
Planet GeoRezo
Agrégateur de flux RSS - Actualités et contenus géomatiques
Toutes les catégories
Dans la presse
Association
Blogs francophones
Dans les régions
Entreprises de Services Numériques
Géomatique anglophone
GeoRezo
Institutionnel
OpenStreetMap
GeoCat: GeoServer 3 is here!
Thanks to an incredible €550,000 community-funded campaign, the extensive modernization work required to secure GeoServer's future is finished, shipping, and ready for deployment. What This Community ...
Lire l'article complet ↗
Mapping Every Russian Casualty in Ukraine
Vladimir Putin is determined to conceal the enormous human cost of Russia's ongoing war against Ukraine. As a result, Russians are largely denied an accurate accounting of how many of their friends, relatives, and fellow citizens have been killed.To cut through this fog of war, the independent Russian media outlet Mediazona and BBC Russian Service created 200.zona.media, an interactive mapping
Lire l'article complet ↗
Le système MIMO de Tobler (1959)
Préambule : Ce billet présente MIMO, le tout premier outil de cartographie assisté par ordinateur (CAO) dit de “cartographie automatique” élaboré en 1959 par Waldo R. Tobler, alors qu’il était étudiant en master au département de géographie de l’Université de Washington à Seattle, et travaillait pour la System Development Corporation à Santa Monica, en Californie. L’outil a fait l’objet d’une publication dans la Geographical Review.
{kind=link}
Il est possible de faire débuter l’histoire de la géovisualisation à la fin des années 1950, plus précisément en 1959, avec l’invention du premier outil de cartographie statistique automatique : le système Map in Map out (MIMO) construit par Waldo Tobler (1930-2018).
...Narcélio de Sá: Soberania Tecnológica no Brasil: O Papel Estratégico do FOSS4G e dos Dados Geoespaciais
O recente artigo publicado no blog da gvSIG levanta uma reflexão fundamental para o século XXI: a verdadeira soberania de uma nação já não se faz apenas com fronteiras físicas, mas com o controle absoluto sobre as suas infraestruturas digitais e de dados.
A adoção, por parte da Comissão Europeia, de medidas sólidas em prol da Soberania Tecnológica e de uma clara Estratégia de Código Aberto evidencia que a dependência de fornecedores externos para tecnologias críticas é uma vulnerabilidade geopolítica inaceitável.
...EOX' blog: EOxCloudless Acquisition year 2025
We have a new EOxCloudless release with more precise ecoregions and advanced ocean mosaicking. Check out the preview! Over the past few years, our engineering focus for EOxCloudless has been, among others, on optimizing the BRDF corrections to eliminate equatorial striping and optimizing performance ...
Lire l'article complet ↗

hebdoOSM 829
04/06/2026-10/06/2026
[1] Carte de l’aire de jeux intitulée « Spieli » | © m_fuhrmann | données cartographiques © Cartographes OpenStreetMap.
...London is in Motion
Zone One is a live map showing every tube train, bus, riverboat, train, and aircraft moving in real-time across central London. The result is a mesmerizing real-time portrait of London's constantly shifting transportation network.Instead of relying on heavy, off-the-shelf mapping platforms like Google Maps or Mapbox, the project is built from scratch as a high-performance 3D canvas
Lire l'article complet ↗

Cartographia, nommé pour le prix du livre scientifique : Le Goût des Sciences (17e ed.)
Le Goût des Sciences est un prix littéraire scientifique créé par le Ministère de l’Enseignement supérieur, de la Recherche et de l’Espace (MESR). Il récompense depuis 2009, les meilleurs ouvrages scientifiques de l’année en valorisation des sciences, qui permettent de valoriser les connaissances scientifiques et plus largement la culture générale.
...Lutra consulting: FOSS4G:HU 2026 - bringing the Hungarian GIS community together
Discover the highlights from FOSS4G:HU 2026 in Budapest, featuring open source GIS insights, QGIS and Mergin Maps field data workflows, and community networking.
Lire l'article complet ↗
GeoSolutions: GeoServer 3.0 is here
You must be logged into the site to view this content.

