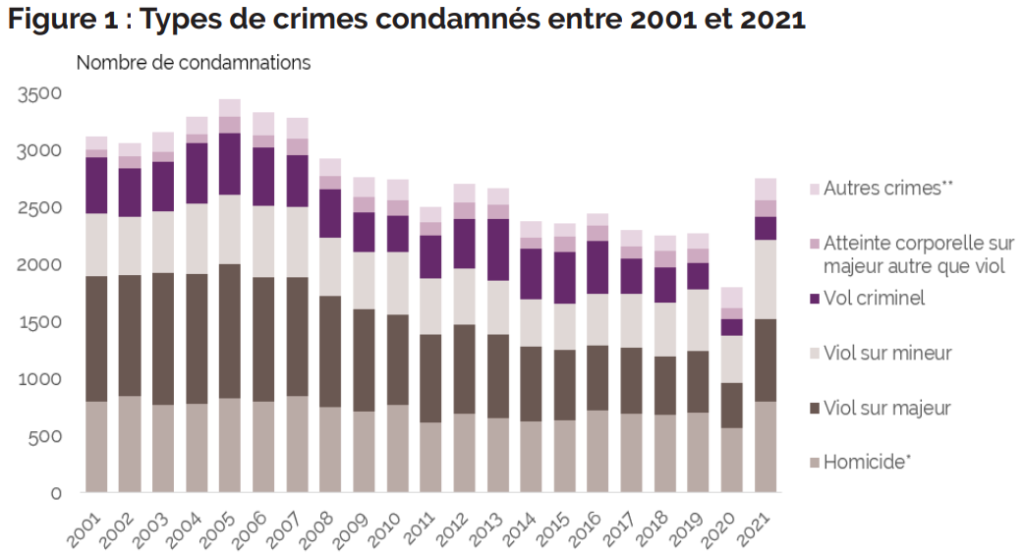 Source : ministère de la Justice/SG/SEM/SDSE, fichier statistique Casier judiciaire national
Source : ministère de la Justice/SG/SEM/SDSE, fichier statistique Casier judiciaire national
Si l’on voit bien le mouvement général, il est plus difficile d’apprécier les détails, d’analyser la morphologie de ces rectangles colorés. Quand la base d’une série est horizontale, par exemple celle des homicides en bas, il suffit d’en suivre visuellement les sommets. Mais quand les segments flottent, le lecteur doit mener deux opérations mentales exigeantes – extraire visuellement la série et la recaler sur une base commune. Cet effort à répéter fatigue et complique la mémorisation, faute d’images prêtes à photographier mentalement.
Comment ordonner les catégories, choisir les couleurs ? « Autres crimes » est la première catégorie que l’œil rencontre, c’est aussi la moins signifiante. Et la palette adoptée crée deux groupes artificiels, un en violet et l’autre en gris.
Que va-t-on retenir d’une telle image ? Au mieux, oubliant les catégories, une tendance globale à la baisse avant la crise du covid, et une reprise post-covid qui ressemble à un rattrapage – dont on ne sait s’il est réel ou purement administratif (du fait d’instructions retardées).
Distinguons chaque série dans une collection de petits graphiques triés et catégorisésAvec un outil soucieux de sémiologie comme Datawrapper (ou Flourish), testons une variante où chaque composante peut apparaitre séparément, la comparaison avec l’évolution d’ensemble restant possible.
Retenons le même ordre de tri que le graphique d’origine, par effectifs finaux décroissants. Cette nouvelle construction graphique présente d’abord les trois catégories les plus importantes. Elles ont en commun de bien marquer l’effet de rattrapage précédemment évoqué. L’importance des viols est manifeste. Un rapide calcul visuel montre qu’ils représentent au total la moitié des crimes. Ce constat m’a particulièrement frappé.
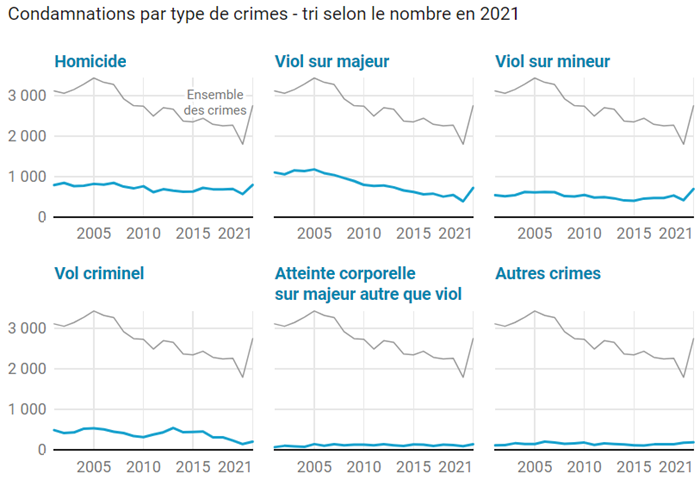
Je le souligne donc, dans cet affinage prêt à diffuser, à l’aide d’une couleur différente et d’un titre qui reprend deux informations majeures.
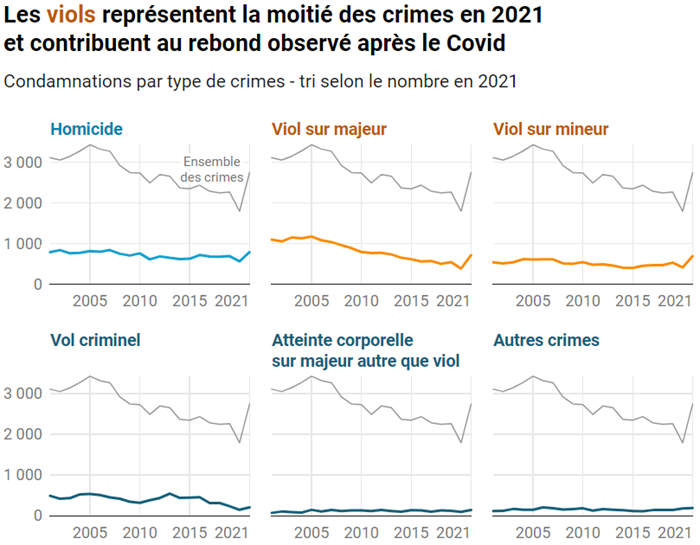
Ces petits graphiques sont évidents et élégants, avec leurs axes épurés dont les étiquettes sont davantage conformes aux règles de lisibilité (écriture horizontale pour les années, séparateur des milliers pour les effectifs).
Un bon graphique présente toutes les données et dégage une ou quelques images simples (par exemple les trois graphiques de la première rangée), que le lecteur pourra relier à des enseignements verbalisés. Il les mémorisera ainsi durablement, grâce à la puissante association entre le visuel et le sémantique, quand ces deux canaux résonnent en cohérence.
C’est le mantra cher à Jacques Bertin, le grand sémiologue français : trier judicieusement ce qui peut l’être, puis catégoriser pour hiérarchiser les niveaux d’information.
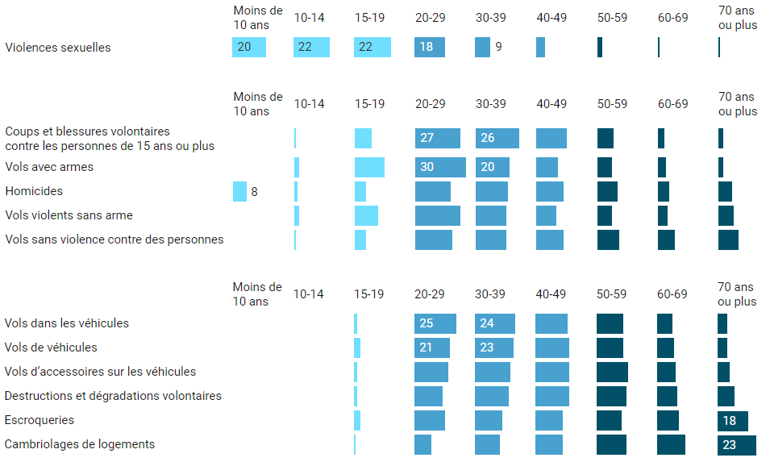
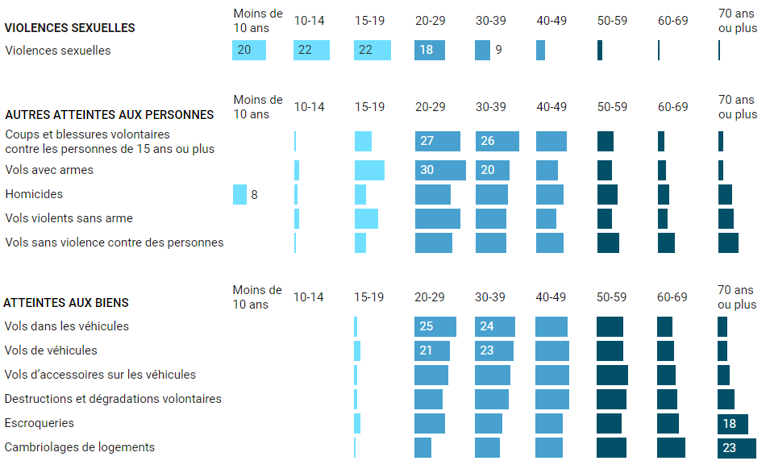
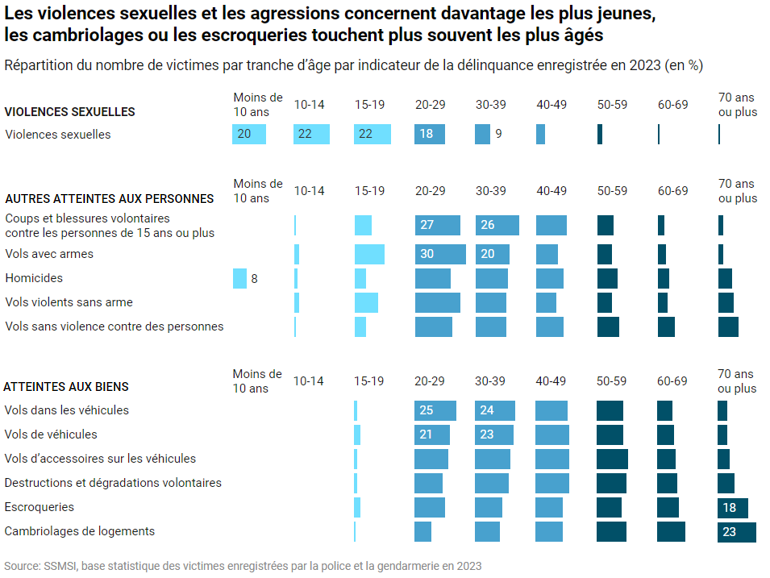
Étendons la démarche à un jeu de données plus fourniIssu d’une source différente, ce nouveau diagramme empilé traite d’un sujet voisin, les actes de délinquance, en regardant plutôt les victimes et ce à quoi elles sont sujettes selon leur âge. La dimension de l’âge, en X dans ce diagramme, est ordonnée de façon logique, croissante.
Mais qu’en est-il des indicateurs de délinquance ? L’auteur ne précise pas le critère de tri en Y et l’œil du lecteur n’en saisit pas la logique. Renforcée par les contrastes lumineux, l‘impression d’ensemble est bruitée et inconfortable.
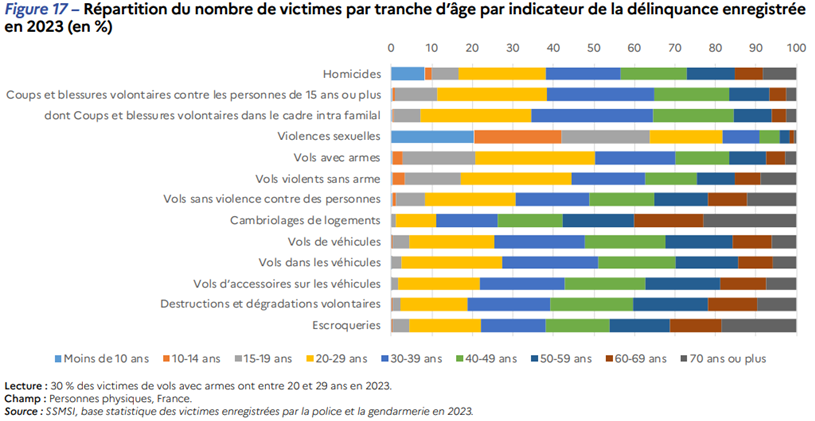
Par ailleurs, la palette de couleur n’est pas ordonnée, elle n’exprime pas la progression des âges. Le lecteur peinera à regrouper visuellement des tranches voisines.
La construction suivante utilise une palette visuellement ordonnée, désempile les barres, et reclasse les faits de délinquance pour construire l’image la plus pure, la plus significative – perceptible dans l’instant minimal de vision, selon les vœux de Bertin. Une telle image, comme il l’exprime dans sa « Sémiologie graphique », tend vers deux critères topologiques : connexité (peu ou pas de trous, une forme ramassée) et convexité (enveloppe plutôt ronde). Idéalement, une belle diagonalisation !
Un bon outil graphique facilitera les reclassements. Après quelques essais, la tranche des 70 ans et plus fournit un bon critère de départ pour un tri. L’examen conjoint des tranches les plus jeunes m’amène à définir trois groupes. Ce nouveau graphique déroule une vague expressive.
Il faut se faire violence, parfois, pour chambouler l’ordre par défaut des nomenclatures. Bertin l’évoquait malicieusement, dans un dernier article, témoignant de sa longue – et fructueuse – expérience de collaboration avec la statistique publique : « À l’école de l’Insee, reclasser un tableau de données était une abomination ! ».
Le geste suivant, encore plus audacieux pour le statisticien, consiste à nommer ces groupes, dès lors qu’il saisit ce qui les caractérise.
Un titre informatif s’en déduit naturellement. C’est l’association entre messages de premier niveau clairs et une forme d’ensemble simple et significative qui va consolider l’inscription en mémoire de la hiérarchie des enseignements.
 Pourquoi la plupart des graphiques statistiques sont-ils paresseux ?
Pourquoi la plupart des graphiques statistiques sont-ils paresseux ?
Certes, la puissance de la sémiologie graphique n’est pas suffisamment exprimée et enseignée, que ce soit à l’école ou en formation continue. Au pays de Bertin, c’est pour le moins étonnant, voire dissonant. À cela, les responsables d’enseignement ou de services statistiques peuvent facilement remédier, si ils/elles le souhaitent – et même si cela prend un peu de temps
 .
. Mais ce déficit renvoie plus fondamentalement à la posture de l’analyste, au rôle qu’il/elle se donne ou qu’on lui donne : mettre à disposition des chiffres solides et laisser au lecteur le soin de les interpréter ?
Ou chercher en plus à transmettre, avec les outils de la sémiologie graphique, ce que soi-même, avec son expertise, sa curiosité, sa déontologie, on a fini par retirer de ses multiples explorations. C’est la voie que, pour ma part, j’approfondis comme rédacteur d’articles, et enseigne en formations sur mesure.
Pour en savoir plus- Près de 750 condamnations par an pour homicide homicide volontaire et coups mortels – Infostat Justice n° 191
- Insécurité et délinquance en 2023, une première photographie – Interstats Analyse n° 64
- Sémiologie graphique, Jacques Bertin, 1967
- Aux origines de la sémiologie graphique, Jacques Bertin, CFC 2004
L’article Barres empilées : comment s’en débarrasser ? est apparu en premier sur Icem7.
-
sur Les lignes de force du vote RN en 2024 : une cartographie lissée avec la grille H3
Publié: 11 July 2024, 3:44am CEST par Éric Mauvière
Les résultats des dernières élections françaises sont maintenant disponibles à un niveau fin, à la commune et même jusqu’au bureau de vote. Mais comment produire une cartographie lisible et synthétique à partir de données si détaillées ?
Ce travail récent de Karim Douïeb, largement repris, illustre bien le dilemme : il dénonce le caractère trompeur de la carte (choroplèthe) de gauche et propose à la place la variante (à symboles) de droite.
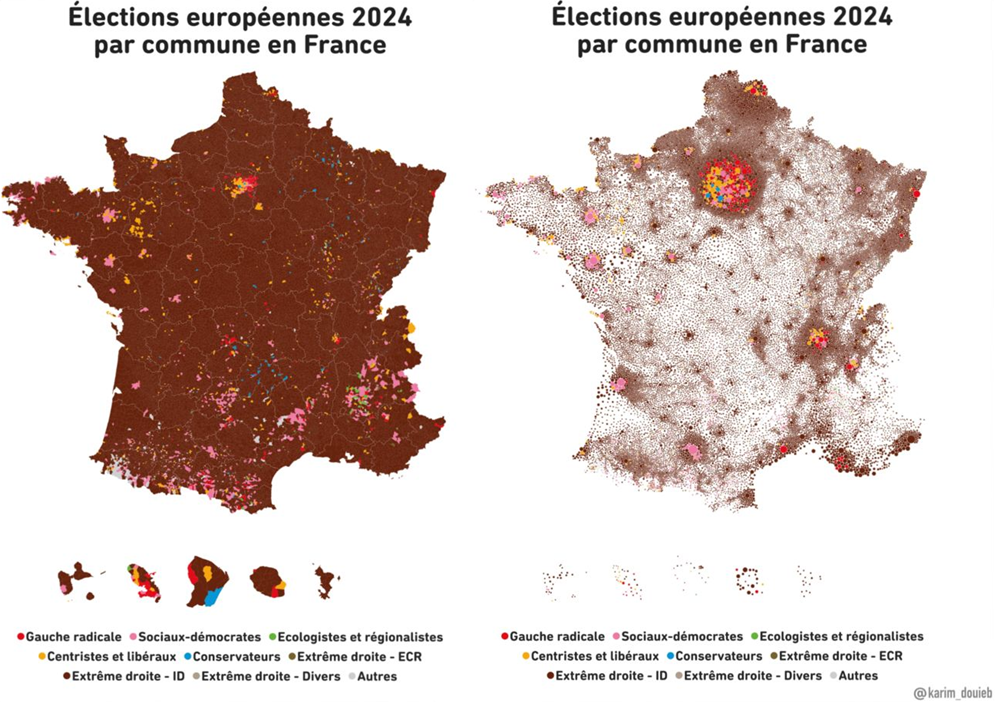
Les cartes choroplèthes sont faciles à lire avec leur coloration continue de tout le territoire. Mais l’œil voit seulement des surfaces, il ne peut faire le tri entre les territoires plus peuplés et les moins peuplés.
Les cartes à pastilles proportionnelles rendent mieux compte des populations en présence, mais les petits ronds se voient peu, ou alors coagulent en amas artificiels là où le maillage communal est très serré (par exemple dans les Hautes-Pyrénées, voisines des Landes où c’est l’inverse). Les cartogrammes qui distordent la géographie pour prévenir les superpositions accentuent souvent ces artefacts.
Une autre voie respecte la géographie, préserve la continuité de l’image et prend en compte les différences de population : celle où le résultat d’un candidat (part en %) est lissé par disques mobiles.
Les spécialistes des études locales la connaissent depuis longtemps – je la pratique depuis 35 ans. Certes, les calculs requis par le lissage en limitent l’usage, même avec des librairies spécialisées. Il est toutefois possible en 2024 de construire simplement de solides cartes lissées, sans logiciel lourd.
Voyons comment faire avec 3 petits bijoux d’efficacité : un moteur SQL autonome (DBeaver/DuckDB), une grille hexagonale (H3) et un outil de cartographie web (Mapshaper).
A - Lissage appliqué aux résultats communaux des européennes de 2024Comparons ci-dessous les résultats bruts des élections européennes et la représentation lissée par disque mobile. Le lissage améliore spectaculairement la lisibilité de l’image.
Européennes 2024 – Part des votes RN et Reconquête (%)
 Lissé
Lissé
 Brut
Brut
Les grandes agglomérations éloignent le vote RNR, mais cet effet est moins visible dans un grand Nord-Est ou sur le littoral méditerranéen. Quelques contrastes locaux sont frappants, par exemple entre le Lot et Tarn-et-Garonne, ou l’agglomération bordelaise et sa frange nord.
Note : les petits points gris signalent les capitales régionales.Comme le pinceau de l’archéologue dépoussière un bas-relief, ou la restauratrice révèle sous les vernis et les taches le tableau originel, le lissage dégage les lignes de force qui traversent les territoires – et bien souvent celles qui résistent au temps et aux soubresauts politiques.
Je vais décrire la méthode, car en saisir le principe, c’est mieux comprendre les limites et les avantages de cette technique. Le lissage n’est pas une moyenne locale des valeurs communales (ici la part de telle liste). Il repose sur une agrégation de deux grandeurs que l’on va ensuite diviser pour recalculer le taux « ambiant ». Cette agrégation se fait sur une étendue plus ou moins large, le rayon du disque de lissage.
En un endroit donné, on additionne par exemple le nombre de votants RNR au sein d’un rayon de 20 km, et l’on procède de même pour l’ensemble des votants ; le nouveau taux se calcule sur ces deux grandeurs étendues. Ainsi, d’une commune à sa voisine, les taux ambiants vont faiblement varier. Les aléas locaux sont lissés, et les territoires localement plus peuplés contribuent davantage à la représentation.
B - La méthode en imagesConsidérons les deux cartographies traditionnelles du résultat d’une liste, dans notre exemple la part du vote RN et Reconquête (en abrégé, RNR). Sur une carte zoomée, la technique des ronds coloriés a bien des avantages, car les symboles sont tous visibles, leur couleur aussi. Ce mode présente à la fois une grandeur absolue (les votants), et la part du vote RNR.
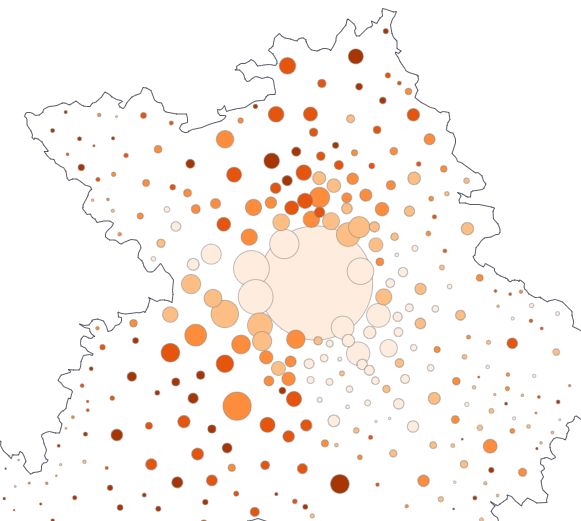 Ronds
Ronds
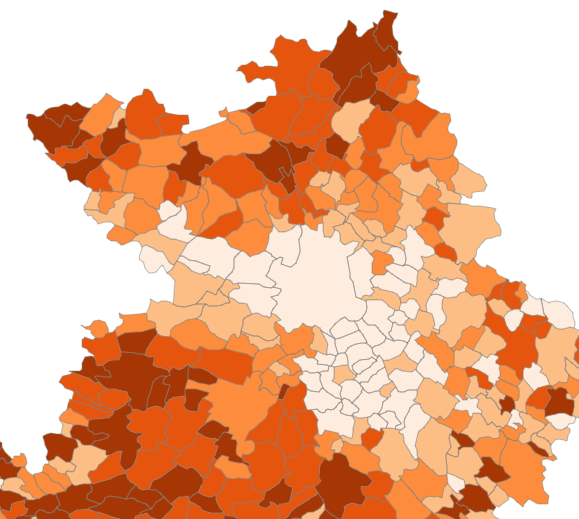 Choro
Choro
Comme on le constate dans cette vue de la périphérie toulousaine, les communes sont de taille fort variable. Le découpage communal influence fortement la morphologie de l’image. C’est la raison pour laquelle certains politiques s’échinent à redéfinir les maillages électoraux, pour tourner l’addition locale des votes à leur avantage.
Passer d’un maillage hétérogène à une grille régulière donnera une assise plus solide à la méthode de lissage.
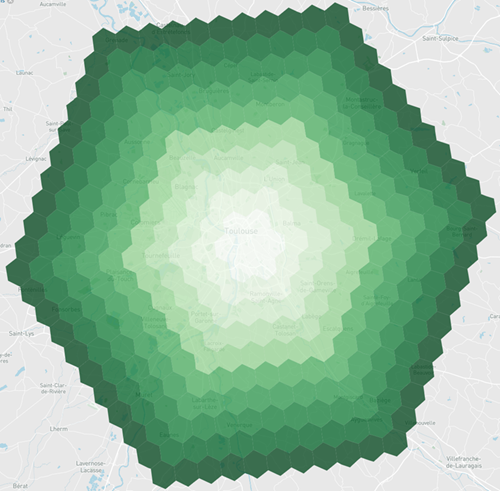
La grille H3, conçue d’abord pour les besoins d’Uber, maille l’ensemble de la planète avec des hexagones. En voici une représentation au niveau de précision 7 (sur une échelle allant de 0 à 15).
38 hexagones de niveau 7 recouvrent la commune de Toulouse. Une première idée consiste à répartir le total des votants à Toulouse de façon égale sur ces 38 hexagones. Je pourrais affiner cette répartition sur les hexagones frontières, par un prorata de la surface intersectée. Mais ce serait me compliquer la vie inutilement, car en définitive, je vais lisser !
Toulouse et les hexagones H3
 Grille H3 de niveau 7, intersectant Toulouse
Grille H3 de niveau 7, intersectant Toulouse
 Votants à Toulouse répartis fictivement en 38 points
Votants à Toulouse répartis fictivement en 38 points
Les hexagones sur les frontières communales vont ainsi recevoir des votants venus de deux, parfois trois communes limitrophes. Cela produit déjà, de fait, un premier microlissage.
En voici le résultat cartographié, après recalcul du taux pour chaque hexagone.
 H3
H3
 Brut
Brut
Le principe du lissage par fenêtre mobile est toutefois bien plus puissant. H3 permet très facilement (c’est aussi une librairie avec quantité de fonctions utilitaires) de lister les hexagones voisins, avec un pas variable – de 1 à 10 dans cet exemple :
Avec ce rayon de lissage de 10 (soit un peu plus de 20 km), je m’emploie à additionner, en un centre donné, les votants et les votants RNR sur l’ensemble de ce disque. Je prends garde à donner de moins en moins d’importance aux hexagones qui s’éloignent, par une pondération inverse de la distance au centre.
Mon lissage intègre ainsi deux paramètres d’ajustement : le rayon du disque mobile (en fait un grand hexagone mobile), et la fonction de pondération (quelle importance j’accorde aux hexagones les plus éloignés pour calculer le taux ambiant).
Voici deux cartes, avec des rayons de lissage différents : 5 (soit environ 12 km) et 10 (20-25 km).
++
 +
C - Comment lisser, en pratique ?
+
C - Comment lisser, en pratique ?
Je conduis les calculs en SQL, avec le moteur DuckDB et son extension H3, dans l’interface DBeaver. DBeaver donne un premier aperçu du résultat des requêtes spatiales, ce qui s’avère très pratique.
Pour la cartographie thématique, Mapshaper, utilisable en ligne, dessine et colorie avec une vélocité remarquable.
Cette démarche procède d’un principe pédagogique auquel je suis attaché : ouvrir des portes pour le plus grand nombre, privilégier les outils les plus simples, les plus accessibles, les mieux conçus.
Commençons par récupérer les résultats des européennes 2024, à partir de la base électorale consolidée par l’équipe data.gouv au format parquet :
-- source : [https:] CREATE OR replace TABLE s_com_europ2024 as WITH t1 AS ( FROM 'candidats_results.parquet' SELECT "Code du département" || "Code de la commune" codgeo, nuance, sum(voix) tvoix, sum(tvoix) over(PARTITION BY "Code du département" || "Code de la commune") exprimes, WHERE id_election = '2024_euro_t1' GROUP BY codgeo, nuance ), t2 AS ( PIVOT t1 ON nuance USING(sum(tvoix)) ) FROM t2 SELECT codgeo,exprimes,LREC+LRN RN,LENS,LFI+LUG+LVEC+LCOM LNFP ORDER BY codgeo ;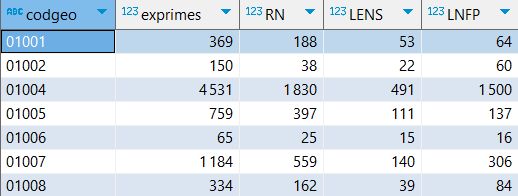
J’utilise DuckDB dans sa version la plus récente (dev 1.0.1), qui simplifie davantage encore les écritures.
Deux extensions vont me servir, SPATIAL pour les requêtes géographiques, H3 pour créer et manipuler le maillage hexagonal.
INSTALL H3 FROM COMMUNITY ; LOAD H3 ; -- pour récupérer, si besoin, la version de dev : -- FORCE INSTALL spatial FROM 'http://nightly-extensions.duckdb.org'; LOAD SPATIAL ;À partir du contour de la France métropolitaine, je crée une enveloppe, et je peux la voir immédiatement dans DBeaver.
CREATE OR REPLACE VIEW e_fra AS FROM st_read('a_frametro.json') SELECT st_convexHull(geom).st_buffer(0.1) AS geom ;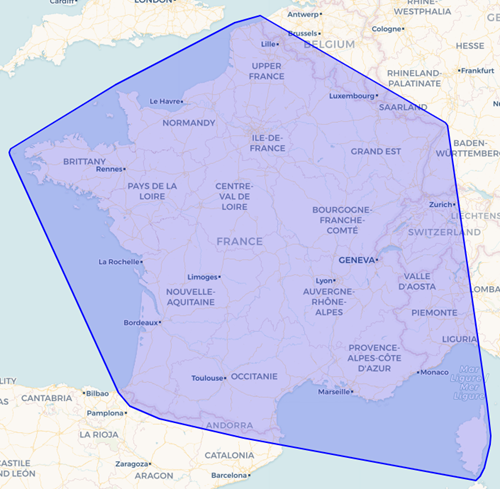
Notre première fonction H3, l’une des plus puissantes, est en mesure de mailler ce polygone avec plein de petits hexagones de niveau 7. Ils sont 182 000. DBeaver ne m’en montre qu’un échantillon, mais c’est déjà impressionnant !
FROM e_fra SELECT h3_polygon_wkt_to_cells(geom, 7) -- ids .unnest() .h3_cell_to_boundary_wkt() .st_geomfromtext() ; -- géométries
h3_polygon_wkt_to_cells() renvoie une valeur qui est en fait une liste d’identifiants d’hexagones. unnest() permet de déplier cette valeur/liste en autant de lignes de la table résultante.
h3_cell_to_boundary_wkt(), autre fonction très utile, génère la géométrie hexagonale d’un identifiant.
On peut ainsi fabriquer un grillage spatial sans écrire soi-même aucun calcul mathématique.
Pour remplir une forme plus complexe que le simple POLYGON précédent, la France par exemple, il faut la décomposer en formes plus élémentaires, et assembler le résultat pour constituer une table homogène.
CREATE OR REPLACE TABLE fra_h3_res7 AS WITH france_polys AS ( FROM st_read('a_frametro.json') -- décomposition MULTIPOLYGON -> POLYGON SELECT st_dump(geom).unnest(recursive := true) AS geom ), h3_ids AS ( FROM france_polys SELECT list(h3_polygon_wkt_to_cells(geom, 7)) .flatten().unnest() AS id -- concaténation des ids d'hexagones ) FROM h3_ids SELECT id, -- conversion en géométries h3_cell_to_boundary_wkt(id).st_geomfromtext() AS geom ;Voici un aperçu des 115 000 hexagones du niveau 7 qui recouvrent la France métropolitaine.
 Passons dans Mapshaper
Passons dans Mapshaper
Les fonctions cartographiques de DBeaver sont pratiques, mais limitées. L’outil Mapshaper affiche sans aucune difficulté l’ensemble de la couche.
Au préalable, on aura procédé, dans DBeaver, à un export Geojson.
COPY fra_h3_res7 TO 'fra_h3_res7.json' WITH (format GDAL, driver GeoJSON) ;Il suffit ensuite de faire glisser ce fichier dans l’interface de Mapshaper. La console de cet outil permet d’écrire de puissantes instructions de manipulation, dont je vais profiter.
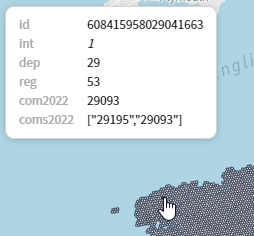
Je souhaite enrichir cette grille par jointure spatiale avec deux autres couches géographiques. Je vais ainsi relier chaque hexagone aux département, région et commune(s) qui le recouvrent ou l’intersectent.
target fra_h3_res7 \ join a-depmetro calc='reg=first(reg), dep=first(dep)' largest-overlap \ join a-com2022 calc='com2022=first(codgeo), coms2022=collect(codgeo)' largest-overlap \ join a-com2022 calc='coms2022=collect(codgeo)'Ces opérations complexes prennent moins de 10 secondes dans mon navigateur.
J’utilise ce fond de carte communal.
L’identifiant d’un hexagone est un entier de grande taille. Mapshaper l’interprète plutôt comme une string, on y sera attentif par la suite.
Je stocke ma couche hexagonale enrichie sous la forme d’un fichier geoparquet, ce que permet très simplement la version 1.0.1 de DuckDB. Le fichier produit pèse à peine 9 Mo.
COPY ( FROM st_read('fra_h3_res7_v2.json') SELECT * REPLACE(id::ubigint AS id), ORDER BY reg,id ) TO 'fra_h3_res7_v2.parquet' (compression ZSTD) ;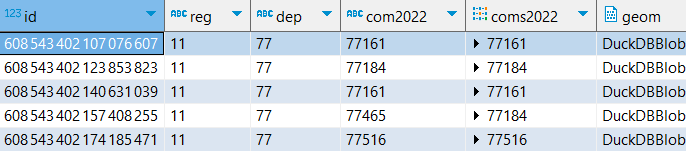 Cartographie thématique avec Mapshaper
Cartographie thématique avec Mapshaper
Je ne les avais jamais utilisées, je découvre avec bonheur les fonctions de coloriage de Mapshaper !
La surface des hexagones n’est pas constante dans H3, car ces hexagones résultent de la projection sur la sphère terrestre d’une forme géométrique complexe, un icosaèdre. De plus, leur surface apparente dépendra de la projection cartographique finale.
Pour autant, cette surface projetée varie peu d’un hexagone à l’autre. Voici ce que donne le rapport à la surface moyenne :
classify field=coeff_area colors='#fff5eb,#fee7cf,#fdd4ab,#fdb97e' classes=4 \ style stroke='d.fill'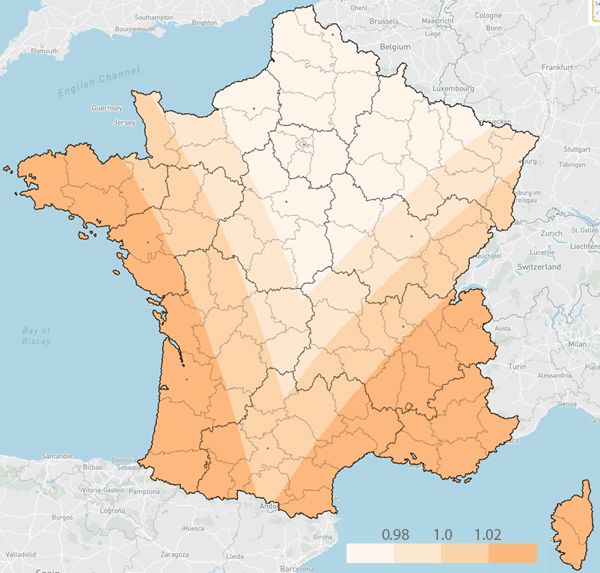
Conscient de ces petites variations, je considère tout de même que le lissage à venir s’appliquera de façon globalement homogène – en tous cas bien plus homogène que si j’en étais resté au maillage communal.
J’ai pu agrémenter ma carte de limites départementales et régionales précisément superposables, par fusion de la couche détaillée : Mapshaper excelle dans ces traitements topologiques, et je vais 10 fois plus vite qu’avec un logiciel spécialisé comme QGIS !
Projection des données communales du vote sur la grille H3target fra_h3_res7_v2 \ dissolve dep,regJe dispose donc d’un excellent référentiel cartographique, avec des hexagones enrichis d’informations communales : elles vont me permettre de faire le lien avec la table des résultats électoraux.
Dans une table intermédiaire, je stocke le nombre d’hexagones couvrant chaque commune.
CREATE OR replace VIEW n_com_h3_res7 as WITH t1 AS ( FROM 'fra_h3_res7_v2.parquet' SELECT UNNEST(coms2022) codgeo, id ) FROM t1 SELECT codgeo, count() AS nb_h3_res7 GROUP BY codgeo ORDER BY codgeo ; FROM n_com_h3_res7 WHERE codgeo = '31555'; -- 38 hexagones intersectent ToulouseGrâce à cela et par jointure, je ventile la table communale du vote à l’hexagone.