gvSIG Team: Europe strengthens its technological sovereignty: also through geospatial data
On 3 June 2026, the European Commission adopted a new package of measures to strengthen Europe’s technological sovereignty.
The package includes two legislative proposals —the Chips Act 2.0 and the Cloud and AI Development Act— together with the European Open Source Strategy and a strategic roadmap for digitalisation and artificial intelligence in the energy sector.
...
gvSIG Team: Europa refuerza su soberanía tecnológica: también desde los datos geoespaciales
El pasado 3 de junio de 2026, la Comisión Europea adoptó un nuevo paquete de medidas para reforzar la soberanía tecnológica de Europa.
El paquete incluye dos propuestas legislativas —el Chips Act 2.0 y el Cloud and AI Development Act—, junto con la Estrategia Europea de Software Libre y una hoja de ruta estratégica para la digitalización y la inteligencia artificial en el sector energético.
...Dual Maps Goes 3D
Dual Maps, an old Maps Mania favorite, has undergone a bit of a makeover this week. As you may have heard, Google recently removed its classic 45° bird's-eye aerial imagery from the Maps JavaScript API. This oblique aerial perspective was one of the core synchronized views offered by Dual Maps. The removal of the bird's-eye view has therefore prompted Map Channels to undertake a ground-up revamp
Lire l'article complet ↗
Journée LiDAR – 23 juin 2026 à Clermont-Ferrand
Oslandia sera présent à la Journée LiDAR organisée par le CRAIG et l’IGN mardi 23 juin à Clermont-Ferrand.
La matinée sera consacrée à des présentations générales : qu’est-ce que la donnée LiDAR, le programme LiDAR HD, où chercher la donnée, quels sont les grands cas d’usage…
L’après-midi deux sessions d’ateliers pratiques avec des interventions des équipes Oslandia :
...Sandro Santilli: Asking a Local LLM to Calculate Car Travel Costs
I asked a locally-downloaded LLM to compute the cost of a car trip using natural language. No calls to any cloud service, just a model queried by an inference tool running on my own machine.
The SetupThe machine used for this excercise is a LemurPro laptop from around 2020, has a 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80GHz CPU and 16GB of RAM. No GPU.
The Procedure-
I downloaded the unsloth/gemma-4-E4B-it-qat-UD-Q4_K_XL model from Hugging Face - about 4GB in size.
-
I built and installed llama-server from the llama.cpp project - version: 9570 (3ac3c20c9).
-
I ran llama-server -m gemma-4-E4B-it-qat-UD-Q4_K_XL.gguf
...
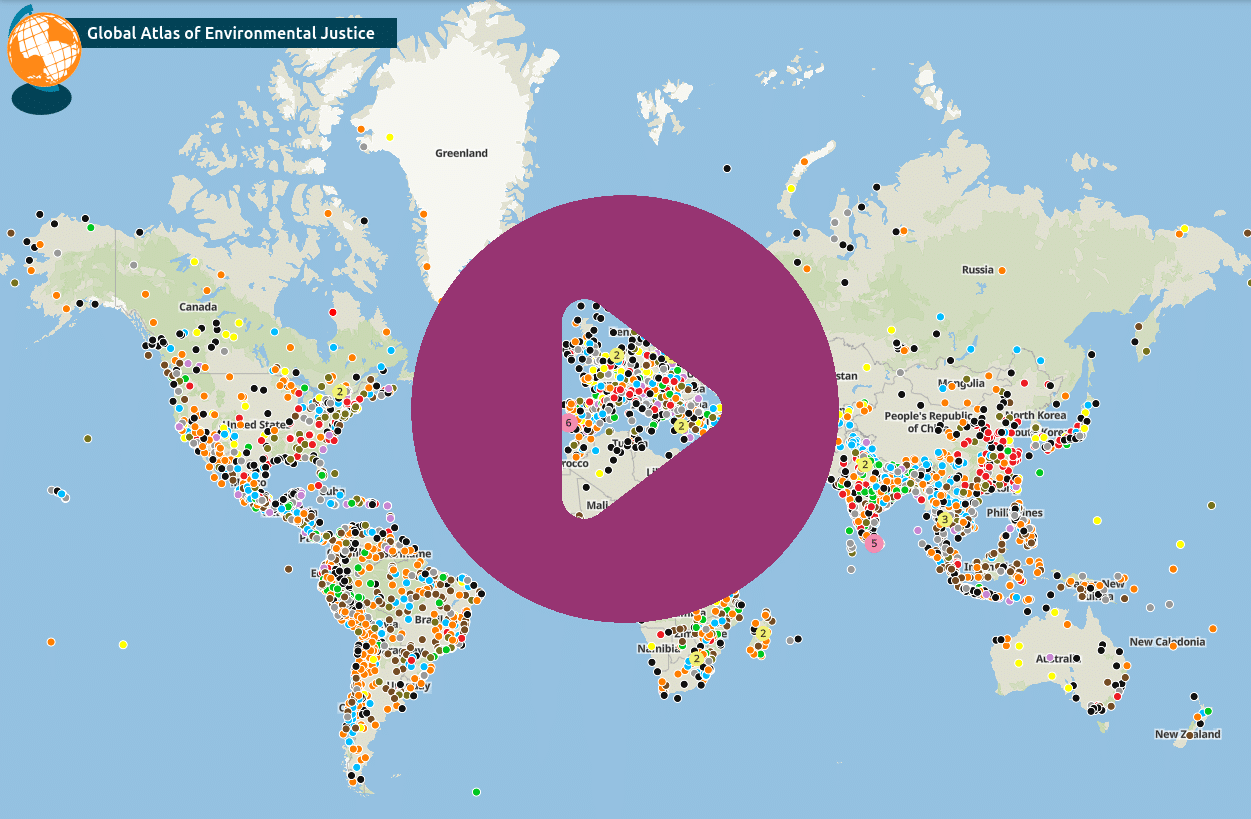
geomatico: Nuestras comunicaciones en las Jornadas de SIG Libre
Las Jornadas de SIG Libre de Girona han sido siempre un referente para Geomatico … porque han sido también la cuna de nuestra empresa, allá en 2011. En estos más de 15 años de conferencias hemos presentado multitud de charlas que celebran la esencia del desarrollo abierto: colaborar, aprender y devolver algo a la comunidad. Cada una aporta una perspectiva que invita a experimentar, contribuir y seguir construyendo tecnología que sirva a todos.
2025: Environmental Justice Atlas, un visor para conflictos ambientales
Micho García 2025 ES 4:582025: Mapas de biodiversidad y estándares: del archivo al dato vivo
Martí Pericay 2025 ES 5:012025: Una nueva infraestructura compartida para las comunidades de geoinquietos al estilo DIWO
...[FR]Suivi des algues vertes par drone multispectral : livre gratuit sur QGIS, classification et IA
Je suis heureux de mettre à disposition un nouvel ouvrage consacré au suivi des algues vertes par drone multispectral. Ce livre est né d’une formation réalisée pour des agents de l’Ifremer dans le cadre d’un travail…
The post [FR]Suivi des algues vertes par drone multispectral : livre gratuit sur QGIS, classification et IA first appeared on Blog SIG & Territoires.How France Sneaked 9 Teams into the World Cup
There are 99 players born in France in the 2026 World Cup. Each national team can name a squad of only 26 players. This means that 73 players representing other national teams were actually born in France. In other words, there are nearly four full squads' worth of French-born players at the 2026 World Cup.There are 1,248 players participating in the 2026 World Cup in total, and you can view the
Lire l'article complet ↗
GeoServer Team: GeoServer 3.0.0 Release
GeoServer 3.0.0 release is now available with downloads (bin, war, windows), along with docs and extensions.
This is a stable release of GeoServer 3.0.x series. GeoServer 3.0.0 is made in conjunction with GeoTools 35.0, and GeoWebCache 2.0.0.
Thanks to Andrea Aaime (GeoSolutions), Jody Garnett (GeoCat), and Peter Smythe (AfriGIS) for making this release.
...GeoServer Team: GeoServer 3 is here, from crowdfunding to release
GeoServer 3.0 is now generally available. This post is not a feature announcement, those have been written, and the release notes cover the details. This is something we get to do less often: closing the loop on a promise. The modernisation work the community funded is finished and shipping, and we want to account for what that funding set out to achieve and what it delivered.
The result is a platform brought back onto a current, supported foundation. The work reached across the wider ecosystem rather than GeoServer alone, and the scope the campaign promised has been covered.
...![[Le blog SIG & URBA] Cartographier dans OpenStreetMap avec un fond PCRS](https://blog.georezo.net/sigurba/files/2026/06/15_apres_exemple3-150x110.png)
[Le blog SIG & URBA] Cartographier dans OpenStreetMap avec un fond PCRS
Initialement conçu pour sécuriser les travaux à proximité des réseaux, le Plan Corps de Rue Simplifié (PCRS) recèle un potentiel bien plus large, comme celui de servir de fond de plan pour enrichir OpenStreetMap, la carte libre et collaborative. En exploitant ces données précises et homogènes, il devient possible d’améliorer la qualité des informations géographiques disponibles pour tous dans OpenStreetMap. Cette démarche ouvre la voie à une meilleure connaissance du territoire, en combinant la rigueur du PCRS et la dynamique participative d’OSM :
Lire la suite →
- Pour la communauté OSM, c’est l’opportunité d’accéder à des données fiables et détaillées, permettant de renforcer la précision des tracés et d’intégrer des éléments souvent difficiles à relever sur le terrain.
- Pour les collectivités locales, contribuer à ce mouvement signifie valoriser leurs investissements dans le PCRS, favoriser la transparence et offrir à leurs citoyens des cart...
GeoTools Team: GeoTools 35.0 released
The GeoTools team is pleased to announce the release of the latest stable version of GeoTools 35.0 : geotools-35.0-bin.zip geotools-35.0-doc.zip geotools-35.0-userguide.zip geotools-35.0-project.zip This release is also available from the OSGeo Maven Repository and is made in conjunction with
Lire l'article complet ↗
Mapping the Lone Star’s Northern March
Climate change is propelling the lone star tick's habitat northward. This expansion poses a major public health threat, as a single bite can trigger alpha-gal syndrome, a life-altering allergy to red meat.You can explore the northern expansion of the lone star tick for yourself on Lone Star Tick: The Frontier - an impressive mapped visualization of citizen-science tick observations over
Lire l'article complet ↗