CREATE OR REPLACE table s_h3_res7_europ2024 AS FROM s_com_europ2024 p -- jointures sur le code commune JOIN n_com_h3_res7 n using(codgeo) JOIN (FROM 'fra_h3_res7_v2.parquet' SELECT UNNEST(coms2022) codgeo, id) h3 ON h3.codgeo = p.codgeo SELECT id, round(sum(RN/n.nb_h3_res7),1) RN, -- ventilation des votants sur chaque hexagone round(sum(exprimes/n.nb_h3_res7),1) exprimes GROUP BY id ORDER BY id ;
Il ne me reste plus qu’à injecter cette information dans la couche spatiale des hexagones, que j’exporte vers Mapshaper :
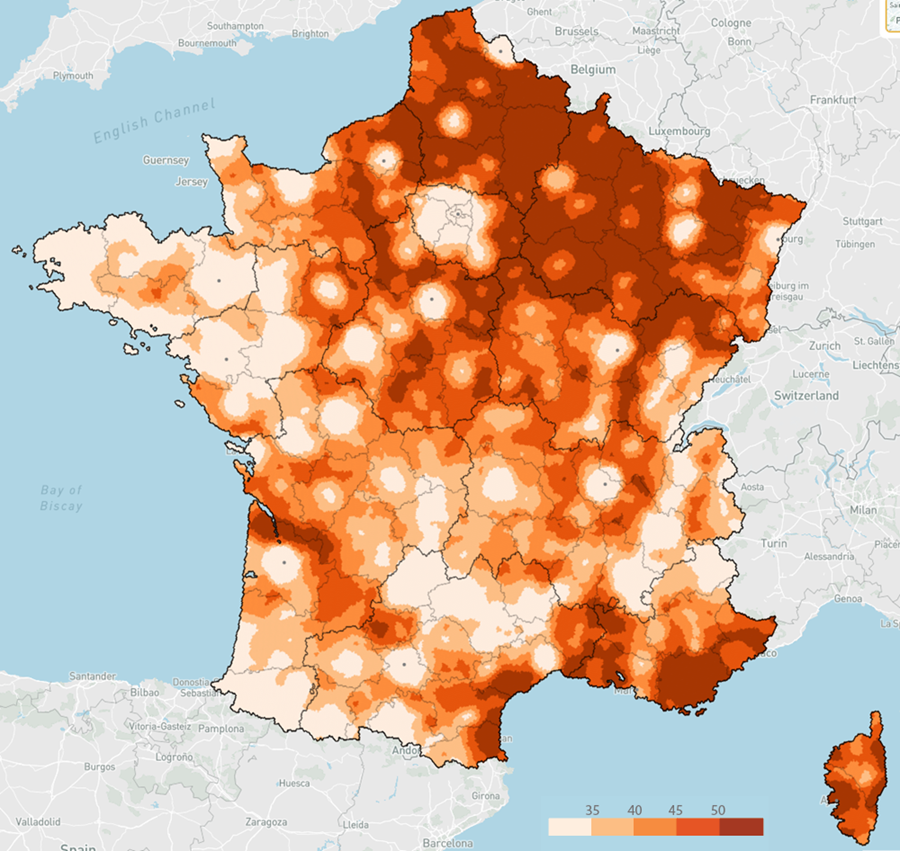
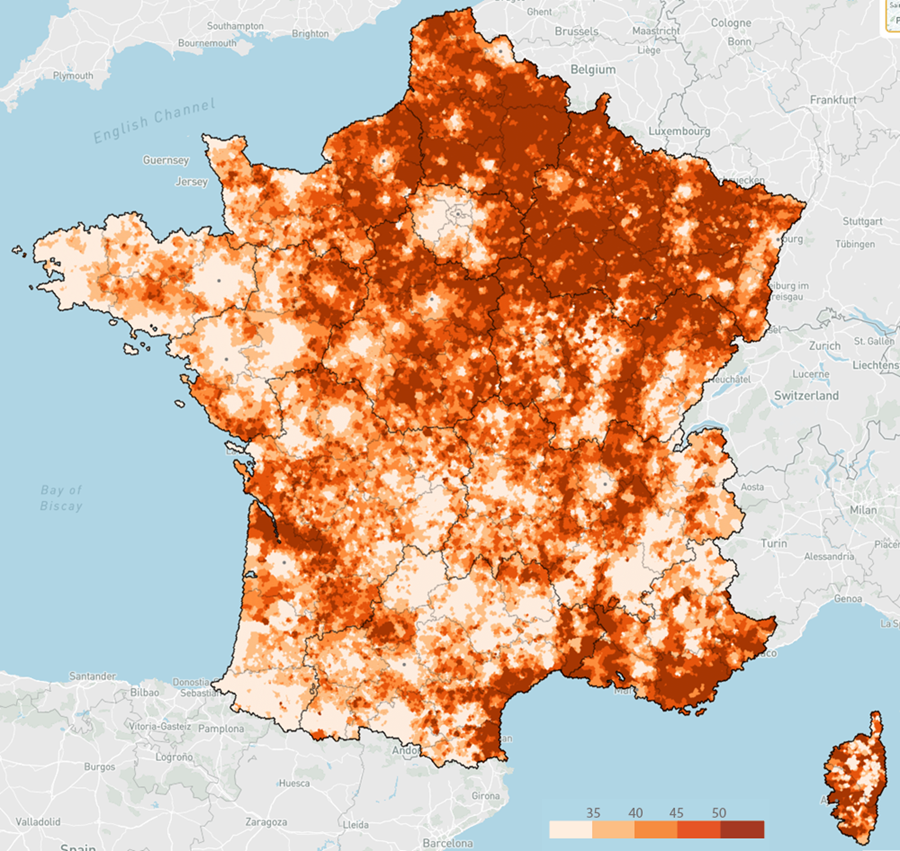
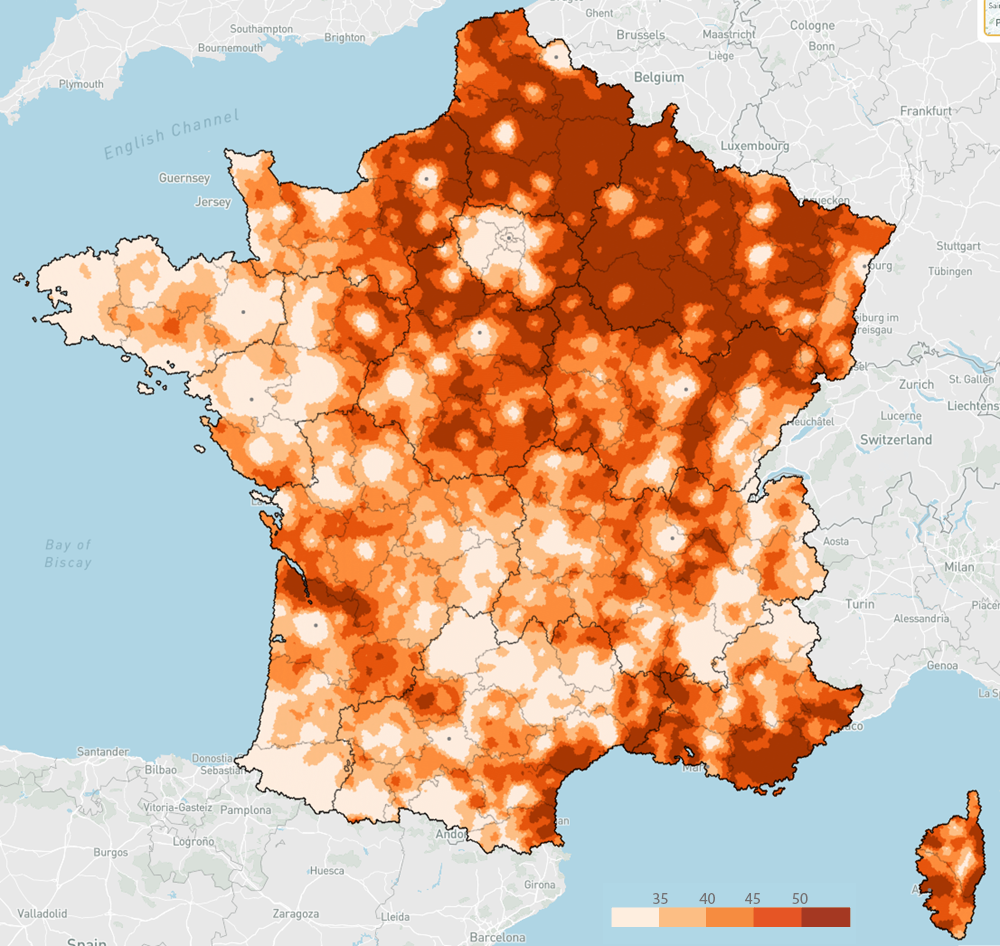
COPY ( FROM 'fra_h3_res7_v2.parquet' m JOIN s_h3_res7_europ2024 l USING(id) SELECT RN, exprimes, round(100*RN/exprimes, 1) part_rn, st_geomfromwkb(geom) geom ) TO 'a_h3_7_europ2024_fra_brut.json' WITH (format GDAL, driver GeoJSON) ;J’essaie deux variantes de coloration, en quantiles, et avec des seuils explicites (pour faciliter les comparaisons à venir entre carte brute et cartes lissées) :
classify field=part_rn quantile classes=5 colors=Oranges \ style stroke='d.fill' classify field=part_rn breaks=35,40,45,50 colors=Oranges \ style stroke='d.fill'Européennes 2024 – Part des votes RN et Reconquête (%) – par hexagone de niveau 7
Le lissage final
Pour lisser les données par fenêtre spatiale mobile, il me faut faire le lien entre un hexagone donné, et l’ensemble des hexagones voisins, de premier niveau jusqu’au niveau 10.
h3_grid_disk_distances() me donne cette liste d’anneaux successifs en un seul appel. C’est un autre atout majeur du système H3.
CREATE OR replace VIEW corresp_h3_res7_dist10 AS WITH t1 AS ( FROM 'fra_h3_res7_v2.parquet' SELECT id, list_transform(h3_grid_disk_distances(id, 10), (c,i) -> {ids:c, distance:i}) .unnest(recursive := true) ) FROM t1 SELECT id, unnest(ids) id2, distance ;
L’opération de lissage résulte d’un appariement de cette table de correspondance et des données de vote à l’hexagone. Je définis une fonction de pondération inverse de la distance, et je me réserve la possibilité d’ajuster le rayon de lissage.
CREATE OR REPLACE VIEW s_h3_res7_europ2024_liss as FROM corresp_h3_res7_dist10 c JOIN s_h3_res7_europ2024 p ON c.id2 = p.id SELECT c.id, sum( RN /(1 + pow(distance-1,1.5)) ) RN, -- 1.5 (pondération) ajustable sum(exprimes/(1 + pow(distance-1,1.5)) ) exprimes WHERE distance
Pour rappel, la méthode commence par agréger séparément le numérateur et le dénominateur, le taux « ambiant » est calculé dans un second temps, avant export vers Mapshaper :
COPY ( FROM 'fra_h3_res7_v2.parquet' JOIN s_h3_res7_europ2024_liss USING(id) SELECT RN, exprimes, round(100*RN/exprimes,1) part_rn, geom ) TO 'a_h3_res7_europ2024_fra_liss_l5_p15.json' WITH (format GDAL, driver GeoJSON) ;classify field=part_rn breaks=35,40,45,50 colors=Oranges \ style stroke='d.fill'Voici le résultat, avec en prime une comparaison avec le vote le Pen lors de l’élection présidentielle de 2022.
Européennes 2024 – part des votes RN et Reconquête (%) et présidentielle 2022 – Part du vote le Pen (%)
2024
 2022
2022
Ces deux cartes présentent de grandes similitudes. Même si les seuils ne sont pas comparables (le vote RN était supérieur, en %, en 2002, mais il s’agissait du 2d tour, avec donc seulement 2 candidats en présence).
D - À vous de jouer !Ci-dessous figure l’accès à ce kit de lissage : la couverture H3 de la France au niveau 7, et la table de correspondance entre chaque hexagone et leurs voisins. Les préparer a demandé un peu de temps, comme on l’a vu ci-dessus.
Leur application à toute base de données communales est toutefois simple et rapide, deux requêtes suffisent, et tournent en moins de 10 secondes : ventilation des valeurs additives sur la grille H3, et lissage par fenêtre mobile. Avec Mapshaper, vous en voyez très rapidement le résultat. Lisser ne demande qu’un éditeur SQL (ou le client léger DuckDB) et le navigateur web.
Pour en savoir plus- H3 : Hexagonal hierarchical geospatial indexing system
- Manuel d’analyse spatiale – Insee Méthodes
- Prendre en compte l’hétérogénéité spatiale avec le lissage – diaporama Insee
- Lissages interactifs sur l’élection présidentielle 2022
- Kit de lissage H3 France sur data.gouv
- Installer la version de dév de DuckDB
- Bindings for H3 to DuckDB
L’article Les lignes de force du vote RN en 2024 : une cartographie lissée avec la grille H3 est apparu en premier sur Icem7.
-
sur Comment bien préparer son Parquet
Publié: 16 May 2024, 5:14pm CEST par Éric Mauvière
De plus en plus de bases sont désormais diffusées en parquet, ce format de données compact, maniable et spectaculairement rapide à interroger. Des outils simples le permettent.
J’observe pour autant ici ou là quelques défauts de préparation qui amoindrissent les avantages de ce nouveau format. Il est facile de les corriger avec un peu de vigilance, les bons outils, et le réflexe de tester ses fichiers avec quelques requêtes types.
 7 points d'attention
7 points d'attention
1 – Des colonnes facilitant l’écriture d’une requête
Cela commence par des noms de colonnes simples à comprendre et à écrire dans une requête : en minuscules, sans accents ni blancs, d’une longueur modérée, par exemple inférieure à 15 caractères. Plutôt que « Code du département », on choisira par exemple « code_dept ».
À l’inverse, l’obscur « nb_vp » peut être précisé en « nb_veh_part » (pour nombre de véhicules particuliers).
On peut aussi ajouter des colonnes qui serviront souvent à filtrer le jeu de données. Pour des données quotidiennes renseignées avec un champ date, n’hésitons pas à placer un champ annee. En parquet, il ne prendra pas beaucoup de place, grâce à la compression.
2 – Définir les bons types de colonne
Une colonne de nombres codés en caractères n’est pas utilisable en l’état. La pire situation : des nombres avec virgule stockés comme du texte. De même, une date doit être décrite selon le type date : on pourra ainsi plus facilement la trier, en extraire le mois ou le jour de la semaine.
Je vois encore fréquemment des codes commençant par 0, comme un code département, qui perdent leur 0 : 09 devient 9, ou 04126 devient 4126. Voilà qui va compromettre les jointures avec d’autres fichiers bien construits.
Quelques optimisations plus fines amélioreront les performances : stocker un champ complexe (json, liste, hiérarchie) non comme du texte mais comme json, map ou struct. Un entier gagnera à être typé comme tel, et non comme float ou double ; un logique comme booléen et non « True » ou « False ».
3 – Trier le fichier selon une ou deux colonnes clés
Le tri est un critère essentiel : une requête filtrée sur un champ trié sera jusqu’à 10 fois plus rapide. Les requêtes de plage sur un fichier parquet permettent dans ce cas de cibler et réduire les seules plages à lire dans le fichier.
Par ailleurs, un fichier trié sur un ou deux champs de faible cardinalité (peu de valeurs distinctes) sera bien plus léger, bénéficiant d’une compression plus efficace.
Cas typiques : trier par année, puis code géographique ; trier un répertoire par code Siren ; trier un fichier géographique (geoparquet) par geohash.
4 – Choisir la meilleure stratégie de compression
Réduire la taille d’un fichier parquet n’est pas une fin en soi. Ce qui importe est de trouver le meilleur compromis entre gain de transfert et vitesse de décompression.
Le contexte d’usage doit aussi être pris en considération : le fichier parquet sera-t-il souvent accédé en ligne (auquel cas la bande passante et donc la compression des données transmises comptent), ou plutôt sur disque local rapide (et là on se passera volontiers du temps de décompression, et donc de la compression).
En pratique, la compression ZStd est la plus intéressante (davantage que le défaut Snappy) : elle est efficace et rapide à décoder.
5 – Ajouter une colonne bbox à un fichier geoparquet
Un fichier geoparquet décrit des données localisées qu’on voudra souvent filtrer à partir d’une emprise, typiquement un rectangle d’extraction. Chaque entité du geoparquet bénéficiera de la présence d’une colonne bbox (de type struct) définissant son rectangle englobant, conformément à la spécification geoparquet 1.1 en préparation.
La géométrie dans un géoparquet peut être codée en WKB ou en GeoArrow. Ce second format est bien plus performant et sera intégré à la spec geoparquet 1.1. Mais il faudra attendre encore un peu pour qu’il soit suffisamment adopté, notamment en lecture.
6 – Servir un fichier parquet à partir d’un stockage physique et non à la volée en API
Certaines plateformes proposent des formats parquet générés à la volée. Le processus est toujours affreusement lent (parquet est un format subtil et complexe à fabriquer). Et il compromet le requêtage direct en ligne car les métadonnées principales d’un parquet sont stockées à la fin du fichier. On perd donc la formidable possibilité propre à Parquet de réduire les plages de données à lire.
Parquet est un format de diffusion qui doit être stocké physiquement pour pouvoir être scanné rapidement (et bénéficier de la mise en cache des requêtes de plage).
7 – Affiner si besoin le nombre de row groups
Un fichier Parquet se structure en groupes de lignes (row groups), puis en colonnes. La taille de ces groupes de lignes doit être optimisée selon les usages pressentis : plutôt large si le fichier doit souvent être lu en grande part, plus réduite si les requêtes sont plutôt très sélectives (ce sera par exemple plus fréquent avec un fichier géographique).
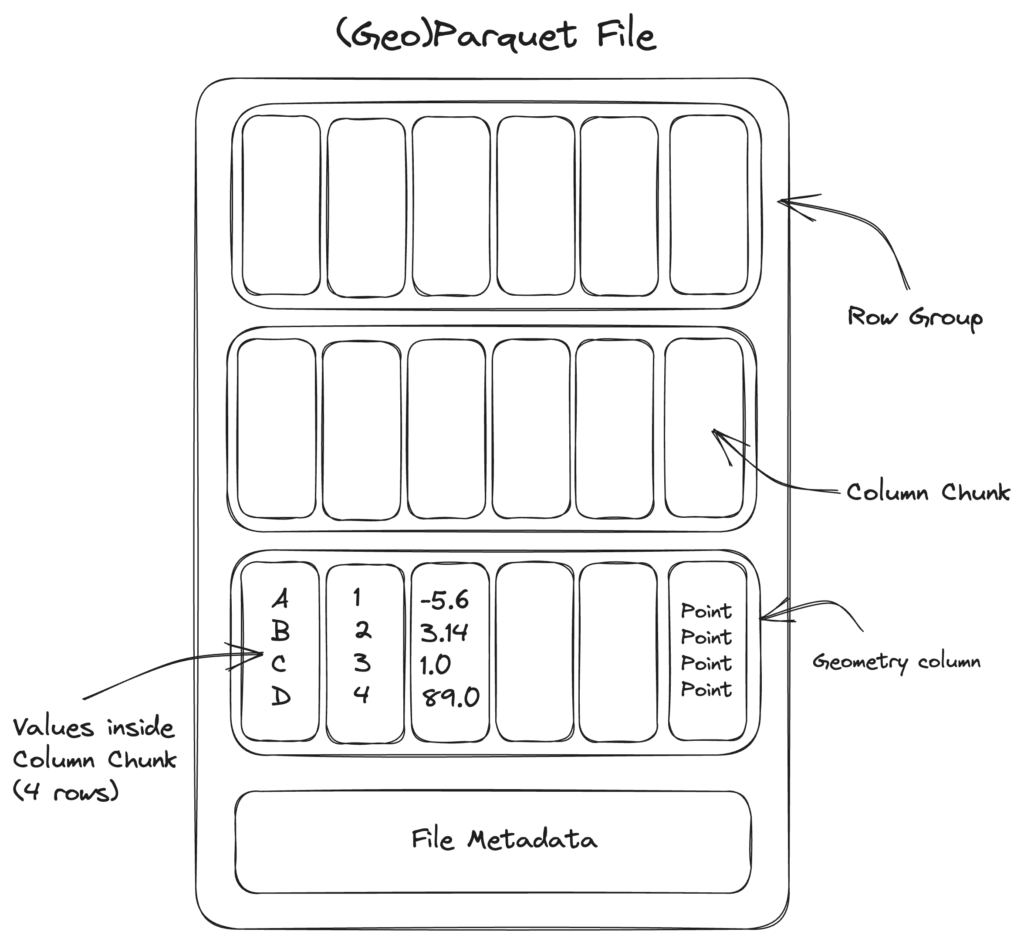
Rappels sur la structure d'un fichier parquetParquet est un format orienté colonne, mais il organise d’abord en groupes de lignes dans lesquels il dispose bout à bout les données des différentes colonnes. Ces « column chunks » ou morceaux de colonne sont compressibles et, comme chaque colonne présente un type homogène, cette compression est efficace.
Un fichier parquet est truffé de métadonnées : au niveau supérieur, décrivant la structure du fichier (nombre de lignes, liste des colonnes et leur type…) et au niveau de chaque row group : valeurs min et max de chaque column chunk, nombre de valeurs distinctes…
Un moteur de requête va prioritairement lire ces zones de métadonnées avant de décider quelles « plages de bits » extraire. Il lui est ainsi souvent possible de sauter plusieurs row groups dont il comprend qu’ils ne peuvent satisfaire la requête courante. Par ailleurs, seules les données des colonnes spécifiées dans la requête seront scannées. C’est tout l’intérêt d’un format orienté colonne.
 [https:]
L'importance du tri
[https:]
L'importance du tri
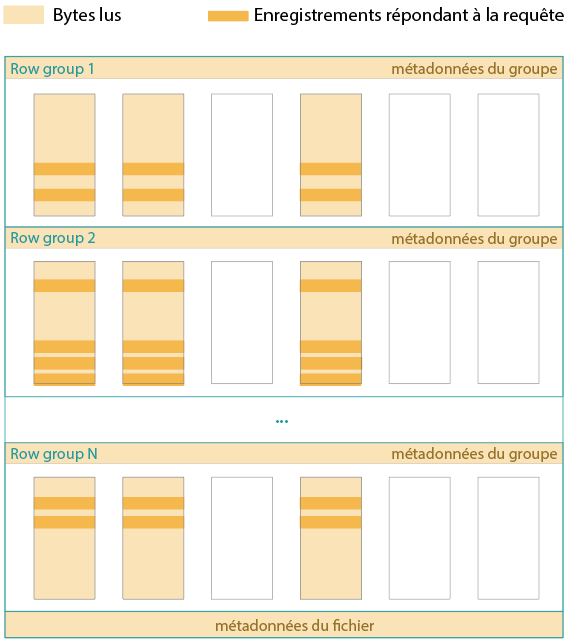
Prenons le cas d’un fichier non trié et d’une requête sélective, qui précise un critère de filtrage. Le schéma suivant matérialise en orange foncé les lignes à extraire des colonnes visées. Chaque row group en comprend, si bien qu’il va falloir extraire les données contenues dans tous les column chunks colorés.
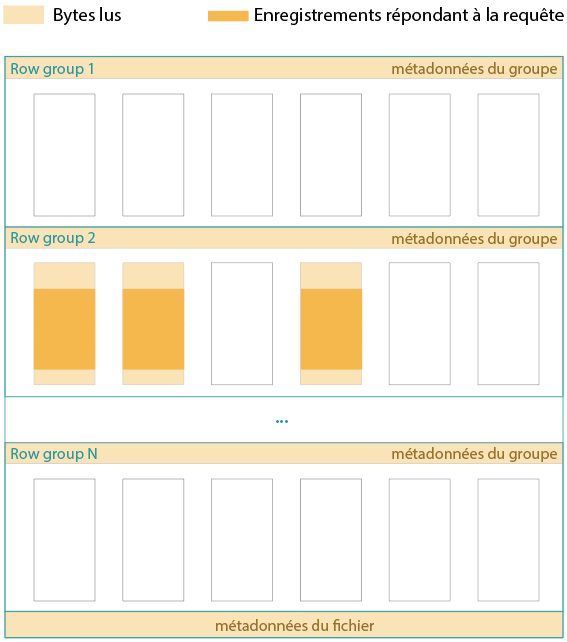
Quand le fichier est trié selon un ou deux champs clés, et que la requête filtre sur l’un de ces champs, notamment le premier, il y aura forcément un certain nombre de row groups « hors champ ». Par exemple, si j’extrais l’année 2018 d’un fichier comprenant des données quotidiennes entre 2010 et 2020, et que le fichier est d’abord trié par année.
Avec nettement moins de données à lire, la requête sera bien plus rapide. C’est ainsi que l’on peut requêter un fichier de 1 Go en ligne, en ne chargeant que quelques Mo de données.
 Quels outils utiliser pour optimiser son Parquet ?
Quels outils utiliser pour optimiser son Parquet ?
J’ai testé la conversion d’un fichier CSV de 5 Go et 25 millions de lignes (une base du recensement de l’Insee) en parquet, avec différents outils. Ce fichier est délimité par des ; et comprend entre autres une douzaine de codes pouvant commencer par 0.
DuckDB est l’outil plus maniable et le plus efficace : rapide, automatique, simple d’écriture.
Outil
Temps en minutes
Taille en Mo du parquet
Commentaires
Polars/Rust
1
500
Spécifier délim et types des codes avec 0 en 1er
DuckDB Cli threads 4
1
350
Trop facile DuckDB Cli
1,5
350
Trop facile R/Arrow
1,7
290
Spécifier délim et types des codes avec 0 en 1er
Python/Arrow
2
290
Spécifier délim et types des codes avec 0 en 1er
R/Parquetize
11
400
CATL et TYPL mal typés (ex : 1.0 à la place de 1)
Voici le meilleur compromis d’écriture avec DuckDB.
SET threads = 4 ; COPY 'data_recensement_2017.csv' TO 'data_recensement_2017.parquet' (compression zstd) ;DuckDB reconnait tout seul le délimiteur français (;) et prend soin des colonnes avec des codes commençant parfois par 0. Enfin, l’outil DuckDB est super léger (25 Mo), s’installe et se lance en un clin d’œil.
Contrôler le nombre de threads, dans le cas de processus lourds, est souvent utile. Par défaut ce nombre équivaut au nombre de cœurs de la machine (12 dans mon cas, et réduire les threads du plan d’exécution à 4 accélèrera le traitement).
Polars dans Python est une bonne alternative (si vous utilisez déjà Python) pour une rapidité (équivalente). Mais Polars impose de spécifier le bon délimiteur et va maltraiter les colonnes de codes commençant par 0 si on ne le surveille pas de près.
Il faut donc lui préciser explicitement toutes les colonnes à préserver, c’est dissuasif et source d’erreurs. Enfin, le fichier généré est sensiblement plus gros. L’optimiser demanderait probablement à Polars plus de temps d’exécution.
import polars as pl pl.read_csv("data_recensement_2017.csv", separator = ';', \ dtypes = {'COMMUNE': pl.String}) \ .write_parquet("data_recensement_2017.parquet", \ compression = 'zstd', use_pyarrow = False)Dans R, la librairie arrow semble la plus véloce pour assurer la conversion de csv vers parquet, bien qu’un peu moins que Polars. Et comme lui, elle exige de préciser le délimiteur et le type des colonnes avec des 0.
library(arrow) write_parquet(read_delim_arrow('data_recensement_2017.csv', delim = ';', as_data_frame = FALSE), 'data_recensement_2017.parquet', compression = 'zstd')Autrement dit, si vous voulez travailler dans R ou Python, n’hésitez pas à utiliser la librairie DuckDB : c’est possible, plus simple à écrire, et plus rapide.
L'intérêt du partitionnement pour les très gros fichiersSi votre fichier parquet doit dépasser les 10 Go et qu’il est plutôt utilisé en local ou sur un cloud comme S3 ou GCS, il y a tout intérêt à le découper en plusieurs fichiers selon les modalités d’un ou plusieurs champs clés, ce que l’on appelle partitionner.
L’instruction suivante crée ainsi une série de sous-répertoires dans lequel figure un fichier parquet par région. Mais on peut partitionner sur 2 colonnes ou plus.
COPY 'data_recensement_2017.csv' TO 'export' (FORMAT PARQUET, PARTITION_BY (REGION), compression zstd)Dans cet exemple, si la requête ne concerne qu’une région, seul le fichier pertinent sera interrogé.
Quels outils utiliser pour optimiser son GeoParquet ?FROM read_parquet('export/*/*.parquet', hive_partitioning = true) WHERE REGION = '76' ;Le cas geoparquet est particulier. DuckDB sait lire ce format, mais pas encore le générer (NDR : annoncé pour juillet 2024). Il faut donc pour l’heure en passer par exemple par Python (geopandas) ou R (sfarrow), à partir d’un format SIG classique (geojson, shape, gpkg, etc.).
Plus simple, si vous disposez de QGIS : exporter/sauvegarder sous au format geoparquet. De plus QGIS (profitant en cela de GDAL) permet de choisir l’encodage WKB ou GeoArrow. GDAL devrait permettre prochainement de produire une colonne bbox servant d’index spatial.
Enfin, pour accélérer plus encore les requêtes filtrées par emprise, ce sera une excellente idée que de trier votre Geoparquet astucieusement selon un indice de grille comme Geohash, H3, S2 ou une « quadkey ».
Un tel « hash » géographique peut être calculé par exemple à partir du centroide de chaque entité géographique. Deux hashes voisins (grâce au tri par exemple) garantissent que les entités correspondantes sont spatialement voisines.
La gigantesque base en ligne OvertureMaps est organisée de cette façon, et de surcroit partitionnée, si bien que cette requête DuckDB d’extraction de 500 m autour de la tour Eiffel ne lit que 13 Mo de données :
LOAD spatial ; FROM read_parquet('s3://overturemaps-us-west-2/release/2024-05-16-beta.0/theme=places/type=*/*') SELECT ST_GeomFromWKB(geometry) AS geom, names, categories WHERE bbox.xmin > 2.2877 AND bbox.ymin > 48.8539 AND bbox.xmax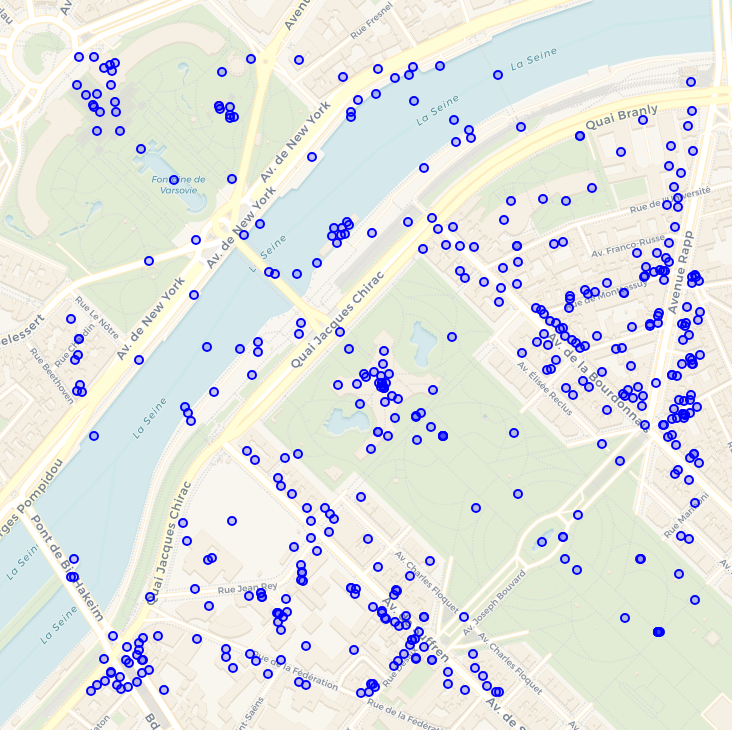
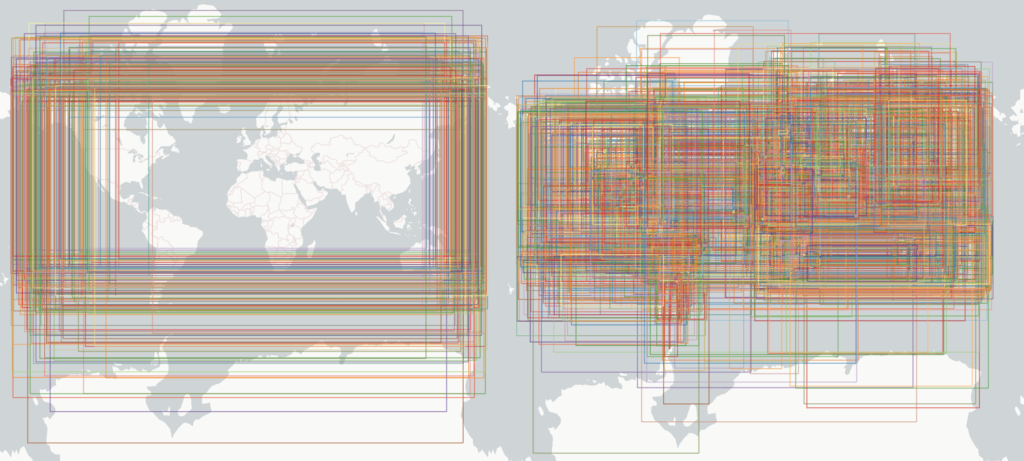
Jacob Wassemarman démontre par ces deux images la spectaculaire progression du partitionnement et du tri dans OvertureMaps.
Dans la version de janvier 2024, encore non optimisée, voici les rectangles englobants pour chaque fichier du partitionnement (à gauche) puis pour chaque row group (à droite) :
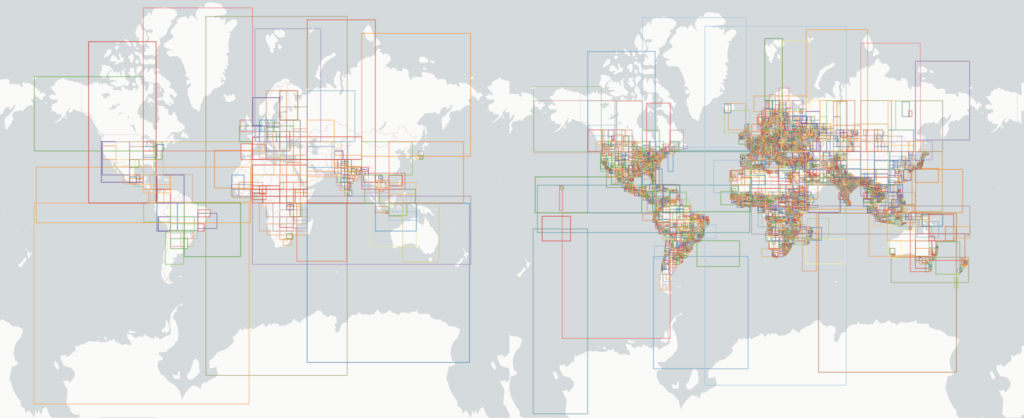
Depuis mars 2024, avec un partitionnement intelligent approchant les pays et un tri de chaque fichier par geohash, voici la différence, dont on comprend que l’impact sur l’efficacité des requêtes spatiales est radical :
 Quelques instructions pour tester son fichier parquet
Quelques instructions pour tester son fichier parquet
Un fichier parquet comprend de nombreuses métadonnées, qu’il est facile de lire dans DuckDB.
-- Métadonnées générales : nombre de lignes, nombre de row groups FROM parquet_file_metadata('https://object.files.data.gouv.fr/data-pipeline-open/prod/elections/candidats_results.parquet'); -- Liste des colonnes avec leur type FROM parquet_schema('https://object.files.data.gouv.fr/data-pipeline-open/prod/elections/candidats_results.parquet'); -- Liste des row groups, de leurs colonnes et statistiques pour chaque colonne (min, max, valeurs distinctes, valeurs nulles, compression...) FROM parquet_metadata('https://object.files.data.gouv.fr/data-pipeline-open/prod/elections/candidats_results.parquet'); -- Métadonnées spécifiques, par exemple pour un geoparquet : bbox, type de géométrie, projection... SELECT decode(key), decode(value) FROM parquet_kv_metadata('s3://overturemaps-us-west-2/release/2024-05-16-beta.0/theme=places/type=*/*') WHERE decode(KEY) = 'geo';Pour connaitre le plan d’exécution et en particulier la bande passante utilisée par une requête, EXPLAIN ANALYZE est incontournable et nous aide à déterminer, à partir d’un choix de requêtes types les plus probables, les meilleurs options de tri, voire de taille des row groups.
Pour en savoir plusEXPLAIN ANALYZE FROM read_parquet('s3://overturemaps-us-west-2/release/2024-05-16-beta.0/theme=places/type=*/*') SELECT ST_GeomFromWKB(geometry) AS geom, names, categories WHERE bbox.xmin > 2.2877 AND bbox.ymin > 48.8539 AND bbox.xmax- DuckDB – Parquet tips
- GeoParquet 1.1 coming soon! – Chris Holmes
- An Empirical Evaluation of Columnar Storage Formats – Xinyu Zeng & al.
- The Battle of the Compressors: Optimizing Spark Workloads with ZStd, Snappy and More for Parquet
- Sorting and Parquet – Pankaj Gupta
- GeoParquet Spatial Sorting/Indexing/Partitioning – Jacob Wasserman
- Completely In-fused ! Guillaume Sueur
- Parquet devrait remplacer le format CSV – icem7
- 3 explorations bluffantes avec DuckDB – Interroger des fichiers distants (1/3), icem7
L’article Comment bien préparer son Parquet est apparu en premier sur Icem7.
-
sur Transmettre un message percutant
Publié: 12 March 2024, 6:29pm CET par Isabelle Coulomb
Éric est régulièrement sollicité sur le thème de la sémiologie graphique, un de ses domaines d’expertise. Il intervient souvent pour des conférences, des exposés, des formations. Encore la semaine dernière, il était invité par SSPHub, le réseau des « datascientists » des services de la Statistique Publique, pour une visioconférence intitulée “La dataviz pour donner du sens aux données et communiquer un message”.
Les présentations d’Éric se basent toujours sur des exemples concrets et récents, qu’il va piocher dans les publications des organismes qui font appel à lui. Il se base sur ces exemples pour les décortiquer, puis examiner quels seraient les ajustements possibles, en vue de les rendre plus signifiants. Ce petit jeu du « avant / après » est très éloquent ; c’est un outil pédagogique toujours efficace.
Le jeu des différences avant / aprèsJ’ai le privilège d’être la première spectatrice des présentations qu’Éric prépare. C’est toujours un plaisir gourmand de découvrir quels nouveaux exemples il a réussi à dénicher. Pour la conférence en ligne pour SSPHub, Éric a puisé dans l’actualité de plusieurs services statistiques, l’Insee en premier lieu, évidemment, mais aussi les services statistiques des ministères de la Justice, de la Transition écologique, du Travail et de la Santé…
Parmi la quinzaine d’exemples analysés, quelques-uns ont particulièrement retenu mon attention : ceux qui non seulement sont les plus marquants sur le contraste entre « avant » et « après », mais surtout exposent des données originales et une information inédite. Mon préféré est un graphique publié dans une étude de la Drees, le service statistique du ministère en charge de la santé.
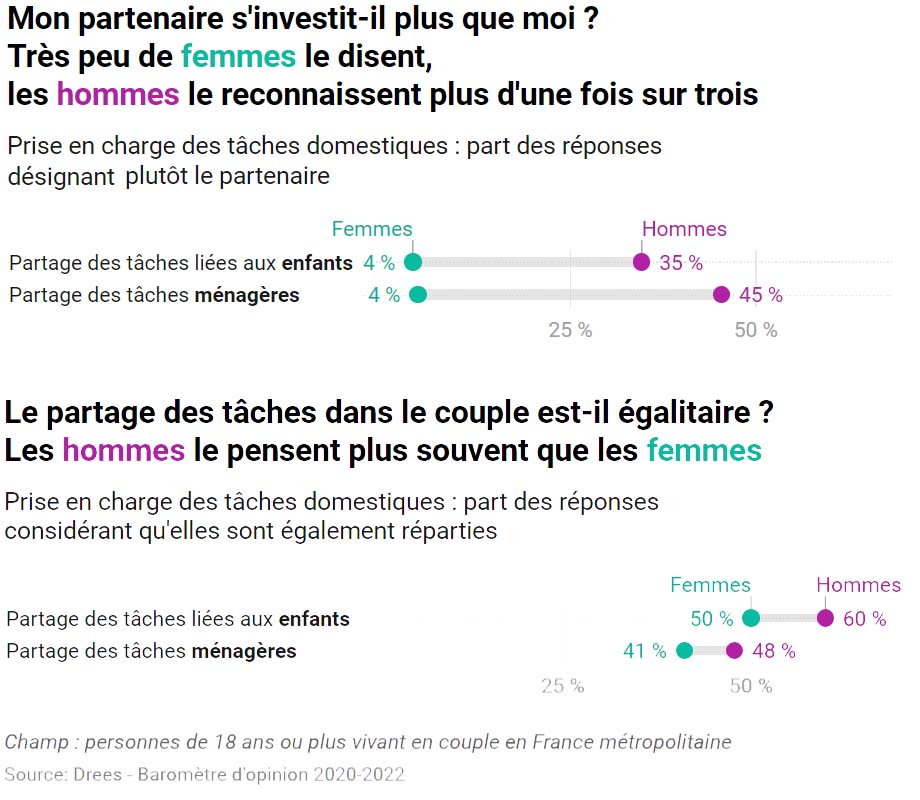
Cette étude, publiée le mois dernier, est intitulée Des stéréotypes de genre encore très ancrés, notamment chez les hommes. Il s’agit d’un document de 8 pages qui rapporte les résultats d’une enquête d’opinion à propos des croyances sur les comportements masculins et féminins. Voilà qui tranche nettement avec les sujets couramment abordés par la statistique publique. Le graphique retenu par Éric pour son exercice de dissection parle de partage des tâches domestiques.
 Avant
Avant
 Après
Après
Parmi les cibles privilégiées d’Éric, se trouvent les diagrammes en barres empilées. Ils sont très fréquents dans les publications des services statistiques ; ils sont pourtant rarement efficaces. Mieux vaut séparer les messages que tout mettre sur une même représentation. UN graphique correspond à UN message. Objectif : réduire l’effort du lecteur.
Ensuite, l’habillage compte aussi, jusque dans les détails : choisir un titre informatif, placer la légende au plus près des éléments graphiques, en utilisant astucieusement un code couleur, le tout sans surcharger inutilement. Au bout du compte, la note de lecture n’est plus indispensable : le graphique parle de lui-même.
L’étude dont il est question ici comporte plusieurs autres graphiques. J’ai demandé à Éric d’en passer un autre dans sa moulinette « avant / après ». Le résultat présenté ci-dessous montre que les barres empilées ne sont pas toutes à rejeter. Elles trouvent leur utilité quand elles représentent une répartition en pourcentage dont le total donne 100 %.
Les présentations et les formations animées par Éric sont appréciées pour leur caractère concret et vivant, avec des exemples toujours renouvelés, choisis pour leur intérêt au regard du thème de la datavisualisation et de la sémiologie graphique.
Des dataviz pour éclairer les débats de sociétéAu-delà de ces vertus pédagogiques, ils sont aussi instructifs par les messages qu’ils portent. Ils se rapportent souvent à la démographie ou à l’économie, domaines de prédilection de la statistique publique. Ils abordent aussi des thèmes plus sociaux, la justice, l’environnement ou… les inégalités hommes/femmes.
Il est largement établi que la répartition des tâches domestiques repose encore largement sur les femmes. Il est encore plus édifiant de constater l’écart de vision entre les hommes et les femmes. Les hommes croient davantage qu’ils font leur part. Un grand merci aux statisticien·nes qui apportent ces éléments objectifs de mesure.

La photo utilisée comme image mise en avant pour cet article provient d’une banque d’images libres de droit. Elle date de 1942.
Et pour vous, qu’est-ce que cela évoque, cette vieille photo en noir et blanc d’un couple faisant ensemble la vaisselle ?
L’article Transmettre un message percutant est apparu en premier sur Icem7.
-
sur Accrocher le regard
Publié: 28 December 2023, 12:01pm CET par Isabelle Coulomb
Qu’est-ce qui retient notre attention ? Dans le flot d’informations dans lequel nous baignons en permanence, il arrive que quelque chose accroche notre regard. C’est le eye catching content, le graal que recherche toute personne souhaitant communiquer.
Je reçois chaque jour des dizaines de courriels, que je ne peux pas tous lire. Dans ce flot, un titre a capté mon attention, il y a quelques jours : walking or cycling 30 minutes per day. Dans mon filtre personnel, les mots-clés walk ou marche sont très réactifs. Cela m’a conduite à cette image :
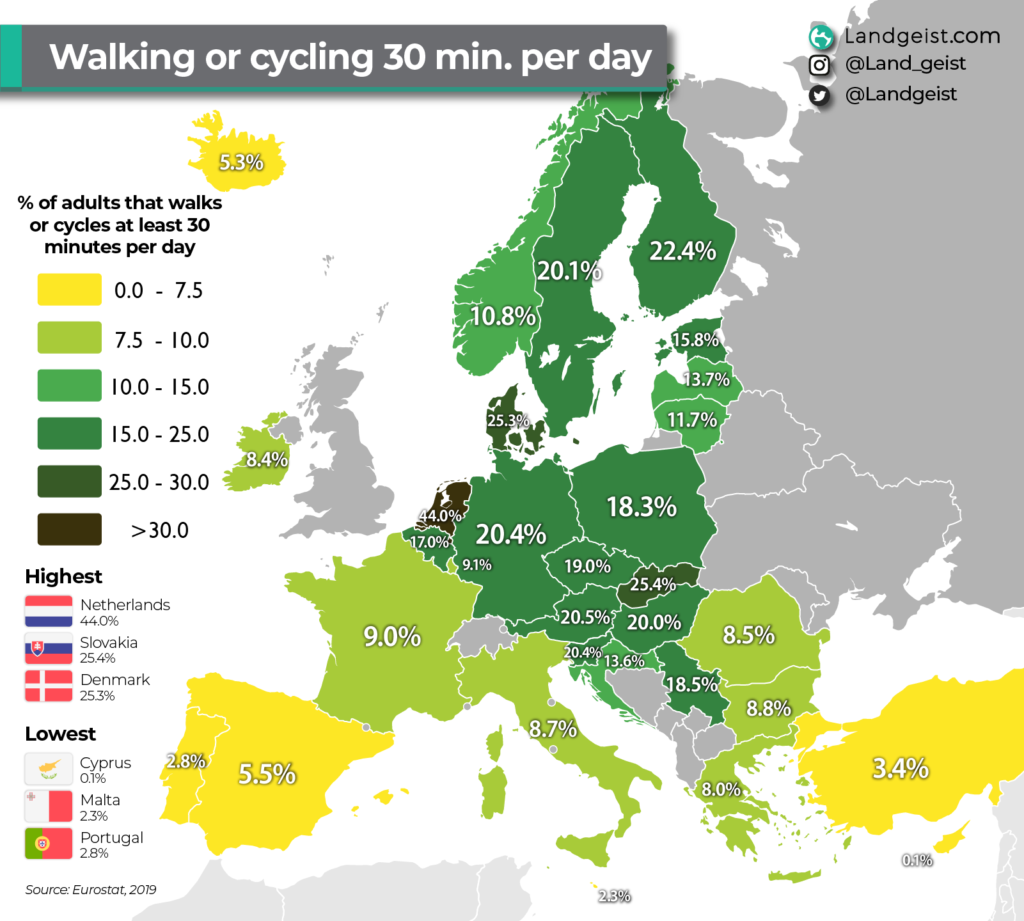
Une carte statistique qui parle de marche, cela ne pouvait pas m’échapper ! Cette image, indéniablement accrocheuse, m’a sauté aux yeux, avec ses couleurs très brillantes, jaune radieux, vert éclatant, rouge lumineux.
Le message de cette carte est loin d’être aussi brillant que ses couleurs ! D’ailleurs, le commentaire qui accompagne la carte souligne : « si le pourcentage est très variable d’un pays à l’autre, dans aucun pays une majorité de personnes ne se déplace à pied ou à vélo au moins une demi-heure par jour ». Pour l’ensemble des 27 pays pris en compte, moins de 2 personnes sur 10 atteignent cette durée ! Et pendant ce temps-là, les maladies chroniques de tout type prolifèrent…
J’aurais imaginé trouver un autre contraste entre les pays du nord et du sud, ces derniers bénéficiant d’un climat plus clément. Les aléas de la météo ne sont apparemment pas un frein pour les piétons et les cyclistes. Les pays avec les pourcentages les moins bas sont aussi les pays de faible superficie.
Cela a éveillé ma curiosité : j’ai eu envie de creuser le sujet, d’abord pour trouver une représentation cartographique moins agressive pour mes yeux, ensuite pour remonter à la source des données.
À la source des donnéesLa source des données, c’est évidemment Eurostat. Sa base de données contient des centaines d’indicateurs, rigoureusement classés dans une arborescence détaillée. Celui que je cherche se trouve logiquement dans Santé > Déterminants de santé > Activité physique.
L’explorateur de données d’Eurostat, Data Browser pour les intimes, permet de visualiser ces données sous plusieurs formes. La première est un tableau statistique de 27 lignes : une par pays, une de moins depuis que le Royaume-Uni vogue de son côté.Sa base
Le tableau comprend plus de colonnes que j’imaginais, puisque l’indicateur en question se décline selon 3 critères : sexe, âge et niveau de formation. Cela valait la peine de creuser le sujet ! L’explorateur de données offre aussi des possibilités de datavisualisations : diagrammes et cartes. Pas de courbes d’évolution possibles ici, car l’indicateur n’est disponible que pour l’année 2019. Voici la carte que j’obtiens pour l’indicateur global Marcher et faire du vélo au moins 30 minutes par jour :
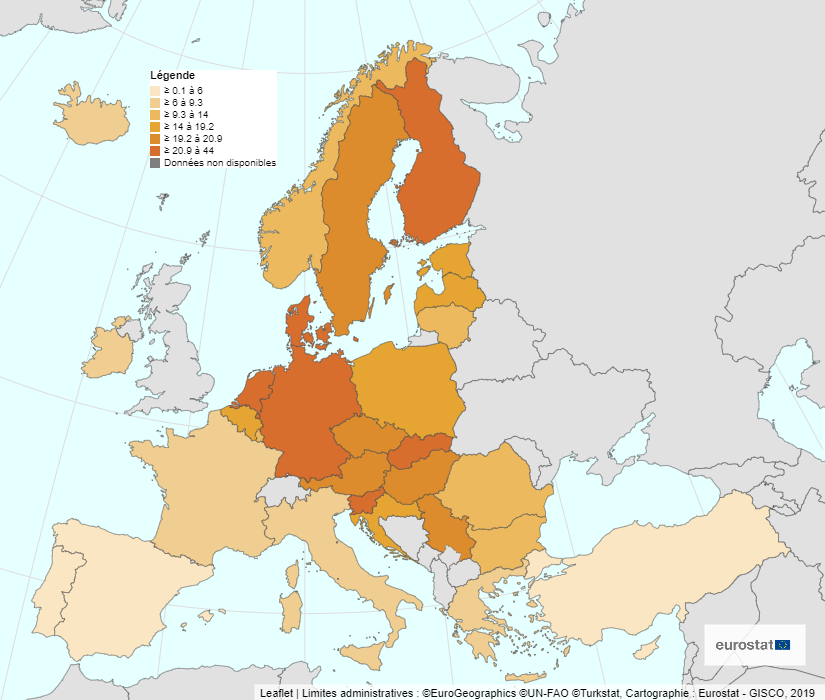
La palette de couleurs est nettement moins agressive que pour la première : je préfère. L’adage dit « des gouts et des couleurs, on ne discute pas. » Il convient toutefois de trouver un équilibre : de la couleur oui, mais pas trop !
La carte est dépouillée de la surcharge des chiffres : plus reposant et plus lisible. Les valeurs se retrouvent indiquées au survol de chaque pays : une ébauche d’interactivité très utile. L’image est également allégée du palmarès illustré avec les drapeaux des pays cités : une surcharge visuelle qui détournait de l’essentiel.
La légende est curieusement positionnée, avec toujours un découpage en 6 classes, mais selon une discrétisation moins adaptée : elle ne met pas en évidence l’écart entre les Pays Bas (44 %) et les pays suivants (autour de 20 %). Dans cet export au format png, la carte ne comporte pas de titre, ni de rappel du nom de l’indicateur (ce dernier est présent en dessous de la carte dans l’export au format pdf).
Plus actifs (ou moins inactifs) :
les hommes ou les femmes ?Maintenant que j’ai découvert que l’indicateur auquel je m’intéresse se décline selon d’autres critères, je suis curieuse de voir quelles informations supplémentaires cela apporte. Par exemple, existe-t-il des différences notables entre les hommes et les femmes ?
L’explorateur de données d’Eurostat me permet d’obtenir une carte pour chaque colonne du tableau de données, en particulier, une pour les hommes et une pour les femmes. Sauf que, pour chaque carte, la discrétisation est recalculée automatiquement et elle est chaque fois différente. Les cartes ne sont donc pas comparables entre elles.
Il y a quelques années, j’aurais tout naturellement utilisé une application fonctionnant avec Géoclip pour créer les cartes de mon choix. Aujourd’hui, je m’en vais explorer d’autres outils de cartographie thématique en ligne. Voyons par exemple ce qu’il est possible de construire avec Khartis, l’outil de création de cartes thématiques proposé par l’Atelier cartographique de Sciences Po.
Dans le Data Browser d’Eurostat, j’exporte très simplement la table de données dont j’ai besoin. Après un petit détour par un tableur, j’importe cette table dans Khartis, d’un rapide copier-coller. La Tchéquie se convertit aisément en République tchèque pour établir la jointure avec les 27 pays du fond de carte.
Reste le paramétrage de la visualisation qui demande plus de soin. Je choisis le même découpage en tranches de valeurs pour les 2 cartes hommes et femmes, afin d’obtenir deux représentations cartographiques comparables.
Pour finir, l’export est possible dans plusieurs formats : png ou svg. Le format svg est très pratique, car plus facilement modifiable pour une personnalisation plus poussée.
Le résultat obtenu en png convient déjà très bien. Khartis propose un joli choix de palettes de couleurs pour les dégradés : bien contrastées, sans être trop agressives.
Il y a beaucoup d’éléments personnalisables : titre, position de la légende, dimensions, couleur des éléments d’habillage, ajout d’étiquettes…
Pour finir, il est possible de sauvegarder le projet, pour le conserver ou le transmettre à une autre personne. Je n’ai pas testé cette possibilité, mais c’est une bonne idée.
Voilà les 2 cartes que j’obtiens, avec les femmes à gauche et les hommes à droite :
Les pays les plus foncés et les plus clairs restent à peu près les mêmes. Les hommes sont (un peu) plus actifs que les femmes. Apparaissent toutefois quelques différences selon les pays. Cependant, les cartes thématiques ne sont pas les mieux à même de les faire ressortir.
Je fais donc appel à mon conseiller en datavisualisation préféré. Il me suggère un outil dont il est fan : Datawrapper. L’objectif annoncé dès la page d’accueil : No code or design skills required. Là encore, un copier-coller de la table de données, quelques réglages pour choisir les paramètres, dans un cadre bien guidé. Et hop, un graphique en barres horizontales, qui montre mieux les différences :
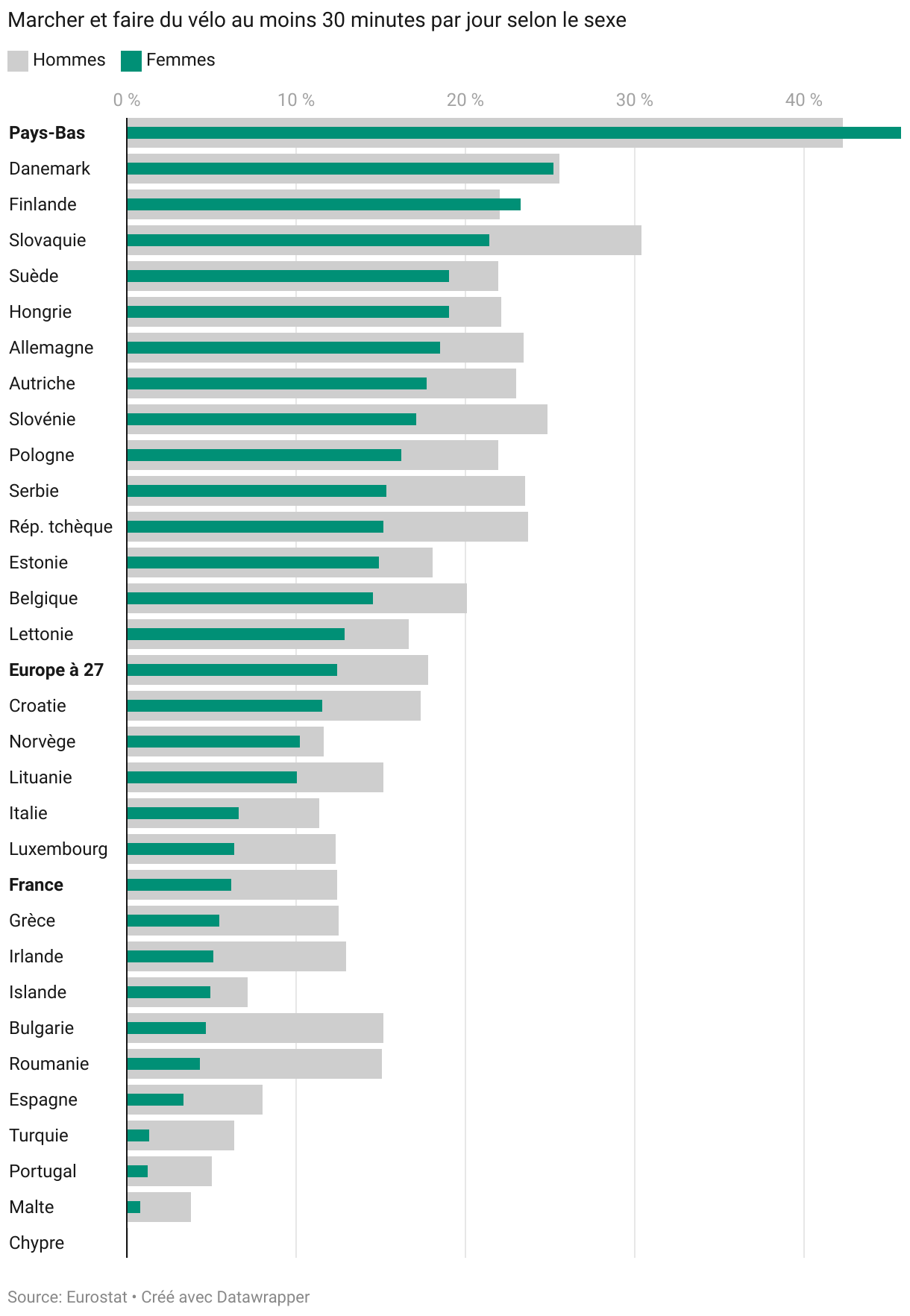
Ce graphique met en évidence que les pays où les femmes sont proportionnellement les plus nombreuses à se déplacer à pied ou à vélo sont aussi les pays où les femmes devancent les hommes dans cette pratique. Bravo et merci à ces 3 pays, Pays-Bas, Danemark, Finlande. Je n’ai jamais eu l’occasion d’y voyager. Je sais cependant qu’ils sont connus pour disposer d’aménagements confortables, qui encouragent et facilitent les modes actifs de déplacement.
Ce n’est pas une découverte, la cartographie thématique est un moyen puissant de « faire parler les données ». Pourtant, un graphique tout simple permet parfois une lecture plus directe et efficace. C’est ce qui ressort régulièrement des exemples que choisit Éric dans ses interventions, en formation, en conférence ou en accompagnement. Certes, il existe des outils pour créer facilement des cartes et des graphiques. Pour éviter de tomber dans le piège de produire des images aussi multicolores que des perroquets, mieux vaut connaître les fondamentaux de sémiologie graphique.

L’article Accrocher le regard est apparu en premier sur Icem7.
-
sur 3 explorations bluffantes avec DuckDB – Croiser les requêtes spatiales (3/3)
Publié: 19 December 2023, 10:33am CET par Éric Mauvière
Nous sommes entourés de données géolocalisées. La séparation données statistiques / données spatiales est bien souvent arbitraire. Mais si elle perdure, c’est parce que les outils SIG (systèmes d’information géographiques) sont lourds à installer et complexes à utiliser.
Avec son extension spatiale, DuckDB met enfin l’analyse géographique à la portée de tou·tes.
Comme dans les deux articles précédents, je vais présenter deux cas concrets, l’un avec les données GTFS de transports en commun dans la métropole toulousaine, l’autre avec la base adresse nationale (BAN).
A - Le standard GTFS pour analyser les transports en commun à ToulouseLe format GTFS (General Transit Feed Specification) permet aux gestionnaires de transports en commun de mettre à disposition, quotidiennement, des informations détaillées sur leur réseau, les horaires et emplacement des arrêts, le niveau de service. Mis au point par Google en 2005, il s’est imposé comme un standard mondial.
Comme bien d’autres en France et dans le monde, le gestionnaire toulousain Tisséo propose en téléchargement un fichier rafraichi tous les jours, dont la carte ci-dessous restitue l’information purement géographique. Si vous zoomez sur ce composant cliquable (l’IGN propose un fort bel outil web intitulé « Ma carte »), vous verrez apparaître aussi les points d’arrêt.
J’ai construit cette carte interactive avec DuckDB à partir de ce fichier GTFS, gtfs_v2.zip (11 Mo), qui contient sous forme d’archive zippée une collection de fichiers CSV, disposés et structurés selon la norme :
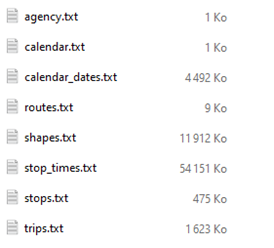
La table routes décrit en bon français des « lignes », de façon purement textuelle, par type (0 = tramway, 1 = métro, 3 = bus, 6 = téléphérique…) : un identifiant unique route_id se distingue du code usuel de la ligne (ex. : ligne A du métro).
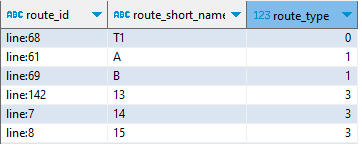
La table trips décrit des navettes. Par exemple le bus de la ligne 26 partant à 6 h 03, lundi 18 décembre 2023, de Montberon, terminus Borderouge correspond à une navette identifiée par un trip_id. Une navette a donc une caractéristique symbolique (la ligne), temporelle – horaire et jours – (elle ne circule pas forcément tous les jours à la même fréquence) et spatiale. Elle emprunte un itinéraire physique particulier définit par un shape_id.
La table shapes décrit ces itinéraires et c’est la première table véritablement géographique.
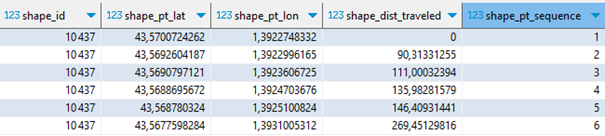
Chaque itinéraire se définit par une suite ordonnée de points GPS (latitude, longitude). Ces points ne correspondent pas aux arrêts, ils sont plus nombreux et définissent les changements d’orientation de l’itinéraire, afin de pouvoir le tracer précisément. Pour une même ligne, il y a généralement un itinéraire aller et un itinéraire retour, qui peuvent légèrement différer.
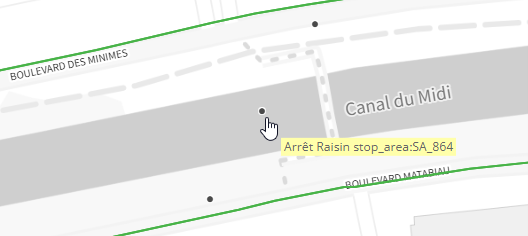
Les arrêts sont décrits dans la table stops, qui constitue la seconde table géographique. On distingue (via location_type) une zone d’arrêt globale des deux points physiques de l’arrêt, selon la direction désirée.

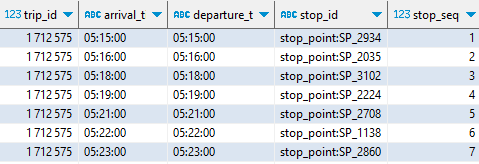
La table stop_times décrit chaque navette (identifiée par un trip_id) comme une suite d’arrêts situés spatialement et temporellement (stop_id, arrival_time…)
Voilà l’essentiel à retenir de ce riche format. Le site transit.land agrège les principales sources GTFS mondiales et en propose une élégante visualisation.
En avant avec DuckDB spatialVoyons comment la produire nous-même, avec DuckDB. Je l’utilise ici au sein de l’utilitaire gratuit DBeaver. DBeaver permet de gérer facilement ses scripts SQL (édition, sauvegarde) et de consulter de façon interactive (y compris cartographique) le résultat des requêtes adressées à DuckDB.
Note : depuis le 18 décembre 2023, l’extension SPATIAL de DuckDB est aussi utilisable dans le navigateur.
Chargeons d’abord les tables. Les fichiers du standard GTFS sont généralement mis à disposition sous forme d’une archive .zip. DuckDB ne sait pas lire directement un zip. Deux méthodes sont possibles :
1 – Télécharger et dézipper manuellement sur un disque local, puis, pour chaque table, écrire une instruction comme :
CREATE OR REPLACE TABLE routes AS FROM read_csv_auto('c:\...\routes.txt') ;2 – Utiliser un proxy capable de charger le zip et d’extraire à la volée la table désirée, le tout via une simple requête [https.] C’est possible avec un petit script PHP prenant comme paramètre le nom de la table à extraire et l’URL du zip :
https://icem7.fr/data/proxy_unzip.php?file=routes
&url=https://data.toulouse-metropole.fr/api/explore/v2.1/catalog/datasets/
tisseo-gtfs/files/fc1dda89077cf37e4f7521760e0ef4e9Utilisons une MACRO pour simplifier les écritures :
CREATE OR REPLACE MACRO get_gtfs(f, cache) AS 'https://icem7.fr/data/proxy_unzip.php?clear_cache=' || cache || '&file=' || f || '&url=https://data.toulouse-metropole.fr/api/explore/v2.1/catalog/datasets/ tisseo-gtfs/file/fc1dda89077cf37e4f7521760e0ef4e9';Le paramètre cache va indiquer au script de conserver le zip sur le serveur proxy le temps d’extraire successivement toutes les tables, ce qui prend 10 secondes.
-- 1er appel forçant le téléchargement du dernier gtfs CREATE OR REPLACE TABLE routes AS FROM read_csv_auto(get_gtfs('routes', 1)) ; CREATE OR REPLACE TABLE trips AS FROM read_csv_auto(get_gtfs('trips', 0)) ; CREATE OR REPLACE TABLE shapes AS FROM read_csv_auto(get_gtfs('shapes', 0)) ; CREATE OR REPLACE TABLE stops AS FROM read_csv_auto(get_gtfs('stops', 0)) ; CREATE OR REPLACE TABLE stop_times AS FROM read_csv_auto(get_gtfs('stop_times', 0)) ; CREATE OR REPLACE TABLE calendar_dates AS FROM read_csv_auto(get_gtfs('calendar_dates', FALSE), types=[VARCHAR,DATE,INT], dateformat='%Y%m%d') ;Pour cartographier le réseau, revenons donc à la table shapes :
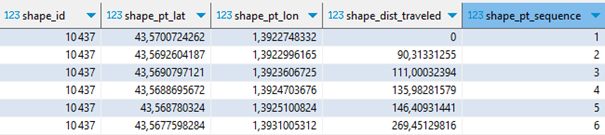
Pour la traduire dans un format spatial, les x lignes décrivant un shape_id particulier doivent être condensées en une seule entité spatiale de type LINESTRING. Autrement dit, la table shapes doit être regroupée par shape_id, chaque enregistrement décrira in fine un itinéraire complet.
Commençons par créer des entités géométriques de type POINT. Conventionnellement, une telle colonne est dénommée geometry :
LOAD spatial ; SELECT shape_id, shape_pt_sequence, ST_Point(shape_pt_lon,shape_pt_lat) AS geometry FROM shapes ;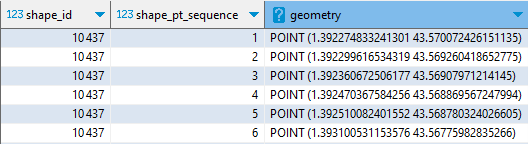
Rajoutons une agrégation pour rassembler tous les points d’un tracé (shape_id) en une seule ligne :
WITH shapes_pt_geo AS ( SELECT shape_id, shape_pt_sequence, ST_Point(shape_pt_lon,shape_pt_lat) AS geometry FROM shapes ORDER BY shape_id, shape_pt_sequence ) SELECT shape_id, ST_MakeLine(list(geometry)) AS geometry FROM shapes_pt_geo GROUP BY ALL ;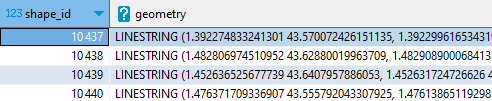
Je n’ai plus que 328 enregistrements (sur les 200 000 de la table shapes).
Et surtout, grâce à la petite manip expliquée ici, je peux visualiser chacun de ces itinéraires, directement dans DBeaver :
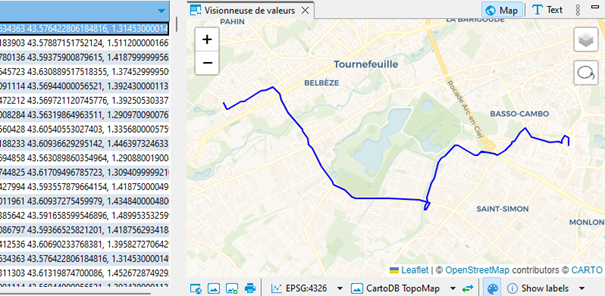
Pour obtenir une table agrémentée du nom des lignes, je vais devoir procéder à deux jointures, ce sont les charmes du format relationnel GTFS :
CREATE OR REPLACE TABLE reseau_gtfs_toulouse_met AS WITH shapes_pt_geo AS ( SELECT shape_id, shape_pt_sequence, shape_dist_traveled, ST_Point(shape_pt_lon,shape_pt_lat) AS geometry FROM shapes ORDER BY shape_id, shape_pt_sequence ), shapes_lines_geo AS ( SELECT shape_id, max(shape_dist_traveled)::int AS shape_length, ST_MakeLine(list(geometry)) AS geometry FROM shapes_pt_geo GROUP BY ALL ) SELECT r.route_id,r.route_short_name,r.route_long_name,r.route_type, s.shape_id,s.shape_length,s.geometry FROM shapes_lines_geo s LEFT JOIN (SELECT DISTINCT route_id, shape_id FROM trips) t ON s.shape_id = t.shape_id LEFT JOIN routes r ON r.route_id = t.route_id ORDER BY r.route_type, r.route_id ;Et voici dans cet aperçu les deux lignes de métro (A et B), sens aller et retour, deux lignes de bus :
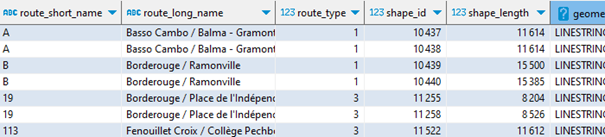
Il ne me reste plus qu’à exporter en GeoJSON pour l’exploiter à ma guise dans une autre application, comme le bien pratique outil web IGN Ma carte.
COPY reseau_gtfs_toulouse_met TO 'C:/…/reseau_gtfs_toulouse_met.json' WITH (FORMAT GDAL, DRIVER 'GeoJSON');J’ai procédé de la même manière avec la table des arrêts, que vous pourrez voir apparaitre en zoomant suffisamment sur la carte.
Simplicité des calculs géométriquesÀ partir d’un tel fonds de carte et des informations associées, on peut calculer la longueur de chaque itinéraire, le temps de parcours, et donc la vitesse moyenne, pour déterminer les lignes les plus longues, les plus rapides, etc.
Pour chaque shape, nous pouvions lire dans la table shapes d’origine la distance totale parcourue, renseignée par Tisséo. Mais il est possible de la calculer à partir de sa géométrie.
Au préalable, pour obtenir une distance en mètres, il convient de projeter à la volée chaque géométrie vers un référentiel métrique, autrement dit de passer du référentiel « GPS » en longitude/latitude (codé conventionnellement EPSG:4326) au référentiel français Lambert 93 (codé EPSG:2154) :
SELECT route_short_name, route_long_name, shape_length, ST_length(ST_Transform(geometry,'EPSG:4326','EPSG:2154', true))::int AS shape_length_calc FROM reseau_gtfs_toulouse_met ORDER BY shape_length DESC ;
Comme on peut le constater, le calcul géométrique est très proche, à quelques mètres près, de l’information fournie par Tisséo.
Pour éviter l’empilement des parenthèses, je préfère la syntaxe alternative suivante, plus lisible, inspirée de la programmation fonctionnelle, que DuckDB implémente également :
Quels sont les arrêts Tisséo les plus proches de chez moi ?SELECT route_short_name, route_long_name, shape_length, geometry.ST_Transform('EPSG:4326','EPSG:2154', true) .ST_Length()::int AS shape_length_calc FROM reseau_gtfs_toulouse_met ORDER BY shape_length DESC ;Autre approche spatiale, et pratique : quels sont les arrêts Tisséo les plus proches de chez moi, et quand sont les prochains départs, et pour où ?
Voici d’abord chez moi :
SELECT ST_Point(1.46158, 43.69875) AS home_location ;
Les arrêts proches de mon domicile (à moins de 700 mètres) se déterminent ainsi :
CREATE OR REPLACE VIEW arrets_proches AS SELECT ST_Point(stop_lon, stop_lat) AS geometry, ST_Distance( ST_Point(stop_lon, stop_lat).ST_Transform('EPSG:4326','EPSG:2154', true), ST_Point(1.46158, 43.69875).ST_Transform('EPSG:4326','EPSG:2154', true) )::int AS distance_home, stop_id, stop_name FROM stops WHERE distance_home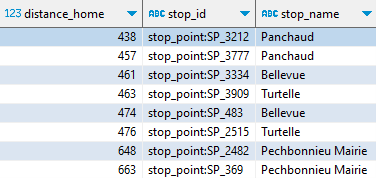
Rappelez-vous, il y a généralement deux arrêts dans la même zone, selon la direction du bus.