Convertir une Géodatabase personnelle dans ArcGIS Pro 3.7
Si vous utilisez comme moi ArcGIS depuis longtemps, il y a de fortes chances que vous ayez déjà géré des données stockées dans une Géodatabase personnelle (.mdb) avec l'application ArcMap et que vous souhaitiez encore aujourd'hui utiliser ces données dans ArcGIS Pro.
ArcGIS Pro n'a jamais pris en charge les Géodatabases personnelles, et pendant des années, cela a signifié maintenir des flux de travail de longue date avec des bases de données Microsoft Access ou s'appuyer sur ArcMap tout en essayant de faire évoluer ces données.
Avec l'évolution d'ArcGIS Pro vers des modèles et des formats de données plus modernes et évolutifs, ArcMap et les Géodatabases personnelles sont arrivées en fin de vie, laissant un vide ...
Name that traffic cam!
GeoGuessr has inspired countless spin-offs over the years, but NYCGuessr adds a clever twist to the formula by replacing Street View imagery with live traffic cameras from across New York City.The premise is simple. You're shown a live feed from an NYC traffic camera and have 40 seconds to work out where it is. Drop a pin on a map, submit your guess, and score points based on how close you are
Lire l'article complet ↗
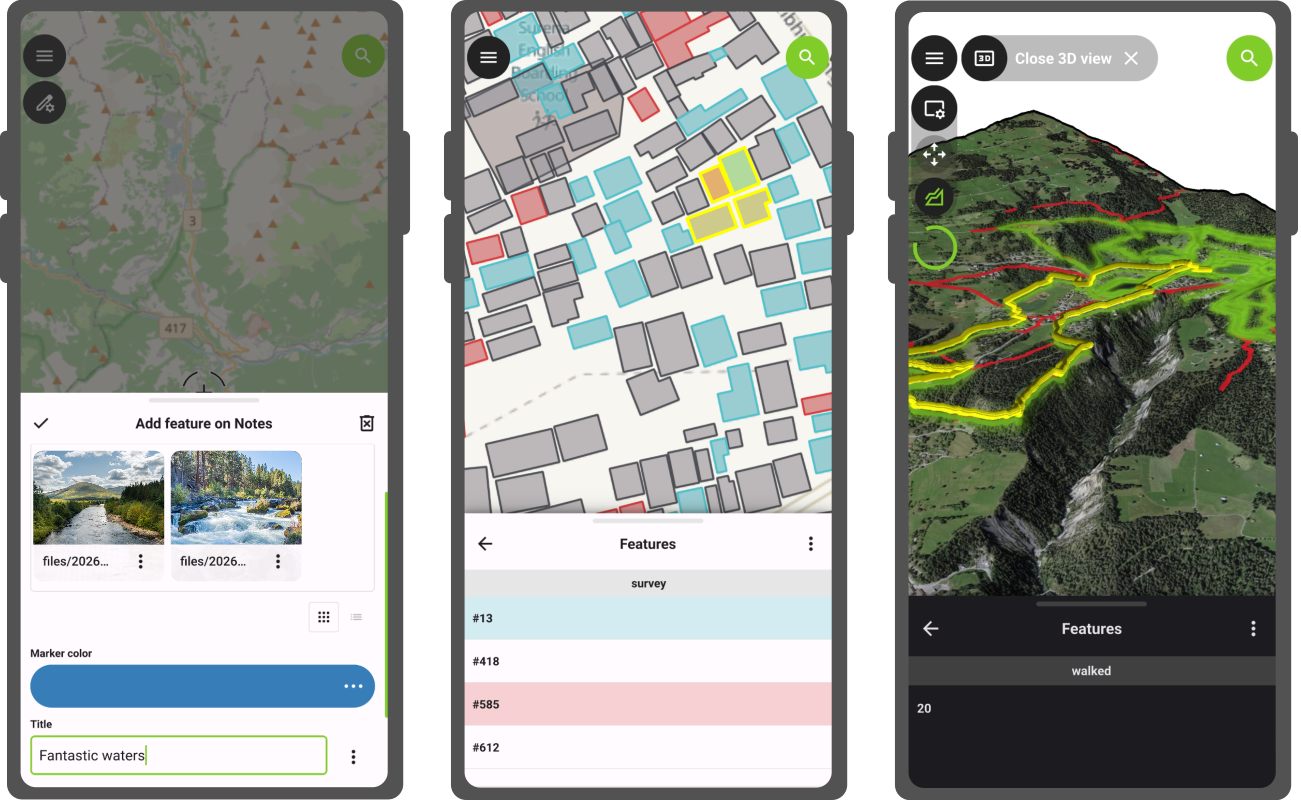
QField: QField 4.2 "Coral Sea": Reaching sub-centimeter accuracy out of the box
Here’s another QField release, packed with the features that have been at the top of professional surveyors’ wish list! (hint: it’s in the title) — plus improvements across the board for our wide range of users.
Main highlights NTRIP & Bluetooth Low EnergyFirst up, NTRIP support has been added in QField unlocking sub-centimeter accuracy position readings without the need for any third-party app. This has long been requested by cadastral surveyors and other professional field workers in need of highly accurate data where being a few centimeters off can have real consequences.
To configure an NTRIP connection, simply connect to an RTK capable GNSS device via Bluetooth, BLE or TCP from the QField settings positioning panel. Once connected, the NTRIP user interface will be visible just below the positioning devices combo box in the same panel.
...When AI Maps More Than Places
Mapedia.ai AI is rapidly becoming one of the biggest trends in online mapping. Google Maps has been steadily rolling out its own AI-powered features, including its Gemini-powered conversational search tools. These allow users to find places using natural language queries such as "things to do on a rainy day" or "restaurants with a romantic atmosphere", helping people discover destinations
Lire l'article complet ↗