Pour faire le lien avec les horaires, le nom de la ligne, et s’en tenir aux horaires valides aujourd’hui à partir de maintenant, engageons une série de jointures et de filtres adaptés (vous n’êtes pas obligés de tout analyser, sauf si vous êtes passionnés par GTFS) :
SELECT route_short_name, route_long_name, stop_name, arrival_time, trip_headsign, distance_home, trips.trip_id FROM arrets_proches JOIN stop_times ON arrets_proches.stop_id = stop_times.stop_id JOIN trips ON stop_times.trip_id = trips.trip_id JOIN calendar_dates ON trips.service_id = calendar_dates.service_id JOIN routes ON routes.route_id = trips.route_id WHERE arrival_time > localtime AND calendar_dates.date = current_date ORDER BY arrival_time, distance_home ;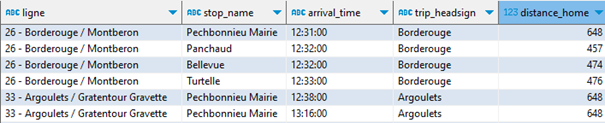
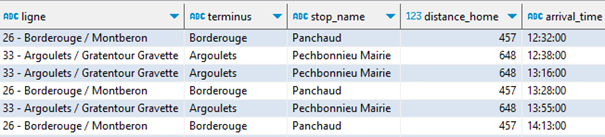
Il reste que la ligne 26 propose plusieurs arrêts près de chez moi ; je souhaite ne retenir que le plus proche.
Il suffira d’un QUALIFY avec une « window function » pour nettoyer le résultat :
WITH trips_proches AS ( SELECT route_short_name || ' - ' || route_long_name AS ligne, trip_headsign AS terminus, stop_name, distance_home, arrival_time, trips.trip_id, geometry FROM arrets_proches JOIN stop_times ON arrets_proches.stop_id = stop_times.stop_id JOIN trips ON stop_times.trip_id = trips.trip_id JOIN calendar_dates ON trips.service_id = calendar_dates.service_id JOIN routes ON routes.route_id = trips.route_id WHERE arrival_time > localtime AND calendar_dates.date = current_date ) SELECT * EXCLUDE(trip_id), FROM trips_proches WHERE terminus IN ('Borderouge', 'Argoulets') QUALIFY rank() over(PARTITION BY trip_id ORDER BY distance_home) = 1 ORDER BY arrival_time, distance_home ;Et le plus drôle, c’est que ma fille vient de passer me voir et se demandait quand était le prochain bus pour Argoulets. Elle n’en est pas revenue que je lui montre la réponse dans cette étrange interface ! Son appli Tisséo marche très bien aussi…
Note : vous pouvez déclencher une requête SQL GTFS via une simple URL.
B – Base adresse nationale (BAN), filaire de voies et GeoParquetMon second cas d’étude porte sur des fichiers bien plus volumineux, et me permet d’introduire le format GeoParquet.
Mon précédent logement se trouvait dans une rue limitrophe des communes de Toulouse et de Launaguet. L’état déplorable de la voie s’expliquait, disait-on, par son statut hybride, aucune des deux communes ne voulant s’en occuper à la place de l’autre.
À l’époque, j’aurais pu vouloir rameuter tous les ménages concernés, habitant le long de cette voie limitrophe, ou à proximité immédiate, pour tancer les autorités (mais c’est juste une fable que j’élabore pour l’occasion).
Comment donc compter tous ces voisins ?
Cette voie s’appelle Chemin des Izards, dont une large portion sud commence dans Toulouse, et une autre délimite Toulouse (à gauche) et Launaguet (à droite).
À partir du filaire de voies de Toulouse métropole, je vais récupérer l’ensemble du tracé de la voie. Plutôt que lire un GeoJSON de 20 Mo, j’utilise la version GeoParquet du filaire, que j’ai ainsi réduite à 3 Mo. Comme d’habitude, je lis directement les données sur le web, ici sur data.gouv :
CREATE OR REPLACE TABLE troncons_izards_ as SELECT code_insee, street, fromleft, fromright, ST_GeomFromWKB(geometry) AS geometry FROM 'https://static.data.gouv.fr/resources/filaire-voiries-toulouse-metropole-format-geoparquet/20231219-050942/filaire-de-voirie-toulouse-met-geo.parquet' WHERE motdir LIKE 'IZARDS%' ORDER BY fromleft, fromright ;
Grace à la lecture ciblée du fichier, les seuls « row-groups » du fichier parquet qui contiennent les données seront chargés et scannés. Ainsi, 1 Mo seulement a transité par le réseau. Ceci est possible parce que j’ai constitué le fichier GeoParquet en le triant sur code_insee et motdir, champs de recherche les plus naturels.
Notez que le champ de géométrie d’un fichier GeoParquet est, selon cette spécification, encodé dans un format spécifique (le WKB). Pour le ramener au format géométrique de DuckDB spatial, il suffit de lui appliquer un ST_GeomFromWKB().
Pour isoler la partie du chemin des Izards qui est limitrophe de Toulouse et Launaguet, je cherche à identifier des doublons. En effet, ces tronçons limitrophes sont décrits deux fois dans le fichier, pour chaque commune qui gère son côté de voie.
CREATE OR REPLACE TABLE frontiere_izards AS SELECT DISTINCT a.geometry,a.fromleft,a.fromright FROM izards_troncons a CROSS JOIN izards_troncons b WHERE ST_Equals(a.geometry, b.geometry) AND a.code_insee b.code_insee ORDER BY a.fromleft, a.fromright ;Vérifions visuellement dans DBeaver : je retrouve bien la partie nord du chemin des Izards, celle qui sépare Toulouse et Launaguet :
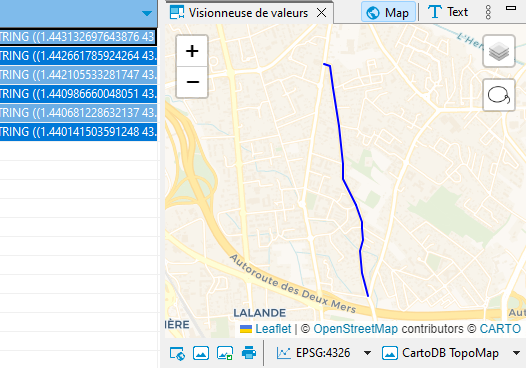
Ma deuxième entreprise consiste à élaborer un tampon de 100 mètres autour de cette voie.
Pour ce faire, je projette en coordonnées métriques avant de calculer le « buffer » :
CREATE OR REPLACE TABLE buffer_izards AS SELECT ST_Union_Agg(geometry) .ST_Transform('EPSG:4326','EPSG:2154',true) .ST_Buffer(100) -- buffer de 100 mètres .ST_Transform('EPSG:2154','EPSG:4326',true) AS geom, quadkey_min_geo(geom) AS quadkey FROM frontiere_izards ;Vérifions l’allure de ce tampon, cela semble assez correct :
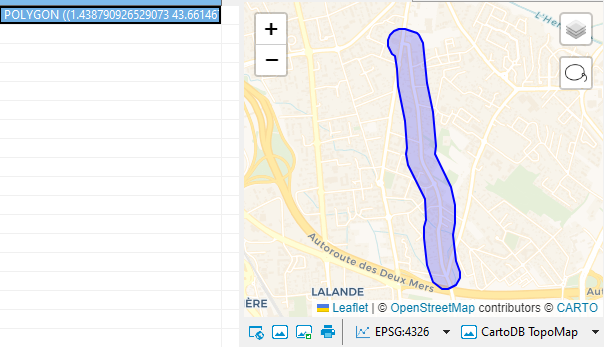 Indexation spatiale avec une quadkey
Indexation spatiale avec une quadkey
La dernière requête inclut le calcul d’une nouvelle information quadkey, qu’on appelle un index spatial. Ce quadkey suit le modèle de Microsoft avec Bing : la terre est découpée en une pyramide de quadrillages. On peut aller jusqu’au niveau 12 par exemple, et affecter à chaque petit carreau de ce niveau un code à 12 chiffres.
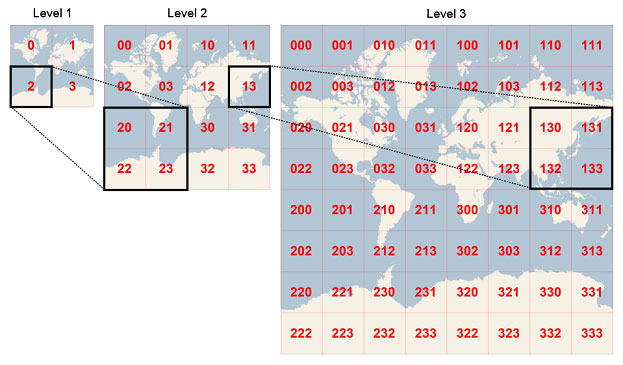 Bing Maps Tile System
Bing Maps Tile System
Ainsi, quand on travaille sur une zone géographique particulière, il est pratique de connaitre le quadkey du carreau qui l’englobe (à un niveau <=12). Cela servira à filtrer d’autres couches, comme la base d’adresses nationale que l’on va découvrir, si elle intègre elle aussi une colonne de quadkey.
La fonction ST_QuadKey() vient d’apparaitre dans la branche de dev de DuckDB spatial, elle sera disponible prochainement en version 0.9.3. Si vous voulez la tester, il suffit de l’installer de la façon suivante, dans le client DuckDB ou même dans la version web :
FORCE INSTALL spatial FROM 'http://nightly-extensions.duckdb.org' ;ST_Quadkey() calcule le quadkey d’un point géométrique.
Le concepteur de l’extension DuckDB spatial prévoit même une fonction de calcul du quadkey du carreau le plus petit englobant une entité géographique quelconque (ligne, polygone).
Je la préfigure par cette macro :
CREATE OR REPLACE MACRO quadkey_min_geo(geom) AS ( WITH t1 AS ( SELECT unnest(split(ST_Quadkey(ST_XMin(geom), ST_YMin(geom),12),'')) AS a, unnest(split(ST_Quadkey(ST_XMin(geom), ST_YMax(geom),12),'')) AS b, unnest(split(ST_Quadkey(ST_XMax(geom), ST_YMin(geom),12),'')) AS c, unnest(split(ST_Quadkey(ST_XMax(geom), ST_YMax(geom),12),'')) AS d ) SELECT string_agg(a,'') AS quadkey FROM t1 WHERE a = b AND b = c AND c = d ) ;Ainsi, le quadkey calculé de notre tampon de 100 m autour du Chemin des Izards est :
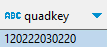
Examinons maintenant la base adresse nationale (BAN), je l’ai constituée au format GeoParquet à partir du csv.gz national, en l’enrichissant, pour chaque point adresse (et il y en a 26 millions), du quadkey correspondant. En voici un aperçu, sur un territoire mieux reconnaissable que la banlieue toulousaine :
 BAN en GeoParquet dans QGIS, Finistère nord - coloration par quadkey niveau 12
BAN en GeoParquet dans QGIS, Finistère nord - coloration par quadkey niveau 12
Ainsi, la requête filtrée suivante ne charge que 6 Mo de données sur les 600 Mo du fichier parquet national – c’est tout l’intérêt de ce quadkey :
SELECT geometry FROM 'https://static.data.gouv.fr/resources/ban-format-parquet/20231228-103716/adresses-france-2023.parquet' WHERE quadkey LIKE '120222030220%' ;Et je vais maintenant préciser ma demande avec un autre filtre spatial : que les adresses soient dans le « buffer Izards » :
SELECT ST_GeomFromWKB(geometry) AS geom FROM 'https://static.data.gouv.fr/resources/ban-format-parquet/20231228-103716/adresses-france-2023.parquet' a JOIN buffer_izards b ON ST_Within(ST_GeomFromWKB(geometry), b.geom) WHERE a.quadkey LIKE '120222030220%' ; -- 1 sL’exécution ne prend ici qu’une seconde. C’est tout bonnement ahurissant.
Un opérateur de comparaison spatiale comme ST_Within() est coûteux, et s’il fallait le jouer sur les 26 millions d’adresses de la BAN, ce serait monstrueusement long. Restreindre le champ de cette comparaison aux seules adresses du carreau/quadkey pertinent nous fait gagner un temps fou.
Cela va vite aussi parce que j’ai recopié manuellement le quadkey du buffer. Une manière plus dynamique d’écrire cette requête serait :
SELECT ST_GeomFromWKB(geometry) AS geom FROM 'https://static.data.gouv.fr/resources/ban-format-parquet/20231228-103716/adresses-france-2023.parquet' a JOIN buffer_izards b ON ST_Within(ST_GeomFromWKB(geometry), b.geom) WHERE a.quadkey LIKE (b.quadkey || '%') ; -- 10 sCette version prend désormais 10 secondes, ce qui reste peu, mais je trouve anormal qu’elle soit bien plus longue que la précédente. J’ai signalé ce cas concret à l’équipe DuckDB et ne doute pas qu’elle saura remettre la vélocité nécessaire ici !
J’obtiens surtout 153 adresses de ménages qui auraient ainsi pu se mobiliser pour réclamer que la voie soit refaite.
Mais certains ont bien dû le faire, car la route a été aménagée à neuf depuis peu, agrémentée comme il se doit de moult chicanes et ralentisseurs…
Pour visualiser ensemble ces adresses, le buffer, la portion limitrophe du chemin et les limites de Toulouse et Launaguet, tentons enfin de réunir ces différentes couches dans une seule table :
SELECT ST_union_agg(geometry) AS geometry FROM frontiere_izards UNION SELECT geom FROM buffer_izards UNION (SELECT ST_GeomFromWKB(geometry) AS geom FROM 'https://static.data.gouv.fr/resources/ban-format-parquet/20231228-103716/adresses-france-2023.parquet' a JOIN buffer_izards b ON ST_Within(ST_GeomFromWKB(geometry), b.geom) WHERE a.quadkey LIKE '120222030220%') UNION SELECT ST_ExteriorRing(geom) FROM st_read('https://geo.api.gouv.fr/communes?code=31555&format=geojson&geometry=contour') UNION SELECT ST_ExteriorRing(geom) FROM st_read('https://geo.api.gouv.fr/communes?code=31282&format=geojson&geometry=contour') ;J’ai mobilisé au passage une API web, l’API Géo, pour récupérer le contour des deux communes. Ainsi, cette ultime requête mobilise ensemble des sources web indépendantes : la BAN (GeoParquet), le filaire de Toulouse métropole (GeoParquet), et l’API Géo (GeoJSON).
Et voici le résultat directement affiché dans DBeaver !
 153 adresses à proximité du tronçon limitrophe du Chemin des Izards
Le format GeoParquet
153 adresses à proximité du tronçon limitrophe du Chemin des Izards
Le format GeoParquet
Ce format nait d’une initiative communautaire, désireuse d’utiliser Parquet pour encoder des fichiers géographiques. Parvenu en 2023 à sa version 1.0, GeoParquet est lu par le logiciel libre QGiS, qui permet donc de le visualiser, et supporté par des éditeurs majeurs (Esri, Carto, FME, Microsoft…)
Depuis août 2023, un groupe de travail au sein de l’OGC est chargé d’en affiner encore la spécification pour l’asseoir définitivement comme un standard géographique mondial. L’IGN anglais, l’Ordnance Survey, utilise déjà GeoParquet.
Un fichier GeoParquet est un fichier Parquet qui comprend des métadonnées géographiques spécifiques et encode la géométrie, officiellement au format WKB, mais aussi possiblement au format Arrow. Le format GeoArrow est donc un GeoParquet dans lequel la colonne de géométrie, au lieu du classique WKB, utilise une structure bien plus rapide à charger en mémoire, sans décodage.
D’une façon générale, le format GeoParquet est bien plus compact que ses alternatives. Comme tout fichier Parquet, on peut le lire (avec DuckDB par exemple) de façon sélective sur le web avec des « range requests », ce qui permet de requêter directement en [https] sans avoir à télécharger le fichier complet en local.
Il existe de multiples façons de convertir en GeoParquet un fichier géographique classique de type GeoJSON, shp, gpkg ou autres, par exemple :
- OGR/GDAL,
- librairies GeoPandas (Python), geoarrow (R),
- utilitaire gpq.
J’utilise plutôt ce dernier car, comme DuckDB, c’est un petit exécutable (30 Mo), sans dépendance. DuckDB ne sait pas – encore, mais ça va venir – exporter en GeoParquet. Mais il peut exporter un fichier géographique en Parquet standard, gpq venant ensuite le transformer en GeoParquet.
Ainsi, pour convertir la base adresse nationale (BAN) en GeoParquet, je commence dans DuckDB par un export Parquet :
COPY ( WITH ban AS ( SELECT *, ST_AsWKB(ST_point(lon, lat)) AS geometry, ST_QuadKey(ST_point(lon, lat), 12) AS quadkey FROM 'c:\...\adresses-france.csv.gz' ) SELECT * EXCLUDE(lon,lat,x,y) FROM ban ORDER BY quadkey ) TO 'c:\...\adresses-france.parquet' ;Notez qu’une fois le champ de géométrie créé (obligatoirement en WKB), je n’ai plus besoin des colonnes redondantes lon, lat, x et y. Par ailleurs, je rajoute une colonne quadkey et, je trie sur cette colonne – très important – pour donner à cet indexation spatiale toute son efficacité.
Puis, en ligne de commande, je passe de Parquet à GeoParquet :
gpq convert c:\...\adresses-france.parquet c:\...\adresses-france-geo.parquet
--from=parquet --to=geoparquet --compression=zstdJe peux aussi préciser un –row-group-length= pour ajuster la taille des row-groups dans le fichier, paramètre important pour accélérer les requêtes [https] : je dois avoir suffisamment de row-groups (une dizaine typiquement) pour que lire le ou les row-groups qui contiennent les données que je recherche soit efficace, fasse économiser beaucoup de bande passante.
adresses-france-geo.parquet est un peu plus léger (600 Mo) que le csv.gz téléchargeable (700 Mo). Et surtout, il est directement requêtable en [https,] avec une extraordinaire efficacité pour ses 26 millions d’adresses.
Conclusion de cette série de trois articles sur DuckDB et ses bluffantes potentialitésDuckDB, Parquet et GeoParquet nous font entrer dans un nouvel univers, qui dépasse le classique modèle client / « serveur spécialisé de base de données », ou client / API web.
À la place des boites noires sur serveur, qui implémentent en silo des API et des requêtes, le web entier devient une base de données généraliste, et c’est l’ordinateur de l’utilisateur qui fait le travail de requêtage, capable de charger sélectivement et sans enrobage inutile des flux de données brutes directement utilisables en mémoire.
Peu de personnes encore ont saisi toutes les implications de cette mutation. Voici quelques avantages très concrets :
- Économiser en gestion des données et d’accès concurrents sur les serveurs de mise à disposition : il suffit de déposer des fichiers et de laisser la magie du protocole [https] et des systèmes de cache opérer.
- Éviter à l’usager de télécharger des fichiers en local, de les dézipper, à chaque fois qu’il veut accéder aux données les plus fraiches.
- Dépasser la syntaxe obscure et variable des API web et surtout leurs limitations : formats de sortie verbeux, identification nécessaire parfois, limite en volume ou en nombre d’appels, lenteur souvent, pannes à l’occasion.
- Pouvoir dans la même requête interroger simultanément plusieurs sources de données sur le web, faire les jointures nécessaires à la volée.
- N’utiliser, côté utilisateur, que deux ou trois logiciels très simples, légers, rapides à charger, gratuits (le navigateur, év. un exécutable DuckDB indépendant si l’on utilise pas DuckDB dans le navigateur, DBeaver pour la productivité) et surtout un seul langage, le standard parmi les standards, SQL, flexible et intuitif.
- Accéder avec une vitesse incroyable à des fichiers plus volumineux, même avec une mémoire limitée.
Au-delà de la technique, j’ai voulu dans ces trois articles vous faire (re)découvrir la belle richesse des sources de données open data en France, en élaborant des cas d’usage les plus concrets et reproductibles possibles.
J’espère enfin que les gestionnaires de ces bases open data et des API liées sauront saisir les avantages, pour l’utilisateur, à proposer en complément de leur dispositif actuel des bases au format (geo)parquet.
Pour en savoir plus- Meetup DuckDB Toulouse Dataviz, janvier 2024
- 3 explorations bluffantes avec DuckDB – Interroger des fichiers distants (1/3), icem7, 2023
- 3 explorations bluffantes avec DuckDB – Butiner des API JSON (2/3), icem7, 2023
- DuckDB – Spatial Extension
- DuckDB Spatial Extension – Documentation
- PostGEESE? Introducing The DuckDB Spatial Extension
- DuckDB: The indispensable geospatial tool you didn’t know you were missing – Chris Holmes, 2023
- Data Science is Getting Ducky, Paul Ramsey, 2023
- Two Tier Architectures are Anachronistic, Hannes Mühleisen, 2023
- Bing Maps Tile System
- GeoParquet – Github
- OGC forms new GeoParquet Standards Working Group, 2023
- Explorer la cartographie des réseaux de transports publics avec des données GTFS – Carto numérique, 2022
- Formation DuckDB, icem7
L’article 3 explorations bluffantes avec DuckDB – Croiser les requêtes spatiales (3/3) est apparu en premier sur Icem7.
-
sur 3 explorations bluffantes avec DuckDB – Butiner des API JSON (2/3)
Publié: 28 November 2023, 1:54pm CET par Éric Mauvière
DuckDB saurait-il rivaliser avec JavaScript pour exploiter des données JSON ? Ce n’est pas le terrain sur lequel j’attendais ce moteur SQL. Quelle ne fut pas ma surprise, pourtant, de le voir se jouer des imbrications les plus retorses, des modèles de données les plus échevelés, auxquels JSON accorde volontiers son flexible habillage.
Après le premier épisode consacré aux formats Parquet et CSV dans DuckDB, voici donc à nouveau deux exemples concrets de jeux avec des données formattées en JSON.
 A - API recherche d'entreprises : celles autour de chez moi, quelles sont-elles ?
A - API recherche d'entreprises : celles autour de chez moi, quelles sont-elles ?
C’est en explorant les belles ressources du portail api.gouv.fr que l’idée de cet article a pris forme. De multiples API de données sont désormais proposées de façon ouverte, sans identification : professionnels bio (Agence bio), base adresses (BAN), demandes de valeurs foncières (DVF), annuaire de l’Éducation nationale, annuaire des entreprises…
Je me suis arrêté sur cette dernière source, interrogeable par une API très simple, construite par la Dinum.
Vous pouvez lui poser deux questions :
• quelles infos peux-tu me donner sur une entreprise ? Ex. : icem7, et si je tape icem77 j’aurai tout de même la bonne réponse ;
• quelles sont les entreprises autour d’un point GPS ?Alors, j’ai voulu regarder les entreprises près de chez moi. Les bureaux d’icem7 jouxtent mon domicile, j’ai donc bien retrouvé ma société et constaté que nous étions cernés par les sociétés civiles immobilières – le quartier est, il est vrai, plutôt résidentiel.
Voyons gentiment comment arriver à un tel résultat, avec DuckDB et un outil web simple.
L’URL suivante construite d’après la doc prend comme paramètres un point GPS (longitude et latitude) et un rayon (en km) ; j’ai choisi 300 m, le rayon maximum est de 50 km.
https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3
Dans un navigateur (ici Chrome), vous pouvez facilement consulter la réponse dans un affichage confortable et flexible. Quelques données numériques encadrent un « array » JavaScript de results, avec ici 10 entreprises (sur 89 annoncées, dans total_results).
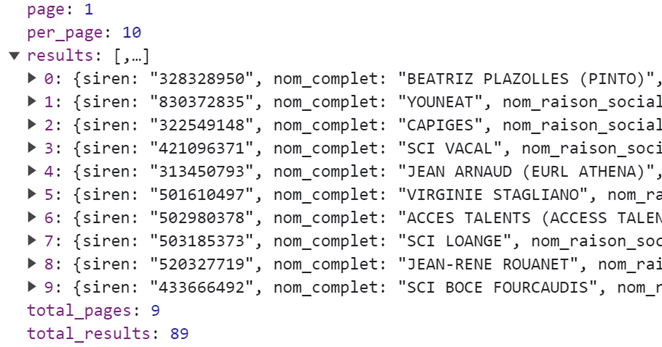
Si je déplie le premier résultat (d’indice 0), se révèle une structure hiérarchique, avec bon nombre de rubriques :
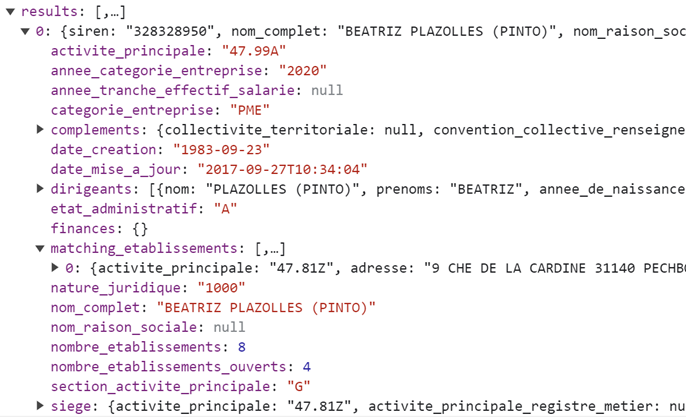
On devine déjà l’intérêt de cette API, pour laquelle la Dinum collationne en temps réel de multiples sources de données : immatriculation et statut juridique, certifications, résultats financiers, siège et établissements. Les entreprises listées ici ont au moins un établissement dans le rayon de ma requête (matching_etablissements).
Que sait lire DuckDB ? Je vais l’utiliser ici dans sa version la plus dépouillée et la plus rapide, l’exécutable de 20 Mo, qui présente les résultats de façon toujours lisible, quelle que soit la largeur de votre écran.
FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3');
Cette simple requête constitue un tableau d’une seule ligne, dont la première colonne reprend results, c’est-à-dire un array (ou liste) de données structurées. Là où JavaScript parle d’array et d’objets, DuckDB évoquera des listes et des structures. Le format Parquet a aussi cette capacité d’accueillir de telles colonnes complexes.
Comment déplier ce tableau en autant de lignes que d’entreprises ?
Découvrons le pouvoir magique (et proprement bluffant, oui) de la fonction unnest() :
SELECT unnest(results, recursive := true) FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3');
Avec le paramètre recursive := true, unnest() va continuer à déplier les structures cachées dans les colonnes de chaque « result », si bien que le tableau ci-dessus contient désormais 10 lignes et 78 colonnes, autant de pépites d’information sur chaque entreprise.
Affichons-en quelques-unes en clair ; je vais réduire mon champ géographique à 10 m autour de chez moi :
SELECT unnest(results, recursive := true) FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.01');
Et en effet, je retrouve bien icem7, et même ma précédente entreprise, dont icem7 a pris la suite. Emc3 n’existe plus à cette adresse, l’API renvoie, je le découvre, des entreprises dont le statut administratif a pu évoluer.
Je vais donc affiner mes requêtes ultérieures en demandant à voir, près de chez moi, les seuls établissements actifs :
FROM ( SELECT unnest(results, recursive := true) FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.01') ) WHERE list_filter(matching_etablissements, d -> d. etat_administratif = 'A').len() >= 1 ;Avec list_filter(), je vous laisse goûter à l’une des nombreuses fonctions de manipulations de listes, qui donnent à DuckDB toute facilité pour explorer des structures imbriquées à la JSON.
Il reste plusieurs colonnes de type liste que unnest() n’a opportunément pas dépliées, car cela aurait encore multiplié le nombre de lignes.
Déplions manuellement la colonne dirigeants, ce qui fait apparaitre une sous-table, où je me reconnais avec mon associée. On y trouve des infos étonnamment personnelles comme l’identité, la nationalité et même la date de naissance (que je ne dévoile pas ici, par galanterie) !
WITH tb1 AS ( SELECT unnest(results, recursive := true) FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.01') ) SELECT unnest(dirigeants, recursive := true) FROM tb1 WHERE list_filter(matching_etablissements, d -> d. etat_administratif = 'A').len() >= 1 ;
Sur les 78 colonnes de la table dépliée, je vais donc choisir quelques infos parmi les plus parlantes, afin de localiser ces entreprises et d’en savoir plus sur ce qu’elles font et qui les dirige. Je peux identifier des certifiés « bio » (producteurs ou revendeurs / préparateurs), des organismes de formation, par exemple ceux certifiés Qualiopi comme icem7.
Par commodité, je m’en tiens au seul premier établissement près de chez moi d’une même entreprise. DuckDB utilise des indices qui commencent par 1 (et non 0 comme dans JavaScript).
SELECT siret, nom_complet, activite_principale, dirigeants, matching_etablissements[1].longitude::float AS lon, matching_etablissements[1].latitude::float AS lat, est_qualiopi FROM ( SELECT unnest(results, recursive := true) FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3') ) WHERE list_filter(matching_etablissements, d -> d. etat_administratif = 'A').len() >= 1 ;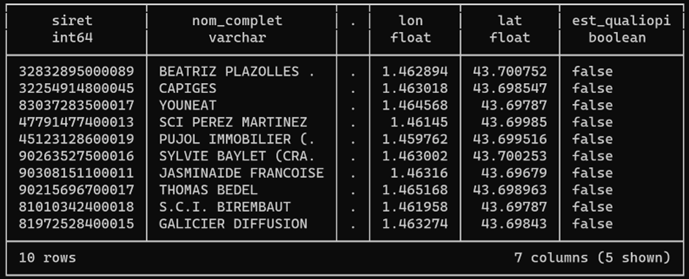
Avec ce premier résultat, je pourrais déjà cartographier ces entreprises et produire une analyse coloriée par code activité (NAF).
Dépasser les contraintes de l'APIBien sûr, le problème est que je n’ai reçu d’infos que sur 10 entreprises. Voyons comment relever le curseur. La doc de l’API indique que je peux pousser jusqu’à 25 entreprises par appel, et lancer 7 appels par seconde.
Pour avoir les 89 établissements à 300 m de chez moi, je m’attends donc à m’y reprendre à plusieurs fois.
SELECT total_results, total_pages FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25');
Avec le paramètre per_page=25, l’API me renvoie désormais une première « page » de 25 résultats, et me précise le nombre de pages nécessaires (4). Pour avoir la page 2, je dois ajouter à l’URL un paramètre &page=2.
DuckDB permet commodément de charger dans le même mouvement toute une collection d’URL :
SELECT unnest(results, recursive := true) FROM read_json_auto([ 'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25', 'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=2', 'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=3', 'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=4' ]) ;Mais une telle écriture reste bien lourde. Il y a plus élégant, plus « vectoriel » :
SELECT unnest(results, recursive := true) FROM read_json_auto( list_transform(generate_series(1, 4), n -> 'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=' || n) ) ;generate_series(1, 4) produit un vecteur [1,2,3,4], lequel se voit transformer avec list_transform() en un vecteur d’URL.
Je suis donc en mesure de récupérer en une seule requête tous mes voisins entrepreneurs, et pour ne pas solliciter l’API à chaque raffinement de mes écritures, je vais stocker ce premier résultat dans une table.
CREATE OR replace TABLE etab_proches_icem7 AS FROM ( SELECT unnest(results, recursive := true) FROM read_json_auto( list_transform( generate_series(1, 4), n -> 'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=' || n) ) ) WHERE list_filter(matching_etablissements, d -> d. etat_administratif = 'A').len() >= 1 ;Voici un aperçu de cette table de 89 établissements, liste que j’ai triée pour montrer en premier les organismes de formation certifiés Qualiopi ; icem7 apparait bien.
SELECT nom_complet, activite_principale, matching_etablissements[1].longitude::float AS lon, matching_etablissements[1].latitude::float AS lat, est_organisme_formation, est_qualiopi FROM etab_proches_icem7 ORDER BY est_organisme_formation DESC, nom_complet ;
Désormais, je peux cartographier ce résultat à partir d’un export GeoJSON de cette table :
LOAD SPATIAL ; COPY ( SELECT nom_complet, activite_principale, ST_Point(matching_etablissements[1].longitude::float, matching_etablissements[1].latitude::float) AS geometry FROM etab_proches_icem7 ) TO 'C:/.../entr_proches_icem7.json' WITH (FORMAT GDAL, DRIVER 'GeoJSON') ;L’export GeoJSON repose sur l’extension SPATIAL, que je charge au préalable (cette procédure devrait prochainement se simplifier dans DuckDB, avec un chargement automatique déclenché dès l’appel d’une fonction spatiale).
La table doit ensuite comprendre une colonne de géométrie (nommée obligatoirement geometry), ici une colonne ponctuelle générée avec la fonction ST_Point().
Je fais glisser le fichier ainsi créé dans l’interface de geojson.io pour découvrir – enfin – cette carte des entreprises près de chez moi – et elles sont nombreuses !
 Joindre une nomenclature
Joindre une nomenclature
Le code activité principale, issu de la NAF, me parle peu, je vais donc chercher des libellés clairs.
Grâce à SQL, le pouvoir des jointures, et la capacité de DuckDB à piocher directement sur le web, je récupère, par une table de passage constituée par mes soins au format parquet, les différents niveaux d’agrégation de la NAF et leurs dénominations.
SELECT nom_complet, activite_principale, ST_Point(matching_etablissements[1].longitude::float, matching_etablissements[1].latitude::float) AS geometry, n.LIB_NIV5,n.LIB_NIV1 FROM etab_proches_icem7 LEFT JOIN 'https://static.data.gouv.fr/resources/naf-1/20231123-121750/nafr2.parquet' n ON etab_proches_icem7.activite_principale = n.NIV5 ;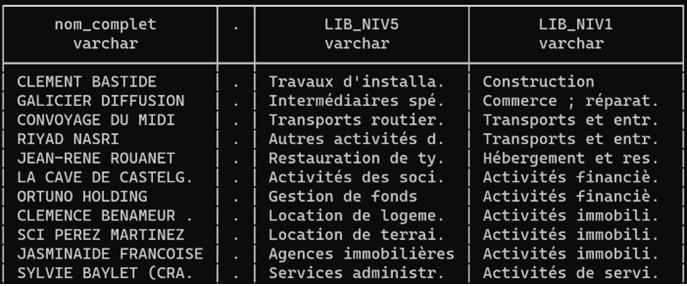 Cartographier selon l'activité principale
Cartographier selon l'activité principale
Pour produire une cartographie plus analytique, avec des punaises coloriées selon l’activité, j’utilise le service MyMaps de Google, seul outil en ligne que j’aie pu identifier pour ce faire et afficher en arrière-plan une couche de rues.
Maps ne lit pas de GeoJSON mais accepte le CSV, pourvu qu’on y insère les deux colonnes longitude et latitude (nommées comme on veut).
COPY ( SELECT nom_complet, activite_principale, matching_etablissements[1].longitude AS lon, matching_etablissements[1].latitude AS lat, n.LIB_NIV5,n.LIB_NIV1 FROM etab_proches_icem7 LEFT JOIN 'https://static.data.gouv.fr/resources/naf-1/20231123-121750/nafr2.parquet' n ON etab_proches_icem7.activite_principale = n.NIV5 ) TO 'C:/.../etab_proches_icem7.csv' ;Comme il me reste, même au niveau le plus agrégé de la NAF, beaucoup de modalités différentes, je termine en créant un code activité simplifié, avec une catégorie « Autres » regroupant les effectifs les plus faibles :
COPY ( WITH tb1 AS ( SELECT nom_complet, activite_principale, matching_etablissements[1].longitude AS lon, matching_etablissements[1].latitude AS lat, n.LIB_NIV5,n.LIB_NIV1, count(*) OVER (PARTITION BY LIB_NIV1) AS eft_naf FROM etab_proches_icem7 LEFT JOIN 'https://static.data.gouv.fr/resources/naf-1/20231123-121750/nafr2.parquet' n ON etab_proches_icem7.activite_principale = n.NIV5 ) SELECT CASE WHEN eft_naf >= 3 THEN LIB_NIV1 ELSE 'Autres' END AS activite, * FROM tb1 ) TO 'C:/.../etab_proches_icem7.csv' ;Et voici une carte interactive, dont vous pouvez déplier la légende (bouton en haut à gauche) ou cliquer les punaises :
B - DataTourisme et le hackaviz DataGrandEstMon second exemple sera plus concis, et il a surtout servi à résoudre un problème concret. Mon collègue Alain Roan, qui prépare le Hackaviz du 13 décembre 2023 de DataGrandEst, s’est déclaré lui-même proprement « bluffé » par l’agilité de DuckDB.
Le concours s’appuie sur des données touristiques ; il s’agit de mettre en regard des nuitées et des points d’intérêt (POI) touristiques, c’est-à-dire de tenter d’expliquer la venue des touristes par l’existence de ressources attractives : monuments, spectacles, itinéraires, etc.
Alain et l’agence régionale du tourisme voulaient constituer un fichier de POI avec une double localisation longitude/latitude et code commune Insee. Selon les sources, ils disposaient soit de l’un, soit de l’autre, mais pas des deux.
Ils le savaient, la réponse se trouve dans le portail DataTourisme. Il s’agit d’une superbe initiative, formalisée en 2017, rassemblant en temps réel toutes les sources de données disponibles. Toutefois, son « API web moderne » évoque plutôt les années 1980, époque regrettée des programmes lancés « en batch » sur « grosse machine ». Comme quand j’ai commencé à l’Insee, il faut attendre le lendemain pour disposer des résultats d’une demande d’extraction. Les « flux » ainsi mis à disposition sont d’une fluidité toute relative, celle d’une grosse goutte se détachant toutes les 24 heures.
Plus enthousiasmant encore, la requête en partie décrite dans l’image suivante (région Grand Est) conduit à récupérer une archive de plus de 20 000 fichiers JSON :
Ces 21 211 fiches JSON représentent environ 500 Mo de données, qu’il faut décompresser sur son disque dur pour envisager de les exploiter. Elles s’organisent dans une arborescence à deux niveaux. Les noms de fichier sont peu évocateurs et chaque document présente un contenu assez dense.
Voilà un court extrait d’une fiche pour vous donner une petite idée :
Armé de DuckDB, ma première entreprise fut d’extraire d’une fiche au hasard les variables essentielles pour le hackaviz. Les noms de champ sont un peu pénibles à manier, mais le bonheur de toucher du doigt l’univers enchanté des « ontologies » et du « web sémantique » l’emporte sur le désagrément d’avoir à multiplier les quotes et les crochets :
SELECT isLocatedAt[1]['schema:address'][1]['hasAddressCity']['insee'] AS code_com, "rdfs:label"['fr'][1] AS label, array_to_string("@type", ',') AS types, array_to_string(isLocatedAt[1]['schema:address'][1]['schema:streetAddress'], ' ') AS streetAddress, isLocatedAt[1]['schema:address'][1]['schema:postalCode'] AS postalCode, isLocatedAt[1]['schema:address'][1]['schema:addressLocality'] AS addressLocality, isLocatedAt[1]['schema:geo']['schema:latitude']::float AS latitude, isLocatedAt[1]['schema:geo']['schema:longitude']::float AS longitude FROM read_json_auto('C:\...\objects\2\23\3-23a1b563-5c8c-32e0-b0fc-e0fcbb077b29.json');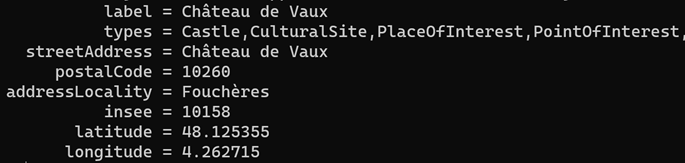
Et voici l’apparition du dernier effet bluffant DuckDB, la lecture en une seule passe et moins de 10 secondes des 21 211 fiches JSON :
CREATE OR replace TABLE poi_grandest AS SELECT isLocatedAt[1]['schema:address'][1]['hasAddressCity']['insee'] AS code_com, "rdfs:label"['fr'][1] AS label, array_to_string("@type", ',') AS types, array_to_string(isLocatedAt[1]['schema:address'][1]['schema:streetAddress'], ' ') AS streetAddress, isLocatedAt[1]['schema:address'][1]['schema:postalCode'] AS postalCode, isLocatedAt[1]['schema:address'][1]['schema:addressLocality'] AS addressLocality, isLocatedAt[1]['schema:geo']['schema:latitude']::float AS latitude, isLocatedAt[1]['schema:geo']['schema:longitude']::float AS longitude FROM read_json_auto('C:\...\objects\*\*\*.json') ;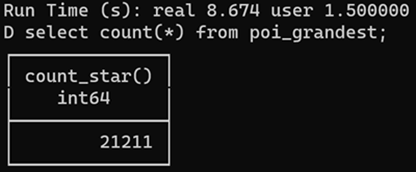
L’API DataTourisme est tellement monumentale et raffinée que la plupart des professionnels du tourisme sont incapables de l’utiliser (mais des simplifications sont annoncées pour la fin de l’année). Qu’à cela ne tienne, un marché de développeurs affutés a pu naitre, auxquels les acteurs du tourisme en besoin de données sur mesure commandent des extractions, réalisées en Python, R ou autres langages d’académique facture.
Bienvenue donc au trublion DuckDB, qui sait rendre l’open data véritablement open.
FROM poi_grandest LIMIT 10;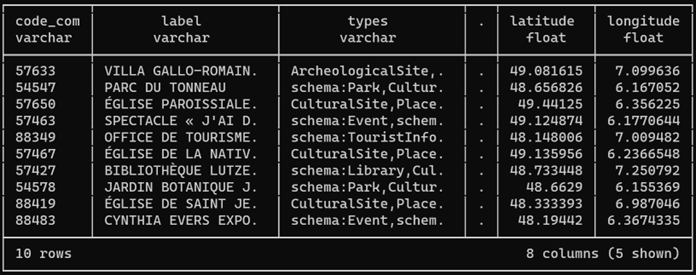
J’ai voulu montrer avec ces deux exemples comment interroger des ressources JSON avec DuckDB, en les manipulant comme des tables. J’ai même pu apparier avec un fichier distant au format Parquet.
L’annuaire des entreprises gagnerait sans doute à être mis à disposition aussi au format parquet. L’API offre de son côté des services spécifiques complémentaires (recherche textuelle, recherche de proximité). Mais le format GeoParquet, dès qu’il aura intégré les index spatiaux, saura rivaliser avec une API par ailleurs contrainte en volume et nombre d’appels.
Dans le prochain épisode (3/3), je parlerai de cartographie, de requêtes spatiales et précisément du format GeoParquet.
Pour en savoir plus- 3 explorations bluffantes avec DuckDB – Interroger des fichiers distants (1/3), icem7, 2023
- 3 explorations bluffantes avec DuckDB – Croiser les requêtes spatiales (3/3), icem7, 2023
- Parquet devrait remplacer le format CSV, icem7, 2022
- DuckDB redonne une belle jeunesse au langage SQL, icem7, 2023
- Why parquet files are my preferred API for bulk open data, Robin Linacre, 2023
- DuckDB – nested functions
- Annuaire des entreprises
L’article 3 explorations bluffantes avec DuckDB – Butiner des API JSON (2/3) est apparu en premier sur Icem7.
-
sur 3 explorations bluffantes avec DuckDB – Interroger des fichiers distants (1/3)
Publié: 16 November 2023, 3:46pm CET par Éric Mauvière
DuckDB révolutionne notre approche des données. En dépit de sa console austère, fleurant bon l’antique terminal, ce petit programme de moins de 20 Mo butine allègrement les bases les plus retorses, les plus lourdes ; qu’elles se présentent en CSV, (Geo)JSON, parquet ou en SGBD classique.
Vous êtes nombreux déjà à avoir entendu parler de cet ovni, à savoir que DuckDB est véloce, qu’il repose sur ce bon vieux langage SQL. Je veux vous présenter dans cette série de trois articles des possibilités que vous n’imaginez même pas. J’ai dû moi-même, parfois, me secouer la tête et retester soigneusement pour vérifier que je ne me trompais pas.
Commençons dans ce premier article par le travail direct avec des bases de données distantes, compressées, en open data sur Internet. Je prendrai deux exemples.
 A - La base Insee du recensement de la population 2020
A - La base Insee du recensement de la population 2020
Premier exemple, l’Insee, l’institut statistique français, vient de mettre en ligne la base détaillée du recensement, niveau individus et logements, au format parquet. Dans ce format parquet, chaque fichier pèse tout de même 500 Mo. Mais vous n’avez pas besoin de les télécharger pour travailler avec.
Je me pose la question suivante : à Paris, quels sont les arrondissements où la part des ménages ayant plus de 2 voitures est la plus forte ? Inversement on pourra s’intéresser aux arrondissements qui privilégient le ‘sans voiture’.
Je vous livre sans ménagement la requête SQL, le graphique exposant le résultat, et juste après, je vous explique. Pour le moment, retenez que vous pouvez exécuter cette requête vous-même, avec DuckDB, qu’elle consomme 12 Mo de bande passante, et prend en gros 2 secondes pour s’exécuter.
WITH tb1 AS ( SELECT ARM, VOIT, sum(IPONDI/NPERR::int) AS eft, sum(eft) OVER (PARTITION BY ARM) AS tot, round(1000 * eft / tot)/10 AS pct FROM 'https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet' WHERE dept = '75' AND NPERR 'Z' GROUP BY GROUPING SETS((ARM, VOIT),(VOIT)) ), tb2 AS ( PIVOT_WIDER (SELECT arm, voit, pct FROM tb1) ON VOIT USING first(pct) ) SELECT CASE WHEN ARM = '75001' THEN '1er' WHEN ARM IS NULL THEN 'Paris' ELSE CONCAT(RIGHT(ARM,2)::int, 'e') END AS 'Arrondt', "0" AS 'pas de voiture', "1" AS '1 voiture', "2" AS '2 voitures', "2" + "3" AS '2 voitures ou +', "3" AS '3 voitures ou +' FROM tb2 ORDER BY (Arrondt = 'Paris')::int, "2 voitures ou +" DESC ;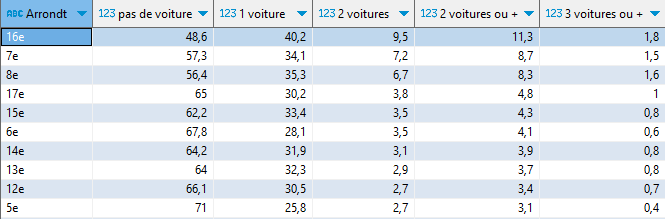
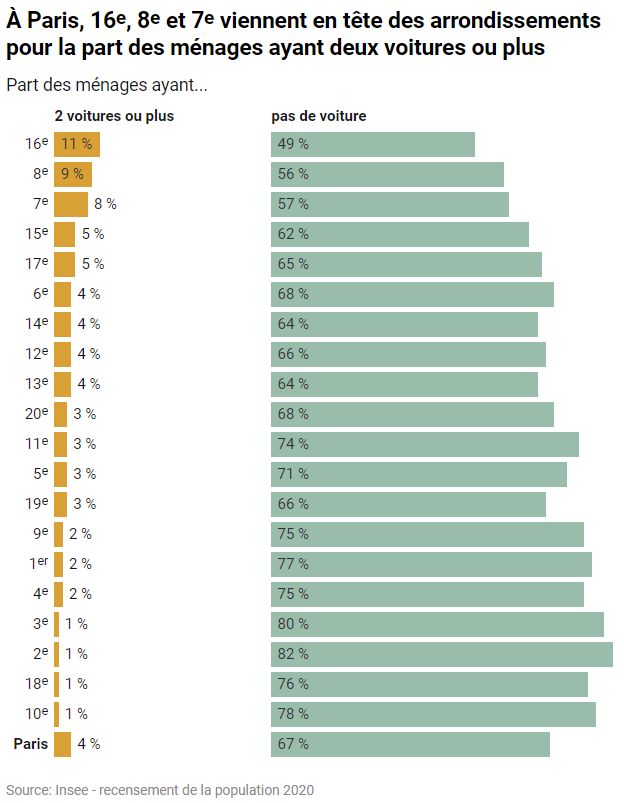
À l’opposé, les 2e et 3e arrondissements sont ceux où la part de ménages sans voiture est la plus élevée (huit ménages sur dix).
DécortiquonsComme l’URL de la base est longue, pour simplifier mon exposé, je crée d’abord une vue SQL, qui n’est qu’un alias vers ce fichier distant :
CREATE OR REPLACE VIEW fd_indcvi_2020 AS FROM 'https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet';Ne vous étonnez pas de l’absence d’un SELECT * avant le FROM, DuckDB permet de s’en passer – et c’est bien pratique – si l’on veut lire toutes les colonnes de la table.
J’utilise DuckDB soit en lançant le petit exécutable DuckDB.exe, soit à l’intérieur de DBeaver, un environnement gratuit de connexion à de multiples sources de données. DBeaver me permet de gérer de vrais scripts, de les documenter pour les retrouver plus tard. L’affichage et l’export des résultats (en CSV par exemple, ou vers le presse-papier) sont aussi plus sympas.
Une première commande simple nous donne une info minimale, la liste des colonnes et leur type :
DESCRIBE FROM fd_indcvi_2020 ;
Elle est quasi instantanée (200 ms), et j’ai mis du temps à comprendre ce qui se passait. J’analyse tout de même la structure d’un fichier de 500 Mo, sur data.gouv.fr , et je ne l’ai pas téléchargé. Comment diantre est-il possible d’avoir une info de structure aussi vite ?
Cela tient à deux facteurs :
- Le format parquet stocke dans son en-tête des métadonnées, par exemple la liste des colonnes et leur type ;
- DuckDB envoie un requête HTTP particulière, de type « range-request », qui demande à data.gouv.fr de ne lui servir qu’une petite plage de bytes, une mini-tranche du fichier parquet. Seuls 700 bytes ont transité par le réseau pour nous livrer la structure de ce fichier parquet.
Je repère les variables dont j’aurai besoin : DEPT pour retenir Paris, ARM pour les n° d’arrondissements, VOIT pour caractériser les personnes selon le nombre de voitures du ménage, IPONDI pour calculer un effectif, NPPER pour prendre en compte le nombre de personnes dans le ménage. La documentation du fichier m’offre toute la compréhension nécessaire.
Voici un comptage de ménages, selon leur nombre de voitures, par arrondissement parisien :
SELECT ARM, VOIT, round(sum(IPONDI/NPERR::int)) AS eft FROM fd_indcvi_2020 WHERE dept = '75' AND NPERR 'Z' GROUP BY ALL ;
Pour calculer un nombre de ménages, je divise la population par le nombre de personnes dans le ménage. NPPER (tout comme VOIT) n’est pas exactement numérique : 6 veut dire 6 personnes ou plus (3 veut dire 3 voitures ou +) : on s’en accommodera. La modalité Z correspond à des logements « non ordinaires », qu’on laisse ici de côté.
Je produis ensuite un tableau croisé, avec PIVOT_WIDER (qu’on peut aussi écrire, plus simplement, PIVOT) :
WITH tb1 AS ( SELECT ARM, VOIT, round(sum(IPONDI/NPERR::int)) AS eft FROM fd_indcvi_2020 WHERE dept = '75' AND NPERR 'Z' GROUP BY ARM, VOIT ) PIVOT_WIDER (FROM tb1) ON VOIT USING first(eft) ORDER BY ARM ;
Notez la nouvelle syntaxe que j’utilise pour enchainer deux opérations dans la même requête. Elle est élégante et m’évite de créer une table physique intermédiaire. Ce qui figure dans le WITH () est comme une table temporaire, disponible le temps de la requête.
J’aimerais maintenant calculer le total pour Paris. Je n’ai pour cela qu’à aménager la clause GROUP BY. Le complément GROUPING SETS permet de spécifier ensemble différents niveaux d’agrégation.
WITH tb1 AS ( SELECT ARM, VOIT, round(sum(IPONDI/NPERR::int)) AS eft FROM fd_indcvi_2020 WHERE dept = '75' AND NPERR 'Z' GROUP BY GROUPING SETS ((ARM, VOIT), (VOIT)) ) PIVOT_WIDER (FROM tb1) ON VOIT USING first(eft) ORDER BY ARM ;
On découvre en bas de tableau la nouvelle ligne ajoutée. On pourra plus tard remplacer ce disgracieux NULL par la mention ‘Paris’.
Maintenant, ce que je voudrais pour répondre à ma question initiale, c’est calculer des pourcentages, pour chaque arrondissement : % de ménages du 12e qui ont 0 voiture, plus de 2 voitures, etc. Pour cela, il me faut le total des ménages pour chaque arrondissement. Il y a plusieurs façons de le faire, plus ou moins manuelles. La plus élégante consiste à utiliser les mots clés OVER et PARTITION.
Revenons à notre premier calcul, avant le PIVOT. Je lui rajoute une ligne, après la première :
SELECT ARM, VOIT, sum(IPONDI) AS eft, sum(eft) OVER (PARTITION BY ARM) AS tot, FROM fd_indcvi_2020 WHERE dept = '75' AND NPERR 'Z' GROUP BY GROUPING SETS((ARM, VOIT),(VOIT)) ;
Cette instruction a bien pour effet de calculer un total par arrondissement. PARTITION fonctionne comme un nouveau GROUP BY, mais qui ne change pas le nombre de lignes, il ajoute simplement une colonne calculée. Cette nouvelle instruction relève de la catégorie des « WINDOW functions », très puissantes, dont je ne vais pas décrire toutes les finesses ici.
Une autre des charmantes spécificités du SQL dans DuckDB, c’est que les colonnes calculées sont immédiatement utilisables pour le calcul d’autres nouvelles colonnes.
Ainsi, je peux produire le pourcentage dans le même mouvement :
SELECT ARM, VOIT, sum(IPONDI/NPERR::int) AS eft, sum(eft) OVER (PARTITION BY ARM) AS tot, round(1000 * eft / tot) / 10 AS pct FROM fd_indcvi_2020 WHERE dept = '75' AND NPERR 'Z' GROUP BY GROUPING SETS((ARM, VOIT),(VOIT)) ;
Il ne me reste plus qu’à pivoter et arranger la présentation du résultat final :
WITH tb1 AS ( SELECT ARM, VOIT, sum(IPONDI/NPERR::int) AS eft, sum(eft) OVER (PARTITION BY ARM) AS tot, round(1000 * eft / tot)/10 AS pct FROM fd_indcvi_2020 WHERE dept = '75' AND NPERR 'Z' GROUP BY GROUPING SETS((ARM, VOIT),(VOIT)) ), tb2 AS ( PIVOT_WIDER (SELECT arm, voit, pct FROM tb1) ON VOIT USING first(pct) ) SELECT CASE WHEN ARM = '75001' THEN '1er' WHEN ARM IS NULL THEN 'Paris' ELSE CONCAT(RIGHT(ARM,2)::int, 'e') END AS 'Arrondt', "0" AS 'pas de voiture', "1" AS '1 voiture', "2" AS '2 voitures', "2" + "3" AS '2 voitures ou +', "3" AS '3 voitures ou +' FROM tb2 ORDER BY (Arrondt = 'Paris')::int, "2 voitures ou +" DESC ;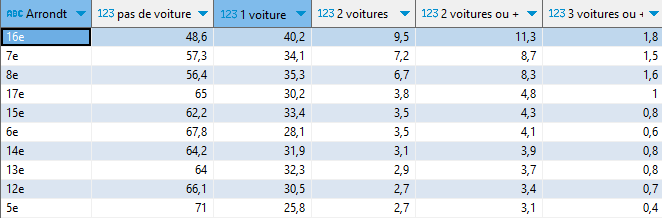
Cette dernière écriture prend 2 secondes et consomme seulement 12 Mo de bande passante. Rappelons-le, elle attaque directement le fichier parquet de 500 Mo en ligne, que je n’ai pas téléchargé au préalable.
Parquet organise l’information par groupe de lignes et par colonne, je n’ai lu via des range-requests que les colonnes dont j’avais besoin pour le calcul, et uniquement pour les lignes correspondant à Paris.
B - Les faits de délinquance du ministère de l’IntérieurIntéressons-nous maintenant à la base statistique communale de la délinquance enregistrée par la police et la gendarmerie nationales.
Il ne s’agit pas – encore – de fichiers parquet, mais de CSV compressés (csv.gz). Pas de problème, DuckDB peut les lire directement. En revanche, les range-requests ne sont pas aussi puissantes qu’avec Parquet : il faudra lire tout le fichier (39 Mo) avant de pouvoir en tirer parti.
Je crée comme tout à l’heure une vue pour simplifier les écritures. En réalité, cette vue analyse déjà tout le fichier pour deviner la structure les colonnes (j’ai mesuré 1 seconde d’attente).
CREATE OR REPLACE VIEW faits_delinq AS FROM 'https://static.data.gouv.fr/resources/bases-statistiques-communale-et-departementale-de-la-delinquance-enregistree-par-la-police-et-la-gendarmerie-nationales/20230719-080535/donnee-data.gouv-2022-geographie2023-produit-le2023-07-17.csv.gz';Ce qui fait qu’un DESCRIBE devient instantané :
DESCRIBE FROM faits_delinq ;
CODGEO_2023 est certainement le code commune, je me fabrique un aperçu de la table pour ma ville, Toulouse :
FROM faits_delinq WHERE CODGEO_2023 = '31555' LIMIT 10 ;Les informations utiles sont : l’année (qu’il faudra arranger), la classe et le nombre de faits. On peut noter que l’unité des faits dépend de la classe d’infraction : victimes ou voitures par exemple.
Avec un PIVOT, la présentation devient plus claire, et distingue en colonnes une quinzaine de classes de faits de délinquance.
WITH faits_tls AS ( SELECT concat('20', annee) AS an, classe, faits, FROM faits_delinq WHERE CODGEO_2023 = '31555' ORDER BY an, classe ) PIVOT_WIDER faits_tls ON classe USING first(faits) ORDER BY an ;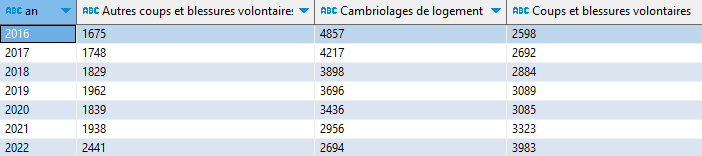
Pour simplifier et construire un graphique, je vais m’en tenir aux seules classes dont le nombre de faits, en fin de période (2022), dépasse les 2 500. Une petite ligne additionnelle, utilisant la puissance des « WINDOW functions », me permet de calculer cette valeur terminale et de filtrer les classes que je veux retenir.
QUALIFY joue le rôle d’un WHERE, et arg_max() – encore une superbe petite fonction – cible le nombre de faits là où an est maximal (donc 2022) :
WITH faits_tls AS ( SELECT concat('20', annee) AS an, classe, faits, FROM faits_delinq WHERE CODGEO_2023 = '31555' QUALIFY arg_max(faits, an) OVER (PARTITION BY classe) > 2500 ORDER BY an,classe ) PIVOT_WIDER faits_tls ON classe USING first(faits) ORDER BY an ;Avec un copier-coller du résultat, je peux produire, avec Datawrapper, cet éclairant graphique :
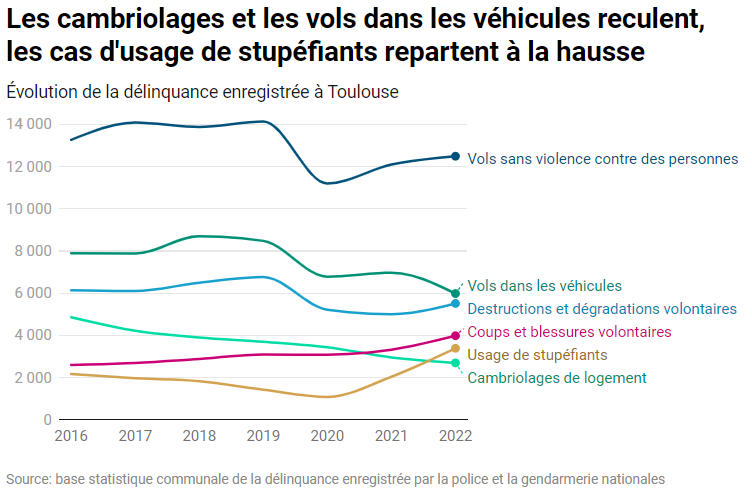
J’ai donc montré avec ces deux exemples comment interroger directement des bases distantes avec DuckDB, et avec beaucoup de souplesse et d’élégance.
J’espère aussi avoir convaincu un peu plus de diffuseurs de bases d’utiliser le format Parquet pour mettre à disposition leurs données.
Dans le prochain épisode (2/3), je parlerai d’API web et du format JSON.
Pour en savoir plus- 3 explorations bluffantes avec DuckDB – Butiner des API JSON (2/3), icem7, 2023
- 3 explorations bluffantes avec DuckDB – Croiser les requêtes spatiales (3/3), icem7, 2023
- Parquet devrait remplacer le format CSV, icem7, 2022
- DuckDB redonne une belle jeunesse au langage SQL, icem7, 2023
- Guide d’utilisation des données du recensement de la population au format Parquet, Antoine Palazzolo, Lino Galiana, Insee, 2023
- Formation DuckDB, icem7
L’article 3 explorations bluffantes avec DuckDB – Interroger des fichiers distants (1/3) est apparu en premier sur Icem7.
-
sur Où sont les femmes dans les rues de Toulouse (et d’ailleurs) ?
Publié: 30 September 2023, 8:20am CEST par Éric Mauvière
L’autre jour, ma femme m’interpelle, tout à trac : « toi qui aimes jouer avec les données, pourrais-tu me faire une carte des rues de Toulouse portant un nom d’une femme ? »
C’est qu’elle coorganise la Transtoulousaine, une randonnée urbaine annuelle, en itinéraires convergeant vers le centre de la ville. Chaque édition comporte un thème : cette année les arbres, une autre fois peut-être bien les femmes. Un enjeu sera alors de définir des parcours qui célèbrent des personnalités féminines, si possible locales.
À cette demande en forme de défi, je réagis d’abord avec réserve : « Ça ne va pas être simple… Je peux sans doute trouver un répertoire des rues, mais comment détecter la présence d’une femme ? ». « Facile », me rétorque-t-elle, « tu n’as qu’à utiliser le fichier des prénoms ! ». Je dois le dire, elle avait bien préparé son affaire !

Et en effet, je connais bien cette source de l’Insee, recensant tous les prénoms donnés depuis au moins 1900, et les distinguant par genre.
La base nationale des prénoms ressemble à ceci, elle présente des effectifs par année de naissance :
Localiser un fichier des rues sur le site open data de Toulouse métropole ne m’a pris que quelques minutes. Il s’agit d’un filaire de voies, un fond de carte couvrant toute la métropole, qui renseigne naturellement le nom des voies, leur nature (rue, allée, boulevard, etc.) et leur commune d’appartenance. Voici un aperçu des données associées à chaque tronçon :
On pressent déjà que les femmes ne seront pas légion.
Pour manipuler des données, mon joujou favori ces derniers temps s’appelle DuckDB. C’est un petit programme tout simple qui permet d’exécuter des requêtes SQL avec une vélocité remarquable. Pour rapprocher les voies des prénoms, je vais joindre les deux bases en précisant une condition : le nom des voies doit contenir un prénom féminin.
Une première écriture ressemble à cela :
LOAD SPATIAL ; CREATE OR REPLACE TABLE filaire_femmes_toulouse AS ( WITH prenoms_feminins AS ( SELECT preusuel, nb_prf FROM ( SELECT strip_accents(preusuel) AS preusuel, sum(nombre)::int AS nb_prf FROM 'https://icem7.fr/data/prenoms_nat2022.parquet' WHERE sexe = 2 GROUP BY ALL HAVING nb_prf > 1000 ) ) , filaire_json AS ( FROM st_read('C:/.../datasets/filaire-de-voirie.geojson') WHERE code_insee = '31555' ) SELECT * FROM filaire_json JOIN prenoms_feminins ON contains(' ' || street || ' ', ' ' || preusuel || ' ') );Cette requête crée une table en 3 étapes :
- Lecture de la base des prénoms, que j’ai convertie de CSV vers le format parquet, bien plus compact et efficace. Je ne retiens que les prénoms donnés à des filles, et plus de mille fois. Cela représente tout de même 1 800 prénoms.
- Lecture du filaire de voies en ne gardant que les données sur Toulouse, dont le code commune est 31555. La fonction st_read() pourrait lire directement l’URL du fichier, mais celui-ci fait 20 Mo et le serveur de téléchargement est assez lent, je l’ai donc stocké au préalable.
- Jointure sur la condition de présence du prénom dans le nom de la voie (les || permettent de coller des bouts de textes, rajoutant ici des blancs de part et d’autre des colonnes pour bien isoler les prénoms).
En moins de 2 secondes, j’obtiens un résultat qui décrit les tronçons de 372 voies, soit un dixième du total des voies toulousaines.
Impatient de les visualiser, je les exporte dans un format géographique passe-partout, le GeoJSON :
COPY filaire_femmes_toulouse TO 'C:/.../datasets/filaire-femmes-toulouse.json' WITH (FORMAT GDAL, DRIVER 'GeoJSON');Notez au passage la souplesse de cet outil de requêtage DuckDB : il est à l’aise avec tous les formats, y compris géographiques.
Une première carte bruteIl me suffit enfin de faire glisser ce fichier généré dans mon navigateur, sur [https:]] par exemple, pour voir s’afficher ces tracés. Ils sont visibles ici en gris, sur un fond de plan classique :
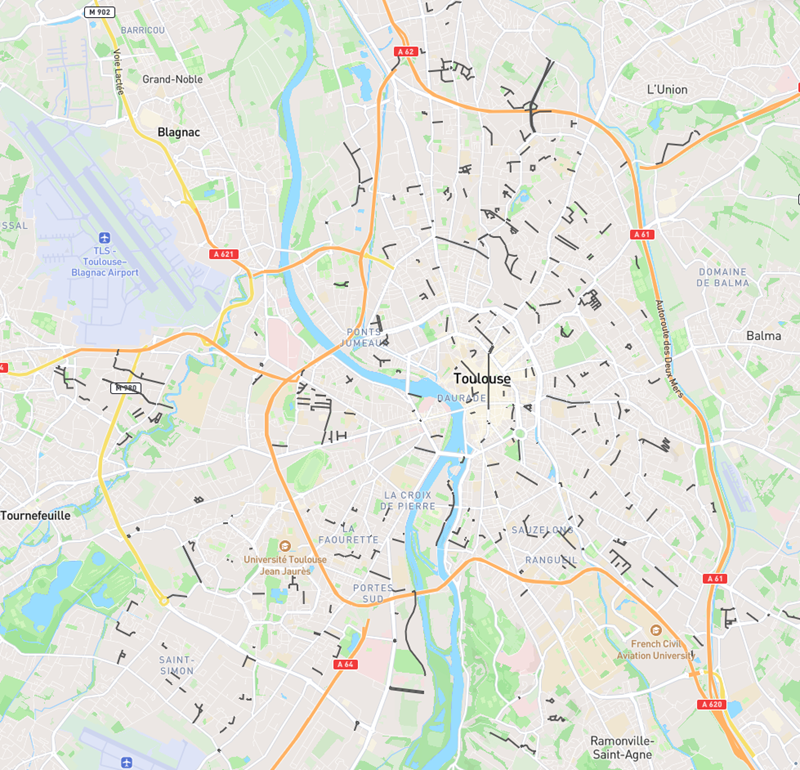 © OpenStreetMap - geojson.io
© OpenStreetMap - geojson.io
C’est presque trop simple pour être tout à fait crédible ! Mais tout de même, ces 372 voies ne sont pas si loin de la réalité, qui correspond plutôt à 300 (soit 8 % des voies toulousaines), comme on va le voir par la suite.
Rassurez-vous, je vous épargne désormais les écritures SQL, que les curieux·ses pourront trouver dans ce classeur Observable.
Examinons de plus près ces rues de première extraction ; le début du fichier, classé par prénom, se présente plutôt bien :
Mais un peu plus loin, je constate qu’il y a du tri à faire :
Claude est en effet un des nombreux prénoms mixtes, comme Dominique, Dany ou Camille. Sur les 480 000 Claude né·es dans entre 1900 et 2020, 88 % étaient des garçons. Il est donc tentant de ne retenir pour notre recherche que les prénoms majoritairement féminins. Exit donc les Claude, Dominique ou Hyacinthe.
Le cas des Camille est intéressant et davantage épineux.
Ce prénom est devenu bien plus populaire pour les filles à partir des années 1980. Ce qui fait qu’il apparait dans notre sélection de prénoms : il est majoritairement féminin.
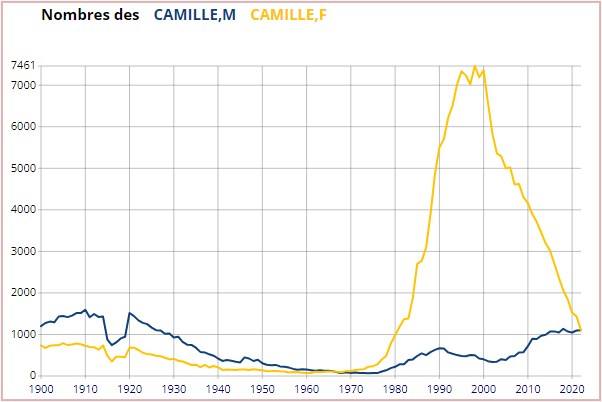 Source : Insee - outil interactif sur les prénoms
Source : Insee - outil interactif sur les prénoms
Pour l’ensemble de la France (données du répertoire national Fantoir), les voies reprenant ce prénom mettent en tête Camille Claudel, mais pour le reste citent exclusivement des hommes.
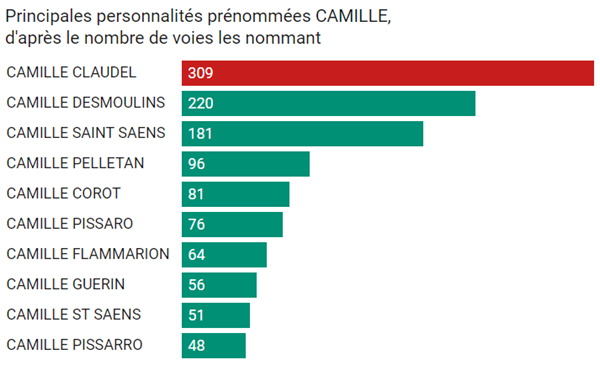
Ainsi, je vais devoir gérer dans ce cas une règle particulière : ne pas tenir compte des Camille dans ma recherche de voies féminines, sauf les « Camille Claudel ». Il en va de même pour George Sand.
D’autres prénoms féminins entrent en compétition avec des toponymes ou des articles : que l’on pense à l’occitan LOU (qui correspond à LE), à ETOILE, LORRAINE, NANCY, AVRIL, ALMA… Pour parfaire mon filtrage, je vais exclure de ma base de prénoms majoritairement féminins ces mots fréquemment rencontrés dans les noms de rues, mais probablement peu liés à des personnes. Dans le même temps, je veille à réintroduire quelques exceptions : outre Camille Claudel et George Sand précédemment évoqués, France Gall par exemple, ainsi que quelques rares prénoms locaux comme Géori ou Philadelphe.
Enfin, en l’absence de prénoms reconnus, certains titres comme COMTESSE (de Ségur), MADAME (de Sévigné), SOEUR fournissent de bons indices de la présence d’une femme.
300 voies féminines à Toulouse,
soit 8 % de l'ensemble des voiesC’est ainsi que j’en arrive à identifier 300 voies a priori évocatrices d’une femme, que l’on voit ici en rouge, sur cette carte interactive et zoomable :
/* [https:] */ .fullwidthx { width: 100vw; position: relative; left: 50%; right: 50%; margin-left: -50vw; margin-right: -50vw; }© IGN - Toulouse métropole
import {Runtime, Inspector} from "https://cdn.jsdelivr.net/npm/@observablehq/runtime@5/dist/runtime.js"; import define from "https://api.observablehq.com/@ericmauviere/cartographions-les-voies-se-referant-a-une-femme-a-toulouse.js?v=4"; new Runtime().module(define, name => { if (name === "viewof cat") return new Inspector(document.querySelector("#observablehq-viewof-cat-a40b5924")); if (name === "viewof search") return new Inspector(document.querySelector("#observablehq-viewof-search-a40b5924")); if (name === "viewof voies_femmes_sel2") return new Inspector(document.querySelector("#observablehq-viewof-voies_femmes_sel2-a40b5924")); if (name === "viewof map") return new Inspector(document.querySelector("#observablehq-viewof-map-a40b5924")); return ["map_p","fly_p"].includes(name); });Les autres catégories résultent d’un travail similaire mené sur les prénoms masculins. Une fois les voies féminines mises de côté, les voies restantes relèvent de 3 classes :
- Celles dont la dénomination comprend un prénom masculin ou un indice significatif (GENERAL, MAL, PRESIDENT, ABBE…)
- Celles ensuite qui excluent a priori la référence à une personne, par la présence, après le type de voie, de DU, DE, DES : BD DE STRASBOURG, CHE DE TUCAUT…
- Les autres au statut indéterminé, qui évoquent un homme, un lieu ou une profession : RUE LAFAYETTE, RUE MOLIERE, RUE MATABIAU, RUE PARGUAMINERES…
Ainsi, il apparait que les 8 % de femmes font face à une fourchette de 44 – 57 % d’hommes référencés, soit en gros 6 fois plus d’hommes que de femmes.
 Source : Toulouse métropole - Insee © icem7
Source : Toulouse métropole - Insee © icem7
Il y a naturellement aussi quelques voies mixtes, Pierre et Marie Curie, Lucie et Raymond Aubrac par exemple, que je ne compte pas deux fois, les classant d’autorité dans la catégorie féminine !
Sur ces 300 voies féminines, une bonne vingtaine renvoient à un prénom seul dont certains sont identifiables (impasse Arletty, rue Colette, impasse Barbara) et d’autres non (impasse Matilda, rue Christiane, rue Sylvie, parc de Claire). 20 autres désignent une sainte.
Des voies aux caractéristiques particulièresToulouse, comme la plupart des grandes villes, conduit un effort de rééquilibrage. Depuis une dizaine d’années au moins, la commission de dénomination célèbre au moins autant de femmes que d’hommes. Il y a aussi ces professions emblématiques que je n’ai pas intégrées, comme les « Munitionnettes » de la Cartoucherie, ou les « Entoileuses » de Montaudran, chargées de recouvrir les avions de tissu.