GIScussions: When Your Maps Disappear Overnight – A PMTiles Horror Story
Thanks to Mario Ame
Everything was working fine. I had just finished building the Grow Your Own allotments map, deployed it to the live server, and was feeling pretty pleased with myself. A few days later a friend messaged me that the map had stopped working. No regions, just a blank basemap. Checked the console and got this:
“Server returned no content-length header or content-length exceeding request. Check that your storage backend supports HTTP Byte Serving.”
...
Voyage en France australe, avec Emmanuel Véron.
Café géographique de Paris, Café de Flore, 1er juin 2026. Animé par Gilles Fumey, compte rendu de Michèle Vignaux.
C’est bien en France qu’Emmanuel Véron nous emmène, ce 1er juin 2026, mais dans une France située à des milliers de kilomètres de la métropole, dans l’hémisphère Sud. Constitués d’espaces plus maritimes que terrestres, les TAAF (1) sont bien mal connus des Français. Notre intervenant, géographe, est professeur à l’Ecole de Guerre dont la mission est de former des officiers supérieurs pour les armées de terre, de l’air, ainsi que pour la marine et la gendarmerie.
Gilles Fumey et Emmanuel Véron (à droite) au Flore. Photo de Micheline Huvet-Martinet
...Votez pour le Conseil d’administration de l’Afigéo (2026-2029) avant le 26 juin 2026
Votez pour le Conseil d’administration de l’Afigéo (2026-2029) avant le 26 juin 2026 Votez pour le Conseil d’administration de l’Afigéo (2026-2029) avant le 26 juin 2026 Afigéo
Lire l'article complet ↗
Dans le cadre de l’élection des 15 membres du Conseil d’administration pour le mandat 2026/2029, chaque électeur (représentant.e titulaire) recevra un mail le mardi 9 juin à 9h contenant un lien unique (V8TE) d’accès au parcours de vote. Le vote ouvert jusqu’au 26 juin sera possible uniquement via ce mail. Pensez à vérifier les courriers […]
...
hebdoOSM 828
28/05/2026-03/06/2026
[1] OnRouteMap, un outil basé sur OSM pour la planification et l’analyse d’itinéraires en plein air | © Nico Isenbeck | données cartographiques © par les contributeurs et contributrices OpenStreetMap.
...
Ustaritz: Rencontre Mapadour, Le mercredi 10 juin 2026 de 16h30 à 19h00.
Rencontre Mapadour, groupe local OpenStreetMap du Pays Basque Sud Landes.
Ouvert à toutes et à tous

Carte de l’Afrique : mensonge XXL ?
Pour une version africaine de la carte de l’Afrique dans le Monde.
« Pendant des siècles, les cartes du monde ont réduit visuellement l’Afrique. L’Union africaine veut corriger ça… mais en demandant la permission aux autres. Il y a un problème. »
{kind=link}
Lien vers l’émission sur la chaîne YouTube de AJ+ français.
Mes remerciements à Arwa Barkallah, journaliste productrice en charge de l’émission « Dans l’œil de Remy ».
The Cheap Eats Map
With the cost of living becoming a major concern for many people, finding affordable places to eat has become increasingly important. While restaurant review platforms often emphasize ratings, trends, or premium dining experiences, there is relatively little focus on helping people quickly locate genuinely low-cost meal options. Fooglemap hopes to address this gap by making budget-friendly
Lire l'article complet ↗