Mais peu de voies sont débaptisées. Ce sont surtout les nouveaux quartiers, résidentiels ou d’activité, voire des aménagements routiers (bretelles) qui ouvrent des opportunités.
Ici, dans un nouveau quartier près du Zénith, la mixité des dénominations est assurée :
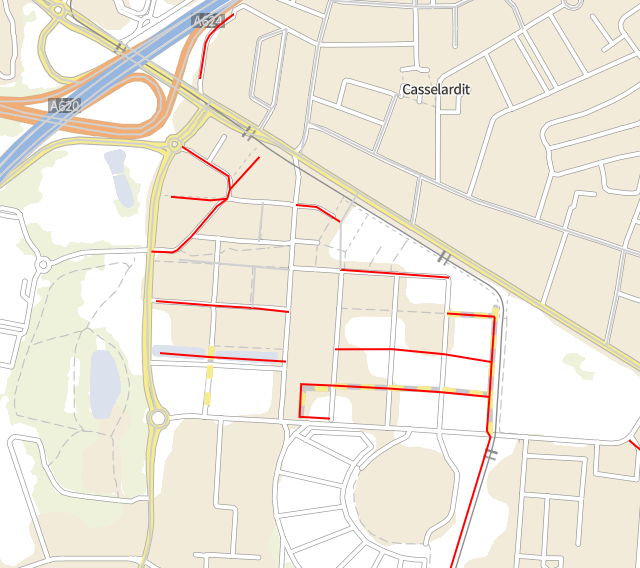 Source : Toulouse métropole - Insee © IGN
Source : Toulouse métropole - Insee © IGN
Mais des voies au statut plus incertain, sans adresse (points verts) identifiée, sont aussi utilisées :
 Source : base adresse nationale © Etalab - OpenMapTiles - OpenStreetMap
Source : base adresse nationale © Etalab - OpenMapTiles - OpenStreetMap
J’ai relevé toutefois un cas de renommage en centre-ville : OpenStreetMap évoque toujours en 2023 la rue du Languedoc quand le début de celle-ci est devenu allée Gisèle Halimi en 2021.
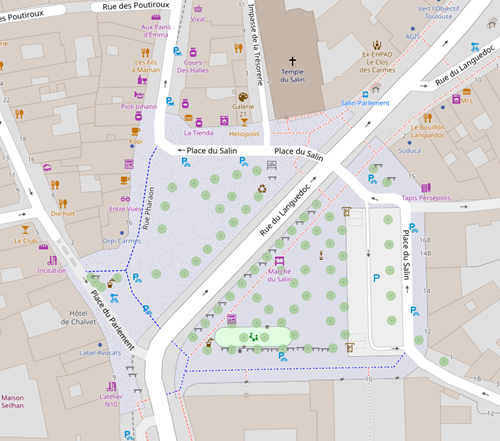 © OpenStreetMap
© OpenStreetMap
 © IGN
Peu nombreuses, les voies féminines sont aussi plus courtes et plus modestes, plus représentées dans la catégorie des allées ou des ronds-points ; les boulevards ou les avenues sont quasiment inexistants.
© IGN
Peu nombreuses, les voies féminines sont aussi plus courtes et plus modestes, plus représentées dans la catégorie des allées ou des ronds-points ; les boulevards ou les avenues sont quasiment inexistants.
 Sources : Toulouse métropole - Insee
La longueur moyenne d’une voie féminine est de 200 m, contre 300 m pour les masculines. La voie féminine la plus longue, le bd Florence Arthaud, parcourt 1,6 km, une trentaine de voies masculines sont plus longues, allant jusqu’à près de 4 km pour l’avenue du Général Eisenhower.
Qu'en est-il ailleurs en France ?
Sources : Toulouse métropole - Insee
La longueur moyenne d’une voie féminine est de 200 m, contre 300 m pour les masculines. La voie féminine la plus longue, le bd Florence Arthaud, parcourt 1,6 km, une trentaine de voies masculines sont plus longues, allant jusqu’à près de 4 km pour l’avenue du Général Eisenhower.
Qu'en est-il ailleurs en France ?
Les données disponibles nationalement proviennent de deux sources :
- Fantoir, répertoire des voies et lieux-dits, produit par la direction générale des finances publiques (les Impôts), alimenté par la gestion du cadastre ;
- La base adresse nationale (BAN), qui référence toutes les adresses (soit x points par voie).
Les deux sont accessibles sous forme de fichiers ou d’API. La BAN est par nature bien plus lourde qu’un simple répertoire des voies. Et elle ne référence que celles qui ont des adresses. Par exemple, la rue Karen Blixen que nous avons rencontrée plus haut n’y figure pas.
Reste donc Fantoir, dont la base nationale est téléchargeable en open data depuis 2013, ce qui est à saluer ! En revanche, son format interne est difficile à décoder, j’ai donc converti la dernière version datée d’avril 2023 au format Parquet (ce qui permet aussi de réduire sa taille de 1 Go à 130 Mo).
En voici un extrait (pour Toulouse) :
 Source : Fantoir/DGFIP
Source : Fantoir/DGFIP
Son intérêt principal, c’est qu’il est national, il présente toutefois quelques limites par rapport au filaire de voies de Toulouse métropole :
- Ce n’est pas un fichier géographique, il ne comprend pas le tracé des voies ;
- Le champ libelle_voie est limité à 30 caractères, ce qui conduit à de fâcheuses abréviations qui peuvent affecter les prénoms. Comment deviner par exemple que les deux premières lignes évoquent une Anne-Marie et une Anne-Josèphe ?
- Il accuse, dans sa version open data, un retard d’environ une année.
Ceci explique qu’une vingtaine de voies manquent à l’appel quand je lui applique, pour Toulouse, mon programme d’identification des voies féminines (soit une sous-estimation de 7 %).
La moyenne nationale s’établit à 3,8 % de part de voies féminines. Je ne m’étends pas sur les comparaisons départementales, tant le degré d’urbanisation parait influer sur les résultats.
En revanche, certaines petites communes se détachent spectaculairement. J’ai par exemple repéré La Ville-aux-Dames, dans l’agglomération de Tours. Cette commune de 5 000 habitants a décidé en 1974 que toutes les rues porteraient des noms de femme, sauf exception, par exemple la place du 8 mai ou celle du 11 novembre.
La commune de Lisores, dans le pays d’Auge, berceau du peintre Fernand Léger, est devenue la cité des peintres, hommes et femmes. Son conseil a décidé en 2018 non seulement de respecter strictement la parité, mais de donner des noms de peintres à toutes ses voies (sauf exceptions toponymiques).
L’examen des plus grandes villes confirme que la taille a un effet sur la féminisationLe taux moyen monte en effet de 3,6 % à 5,5 % pour l’ensemble des villes de plus de 100 000 habitants, et 6,7 % pour les plus de 200 000.
Et dans cette dernière catégorie, Toulouse se classe plutôt bien, 3e derrière Rennes et Nantes.
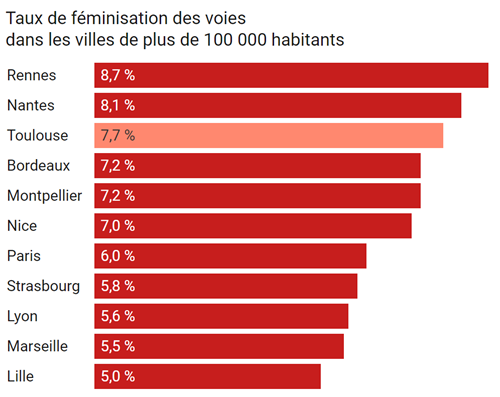 Sources : Fantoir/DGFIP - Insee
Sources : Fantoir/DGFIP - Insee
Paris est proche de la moyenne, mais les disparités sont grandes entre ses arrondissements : moins de cinq références significatives dans le 8e ou le 9e, mais près de 10 % de voies féminines dans le 13e.
Quelles sont les personnalités les plus citées
dans nos rues ?Pour dresser ces tableaux pour les femmes et les hommes, j’ai dû prendre en compte de subtiles variations orthographiques. J’ai aussi choisi d’affecter PIERRE ET MARIE CURIE à MARIE CURIE (idem pour LUCIE AUBRAC, souvent associée à RAYMOND). Par ailleurs, Pasteur, Gambetta ou Foch sont souvent cités sans prénom, il faut donc les prendre en compte manuellement après examen du palmarès de tous les noms de voies en France.
Simone Veil est la personnalité la plus contemporaine à être honorée sur les plaques de nos rues, devant même François Mitterrand.
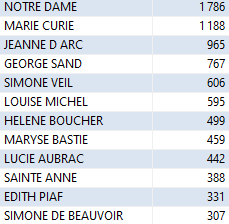
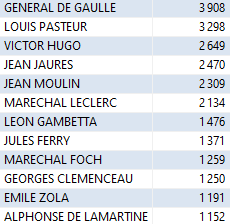 Quelles sont enfin les tendances récentes ?
Quelles sont enfin les tendances récentes ?
Pour répondre à cette question, la présence dans Fantoir d’une colonne date_creation m’a paru prometteuse. Mais à l’examen, elle ressemble plus à une date de modification de l’enregistrement (elle est toujours supérieure à 1987), et celles-ci peuvent intervenir pour tout un tas de raisons liées aux évolutions du cadastre.
J’ai donc considéré les noms de voies qui n’étaient que peu représentés à la création du fichier, mais qui sont apparus depuis 2010. Là encore, il a fallu prendre en compte des variations orthographiques, voire des coquilles (Mitterrand étant par exemple parfois écrit avec un seul r).
Commençons donc par les hommes. Quand une personnalité éminente disparait, il est de coutume de la célébrer, entre autres sous la forme d’un odonyme. Et s’il s’agit d’un président, on n’hésitera pas à rebaptiser une voie prestigieuse. L’avenue Jacques Chirac remplace ainsi depuis peu, à Toulouse le boulevard des Crêtes. Toutefois, Jacques Chirac (40 voies à ce jour) et Valéry Giscard d’Estaing (25) n’ont pour l’heure pas connu de succès comparable à la seule année qui a suivi le décès de François Mitterrand.
Nelson Mandela illustre un cas différent et intéressant, il était déjà admiré et célébré de son vivant. Je ne m’attendais pas, enfin, à voir apparaitre dans ce palmarès le colonel Arnaud Beltrame, en 4e position.
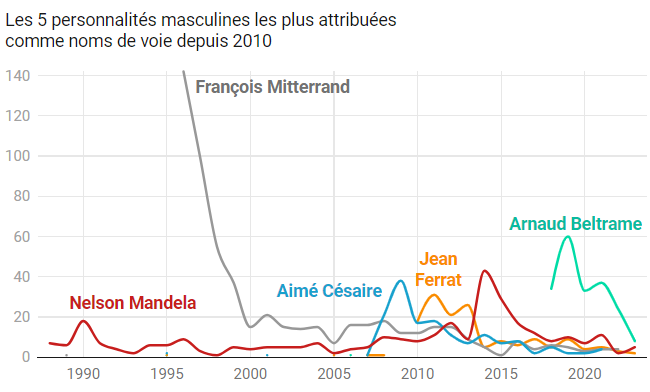 Sources : Fantoir/DGFIP - Insee
Sources : Fantoir/DGFIP - Insee
Pour les femmes, Simone Veil domine ce palmarès des tendances depuis 2010, mais elle était déjà honorée avant son décès. Simone de Beauvoir et Olympe de Gouges restent des valeurs sûres, icônes du féminisme, gagnant même en popularité ces dix dernières années. La disparition brutale de Florence Arthaud, enfin, a provoqué une réelle émotion.
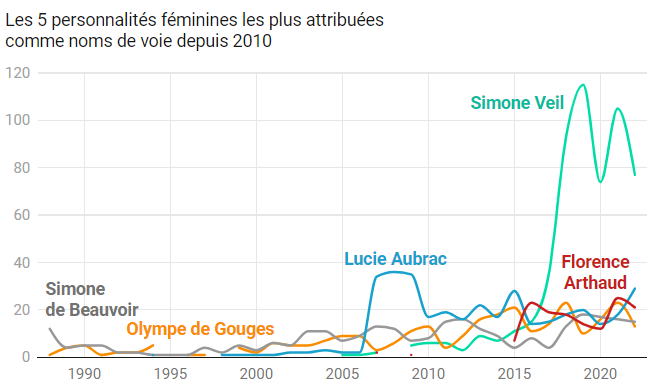 Sources : Fantoir/DGFIP - Insee
Sources : Fantoir/DGFIP - Insee
On le voit, tester la présence de prénoms permet de bien dégrossir le sujet, mais il reste pas mal de travail manuel pour ne pas rater ce qui apparait après coup comme des évidences. Les bases ont aussi leurs petits défauts, quand ce sont d’abord des bases de gestion, qu’il faut connaitre et savoir contourner.
Le prénom des gens est important, il les identifie et les humanise. Il devrait apparaitre systématiquement, sur les plaques comme dans les fichiers.
En dépit de mes réserves initiales, je dois remercier mon épouse de m’avoir plongé dans cette instructive exploration. Et tout autant les concepteurs de ce fabuleux outil qu’est DuckDB : sa souplesse et sa vélocité m’ont permis de pousser sans entraves tous mes questionnements et souhaits de vérification. Et enfin toutes celles et ceux qui œuvrent à mettre à disposition libre ces précieuses bases de données.
Pour en savoir plus- Classeur Observable avec requêtes et programmation de la cartographie
- La féminisation des noms de rue à Toulouse, c’est pour quand?? Médiacités
- Toulouse : place aux femmes dans les nouveaux noms de rue – France 3
- Archipel Citoyen propose de nouveaux noms de femmes pour les rues de Toulouse – Le journal toulousain
- Parité dans les noms donnés aux rues et son évolution ces dernières années – Christian Quest
- Vers l’automatisation d’une visualisation des hommages aux femmes dans la ville – Philippe Gambette
- Ces 200 personnalités sont les stars des rues françaises – Slate
- Comment nos rues se féminisent et s’internationalisent (lentement) – Slate
L’article Où sont les femmes dans les rues de Toulouse (et d’ailleurs) ? est apparu en premier sur Icem7.
-
sur Récréation – recréation sémiologique*
Publié: 10 August 2023, 1:57pm CEST par Éric Mauvière
Les publications statistiques de la Drees sont très intéressantes sur le fond, mais j’ai parfois un peu de mal à comprendre rapidement le message des graphiques qu’elles présentent…
Cet article de juillet 2023 sur « les mesures socio-fiscales 2017-2022 » évoque un sujet majeur, celui du pouvoir d’achat, et la contribution des prestations sociales comme le RSA, les aides au logement ou la prime d’activité, à son évolution récente. Les impôts et les taxes sont également pris en compte : quand ils baissent, ils augmentent le « revenu disponible ».
Nous allons examiner deux graphiques de cette publication et voir comment les reconstruire de façon plus expressive.
Ce premier diagramme expose les différentes composantes du revenu disponible : salaire (quand la personne travaille), prestations sociales, impôts et taxes. Le graphique considère un « cas-type », celui de personnes seules locataires, à différents niveaux de salaire, y compris celles sans activité (pas de salaire).
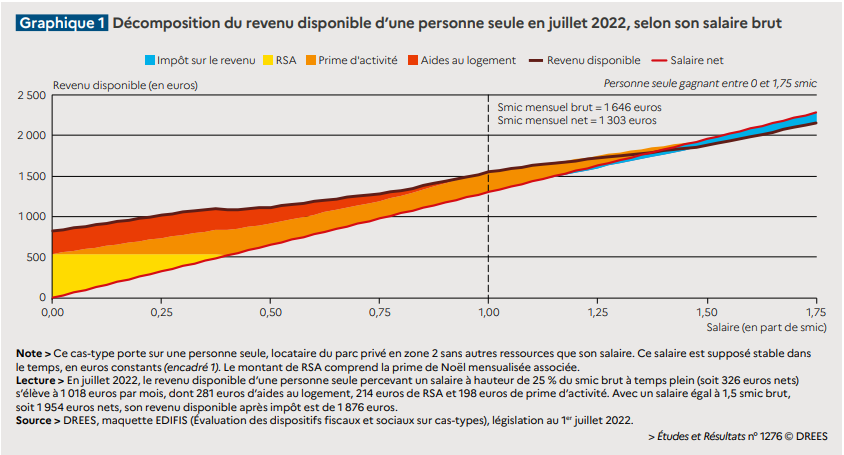
Bien qu’évoquant une « décomposition », le graphique de la Drees met surtout l’accent, par des aplats de couleur tranchés, sur la différence entre salaire (ligne rouge) et revenu disponible (ligne noire). Cette représentation dérivée élève d’emblée le niveau d’exigence requis pour la bonne compréhension des concepts et de leur articulation.
La zone de croisement des courbes est un peu floue, il faut saisir que la surface bleue (impôts) vient se soustraire du salaire pour aboutir au revenu disponible.
Reconstruire posément avec un outil simple type DatawrapperCommençons par mettre à plat, de façon homogène, toutes les composantes du revenu disponible :
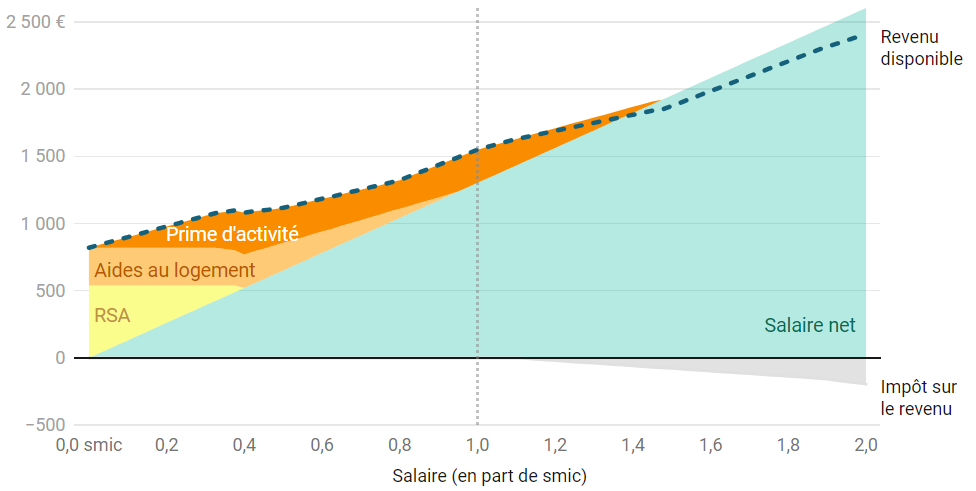
La Drees fournit les données détaillées avec l’article (elles vont même jusqu’à 2 smic), et j’utilise l’outil web Datawrapper dans sa version gratuite, par copier/coller du jeu de données.
Les aires (colorées de façon plus douce) traduisent clairement toutes les contributions, positives (salaire et prestations) ou négatives (impôt). Les trois grandes catégories se distinguent aisément par leur opposition chromatique (oranges, vert, gris).
Le seul tracé linéaire dessine la résultante, le revenu disponible. L’on devine intuitivement qu’il exprime la soustraction entre contributions positives et négative.
L’impôt apparait un peu avant (1,1 smic) que les prestations ne s’effacent (1,45 smic).
En inversant le placement de la prime d’activité et des aides au logement (AL), je mets mieux en évidence la quasi-constance des AL de 0 à 0,4 smic.
D’une façon générale, ramenant à une base horizontale un maximum de contributions (salaire, RSA, AL et impôt), leur évolution devient précisément perceptible.
Légende intégrée (les aires sont nommées au plus près), suppression du grisé d’arrière-plan, atténuation des grillages contribuent à la hiérarchisation des éléments du graphique, et donc à la lisibilité d’ensemble.
Pour parfaire le résultat, je réintègre les mentions obligatoires (source, définitions), ajoute un titre informatif et annote quelques points clés.
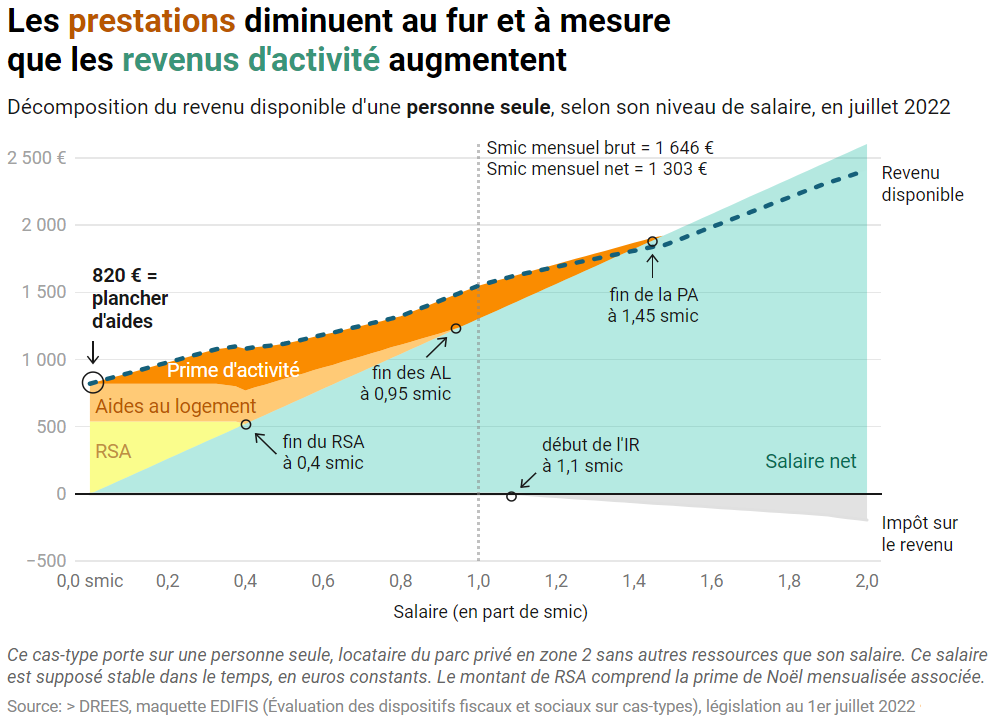
Ce graphique de synthèse traduit l’essentiel à retenir des mécanismes de compensation et d’amortissement à l’œuvre. Il est plus facile à mémoriser.
En réalisant ce travail sémiologique, j’ai enfin saisi l’articulation de concepts que je n’avais compris que partiellement jusqu’alors. Ces vagues qui se déploient et se succèdent deviennent tout naturellement esthétiques : la beauté nait de l’évidence.
C’est un autre graphique que la Drees a mis en avant sur les réseaux sociaux, car il relaie le titre et donc le message essentiel de l’étude : comment le pouvoir d’achat a-t-il évolué ces 5 dernières années selon le niveau de salaire ?
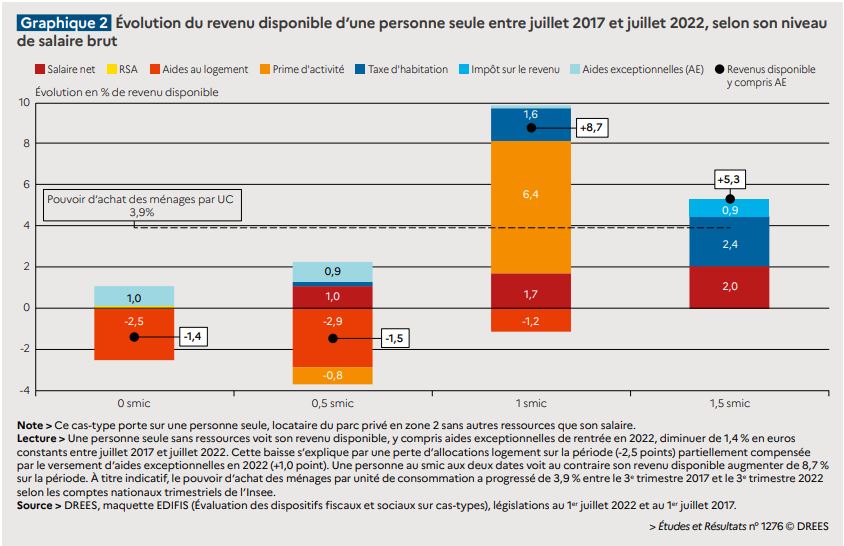
Si j’ai assez vite épinglé ce graphique dans mes « favoris », c’est qu’au bout de 10 secondes je n’avais toujours rien saisi, même pas un début de fil à tirer ! Ces empilements colorés flottaient devant mes yeux sans qu’aucune porte ne s’ouvre.
J’ai donc suivi la même démarche que précédemment, partant des données détaillées et jouant avec Datawrapper. La première action clarifiante consiste à ramener les données à comparer à une base (verticale) commune : les éléments ne flottent plus, le diagramme gagne en structure.

Après transposition, cette représentation quasi-brute proposée par l’outil graphique a commencé à me parler, des motifs et des regroupements naturels se laissent deviner.
Jacques Bertin : « Comprendre, c'est catégoriser »Ainsi, suivant le précepte bertinien du reclassement optimal des colonnes (les lignes sont déjà naturellement ordonnées), j’aboutis après quelques permutations à ceci :
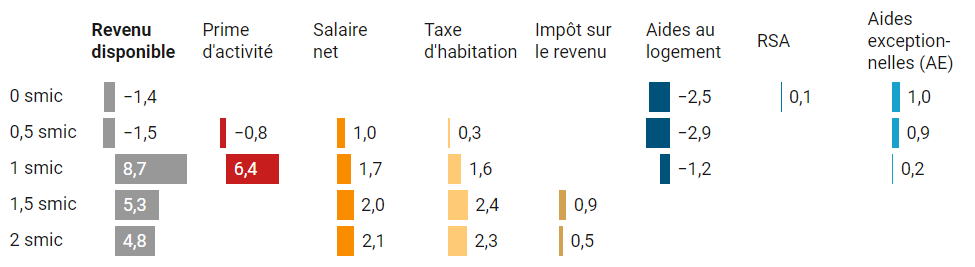
Je place en premier l’indicateur de synthèse, l’évolution du revenu disponible. Ensuite, deux groupes de composantes s’ordonnent dans un sens que le choix des couleurs rehausse.
Il est d’abord manifeste que le revenu disponible a évolué en 5 ans de façon fort différente sous le smic et à partir d’un smic :
- Le maximum, près de 9 % de progression, s’observe pour les personnes seules au niveau du smic ; il est porté par la prime d’activité (forte revalorisation du bonus individuel en 2019).
- Au-dessus du smic, la progression du salaire net et surtout la diminution de la taxe d’habitation et de l’impôt sur le revenu prennent le relais : elles assurent une augmentation de près de 5 %.
- Sous le smic, la baisse sensible des aides au logement n’a pas été compensée par les « aides exceptionnelles » : il en résulte une diminution de pouvoir d’achat de l’ordre de -1,5 %.
Ces trois constats sont bien plus aisément perceptibles qu’avec le graphique originel. Un titre informatif peut les introduire, dans cette version finale :
 Pour aller plus loin* : comme quoi parfois un accent fait toute la différence
Pour aller plus loin* : comme quoi parfois un accent fait toute la différence
L’article Récréation – recréation sémiologique* est apparu en premier sur Icem7.
-
sur Une datavisualisation comme outil d’aide à la décision
Publié: 14 February 2023, 4:15pm CET par Isabelle Coulomb
 (clic pour agrandir)
(clic pour agrandir)
Cet article a pour point de départ l’image ci-contre. Il s’agit d’une affiche au format A4, présentant un outil d’aide à la décision sur le dépistage mammographique du cancer du sein.
Cette affiche s’adresse aux femmes de 50 à 74 ans et montre la balance bénéfices-risques du dépistage du cancer du sein. Je dois avouer que ma première lecture de cette visualisation m’a plutôt ébranlée.
La plupart du temps, les représentations servent à illustrer des études, des rapports ou alimentent des tableaux de bord. En général, ce qu’elles montrent vient conforter ce que l’on savait d’une répartition ou confirmer une tendance. Il est plus rare qu’elles montrent quelque chose d’inattendu.
C’est pourtant le cas avec ce visuel qui met en parallèle les situations « avec » et « sans » dépistage. Cette représentation, nommée « icon array » en anglais, est celle utilisée pour des données concernant des risques. Elle se base sur un nombre de femmes, ici 2 000, plus facile à appréhender qu’un pourcentage, et met en vis à vis les 2 hypothèses « avec » ou « sans » dépistage.
Cette affiche reprend, sur un mode plus communiquant, un autre graphique publié par le Harding Center for Risk Literacy, à partir de données issues d’une revue Cochrane. L’organisation Cochrane est un organisme international indépendant dont la mission est de « favoriser la prise de décisions de santé éclairées par les données probantes, grâce à des revues systématiques pertinentes, accessibles et de bonne qualité et à d’autres synthèses de données de recherche. »
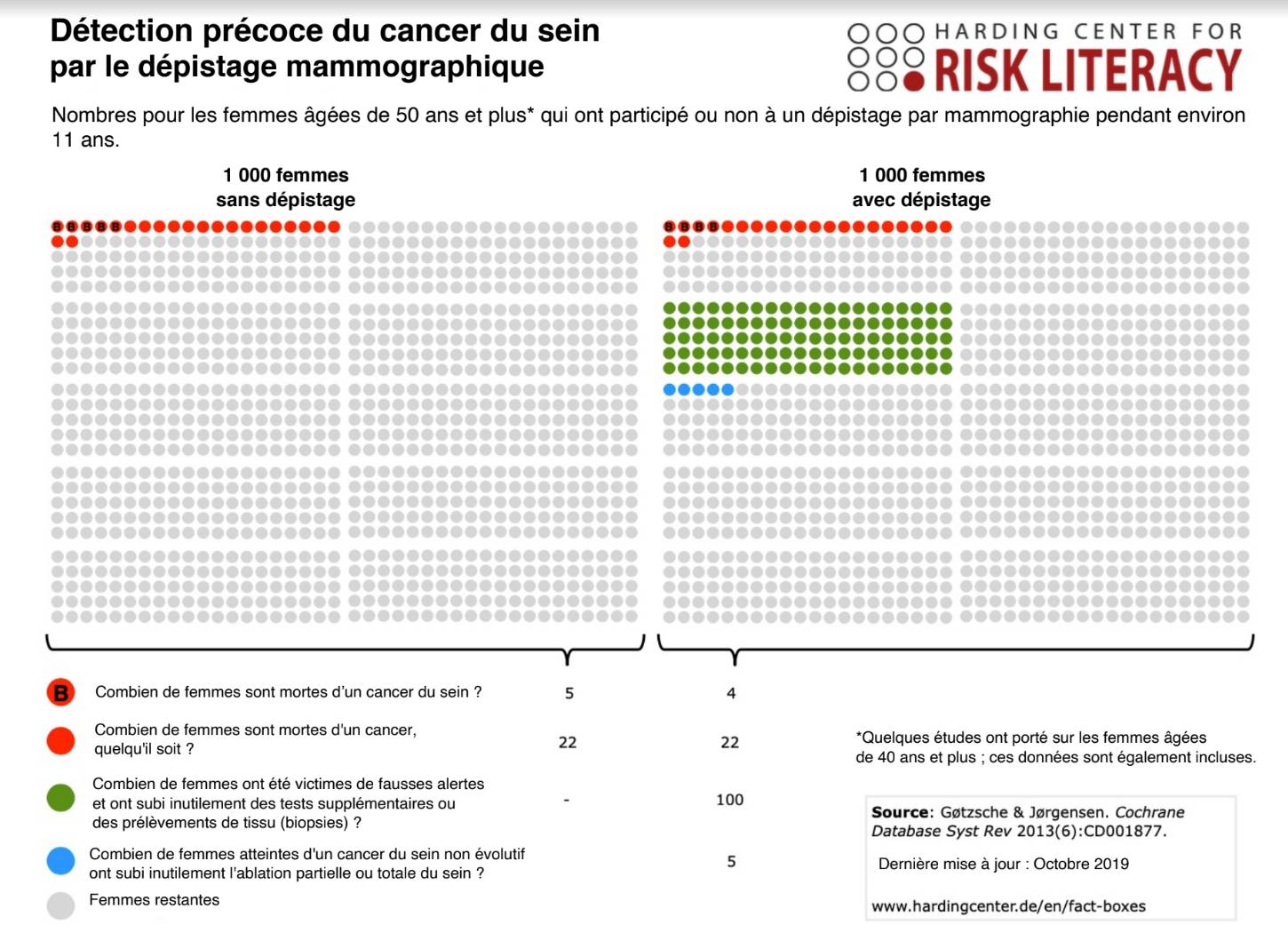
Cela signifie que le nombre de décès par cancer du sein parmi des populations de 1 000 femmes de 50 ans et plus passe de 5 sans dépistage à 4 avec dépistage, soit 1 décès évité. Cela signifie également que sur les 1 000 femmes dépistées, 5 feront l’objet d’un surdiagnostic, c’est-à-dire atteintes d’une tumeur non évolutive.
J’étais, comme certainement beaucoup de personnes, convaincue que la balance penchait largement en faveur du dépistage. Une tumeur décelée à un stade précoce semble plus facile à traiter, sans doute avec des traitements moins lourds. C’est l’intuition de base sur laquelle reposent toutes les campagnes organisées de dépistage du cancer, dans la plupart des pays occidentaux, depuis plus de 20 ans.
Or, avec le recul et les études médicales effectuées ces dernières années, on s’aperçoit que les choses ne sont pas aussi simples. Si la mortalité par cancer du sein a tendance à baisser au fil du temps, difficile toutefois de faire la part entre l’amélioration de l’efficacité des traitements et les effets du dépistage.
Il apparaît cependant que les avantages du dépistage ne compensent pas les risques, dont le principal est celui du surdiagnostic. Les microlésions détectées à la mammographie et traitées en tant que tumeurs cancéreuses n’auraient peut-être pas évolué. Sauf que, une fois repérées, il est impossible de faire comme si elles n’existaient pas.
Pour approfondir le sujet, je renvoie à la lecture d’informations publiées sur le site de l’association Cancer Rose, ou encore à celle du livre de la Dre Cécile Bour, intitulé « Mammo ou pas mammo ? », présenté de façon très pédagogique. Ce livre reprend en détail la construction de cette dataviz, présentée comme outil d’information des femmes face au choix de se faire dépister.
Ne pas confondre dépistage et préventionLe but des campagnes de dépistage est d’inciter les femmes dont l’âge est compris entre 50 et 75 ans à effectuer une mammographie tous les 2 ans. Le message utilise aussi le levier de la peur, puisque le cancer est toujours une maladie potentiellement mortelle. Il joue également sur l’idée qu’en se faisant dépister, on y gagnerait une protection : « ma mammo est OK, c’est bon, je suis tranquille pour 2 ans ! ». Or, il s’agit d’une idée erronée. Une tumeur peut apparaître et se développer entre 2 mammographies ; on parle alors de « cancer de l’intervalle ».
Une véritable prévention consisterait plutôt en mener des actions pour la lutte contre les addictions autorisées telles que le tabac et l’alcool, l’adoption d’une alimentation saine et équilibrée (et moins sucrée), l’habitude d’une activité physique régulière, les pratiques permettant de réduire l’excès de stress. Il y aurait sûrement beaucoup d’intéressantes dataviz à construire pour illustrer ces passionnants sujets.
Comment un message juste peut être invisibilisé
par une communication de masseDepuis les années 90, le mois d’octobre se pare de rose en faveur de la lutte contre le cancer du sein. D’une campagne de collecte de fonds pour la recherche, l’opération glisse vers la diffusion d’un message pour encourager le dépistage. Même parée d’intentions généreuses, cela s’apparente davantage à une opération de marketing.
Face au rouleau compresseur d’une opération disposant d’une forte et ancienne notoriété, difficile de faire entendre une parole différente. Face à un message simple, voire simpliste, il est compliqué d’en présenter un nouveau, plus difficile à expliquer. Là réside une difficulté en communication : ce n’est pas parce qu’un message est juste qu’il sera entendu, même avec de belles dataviz pour l’illustrer avec pédagogie.
Le curieux chemin qui a conduit cette dataviz sous mes yeuxComme le cancer du sein est un sujet qui me concerne personnellement, je me tiens régulièrement informée à son propos : livres, magazines, lettres d’information, sites internet… Pourtant, l’outil d’aide à la décision pour le dépistage du cancer du sein dont il est question ici m’est parvenu par un tout autre canal.
C’est Éric que je remercie de me l’avoir apporté. Il l’a lui-même découvert au cours de sa quête sans fin de nouvelles et intéressantes dataviz. S’intéressant à la question de la mesure du risque, il a lu l’ouvrage Calculated Risks, de Gerd Gigerenzer, dans lequel l’exemple du dépistage du cancer du sein est cité. Comme quoi, la statistique mène à tout.
L’article Une datavisualisation comme outil d’aide à la décision est apparu en premier sur Icem7.
-
sur Parquet devrait remplacer le format CSV
Publié: 29 December 2022, 12:19pm CET par Éric Mauvière
Parquet est un format ouvert de stockage de jeux de données. Créé en 2013 par Cloudera et Twitter, longtemps réservé aux pros du big data, il a beaucoup gagné en popularité ces derniers mois. Bien plus compact, super-rapide à lire, compris par davantage d’outils, Parquet est devenu une alternative crédible à l’omniprésent CSV.
C’est un standard ouvert, comme le CSV, qui prend les données telles qu’elles sont collectées, en simples tables de lignes et de colonnes. Si CSV empile des lignes, Parquet raisonne d’abord en colonne : il les distingue, les catégorise selon leur type, documente leurs caractéristiques fines. Cela rend les données plus faciles à manipuler, plus rapides à parcourir. Et comme elles sont intelligemment compressées, elles prennent bien moins de place de stockage, jusqu’à 10 fois moins qu’un fichier texte délimité !

Parquet sait aussi organiser l’information en groupes de milliers de lignes, voire en fichiers distincts, partitionnés, ce qui accélère les requêtes en les dirigeant plus vite vers les seules données pertinentes pour le traitement désiré. La richesse de son dictionnaire de métadonnées est d’une efficacité redoutable, au niveau de celles des index d’une base de données.
À rebours du paradigme classique de R ou Python, il n’est plus nécessaire de charger toute une table en mémoire pour l’analyser, les données sont lues uniquement là où elles sont utiles, sans aucune conversion ou recopie (c’est le principe de localité).
Des avantages incontestables par rapport à CSVRésumons les deux points forts de Parquet par rapport au format CSV :
- un fichier Parquet a la taille d’un CSV compressé, il prend jusqu’à dix fois moins de place de stockage.
- Il est parcouru, décodé et traité bien plus rapidement par les moteurs de requêtes analytiques.
Dernier avantage : Parquet sait modéliser des types complexes, une colonne comprenant par exemple une structure hiérarchique, un contenu JSON ou le champ géométrique de nos couches SIG (cf. plus loin le projet GeoParquet).
Encore faut-il savoir créer et lire le format ParquetJusqu’à il y a peu, seuls des outils très spécialisés permettaient de générer ou lire le format Parquet. En quelques mois, la donne a radicalement changé. Le vaste projet Apache Arrow, porté à partir de 2016 par Wes McKinney (le créateur de la librairie Python/Pandas) et des dizaines de développeurs majeurs du monde de la datascience, est sans nul doute à l’origine de cette accélération.
La plupart des outils analytiques de la datascience, jusqu’à JavaScript dans le navigateur, lisent les formats Parquet et son jeune cousin Arrow en s’appuyant sur un noyau commun de routines C++ développées dans le cadre du projet Apache Arrow.
Enfin, le formidable moteur portable DuckDB met à la portée de n’importe quel PC les performances d’un moteur de base de données traditionnel sur serveur. DuckDB est désormais, avec des données Parquet, plus rapide qu’une base PostgreSQL pour les requêtes d’analyse.
R offre un environnement efficace pour travailler avec ParquetVotre tableur favori ne propose pas encore de fonction “Enregistrer sous .parquet”, mais cela ne saurait tarder. Pour aller au plus vite, ce classeur Observable en ligne vous permet de le faire : il vous invite à téléverser un CSV, le type des colonnes tel que deviné vous est présenté, vous pouvez télécharger la version .parquet de votre fichier et déjà admirer la belle réduction de taille.
Pour visualiser le contenu d’un fichier Parquet, à l’opposé, Tad est un utilitaire libre multiplateforme efficace et véloce ; il autorise même les filtrages et les agrégations. À vous de jouer !
Les convertisseurs en ligne CSV => Parquet sont toutefois limités : à l’évidence par la taille des CSV que vous pouvez téléverser (quelques dizaines de Mo), et parfois parce qu’ils “typent” incorrectement certaines colonnes : vos codes département ou commune se retrouveront amputés du 0 initial, ou pire, une erreur surviendra parce qu’une colonne de codes département sera intuitée numérique au vu des premières lignes, mais produira une erreur à l’apparition des 2A ou 2B des départements Corse.
Pour l’heure, R offre un environnement très efficace pour créer des fichiers Parquet (Python aussi, sans doute). La librairie R arrow fait l’essentiel du travail, avec vélocité et robustesse.
Le fichier des migrations résidentielles : un CSV de 2 Go qui devient facile à manipuler converti en ParquetNous allons explorer les avantages du format Parquet à partir d’une table respectable de 20 millions de lignes et 33 colonnes. L’Insee met à disposition la base des migrations résidentielles, issue du recensement de la population, sous deux formats, CSV zippé et .dbf. Le format dbf (DBASE) me rappelle de vieux souvenirs, je ne sais pas qui l’utilise encore… J’espère convaincre mes amis de l’Insee de remplacer un jour ces .dbf par des .parquet !
Chaque résident se trouve comptabilisé dans ce tableau qui résulte d’une ventilation selon une trentaine de caractéristiques de la personne ou de son ménage : commune de résidence et résidence un an avant, CSP, tranche d’âge, type de logement, etc.
Une ligne correspond à un croisement de caractéristiques, elle peut regrouper plusieurs personnes. La colonne IPONDI en donne le nombre : comme il s’agit d’une estimation, IPONDI est en pratique une valeur décimale. C’est la seule colonne numérique, toutes les autres sont des catégories qualitatives d’une nomenclature : code commune, code CSP, etc.
Voici un aperçu de ce CSV, on reconnait le délimiteur français (;), et des valeurs qui peuvent commencer par un 0. Ce CSV n’est pas si simple à afficher, car peu de programmes peuvent ouvrir un fichier texte de 2 Go. J’utilise EmEditor dont la version gratuite fait cela en un clin d’œil.
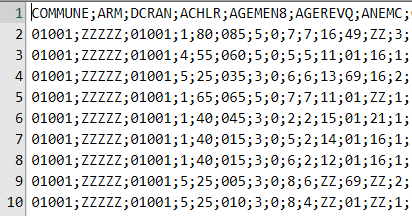
J’ai rencontré plusieurs personnes s’étant bien pris la tête avec un tel fichier. Dans R ou Python, il faut le charger en entier en mémoire, dont l’occupation peut atteindre en pointe les 10 Go : c’est difficilement supportable, et inenvisageable quand l’environnement de travail R est sur serveur et multi-utilisateurs. On s’en sort habituellement en chargeant les données dans une base comme PostgreSQL, ce qui demande pas mal d’écriture, de temps de chargement et oblige à dupliquer les données.
Dans R, les quelques lignes suivantes assurent la conversion vers Parquet, une fois pour toutes, en moins d’une minute.
library(tidyverse) library(arrow) library(data.table) write_parquet( fread("data/FD_MIGCOM_2019.csv") |> mutate(across(-IPONDI, as.factor)), "data/FD_MIGCOM_2019.parquet" ) # data.table::fread est très efficace pour charger des gros CSV (50 s ici) # IPONDI est la seule col. numérique, les autres seront typées factors plutôt que string # write_parquet génére l'équivalent Parquet du CSV en entréeLa version Parquet ne fait plus que 200 Mo, dix fois moins que le CSV de départ. Et elle est directement utilisable avec peu de mémoire, y compris en contexte multi-utilisateurs, aussi facilement qu’une table dans une base de données. En raison de sa nature de standard ouvert, elle a l’avantage supplémentaire de pouvoir être lue par un grand nombre d’outils analytiques.
Les colonnes caractères de nomenclature doivent être typées avec soinAttardons-nous sur le typage des colonnes qualitatives, car c’est un important facteur d’optimisation des fichiers Parquet. Une colonne de type caractère comprenant les codes souvent répétés d’une nomenclature peut être décrite de façon optimisée à partir du dictionnaire de ses valeurs distinctes, et d’un simple n° d’indice, un entier.
Ces colonnes qualitatives “dictionary-encoded” sont bien plus rapides à lire que les colonnes caractères classiques. Pour l’heure, la plupart des outils automatiques de conversion vers Parquet négligent cette structure optimisée. Dans R, dès lors que les “strings” sont convertis en “factors”, qui reposent sur la même idée de dictionnaire, on pourra générer un Parquet bien optimisé. En pratique, les requêtes deviennent deux fois plus rapides encore, cela vaut donc le coup d’y penser !
Clic droit sur FD_MIGCOM_2019.parquet dans mon explorateur de fichiers et Tad m’affiche en deux secondes le contenu de cette table Parquet. Chaque colonne apparait bien typée, et mes codes géographiques n’ont pas été altérés :
 Avec Tad, je peux trier, filtrer sur plusieurs colonnes, et même agréger !
Comprenons comment optimiser une requête en évitant les chargements ou recopies inutiles
Avec Tad, je peux trier, filtrer sur plusieurs colonnes, et même agréger !
Comprenons comment optimiser une requête en évitant les chargements ou recopies inutiles
Revenons dans R avec une première requête simple, compter les habitants de Toulouse qui ont changé de logement en un an :
read_parquet("data/FD_MIGCOM_2019.parquet") |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) # 93151 # 7 sSept secondes peut sembler un bon résultat pour compter ces 93 151 personnes, mais on peut réduire le temps de calcul à une seconde avec cette variante :
read_parquet("data/FD_MIGCOM_2019.parquet", col_select = c(COMMUNE, IRAN, IPONDI)) |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) # 93151 # 1 sCe qui est encore excessif, car la librairie duckdb peut nous faire descendre à 150 ms :
library(duckdb) con <- dbConnect(duckdb::duckdb()) dbGetQuery(con, "SELECT sum(IPONDI) FROM 'data/FD_MIGCOM_2019.parquet' WHERE COMMUNE = '31555' AND IRAN <> '1'") # 93151 # 150 msComment comprendre que l’on arrive à ces performances assez hallucinantes, et l’impact de ces variantes d’écriture sur la charge d’exécution ?
Soyez vigilants avec les pipelines d'instructions chaînéesDans R et dplyr, le chainage des opérations avec le pipe
|>(ou%>%) conduit à séparer les traitements. Ainsi, dans l’écriture suivante;read_parquet()charge en mémoire toute la table avant de la filtrer drastiquement.read_parquet("data/FD_MIGCOM_2019.parquet") |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) # 93151 # 7 sParquet, on l’a vu, encode séparément chaque colonne, si bien qu’il est très rapide de cibler les seules colonnes utiles pour la suite d’un traitement. La restriction suivante apportée au
read_parquet()par uncol_selectdiminue considérablement la charge mémoire, expliquant la réduction du temps d’exécution d’un facteur 7 :read_parquet("data/FD_MIGCOM_2019.parquet", col_select = c(COMMUNE, IRAN, IPONDI)) |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) # 93151 # 1 sPour autant, on n’évite pas la recopie d’une partie du contenu de FD_MIGCOM_2019.parquet (trois colonnes) vers la mémoire de travail de R.
La variante DuckDB est bien plus optimisée : le fichier FD_MIGCOM_2019.parquet est lu et traité en place sans (presque) aucune recopie des données en mémoire :
library(duckdb) con <- dbConnect(duckdb::duckdb()) dbGetQuery(con, "SELECT sum(IPONDI) FROM 'data/FD_MIGCOM_2019.parquet' WHERE COMMUNE = '31555' AND IRAN <> '1'") # 93151 # 150 msCette notion de “zéro-copie” est fondamentale : elle est au cœur du projet Arrow et avant lui de la conception du format Parquet.
Les requêtes compilées sont plus efficacesUne requête considérée globalement est plus facilement optimisable par un moteur intelligent, qui va chercher le meilleur plan d’exécution. C’est comme cela que les moteurs de bases de données relationnelles fonctionnent, prenant en considération par exemple les clés et les index ajoutés aux tables.
Le chainage proposé par dplyr (ou Pandas dans Python) est toutefois plus agréable à écrire ou à relire qu’une requête SQL. Comment réunir le meilleur des deux mondes ?
C’est possible dans R avec
open_dataset()qui plutôt que lire directement le contenu du fichier, se contente d’ouvrir une connexion, prélude à l’écriture d’une chaine d’instructions qui ne sera compilée et exécutée que par l’ordre finalcollect():open_dataset("data/FD_MIGCOM_2019.parquet") |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) |> collect() # 93151 # 1 sCette écriture conduit le moteur (ici arrow et non plus dplyr) à comprendre qu’il n’a pas besoin de lire toutes les colonnes de la table Parquet. Elle n’est pas tout à fait aussi rapide que le SQL direct dans DuckDB, mais elle s’en approche.
Partitionnez pour simplifier le stockage et les mises à jouropen_dataset()a un autre mérite, celui de permettre d’ouvrir une connexion vers un ensemble partitionné de fichiers physiques décrivant la même table de données.La base des migrations fait ici 200 Mo, c’est relativement faible. On considère qu’un fichier Parquet peut raisonnablement aller jusqu’à 2 Go. Au-delà, il y a tout intérêt à construire un dataset partitionné.
La base des courses des taxis de New-York représente 40 Go de données couvrant plusieurs années, et elle se décompose en une partition de dizaines de fichiers Parquet, découpés par année et par mois. Ce découpage est logique, il permet par exemple de ne mettre à jour que les nouveaux mois de données fraichement disponibles. La clé de partitionnement correspond également à une clé de filtrage assez naturelle.
R et Arrow arrivent à requêter l’ensemble de ce dataset en moins d’une seconde (DuckDB fait cinq à dix fois mieux).
Voici comment constituer un dataset Parquet partitionné à partir de la base plus modeste des migrations résidentielles, avec ici un seul champ de partitionnement :
write_dataset(fread("data/FD_MIGCOM_2019.csv") |> mutate(across(-IPONDI, as.character)), path = "data/migres", partitioning = c('IRAN'))Cela crée une petite arborescence de fichiers Parquet :
Nous pouvons désormais comparer les performances de la même requête, sur l’ensemble partitionné en dix fichiers, ou sur le fichier Parquet unique.
La partition accélère naturellement nettement l’exécution (200 ms contre 1 s) car le filtrage suivant sur IRAN correspond à la clé de partitionnement, il n’est donc pas besoin d’ouvrir le second fichier de la partition :
open_dataset("data/migres", partitioning = c('IRAN')) |> filter(COMMUNE == '31555' & IRAN != 1) |> summarise(i = sum(IPONDI)) |> collect() # 93151 # 200 ms open_dataset("data/FD_MIGCOM_2019.parquet") |> filter(COMMUNE == '31555' & IRAN != '1') |> summarise(i = sum(IPONDI)) |> collect() # 93151 # 1 sParquet et DuckDB surpassent les bases de données relationnelles classiquesJe me suis intéressé à cette base de migrations pour conseiller un client peinant à la traiter dans R. Travaillant dans une agence d’urbanisme, il voulait simplement extraire les données pertinentes pour sa métropole. Dans le cas de Toulouse, cela reviendrait à extraire de la base les personnes résidant dans l’EPCI de Toulouse-métropole, ou y ayant résidé l’année précédente.
Je m’appuie pour ce faire sur une table annexe listant les communes de Toulouse Métropole. Il s’agit ensuite d’opérer une double jointure avec la base des migrations, utilisant successivement COMMUNE (code de la commune de résidence) et DCRAN (code de la commune de résidence antérieure).
Grâce à DuckDB, cela s’exécute en 2 secondes, je n’ai même pas eu à me préoccuper d’indexer la table principale. Dans PostgreSQL 15, même après avoir indexé COMMUNE et DCRAN, la requête prend plus de 20 secondes. Ite missa est. DuckDB et Parquet écrasent tout !
library(duckdb) con = dbConnect(duckdb::duckdb()) dbSendQuery(con, "CREATE TABLE COM_EPCI_TOULOUSE AS SELECT * FROM read_csv('data/communes_epci_tls.csv', AUTO_DETECT = TRUE, ALL_VARCHAR = TRUE)") dbGetQuery(con, "SELECT M.* FROM 'data/FD_MIGCOM_2019.parquet' as M LEFT JOIN COM_EPCI_TOULOUSE as C1 ON M.COMMUNE = C1.CODGEO LEFT JOIN COM_EPCI_TOULOUSE as C2 ON M.DCRAN = C2.CODGEO WHERE C1.CODGEO IS NOT NULL OR C2.CODGEO IS NOT NULL ") |> summarise(i = sum(IPONDI)) # 282961 # 2,5 sParquet et Arrow sont deux technologies complémentairesCloudera est l’une des entreprises conceptrices originelles de Parquet, en 2013, avec Twitter et Google. Quand Wes McKinney la rejoint en 2014, lui qui a créé la célèbre librairie Pandas pour Python (équivalent de R/Tidyverse), il comprend vite qu’il y a là un format d’avenir : un modèle de “dataframe” universel, qui peut encore s’optimiser.
Wes rêve d’un format de données qui soit quasi-identique dans sa représentation physique (stockée ou streamée via les réseaux) à sa représentation en mémoire, qui éviterait toutes ces coûteuses opérations de conversion des différents formats textes ou “propriétaires” vers les bits que manipulent les processeurs. Le pire exemple est naturellement celui du CSV, où les nombres sont d’abord stockés comme des chaines de caractères, qu’il faut décoder (“désérialiser”). Avec ce format idéal auquel le projet Apache Arrow donne forme à partir de 2016, les processeurs pourront déplacer des pointeurs vers des sections de bits de données, sans jamais les recopier.
Si Parquet, format binaire “streamable” (découpable en petits morceaux autonomes) orienté colonnes, s’approche de cet idéal, il impose tout de même une forme de décodage avant d’être porté en mémoire, par exemple parce qu’il compresse les données. A contrario, un fichier physique constitué à partir d’un format Arrow prend beaucoup plus de place car il n’est pas compressé.
Parquet a le mérite d’exister et d’être déjà beaucoup utilisé, il est optimisé pour l’archivage et le partitionnement, Arrow pour les traitements, les accès concurrents et les systèmes très distribués.
Wes McKinney a su motiver de très bons programmeurs au sein du projet Apache Arrow pour bâtir à la fois une spécification de format et des librairies partagées, dont une interface très performante entre Parquet et Arrow. Nous voyons – nous humains – des fichiers Parquets, les moteurs analytiques et les réseaux travaillent à partir de leur conversion en structures Arrow.
Dans le même ordre d’idée, plutôt que chacun dans son coin implémente un module de lecture de fichiers CSV, l’effort est désormais centralisé au sein du projet Arrow. R, Python, Rust, Julia, Java et bien d’autres réutilisent les librairies C++ du projet Arrow. Il en existe même un portage pour JavaScript en Web-Assembly : nos navigateurs savent désormais lire des fichiers Arrow ou Parquet (cf. les librairies Arrow.js, Arquero ou duckdb-wasm).
Ainsi, à rebours de la logique intégrée des systèmes de bases de données, il est aujourd’hui possible de rendre indépendants – sans sacrifier la performance – les sources de données et les moteurs analytiques, les uns et les autres pouvant se déployer dans n’importe quel environnement, portable ou distribué.
GéoParquet pourrait renouveler le stockage des données géographiques tabulairesLe cahier des charges de Parquet prévoyait la possibilité de décrire des colonnes stockant des structures complexes, imbriquées, organisées en listes. Parquet est donc tout à fait capable de modéliser des données spatiales, qui complètent typiquement une table de données classique par un champ géométrique.
À la clé, tous les avantages déjà évoqués : stockage réduit, données volumineuses possiblement partitionables, traitements accélérés, nouveau standard plus facilement acceptable par l’industrie, réduisant l’écart entre l’exotisme des formats SIG et les formats de données statistiques plus traditionnels.
Géoparquet permettra de gérer plusieurs systèmes de référence géographique dans le même dataset, voire plusieurs colonnes de géométrie.
Le projet GeoParquet est déjà bien avancé et le format est d’ores et déjà utilisable. Vous pouvez générer des fichiers GeoParquet avec R ou Python, et les ouvrir, grâce à l’intégration GeoParquet dans GDAL, dans la dernière version de QGIS (3.28).
Voici un exemple à partir d’un fichier historique des cultures en Ariège, obtenu au format geopackage. La conversion en GeoParquet aboutit à un fichier deux fois plus petit, de contenu identique. L’équivalent au format Esri shape produirait un ensemble de fichiers de plus de 500 Mo, de taille quasiment 10 fois supérieure.
Les trois versions s’ouvrent dans R ou dans QGIS avec la même rapidité.
library(sf) library(sfarrow) # [https:] # le gpkg pèse 110 Mo # l'équivalent esri shape 540 Mo gpkg_file = "data/filiation_20_07.gpkg" # liste des couches de ce geopackage : 1 seule couche st_layers(gpkg_file) read_sf(gpkg_file) |> st_write_parquet("data/filiation_20_07_d09.parquet") # le geoParquet généré pèse 60 Mo
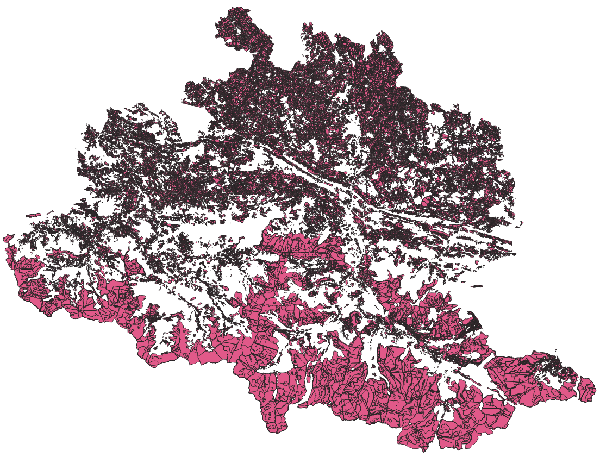 Un fond de carte GeoParquet ouvert dans QGIS
Pour résumer
Un fond de carte GeoParquet ouvert dans QGIS
Pour résumer
Parquet est un standard ouvert particulièrement bien adapté pour stocker des données volumineuses, et traiter des fichiers avec beaucoup de colonnes, ou comprenant des nomenclatures.
Sa structure astucieusement croisée et documentée en colonnes et en groupes de lignes exploite à merveille les capacités des processeurs modernes : parallélisation, vectorisation, mise en cache. Elle est aussi compatible avec une organisation partitionnée ou une distribution “streamée” des données.
Comme Arrow, Parquet épouse le principe de localité : rapprocher les process des données, les lire là où elles se trouvent, plutôt que recopier les données dans des espaces de traitement spécialisés. C’est l’objectif du “zéro-copie” : il permet de travailler avec des données plus volumineuses que la mémoire disponible et de dépasser ce goulet d’étranglement classique, bien connu des praticiens de R ou Python.
GéoParquet est en passe de résoudre le casse-tête de l’hétérogénéité des formats SIG, de leur apporter de nouveaux gains de performance et de substantielles économies de stockage.
Un des formats majeurs de la boite à outils Arrow, Parquet est la face émergée d’un nouvel écosystème décloisonnant les données et les process qui les traitent, complémentaire des bases de données relationnelles traditionnelles.
Si la plupart des outils d’analyse de données lisent désormais les fichiers Parquet, le nouveau moteur portable DuckDB est tout spécialement optimisé pour en tirer le meilleur parti. Il démontre des performances extraordinaires, qui ne cessent de croitre, tirées par la créativité et l’enthousiasme d’une belle communauté de développeurs open-source.
Pour aller plus loinPrésentation du format
- Apache Parquet pour le stockage de données volumineuses
- What is the Parquet File Format?
- What Is Apache Parquet?
- Parquet file format
Différences Arrow / Parquet
- Difference between Apache parquet and arrow
- [https:]]
- The Columnar Roadmap: Apache Parquet and Apache Arrow
Pour jouer avec Parquet
- Tad: A better way to view & analyze data
- Online, Privacy-Focused Parquet File Viewer
- Dbeaver: Universal Database Tool
- How to set up DBeaver SQL IDE for DuckDB
- DuckDB redonne une belle jeunesse au langage SQL
- Package R Parquetize
Le projet Arrow
- Apache Arrow: High-Performance Columnar Data Framework (Wes McKinney)
- Apache Arrow: a cross-language development platform for in-memory analytics
L’article Parquet devrait remplacer le format CSV est apparu en premier sur Icem7.
-
sur across() est plus puissant et flexible qu’il n’y parait
Publié: 3 November 2022, 5:44pm CET par Éric Mauvière
La librairie R dplyr permet de manipuler des tables de données par un élégant chainage d’instructions simples : select, group_by, summarise, mutate… à la manière du langage de requête SQL.
dplyr est le module central de l’univers tidyverse, une collection cohérente de librairies spécialisées et intuitives, ensemble que l’on a souvent présenté comme le symbole du renouveau de R.
Arrivée à maturité il y a deux ans avec sa version 1.0, dplyr accueillait en fanfare l’intriguant élément “across()”, destiné à remplacer plus d’une dizaine de fonctions préexistantes. across() est ainsi devenu l’emblème de la version toute neuve de la librairie emblématique du “R moderne” !
Je l’ai constaté, across() est encore insuffisamment compris et utilisé, tant il implique une façon de penser différente de nos habitudes d’écriture. Cet article vous présente, au travers de 7 façons de le mettre en œuvre, sa logique assez novatrice. Il s’adresse en priorité à des lecteurs ayant déjà une connaissance de R et dplyr.

across() permet de choisir un groupe de colonnes dans une table, et de leur appliquer un traitement systématique, voici sa syntaxe générique :

Je vais présenter l’usage d’across() avec la base Gaspar, qui décrit les risques naturels et industriels auxquels chaque commune française est exposée. J’en ai préparé un extrait décrivant sept risques pour la métropole. Chaque colonne indicatrice de risque vaut 0 ou 1 (présence).
library(tidyverse) tb_risques = read_delim(str_c(" [https:] "20221027-104756/tb-risques2020.csv"), col_types = c('reg' = 'c')) # A tibble: 34,839 x 11 com dep reg lib_reg risq_inond risq_seisme risq_nucleaire risq_barrage risq_industriel risq_feux risq_terrain <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> 1 01001 01 84 Auvergne-Rhône-Alpes 1 0 0 0 0 0 0 2 01002 01 84 Auvergne-Rhône-Alpes 0 1 0 0 0 0 1 3 01004 01 84 Auvergne-Rhône-Alpes 1 1 0 0 0 0 1 4 01005 01 84 Auvergne-Rhône-Alpes 0 0 0 0 0 0 0 5 01006 01 84 Auvergne-Rhône-Alpes 0 1 0 0 0 0 0 6 01007 01 84 Auvergne-Rhône-Alpes 1 1 0 1 0 0 0 7 01008 01 84 Auvergne-Rhône-Alpes 0 1 0 0 0 0 0 8 01009 01 84 Auvergne-Rhône-Alpes 1 1 0 0 0 0 0 9 01010 01 84 Auvergne-Rhône-Alpes 1 1 0 1 1 0 0 10 01011 01 84 Auvergne-Rhône-Alpes 0 1 0 0 0 0 1 # ... with 34,829 more rowsVoici par exemple la traduction cartographique de la colonne risq_barrage (risque de rupture de barrage, en bleu la modalité 1) :
across() cible un ensemble de colonnes avec la même syntaxe que celle utilisée dans un select().
Rappelons les mécanismes de la sélection de colonnes dans dplyr – ils sont nombreux et astucieux – au travers de quelques exemples :
# "tidy selection" : offre plein de possibilités pour spécifier des colonnes # à partir de leur nom, de leur type, de leur indice... tb_risques |> select(codgeo, starts_with('risq_')) tb_risques |> select(where(is.character), risq_nucleaire) # on peut même intégrer une variable externe # ces 3 variables constituent chacune une liste de noms de colonnes de risques c_risques = tb_risques |> select(starts_with('risq_')) |> names() c_risques_naturels = str_c("risq_", c('inond','seisme','terrain')) c_risques_humains = str_c("risq_", c('barrage','industriel','feux','nucleaire')) tb_risques |> select(1:3, all_of(c_risques_humains)) # note : ceci fonctionne, mais plus pour longtemps : avertissement "deprecated" tb_risques |> select(codgeo, c_risques_humains) # il faut donc entourer toute variable (simple ou liste de colonnes) avec all_of()across() utilise les mêmes mécanismes de sélection concise (tidy selection) à partir d’indices, de portions de noms ou via les types de colonnes : caractère, numérique, etc.
La “tidy selection” ne fonctionne pas partout dans dplyr (ou sa copine tidyr) : seuls quelques verbes en tirent parti comme select(), pivot_longer(), unite(), rename_with(), relocate(), fill(), drop_na() et donc across().
À l’inverse, group_by(), arrange(), mutate(), summarise(), filter() ou count() n’autorisent pas la tidy selection (group_by(1,2) ou arrange(3) ne fonctionnent pas).
Une bonne part de la magie d’across(), on va le voir, consiste à amener la souplesse de la tidy selection au sein de ces verbes qui normalement ne l’implémentent pas (ce “pontage” est aussi dénommé bridge pattern).
1 - rowSums() et across()Voici un premier exemple avec la fonction de sommation de colonnes rowSums(), qui précisément n’est pas compatible avec la tidy selection.
Pour sommer des colonnes, on devait auparavant les écrire toutes (dans un mutate()), ou utiliser une obscure syntaxe associant rowSums() avec un select() et un point.
across() simplifie tout cela :
# on peut sommer des colonnes à la main avec mutate() tb_risques |> mutate(nb_risques = risq_inond + risq_seisme + risq_feux + risq_barrage + risq_industriel + risq_nucleaire + risq_terrain) # ou avec rowSums() tb_risques %>% mutate(nb_risques = rowSums(select(., starts_with('risq_')))) # note : cette syntaxe complexe, où le . rappelle la table en cours, # ne fonctionne qu'avec l'ancien "pipe" %>% # >>> on peut faire plus simple avec across() tb_risques |> mutate(nb_risques = rowSums(across(starts_with('risq_')))) # ou avec une liste de colonnes stockée dans une variable c_risques_humains tb_risques |> mutate(nb_risques = rowSums(across(all_of(c_risques_humains)))) # pour mémoire : cette alternative rowwise() est À EVITER ! # les performances sont catastrophiques (30 s contre 0,5 s ci-dessus) : tb_risques |> rowwise() |> mutate(nb_risques = sum(c_across(all_of(c_risques_humains))))Cette première utilisation d’across() est basique (et méconnue), elle ne fait intervenir que le premier paramètre d’across() : une sélection de colonnes.
rowSums() (ou sa cousine rowMeans()) conduisent le traitement souhaité (somme ou moyenne) sur ces colonnes.
2 - summarise() et across()Celles et ceux qui ont déjà joué avec across() l’ont probablement employé dans le contexte d’un summarise(), par exemple pour sommer “vite fait” tout un paquet de colonnes numériques.
across() invite à spécifier les colonnes visées, puis le traitement à opérer sur chacune d’entre elles. De façon optionnelle, les colonnes produites par le calcul sont renommées pour mieux traduire l’opération conduite, avec par exemple ajout d’un préfixe ou d’un suffixe aux noms de colonne d’origine.

# série de 5 écritures équivalentes pour compter les communes à risque # avec across et une fonction toute simple tb_risques |> summarise(across(starts_with('risq_'), sum)) # across et une fonction "anonyme", avec une option tb_risques |> summarise(across(where(is.numeric), \(r) sum(r, na.rm = TRUE))) # R 4.1 # across avec l'écriture "en toutes lettres" de la fonction tb_risques |> summarise(across(5:last_col(), function(r) { return( sum(r, na.rm = TRUE) ) })) # across et une fonction anonyme, écriture ultra concise tb_risques |> summarise(across(-(1:4), ~sum(., na.rm = TRUE))) # across avec une variable listant les colonnes tb_risques |> summarise(across(all_of(c_risques), ~sum(., na.rm = TRUE))) # across avec une autre variable et une règle de renommage tb_risques |> summarise(across(all_of(c_risques_humains), \(r) sum(r, na.rm = TRUE), .names = "nb_{col}")) # A tibble: 1 x 4 nb_risq_barrage nb_risq_industriel nb_risq_feux nb_risq_nucleaire <dbl> <dbl> <dbl> <dbl> 3731 1819 6565 480across() opère un renversement de l’ordre naturel, habituel des opérations, tout en les séparant sous forme de paramètres distincts, de nature très différente : liste (de colonnes) et fonctions (de traitement et de renommage).
Considérez les deux écritures suivantes, la première correspond à nos habitudes de pensée, la seconde, avec across(), introduit une nouvelle façon de modéliser les traitements. Elle n’est pas immédiate à intégrer, elle peut même paraitre abstraite, peu intuitive. Pourtant, l’absorber, franchir ce pas logique, permet de s’ouvrir à de nouvelles dimensions d’analyse et de programmation (dite “fonctionnelle”).

Autre caractéristique fondamentale d’across() : le même traitement est répété indépendamment pour chaque colonne( seule une fonction très particulière comme rowSums() permet de combiner plusieurs colonnes dans une même opération).

Un bouquet de fonctions (par exemple sum et mean) peut être appelé dans un seul across(), en utilisant une liste.
Enfin, comme on l’a déjà souligné, il est très facile avec across() d’injecter des variables dans une chaine de requête, et donc d’écrire ses propres fonctions pour raccourcir et simplifier ses scripts.
3 - mutate() et across()mutate() avec across() suit la même logique qu’un summarise(), tout en préservant le niveau de détail (le nombre de lignes) de la table d’origine. across() permet typiquement de recoder ou “normaliser” (convertir en % par exemple) un ensemble de colonnes.
Les colonnes transformées sont souvent renommées, pour plus de clarté, les colonnes d’origine pouvant être conservées, ou non.
Recodage :
# recoder des colonnes : 1 => 'exposée', 0 => '' tb_risques |> mutate(across(starts_with('risq_'), \(r) ifelse(r == 1, 'exposée', ''))) # recoder selon le risque, 1 => 'barrage', 'inond', 'nucleaire'.... # cur_column() indique le nom de la colonne en cours de lecture tb_risques |> mutate(across(starts_with('risq_'), \(r) ifelse(r == 1, str_sub(cur_column(), 6), ''))) |> select(com, all_of(c_risques_naturels)) # A tibble: 34,839 x 4 com risq_inond risq_seisme risq_terrain <chr> <chr> <chr> <chr> 1 01001 "inond" "" "" 2 01002 "" "seisme" "terrain" 3 01004 "inond" "seisme" "terrain" 4 01005 "" "" "" 5 01006 "" "seisme" "" # ... with 34,834 more rowsNormalisation :
# conversion en % : 100 * nb de communes exposées / nb total de communes tb_risques |> summarise(across(starts_with('risq_'), sum), nb_com = n()) |> mutate(across(starts_with('risq_'), \(r) 100 * r / nb_com)) # A tibble: 1 x 8 risq_inond risq_seisme risq_nucleaire risq_barrage risq_industriel risq_feux risq_terrain nb_com <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> 59.2 25.1 1.38 10.7 5.22 18.8 53.8 34839 # conversion en % avec renommage tb_risques |> summarise(across(starts_with('risq_'), sum), nb_com = n()) |> mutate(across(starts_with('risq_'), \(r) 100 * r / nb_com, .names = "part_{str_sub(col, 6)}"), .keep = "unused") # conversion en % avec une variable pour la liste des colonnes à traiter tb_risques |> summarise(across(all_of(c_risques_humains), sum), nb_com = n()) |> mutate(across(all_of(c_risques_humains), \(r) 100 * r / nb_com, .names = "part_{str_sub(col, 6)}"), .keep = "unused") # éliminer les colonnes d'origine # A tibble: 1 x 4 part_barrage part_industriel part_feux part_nucleaire <dbl> <dbl> <dbl> <dbl> 10.7 5.22 18.8 1.384 - filter() et 2 variantes d'across() : if_all() et if_any()Que veut dire filtrer une table en considérant tout un ensemble de colonnes ?
Je peux vouloir filtrer cette table des risques de deux façons différentes : dégager les communes cumulant tous les risques, ou celles présentant au moins un risque.
Cette dualité a conduit les concepteurs d’across() à en décliner deux variantes : if_all(), qui reprend la logique d’across() (même condition pour toutes les colonnes), et if_any(), qui ne s’intéresse qu’à la possibilité qu’une colonne au moins remplisse la condition définie par la fonction anonyme.
Par souci de cohérence, across(), étant l’équivalent de if_all(), devient au sein d’un filter() déconseillé (déprécié) au profit de if_all().
# across() est encore utilisable dans filter(), mais plus pour longtemps tb_risques |> filter(across(starts_with('risq_'), \(r) r == 1)) # un avertissement invite à utiliser plutôt if_all() tb_risques |> filter(if_all(starts_with('risq_'), \(r) r == 1)) |> select(com) # A tibble: 4 x 1 com <chr> 1 13039 2 13097 3 42056 4 84019 # 4 communes sont exposées aux 7 risques : Fos-sur-Mer, St-Martin-de-Crau, # Chavanay et Bollène # if_any pour une condition vérifiée sur une colonne au moins # parmi celles décrites dans une variable c_risques_humains tb_risques |> filter(if_any(all_of(c_risques_humains), \(r) r == 1)) |> select(com, all_of(c_risques_humains)) # plus de 10 000 communes exposées à un risque humain # A tibble: 10,679 x 5 com risq_barrage risq_industriel risq_feux risq_nucleaire <chr> <dbl> <dbl> <dbl> <dbl> 1 01007 1 0 0 0 2 01010 1 1 0 0 3 01014 0 1 0 0 4 01024 0 1 0 0 5 01027 1 1 0 0 # ... with 10,674 more rows5 - mutate() et if_all() ou if_any()if_all() et if_any() ne sont pas réservés au contexte d’un filter(), il est possible de les utiliser avec un mutate(), matérialisant dans une nouvelle colonne le respect d’une condition.