GIScussions: Ebola Outbreaks in Africa
The current outbreak of Ebola has inevitably triggered lots of maps of the outbreak, just search for “Maps of the Ebola outbreak in Africa” and you will find something like this.
Some of these are pretty good, some don’t communicate very well and a few are awful. My attention was drawn to a static map obviously generated by AI which was so so bad that it was laughable and you had to wonder why anyone share this without picking up the numerous obvious geographic errors.
...
Utiliser ArcGIS Pro via un type d'utilisateur ou en Standalone ?
Les types d'utilisateurs ArcGIS ont fait l'objet d'une attention particulière depuis leur mise à jour en 2024, et sont désormais la pierre angulaire du système ArcGIS. Qu'ils soient fournis via ArcGIS Online ou ArcGIS Enterprise, les types d'utilisateurs nommés vous donnent accès à une plateforme SIG complète en prenant en compte la sécurité et les différents besoins fonctionnelles des utilisateurs.
Mais les types d'utilisateurs ne sont pas la seule façon d'accéder à ArcGIS Pro. Il existe une option ArcGIS Pro Autonome (Standalone), qui, comme son nom l'indique, permet d'utiliser ArcGIS Pro comme logiciel Desktop indépendant, sans passer par un type d'utilisateur. Dans ce cas, vous n'aurez pas accès aux capacité...
Project Hail Mary - Mapping the Astrophage
Navigating the Stars of Project Hail Mary Warning: may contain spoilers for Project Hail MaryOne of the joys of Andy Weir’s Project Hail Mary is how convincingly it blends speculative science fiction with real astronomy. Val Hovey’s interactive Project Hail Mary – Stellar Navigation Chart leans into that realism, using authentic data from the GAIA DR3 star survey to recreate the ship’s
Lire l'article complet ↗
OSGeo.nl: Foss4G-NL 2026: Programma compleet en ticketverkoop gestart
Ticketverkoop voor Foss4G-NL 2026 (8/9 juli in Groningen) gestart
Lire l'article complet ↗
Sinds gisteren zijn ook voor de workshops op de FOSS4G-NL (op 8 juli) de tickets te koop. Voor de conferentie dag op 9 juli waren ze dat al, maar nu kun je dus in één keer je slag slaan voor 2 leuke & leerzame dagen. Ga naar https://www.foss4g.nl voor programma en ticketverkoop
• Tickets zijn 𝘱𝘢𝘺-𝘸𝘩𝘢𝘵-𝘺𝘰𝘶-𝘸𝘢𝘯𝘵. Je ziet in de shop wel een prijsvoorstel zodat de catering, banners en andere kosten die wij maken voor de organisatie netjes betaald kunnen worden. En extraatjes gebruiken we weer voor volgende (gratis) events. • Let er zelf op dat je niet voor 𝘨𝘦𝘭𝘪𝘫𝘬𝘵𝘪𝘫𝘥𝘪𝘨𝘦 workshops tickets koopt. • Doe ons een groot plezier, en koop je ticket bijtijds. Dan weten wij hoeveel broodjes we moeten smeren, hoeveel tafels en meters kapstok we nodig hebben etc.
[Webinar / discussion panel] Creating QGIS plugins in 2026
issues, expectations and concerns!
Lire la suite →
Oslandia has been developing QGIS plugins for more than 15 years, and we would like to invite developers to webinar and discussion event Tuesday June 30th at 5pm (Paris time)
The goal is to share QGIS plugin developer’s experiences, our goals, habits and difficulties, as well as discuss available tools. This discussion will also be a good opportunity to share feedback on our experience as a developer, identify needs around QGIS plugins development, and explore ways to make the most of our development work.
...A multilingual dictionary for the recognition of macro-regions and countries mentioned in daily press news
This data paper presents a reproducible method for identifying national and supranational geographical entities mentioned in international news published by daily newspapers. The approach relies on a multilingual dictionary covering macro-regions (part of the world and political organisations) and nation-states in four languages (French, German, English, Turkish). The dictionary has been tested and validated on a corpus of news titles from five daily newspapers in France, Tunisia, Germany, the United Kingdom, and Turkey, spanning the period from April 2013 to March 2023. This corpus serves as an example of the dictionary’s application for elaborating geographical networks and geopolitical agendas.
French pesticide purchase data spatialised at the municipality level
Pesticide purchase data in France are published annually at the ZIP code level. However, this spatial resolution is often too coarse in rural areas, which are nonetheless the most affected by sanitary and environmental impacts associated with pesticide use. This paper proposes a method to disaggregate these data to the French municipal level (i.e., « commune »), thereby facilitating spatial monitoring and integration with other datasets. The proposed approach is based on: (i) information on authorised pesticide application doses; and (ii) a geographical layer that accurately delineates surfaces subject to phytosanitary treatments. This method enables the precise allocation of more than 95% of the total quantity of active substances for the period between 2015 and 2020. These data can be used in epidemiology, agronomy, ecology, and economics, to investigate issues related to public health, agricultural systems, diffuse pollution and environmental damag...

Présentation d'ArcGIS Velocity pour ArcGIS Enterprise
ArcGIS Velocity offre des fonctionnalités d'intégration et d'analyse de données en temps réel, permettant aux organisations d'ingérer, d'analyser et d'exploiter des données en flux continu provenant de pratiquement n'importe quelle source, y compris les capteurs IoT, les équipements mobiles et les flux d'événements. Vous pouvez désormais héberger Velocity dans votre propre environnement pour explorer vos données IoT en flux continu sur des cartes et des tableaux de bord, identifier les tendances temporelles et extraire des informations géolocalisées. Cet article vise à vous faire découvrir cette solution qui est désormais disponible avec ArcGIS Enterprise.
Un monde toujours plus connecté
Les données en temp...

Grenoble: Atelier applications mobiles autour de la contribution à OSM & Panoramax, Le lundi 8 juin 2026 de 19h00 à 21h00.
Cet atelier sera consacré à la contribution aux projets OpenStreetMap et Panoramax à partir de smartphones.
Première partie à la Turbine
Nous vous présenterons des applications mobiles permettant de charger les cartes OSM sur votre mobile pour les consulter sans connexion de données (applis OSMAnd et CoMaps)
Nous vous initierons ensuite à la contribution :
- en prenant des photos géolocalisées avec son smartphone.
- directement sur mobile Android & iOS
- en enregistrant des traces GPS permettant une contribution différée (en conjonction avec la prise de photos géolocalisées)
Nous vous montrerons également comment contribuer au projet Panoramax en utilisant l'application BaBa.
Deuxième partie : déambulation dans le quartier
Vous contribuerez « en situation » sur vos téléphones mobiles Android et iOS.
...How Accurate Is Your Mental Globe?
Can you name the missing city in this diagram? If you can then you could be the potential daily champion of City Angle - a fun new geography puzzle game.If you think you know your global geography because you can point out Italy on a blank map, City Angle is here to completely shatter your confidence.At its core, this game flips the standard "point-and-click" map trivia template on its head.
Lire l'article complet ↗

GIScussions: Grow Your Own – a lot of data to work with and yet again more challenges than I expected
My wife grows some vegetables in our back garden, she used to have an allotment but she gave it up and we dug up part of our grass. I got to wondering about allotments and whether they were a British phenomena or they were widely spread? Which countries have the most allotments, growing space per capita and the largest size of allotments?
...The Syphilis Blame Game
Do you remember how during his first term Donald Trump kept calling Covid the "Chinese Virus"? This impulse to point fingers across borders is nothing new. When syphilis swept Europe after the 1495 Naples outbreak, no nation would own it. Instead, blame spread faster than an STD in a retreating French army platoon: the Russians called it the "Polish Disease," the Poles called it the "
Lire l'article complet ↗
[FR]Développer Un Plugin Qgis : Ajouter Un Bouton Et Une Fenêtre
Ajouter un bouton dans l’interface de QGIS est souvent la première étape concrète lorsqu’on développe un plugin. C’est ce qui transforme un simple script Python en outil réellement utilisable par l’utilisateur. Dans ce troisième article du…
The post [FR]Développer Un Plugin Qgis : Ajouter Un Bouton Et Une Fenêtre first appeared on Blog SIG & Territoires.Oslandia: [Webinar / discussion panel] Creating QGIS plugins in 2026
issues, expectations and concerns!
Lire la suite →
Oslandia has been developing QGIS plugins for more than 15 years, and we would like to invite developers to webinar and discussion event Tuesday June 30th at 5pm (Paris time)
The goal is to share QGIS plugin developer’s experiences, our goals, habits and difficulties, as well as discuss available tools. This discussion will also be a good opportunity to share feedback on our experience as a developer, identify needs around QGIS plugins development, and explore ways to make the most of our development work.
...

Matrice des fonctionnalités ArcGIS Enterprise 12.1
Comme mentionné dans ce précédent article, ArcGIS Enterprise 12.1 est désormais disponible. Dans ce contexte, Esri a également mis à jour la matrice des fonctionnalités du produit.
Ce document de synthèse présente les principales capacités selon les niveaux de licence (Standard et Advanced) ainsi que pour les différents composants de la plateforme (Serveur SIG, Portail, rôles serveur additionnels et extensions). Il propose une vue d’ensemble des fonctionnalités associées aux types d’utilisateurs, aux extensions, aux rôles serveur et aux éditions Standard et Advanced. Il intègre aussi des mi...
Lire la suite →
{kind=link}
Ce document de synthèse présente les principales capacités selon les niveaux de licence (Standard et Advanced) ainsi que pour les différents composants de la plateforme (Serveur SIG, Portail, rôles serveur additionnels et extensions). Il propose une vue d’ensemble des fonctionnalités associées aux types d’utilisateurs, aux extensions, aux rôles serveur et aux éditions Standard et Advanced. Il intègre aussi des mi...

Les nouveautés d'ArcGIS Enterprise 12.1
ArcGIS Enterprise 12.1 pour Windows et Linux est disponible. Première version à support à long terme de la génération 12.x, ArcGIS Enterprise 12.1 offre une base stable et fiable, supporté pendant environ quatre ans selon le cycle de vie des produits Esri. Cette version apporte des mises à jour importantes pour les administrateurs SIG, les équipes de DSI, les analystes SIG et les développeurs.
Résumé
Les principales évolutions d'ArcGIS Enterprise 12.1 sont :...

OPENGIS.ch: Python Full-Stack Engineer (Django focused) (80-100% Remote)
Location: Remote (at least 4h overlap with CET)
Employment Type: Full-time (80-100%)
About OPENGIS.ch:
OPENGIS.ch is a team of Full-Stack GeoNinjas offering personalized open-source geodata solutions to Swiss and international clients. We are dedicated to using and developing open-source tools, providing flexibility, scalability, and future-proof solutions, and playing a key role in the free and open-source geospatial community. We pride ourselves on our agile and distributed nature, which allows us to have a motivated and multicultural team that supports each other in working together.
Quinsac: Carto-partie lors de la permanence mensuelle Libretic, Le jeudi 4 juin 2026 de 19h00 à 22h00.
La prochaine permanence Libretic aura lieu ce JEUDI 04 JUIN.
Pour cette période estivale, nous renouvelons la carto-party comme l'année dernière :
Carto-Party avec Openstreet-Map Jeudi 04 Juin à partir de 19h00Découverte d'Openstreet map, une application de navigation, cartographie et géolocalisation participative et libre alimentée par ses membres à travers la planète !
Présentation de l'activité :
- qu'est ce qu'OpenStreetMap, quels objectifs, pour qui ?
- les outils,
- organisation de la promenade.
- Relevés sur le terrain
- Restitution et partage
- Auberge espagnole
En amont de l'activité, vous pouvez créer un compte sur openstreetmap.org, « s'inscrire » (pseudo, mail et mot de passe).
...The Geography of Country Names
There’s a pretty clear geographical split in what different countries call Greece. In most of Europe, the name comes from the Latin Graecia. But across North Africa, the Middle East, and much of Asia, the name is usually derived from Ionia or Yunan, through Persian, Arabic, Turkish, and related linguistic influences. The split basically reflects two different historical contact routes:
Lire l'article complet ↗