Je pourrai ainsi comparer les communes à risque avec les communes sans aucun risque.
tb_risques |> mutate(risque_humain = if_any(all_of(c_risques_humains), \(r) r == 1)) |> select(com, all_of(c_risques_humains), risque_humain) # A tibble: 34,839 x 6 com risq_barrage risq_industriel risq_feux risq_nucleaire risque_humain <chr> <dbl> <dbl> <dbl> <dbl> <lgl> 1 01001 0 0 0 0 FALSE 2 01002 0 0 0 0 FALSE 3 01004 0 0 0 0 FALSE 4 01005 0 0 0 0 FALSE 5 01006 0 0 0 0 FALSE # ... with 34,834 more rows # variante : un comptage simple tb_risques |> count(if_any(all_of(c_risques_humains), \(r) r == 1)) |> select(`exposition risque humain` = 1, nb_com = n) # A tibble: 2 x 2 `exposition risque humain` nb_com <lgl> <int> 1 FALSE 24160 2 TRUE 106796 - group_by() et across()group_by() ne permet pas d’utiliser directement la “tidy selection”, across(), dans sa syntaxe la plus simple (sans fonction), lui apporte cette souplesse d’écriture.
# regroupement selon les colonnes d'indice 2 à 4 tb_risques |> group_by(across(2:4)) |> summarise(across(where(is.numeric), sum)) # regroupement selon les colonnes de type caractère, sauf la 1ère tb_risques |> group_by(across(where(is.character) & -1)) |> summarise(across(where(is.numeric), sum)) tb_risques |> group_by(across(where(is.character) & -1)) |> summarise(across(all_of(c_risques_humains), sum)) # A tibble: 96 x 7 # Groups: dep, reg [96] dep reg lib_reg risq_barrage risq_industriel risq_feux risq_nucleaire <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> 1 01 84 Auvergne-Rhône-Alpes 70 56 0 20 2 02 32 Hauts-de-France 0 48 0 0 3 03 84 Auvergne-Rhône-Alpes 73 5 31 0 4 04 93 Provence-Alpes-Côte d'Azur 53 14 173 1 5 05 93 Provence-Alpes-Côte d'Azur 17 37 162 0 # ... with 91 more rows
Il devient également possible, avec across(), d’injecter une variable dans un group_by(), comme on va le voir dans la section suivante.
7 - arrange() et across()Avec across(), le verbe de tri arrange() gagne lui-aussi en souplesse d’écriture.
# cette écriture ne marche pas, arrange n'est pas "tidy select" compatible tb_risques |> arrange(3) # mais avec across, ça marche tb_risques |> arrange(across(3)) # on peut utiliser desc à titre de fonction tb_risques |> arrange(across(3, desc))
Ce bloc plus riche considère, par département, la part de communes exposée au risque rupture de barrage. Le type de risque devient un paramètre, prélude à l’écriture possible d’une fonction.
# deux variables pour cibler un risque risq = 'barrage' col_risq = str_glue("risq_{risq}") # risque barrage par département tb_risques |> group_by(dep) |> summarise(across(all_of(col_risq), sum), nb_com = n()) |> mutate(across(all_of(col_risq), \(r) 100 * r / nb_com, .names = "part_{.col}"), .keep = 'unused') |> # on ne garde pas les variables d'origine arrange(across(str_glue("part_risq_{risq}"), desc)) # avec str_glue(), across() peut même décoder une formule ! # A tibble: 96 x 2 dep part_risq_barrage <chr> <dbl> 1 13 46.2 2 46 38.0 3 38 34.0 4 10 32.7 5 19 30.7 # ... with 91 more rows # Bouches-du-Rhône, Lot, Isère, Aube et Corrèze ont la plus forte # part de communes exposées au risque de rupture de barrageCette dernière variante utilise across() à tous les étages : group_by(), summarise(), mutate() et arrange() !
# nouvelle variable pour les colonnes de regroupement # on veut pouvoir regrouper soit par département, soit par région # (avec le libellé associé) nivgeo = c("reg","lib_reg") tb_risques |> group_by(across(all_of(nivgeo))) |> summarise(across(all_of(col_risq), sum), nb_com = n(), .groups = 'drop') |> # raccourci pour ungroup() mutate(across(all_of(col_risq), \(r) 100 * r / nb_com, .names = "part_{.col}"), .keep = 'unused') |> arrange(across(str_glue("part_risq_{risq}"), desc)) # A tibble: 13 x 3 reg lib_reg part_risq_barrage <chr> <chr> <dbl> 1 84 Auvergne-Rhône-Alpes 21.6 2 76 Occitanie 20.0 3 93 Provence-Alpes-Côte d'Azur 19.6 4 75 Nouvelle Aquitaine 13.1 5 44 Grand-Est 10.3 # ... with 8 more rowsCes 7 exemples démontrent la puissance et la flexibilité d’across(), qui nous permet d’écrire des programmes plus élégants, plus flexibles.
Ayez le réflexe DRY : Don’t Repeat Yourself. Dès que vous détectez une répétition dans vos scripts, la même formule réécrite pour x colonnes, des blocs de code qui ne diffèrent que par quelques variables, il y a de fortes chances qu’across() vous rende service, vous aide à écrire des scripts plus robustes, lisibles et paramétrables.
across() fait intervenir, le plus souvent, l’écriture d’une petite fonction (dite anonyme), matérialisant l’opération à répéter, qui peut ainsi être optimisée.
Il vous invite à écrire vos propres fonctions plus globales, sans en passer par la complexité des {{}}, enquos() et autres :=, toutes syntaxes assez vilaines, impossibles à retenir (et à expliquer).
Pour aller plus loin- Column-wise operations
- Why did it take so long to discover across() ?
- Bridge patterns
- across : appliquer des fonctions à plusieurs colonnes
- Mon top 7 des évolutions récentes de tidyverse
L’article across() est plus puissant et flexible qu’il n’y parait est apparu en premier sur Icem7.
-
sur Divagations à propos du temps
Publié: 21 October 2022, 9:34pm CEST par Isabelle Coulomb
 Bonjour, je suis le temps.
Bonjour, je suis le temps.Donnée universelle, avec l’implacable régularité du métronome, je passe.
Immuable et inexorable, j’avance de la même manière, partout, toujours.
Je suis la richesse la plus équitablement répartie : 60 secondes par minute, 24 heures par jour, 12 mois par an, c’est pareil pour tout le monde.
Ce qui change, pour vous autres, êtres humains, c’est la perception que vous avez de moi. Dans l’ennui, la peine ou la douleur, je vous semble long. Mais dès que la joie fleurit, vous trouvez que je passe trop vite.
Dans l’époque frénétique et connectée où vous vivez, où les sollicitations pleuvent de toutes parts pour beaucoup d’entre vous, vous êtes nombreux à dépenser beaucoup d’énergie à courir après les aiguilles de la montre. Je suis toujours présent, et pourtant, je vous manque.
Cependant, je reste bien toujours le même. La seule inconnue, pour chacun de vous, c’est de savoir quand cesserez-vous de voir l’horloge tourner. Moi, de toute façon, je continuerai, jusqu’à la fin des temps…
L’horloge ne cesse jamais de tourner
Évidemment, depuis la nuit des temps, on a cherché à me mesurer. De calendriers antiques en cadrans solaires, on a voulu me quantifier avec toujours plus de précision, jusqu’aux plus précises horloges atomiques. Cependant, difficile de savoir exactement quand j’ai commencé. Et, question encore plus vertigineuse, savoir si je finirai un jour.
La statistique, qui se penche sur tous les domaines de la connaissance, n’a pas manqué de s’intéresser à moi. Le moindre indicateur ne fournit aucune information utile s’il n’est pas daté. Dire que la population totale de la ville de Toulouse est de 498 596 habitants ne présente un intérêt qu’en précisant en 2019.
Et cela prend une toute autre dimension si l’on ajoute que cette population était de 466 219 en 2013. Cela permet au statisticien de faire quelque chose dont il raffole : une comparaison
 ! Et même de calculer une évolution
! Et même de calculer une évolution  ! Entre 2013 et 2019, la population toulousaine a augmenté de près de 7 %.
! Entre 2013 et 2019, la population toulousaine a augmenté de près de 7 %.Le taux d’évolution est assez simple à calculer : Te = ((Va-Vd) / Vd) * 100 = (Va/Vd – 1) * 100, où Va et Vd sont les valeurs de départ et d’arrivée. Il y a des calculateurs en ligne qui font le calcul tout seuls. Un peu plus compliqué, le taux d’évolution annuel moyen est, comme son nom l’indique, une moyenne par an. Dans cet exemple, il vaut 1,13 %. La formule pour le calculer est assez jolie, même si elle peut intimider les personnes réticentes aux mathématiques : Tem = (((Va/Vd)**(1/n)) – 1) * 100, où n est le nombre de périodes, 6 dans cet exemple.
 La boîte à outils du statisticien
La boîte à outils du statisticienAvec dans sa trousse à outils, ces 2 formules, ainsi que les calculs d’une moyenne simple et d’un pourcentage, le statisticien dispose de la base indispensable. Ensuite, une grande partie de son art réside dans savoir représenter les données qu’il a calculées, pour pouvoir les interpréter.
Une donnée, pour avoir du sens, doit être datée. Elle en prend davantage s’il est possible de la comparer. Et moi, le temps, je déploie tout mon potentiel lorsque le statisticien dispose de toute une série de données. L’Insee consacre tout une rubrique de son site aux séries chronologiques. Dans la rubrique consacrée à la population, on trouve des séries remontant jusqu’à 1876.
La série chronologique va de pair avec sa représentation la plus naturelle : la courbe d’évolution. Peu importe l’unité de mesure, on me couche sur l’axe des abscisses. Et on mesure la donnée représentée sur l’axe des ordonnées. Par exemple, l’électrocardiogramme mesure l’activité électrique du cœur.
Plutôt qu’une courbe d’évolution, dans les cas où le nombre de périodes de la série n’est pas trop important, un diagramme en barres verticales peut opportunément être utilisé. Et si les intervalles sont d’inégales amplitudes, le statisticien aura recours à l’histogramme, dans lequel la grandeur représentée est proportionnelle à la surface de chaque barre.
Un autre moyen efficace de représenter des données temporelles est de construire une série de petits graphiques, un pour chaque période (sous réserve que le nombre de périodes ne soit pas trop grand). Les outils numériques rendent aussi possible la construction d’animations temporelles, qui peuvent produire des effets visuels éloquents.
La première courbe d’évolution de l’histoire
Cette forme de représentation semble aujourd’hui une évidence tant on la rencontre un peu partout. Cela n’a pas toujours été le cas. On doit ses premières apparitions, dans les années précédant la Révolution française, au génial et inventif William Playfair. Le même a également eu l’idée des diagrammes en barres et circulaires.
Cela s’applique bien en cartographie statistique : créer une série de cartes thématiques et les afficher successivement rend visible l’évolution du phénomène cartographié dans le temps et dans l’espace. Ceci est par exemple mis en œuvre dans l’application Géodes, de Santé Publique France, pour suivre l’évolution hebdomadaire et quotidienne des taux d’incidence, de positivité et de dépistage du Covid-19 (données de laboratoires Si-Dep).
La distance, la vitesse et moiRevenons pour finir sur cette bonne vieille courbe d’évolution. En voici un exemple très éloquent :
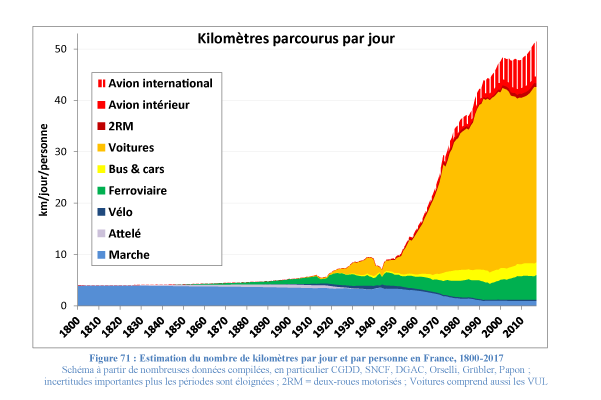
Il provient de la thèse de doctorat intitulée « Les transports face au défi de la transition énergétique. Explorations entre passé et avenir, technologie et sobriété, accélération et ralentissement. », soutenue en novembre 2020, par Aurélien Bigo. Il représente l’évolution de la distance parcourue par jour. Il est plus conçu pour les lecteurs experts d’un rapport de thèse que pour le public large d’un journal, par exemple. On imagine bien qu’Éric Mauvière, expert en datavisualisation, aurait quelques petites remarques sur la présentation de ce graphique, sur les titres, les légendes, la typographie, le choix des couleurs… Il est déjà très intéressant tel qu’il est.
Il montre quelle place absolument prépondérante a pris la voiture individuelle dans les modes de déplacement en à peine un siècle. Les progrès technologiques, permis par l’abondance de sources d’énergie, ont considérablement augmenté les vitesses de déplacement. Des vitesses plus élevées permettent d’aller plus loin ou de mettre moins de temps. Visiblement, la priorité a été donnée à aller plus loin plutôt qu’à gagner du temps. Je ne sais pas vous, mais moi, cela me fais réfléchir sur l’importance que l’on m’accorde, ou pas…
L’article Divagations à propos du temps est apparu en premier sur Icem7.
-
sur Le syndrome de l’empilement
Publié: 4 September 2022, 2:04pm CEST par Éric Mauvière
Les graphiques en barres empilées sont notoirement peu lisibles, la presse le sait et les évite. Des alternatives plus efficaces existent. Nous les rencontrons pourtant partout dans la production institutionnelle : pas une étude statistique, pas un rapport d’activité où l’on ne subisse ces guirlandes de bâtons multicolores[1], leurs légendes extensibles et leurs inévitables aides au déchiffrage.
Prenons deux exemples publiés la semaine dernière : à chaque fois la matière est intéressante, mais le traitement graphique la dessert.
Vous avez 5 secondes pour capter une première idée simple qui vous surprenne et vous donne envie d’aller plus loin dans l’exploration (j’aime bien ce test basique, que m’a confié un data-journaliste).
Publication de la Drees : Impact des assurances complémentaires santé et des aides sociofiscales à leur souscription sur les inégalités de niveau de vie (septembre 2022)
Publication de l’Insee : Un habitant sur sept vit dans un territoire exposé à plus de 20 journées anormalement chaudes par été dans les décennies à venir (août 2022)
 Un graphique inutile car trop complexe, dans une étude par ailleurs fort intéressante
Un graphique inutile car trop complexe, dans une étude par ailleurs fort intéressante
Vous n’y êtes pas arrivés ? Ou vous avez seulement vu dans le 1er exemple que la CMU concerne surtout les plus précaires, ce qui ne vous a rien appris ? Ne stressez pas, c’est normal. Ces graphiques n’offrent pas de point d’entrée évident, et l’absence de titre informatif ne fait rien pour les sauver. Faute de base horizontale ou verticale commune, la plupart des séries (identifiées par une même couleur) ne sont pas signifiantes « dans l’instant minimal de vision », pour reprendre les mots de Jacques Bertin, le grand sémiologue français.
Considérez par exemple la série rose pâle ci-dessus : présente-t-elle ou non des variations significatives ? Cela ne saute pas aux yeux. Seules les séries jaunes et violettes, aux extrémités, sont rapidement évaluables, disposant d’un solide point d’appui à gauche ou à droite.
Souvent, la juxtaposition de couleurs vives complique l’effort de sélection que l’œil doit conduire pour isoler chaque concept. On le constate dans le premier graphique, par ailleurs constellé de chiffres sans grand intérêt. Enfin, qui souffre de déficience visuelle, même légère, sera peu à la fête, compte tenu du nombre de couleurs à distinguer ou de l’emploi abusif de l’opposition rouge / vert.
Le second graphique (Insee) est un peu plus amical : moins de chiffres, des couleurs plus douces, des axes plus explicites. Mais je n’en retiens rien – si je refuse d’y passer plus de 20 secondes – trop de catégories sans contraste évident surchargent ma mémoire de travail.
Désempilez et simplifiez en catégorisantRevenons aux données publiées par la Drees. Comment leur rendre mieux justice ?
Il s’agit de dépenses de santé et des différentes aides soutenant les ménages selon leur niveau de vie : cela concerne et parle – a priori – à tout le monde. Quels sont les principaux contrastes, les lois et les ordres de grandeur à retenir ?
La science de la sémiologie graphique, formalisée par Jacques Bertin et Edward Tufte, pour ne citer que les plus connus, nous donne les règles à suivre, dont voici une mise en musique.
Les variables visuelles les plus efficaces sont la position dans le plan et la longueur rapportée à une base commune. L’organisation du diagramme suivant, en colonnes, et ses barres horizontales alignées à gauche répondent à ces critères.
La loi de proximité issue de la théorie de la Gestalt[2] privilégie le légendage direct de chaque série. Il est naturellement assuré par la disposition tabulaire : plus besoin d’une légende déportée obligeant à des allers et retours visuels fastidieux.
La théorie de la charge cognitive (que Bertin anticipe) encourage les tris logiques et l’extraction de grandes catégories : on oppose ici de gauche à droite les aides ciblant les niveaux de vie modestes à celles concernant les plus aisés. À côté de ces deux grandes catégories, qui dégagent une première image mentale facile à imprimer, le profil du total des aides relève d’un autre niveau de lecture : la distribution est symétrique, elle favorise les extrémités de l’éventail des niveaux de vie.
L’emploi de la couleur, subtil et souriant, souligne ces différents niveaux de lecture. Il laisse de côté le funeste duo rouge-vert rétif aux daltoniens, et n’hésite pas à utiliser le gris.
Quelques chiffres clés sont portés pour saisir l’ordre de grandeur des barres et souligner les maxima ainsi que les oppositions entre les deux principaux groupes d’aides. L’unité € précise ces chiffres pour une appréhension immédiate de ce dont il s’agit (un montant financier).
Avec ces chiffres repères, nul besoin de dessiner une grille ou des axes gradués, qui surchargeraient inutilement le graphique. Précisons que les données de l’étude sont téléchargeables pour qui voudrait les consulter en détail ou, comme moi, faire ses propres graphiques.
L’aide à la lecture sous le graphique – dont on devrait même pouvoir se passer – vient surtout expliciter les notations « D1-D10 ». Pour soulager le lecteur et lui éviter de scanner le diagramme, elle se rapporte au premier chiffre, au premier symbole visuel rencontré dans le sens de la lecture.
Certains sigles sont explicités : CMU-C, ACS. D’autres libellés sont un peu abrégés pour une meilleure homogénéité et un bandeau d’en-tête réduit à 3 lignes seulement. Tous les textes s’affichent à l’horizontale, le lecteur n’a pas à torturer ses cervicales pour comprendre un axe.
La date des données est plus clairement exposée, de fait elle est un peu ancienne. Depuis, CMU-C et ACS ont été fusionnées dans une nouvelle mesure : la « complémentaire santé solidaire » (2019).
Le titre enfin, l’élément le plus important de cette visualisation, expose le message clé. Sur deux lignes, il présente une coupure « logique » en fin de première ligne (règle de lisibilité trop méconnue elle aussi). La nature de l’indicateur présenté apparait en sous-titre, c’est à la fois nécessaire et suffisant.
Ce n'est pas au lecteur de faire l'effort de déchiffrer, c'est à vous de faire lisible et mémorableOn le voit, cette nouvelle représentation ne prend pas plus de place que l’original. Elle expose autant de données et surtout elle révèle bien davantage, avec plus d’efficacité. Davantage qu’un tableau croisé mis en couleurs, tel quel, dans un « grapheur », elle traduit la démarche analytique du rédacteur-concepteur. Chaque petit ciselage compte et contribue à l’évidence de l’ensemble : confort, équilibre, simplicité, mémorabilité.
Ce n’est pas au lecteur de faire l’effort de déchiffrer vos graphiques, c’est à vous, auteur, statisticien, expert du sujet, pédagogue obstiné, de faire ce qu’il faut pour que le ou les messages principaux « sautent aux yeux ».
Ce travail, la « résolution du problème graphique » comme l’énonçait Bertin, apporte beaucoup de plaisir à celui qui le mène. Des outils intelligents comme DataWrapper – conçus par des sémiologues avertis – le rendent accessible à tout un chacun en offrant de tester en confiance différentes variantes. Ne vous en privez pas, et surtout n’en privez pas vos lecteurs !
Pour aller plus loin« La plus grande qualité d'une image,
John Tukey, Exploratory Data Analysis, 1977
c'est quand elle nous amène à remarquer
ce que l'on ne s'attendait pas à voir. »Voici quelques ressources :
[1] Stacked bars are the worst, Robert Kosara, 2016
[2] Psychologie de la forme, Wikipedia
[3] What to consider when creating stacked column charts, Lisa Charlotte Muth, 2018
PS : Il faudrait conduire un autre genre d’étude pour comprendre l’étrange fascination qu’exerce le diagramme en barres empilées sur le statisticien. J’ai quelques hypothèses en tête. Ce visuel consacre le geste statistique canonique, croiser deux critères. Il permet de “mettre à disposition” dans un petit espace un volume significatif de données. Docile à la mise en couleurs, il ravit le concepteur tout comme le maquettiste. Ne cédant pas à la facilité d’un message trop trivial, il rappelle – discrètement – que l’accès à la connaissance se mérite !
L’article Le syndrome de l’empilement est apparu en premier sur Icem7.
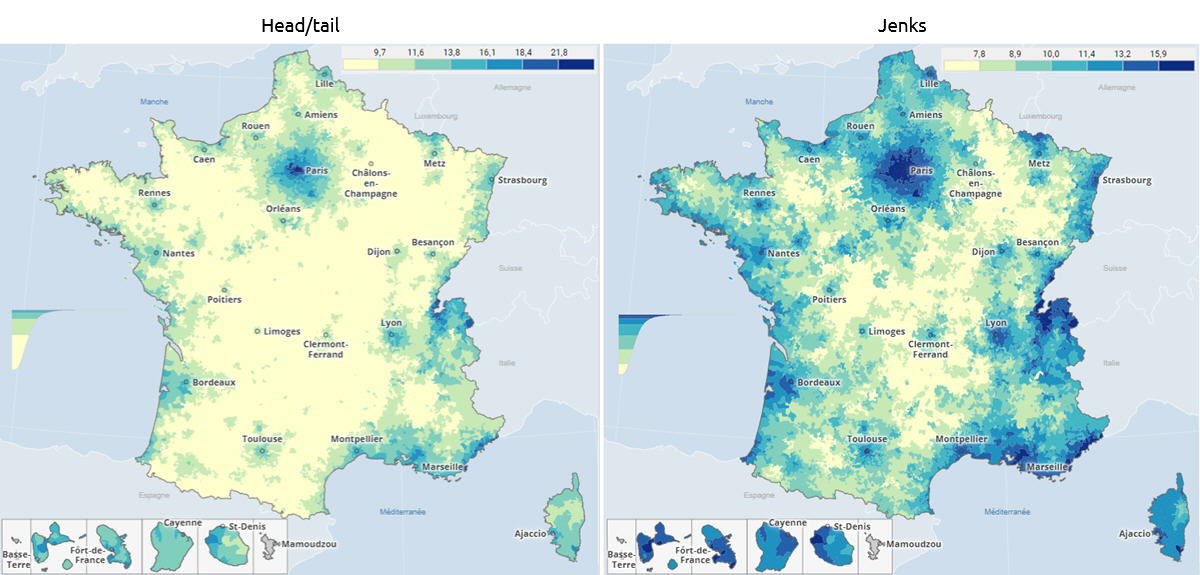{kind=link}
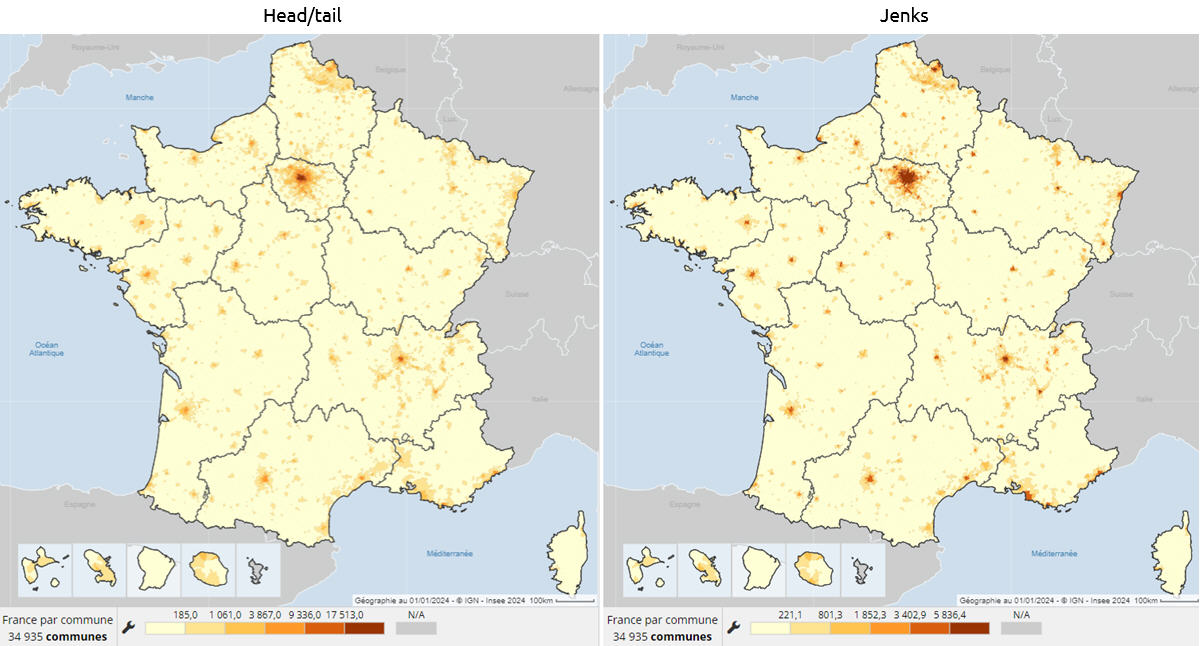{kind=link}
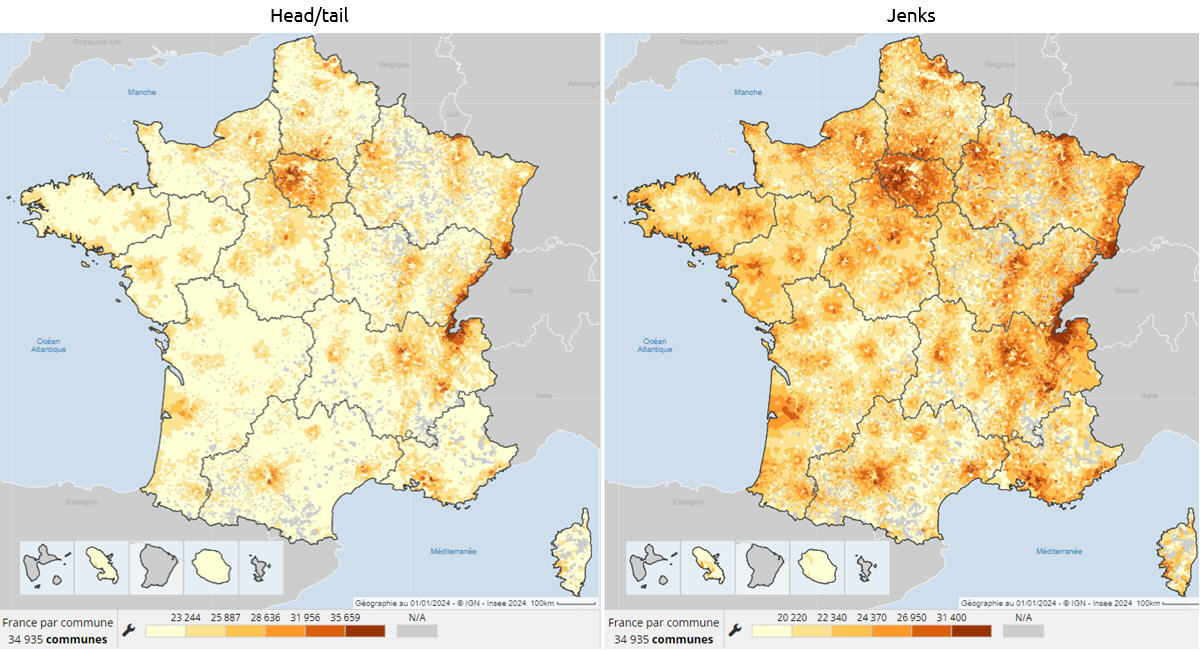{kind=link}
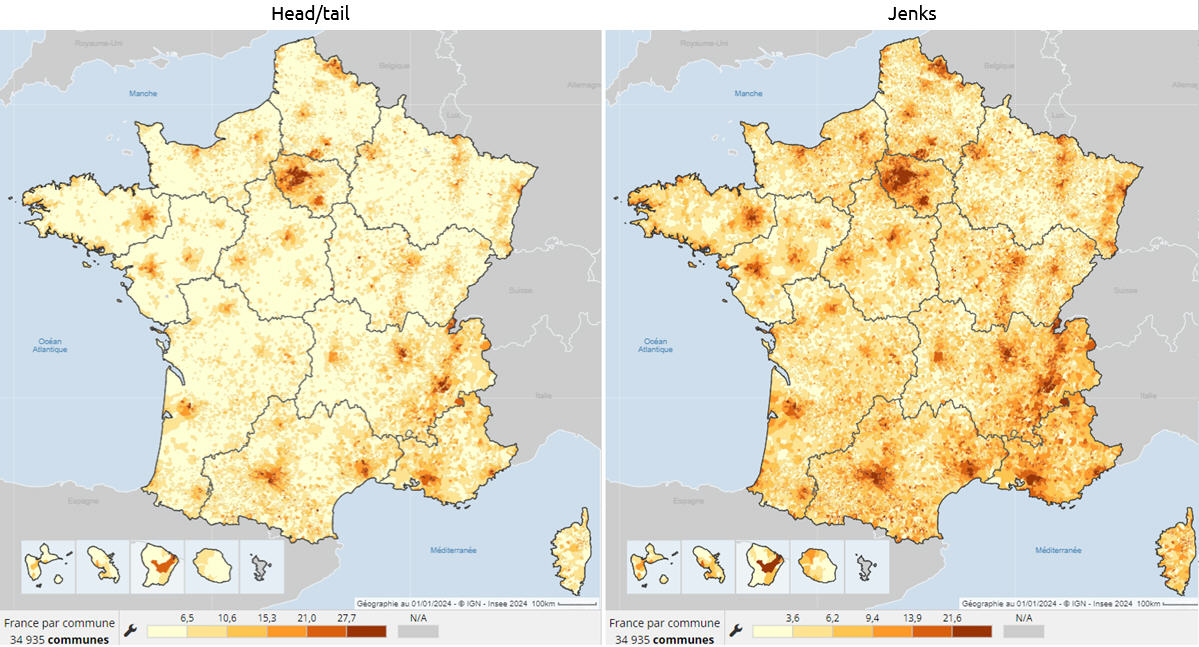{kind=link}
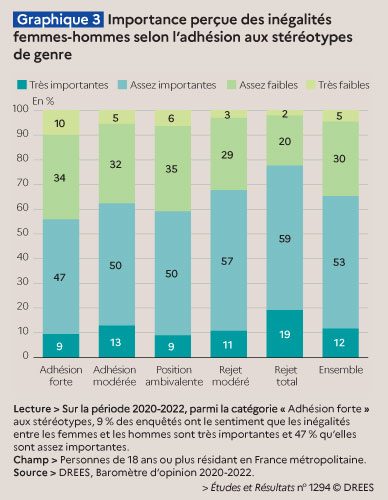{kind=link}
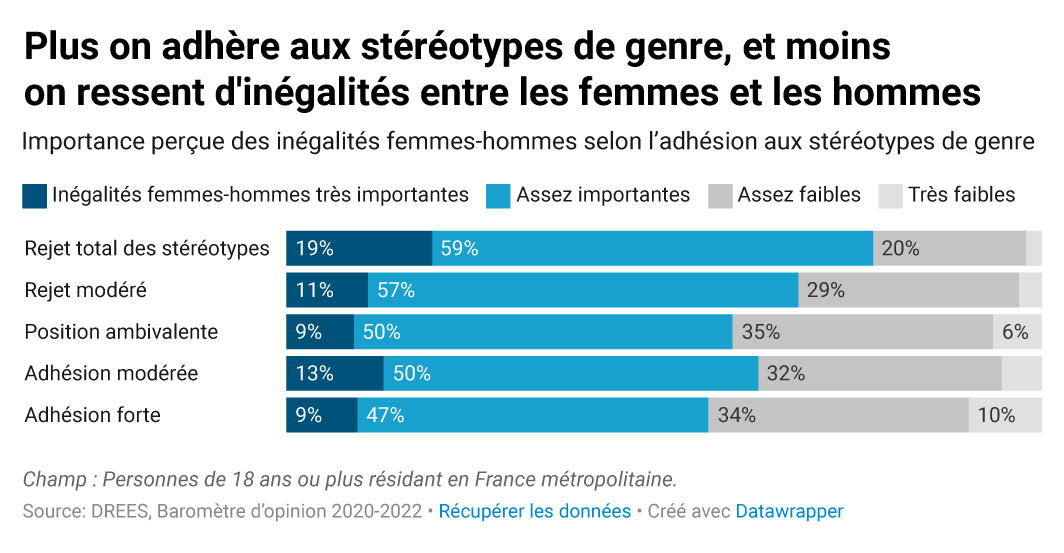{kind=link}
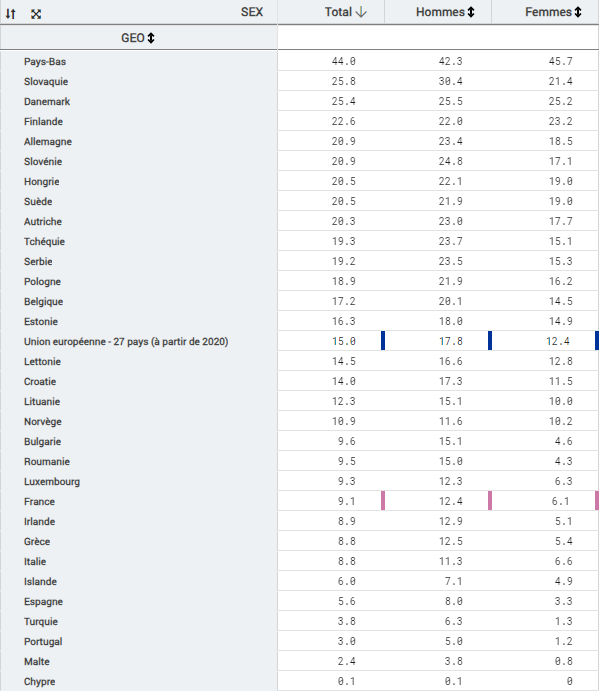{kind=link}
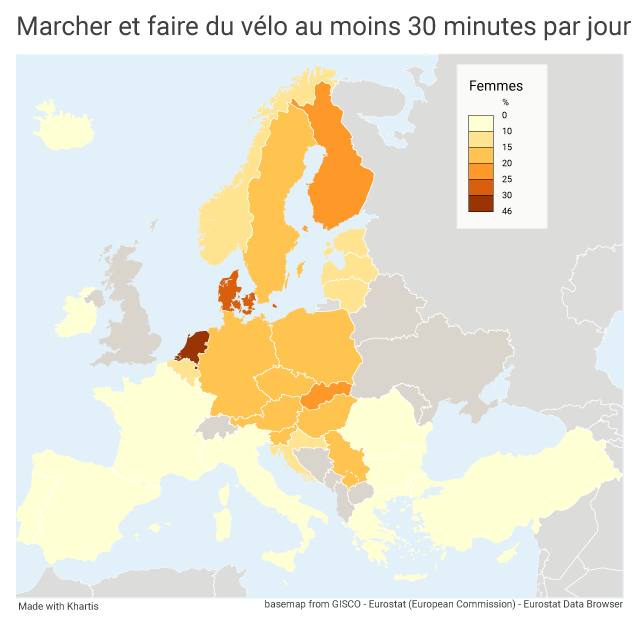{kind=link}
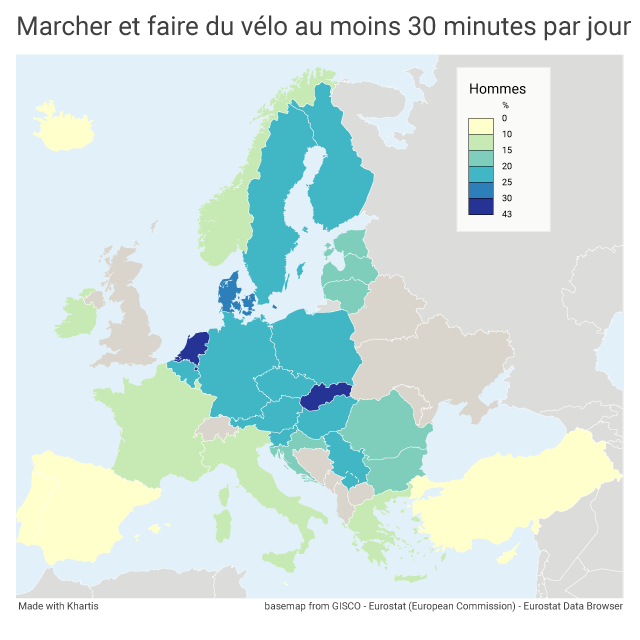{kind=link}