OSMF at the Geospatial World Forum 2026
From 28th April to 1st May 2026, I attended the Geospatial World Forum (GWF) 2026, representing the OpenStreetMap Foundation. The GWF is an annual forum attended mostly by companies and public administration delegates in the geospatial domain. Henk Hoff, all the way back in 2013, was the last OSMF representative attending the GWF, when we received the award for “Geospatial Content Organisation of the year 2012”. So it was long overdue that OSM’s voice could be heard in this professional setting.

hebdoOSM 827
21/05/2026-27/05/2026
[1] Plusieurs infrastructures liées à la faune | © imagico | données cartographiques © Cartographes OpenStreetMap.
...The White House's Conspiracy Theory Map
The White House has launched a new interactive map intended to showcase ICE operations across the United States. Normally, the release of a government map would be a fairly mundane affair involving data sources, methodology notes, and perhaps a few carefully chosen statistics.However The Enemy Within appears to have been written by someone who spent the weekend binge-reading conspiracy
Lire l'article complet ↗
Sandro Santilli: Writing a Blog Post with OpenCode
This blog post was written by an AI coding agent. Specifically, by opencode, a terminal-based coding assistant, running against a remote inference provider (OpenCode Zen) serving the opencode/big-pickle model.
The entire process took about two minutes. Here is how it went.
I opened a terminal, typed opencode, and when the prompt appeared I pasted the following:
Write a blog post about writing this blog post using this coding agent and a remote inference provider. Include this prompt and the name of the LLM model.
The agent then explored the codebase to understand the blog structure (it found Hugo with the Indigo theme, looked at existing posts for style and frontmatter conventions), asked a clarifying question about which provider to name, and produced this very file — complete with correct frontmatter, matching date format, and consistent URL scheme.
...Coopération France / Québec : soutien renouvelé du Consulat de France
Coopération France / Québec : soutien renouvelé du Consulat de France Coopération France / Québec : soutien renouvelé du Consulat de France Afigéo
Lire l'article complet ↗
L’année 2026 permettra à l’Afigéo et Geospatial Québec de poursuivre leur collaboration en faveur de l’usage des geodata pour la transition écologique, grâce à un soutien financier de la coopération France Québec pour la 2è année. Wébinaire regards croisés, interventions dans les évènements respectifs, organisation de stand collectif rythmeront ce partenariat comme ce fut le cas en 2025 avec de […]
...CICCLO : tendre vers des Espaces communs de données
CICCLO : tendre vers des Espaces communs de données CICCLO : tendre vers des Espaces communs de données Afigéo
Lire l'article complet ↗
Le collectif CICCLO était réuni le 4 mai pour avancer sur les chantiers en cours sur l’interopérabilité des plateformes logicielles (indicateurs communs, clausier technique, métadonnées de cartes) et l’actualité TechSprint. La communauté PRODIGE par la voix d’Alkante a restitué les résultats d’une étude pour tendre vers les Espaces communs de données. Après un riche tour de l’actualité de l’Afigéo, les ressources utiles et les communautés logicielles (voir ci-dessous), […]
...Strasbourg: 1er apéro-rencontre du groupe local OpenStreetMap de Strasbourg, Le mardi 16 juin 2026 de 20h00 à 22h00.
Rencontrons-nous autour d'un verre pour faire connaissance, partager nos envies et nos expériences autour d'OSM et lancer le tout nouveau groupe local de Strasbourg.
Attention, le bar n'est pas accessible en fauteuil à cause des marches (nous tentons de trouver un lieu accessible pour la prochaine rencontre)
Beyond the Data Dump: The AI-Curated Wiki Map
At least once a week, I discover a new 'vibe-coded' interactive map that features geo-located Wikipedia articles. Most never get a mention on Maps Mania because they offer nothing different than what can already be seen on GeoCards, WhereWiki, Wiki Explore, Nearby Wiki, Wikimap, or the hundreds of other interactive maps listed under the Maps Mania Wiki label.LocalLore does have a USP which
Lire l'article complet ↗
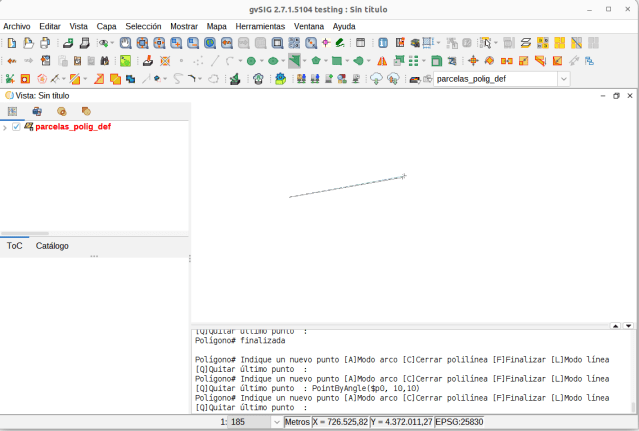
gvSIG Team: Novedades gvSIG Desktop 2.7: Edición vectorial a partir de rumbo y distancia
En la nueva versión de gvSIG Desktop, la 2.7, se han incluido tres herramientas que permiten crear geometrías de líneas y polígonos mediante rumbo y distancia. Para ello se han incluido tres funciones nuevas en el gestor de expresiones:
- PointByAngle(): Permite insertar nuevos puntos de la geometría mediante un ángulo y una distancia. El ángulo sería antihorario, siendo el origen 0º en dirección este. La fórmula sería:
PointByAngle(geometría, distancia, ángulo)
donde “geometría” sería el punto desde el cual se insertaría la nueva línea (siendo “$p0” el último punto insertado, “$p1” el penúltimo…), “distancia” sería la longitud del segmento en las unidades de la vista, y “ángulo” sería el ángulo en grados sexagesimales. Por ejemplo PointByAngle($p0,10, 10) sería como se muestra a continuación, 10 metros con un ángulo de 10º sobre la horizontal.
...The Sunny Coffee Map
There are lots of maps that can help you find a good cafe in Paris. But Sunny Coffee answers a much more important question: which café terraces are actually in the sun right now? Created by developer Paul Baron, Sunny Coffee is an interactive map that shows which Paris café terraces are currently sunny - and which are sitting in the shade. The map combines Paris open data, 3D
Lire l'article complet ↗
GRASS GIS: GRASS on conda-forge for every major platform
Full conda support for GRASS is finally here! You can now install GRASS 8.5.0 on conda on Windows, Linux, macOS on Intel, and macOS on Apple Silicon, simply by running:
conda install -c conda-forge grass From soft launch to full rollout GRASS was soft-launched on conda with the 8.4.2 release, with packages for Linux (linux-64) and macOS on Intel (osx-64). Now Windows (win-64) and macOS on Apple Silicon (osx-arm64) are both fully supported, providing full coverage of every major platform starting with GRASS 8.
Lire l'article complet ↗
Sean Gillies: Run Rabbit Run training week one, and cramps
Welcome to week one of my year's second eighteen week training program. I'm gearing up for a race that I've never run before, a long-standing one that is close to home: Steamboat Springs' Run Rabbit Run. The 50 mile course goes from the base of Steamboat Mountain, up Right-o-way, then up next to the Thunderhead Express lift, and then (as far as I can tell) up around Tornado and Buddy's Run to one of the chutes and onto the ridge just below Mt. Werner. 3,500 feet D+ (dénivelé, in French, or cumulative elevation gain) in the first 6.5 miles. From there it rolls through the high country to Rabbit Ears Peak and then returns along the same route. The total elevation gain is almost 9,000 feet. It doesn't climb quite as much as the 50 mile Quad Rock course, which I've finished three times, but is at higher altitude. I'm looking forward to it!
...
Just van den Broecke: Adiós 2022-2025
Filling a 4-year gap here! Did not find time to post itemized yearly overviews, plus other updates. And that while even more has been happening compared to the past "COVID-years". Will stick to highlights with a promise to add regular updates.
Below a brief overview of my professional life during 2022-2025.
Highlights of living and working in the Open Source Geospatial and OSGeo(.nl
|.org
)-world,
organized by "Theme".
TL;DR Main 2022-2025 highlights:
...Validation
Présentation #
Lire la suite →
Le service de validation de la Géoplateforme est disponible au travers d’une API REST.
Il permet à un utilisateur authentifié de la Géoplateforme de réaliser une validation d’une donnée fournie en tant qu’archive selon un standard ou une norme : standard PCRS ou standard PLU par exemple. En sortie de cette API, l’utilisateur récupère :
- Un rapport de validation au format CSV
- À son choix, une donnée dont la structure a été modifiée pour correspondre au standard
Ce système de validation est aussi mobilisable directement en tant que traitement au sein de la Géoplateforme - Entrepôt, afin, par exemple, de constituer une étape de prérequis avant intégration en base.
...Gestion des styles pour la diffusion WMS de données vecteur
Gestion des styles #
Lire la suite →
Pour certains types de diffusion, le serveur de diffusion peut avoir besoin de fichiers de configuration. Dans le cas de la diffusion WMS à partir de données vecteur, assurée par Geoserver, ce sont des styles au format SLD et des FTL qui sont utilisés. Afin de les déposer au sein de l'entrepôt, le concept de fichier statique (static) est exploité.
Génération d'un SLD #Après l'export des styles depuis QGis dans son format, il est nécessaire d'utiliser l'outil geostyler en ligne de commande pour les convertir :
...Autocomplétion
Présentation #
Lire la suite →
L’API d’autocomplétion de la Géoplateforme a pour but de suggérer des localisants probables, au fur et à mesure de la saisie d’adresses ou de noms de lieux.
Son usage est limité à 10 requêtes par seconde depuis une même adresse IP.
Elle s’appuie sur des données BAN, BD TOPO® et Parcellaire Express (PCI).
L’API est interrogeable en méthode GET.
Son swagger est accessible ici : swagger de l’autocomplétion.
...Lutra consulting: M3C2 Point Cloud Comparison in QGIS 4.0
Master M3C2 in QGIS 4.0 for direct point cloud comparison. Learn how to detect erosion and landslides with surface normals and 95% statistical confidence intervals.
Lire l'article complet ↗

Typologie des forêts à l'échelle mondiale à une résolution de 10 mètres
Source : M. Neumann, A. Raichuk et al. « Global forest typology at 10-meter resolution for forest and land-use monitoring » [Typologie forestière mondiale à une résolution de 10 mètres pour la surveillance des forêts et de l'utilisation des terres], EarthArXiv, https://doi.org/10.31223/X58R27
...
QGIS
Utiliser les données libres en flux WMS/WMTS #
Intégration d’un flux WMS #
Lire la suite →
Dans le menu « Couche », allez sur « Ajouter une couche » puis « Ajouter une couche WMS/WMTS ».
Cliquez sur « Nouveau » pour ajouter un nouveau flux WMS.
Dans la boîte de dialogue « Créer une nouvelle connexion WMS », renseignez les champs :
-
« Nom » : nom que vous souhaitez donner à la connexion au serveur
...
API de téléchargement
Présentation #
Lire la suite →
L’API de téléchargement de la Géoplateforme permet de découvrir et télécharger des fichiers.
Elle est conforme au format Atom RFC 4287.
Elle s’appuie sur 3 méthodes :
- GetCapabilites pour lister les ressources disponibles
- GetResource pour lister les fichiers téléchargeables de la ressource interrogée
- Download pour télécharger un fichier
Son usage est limité à 10 requêtes par seconde depuis une même adresse IP.
Attention, les résultats des requêtes sont paginés. Pour parcourir les résultats, les paramètres sont :
...
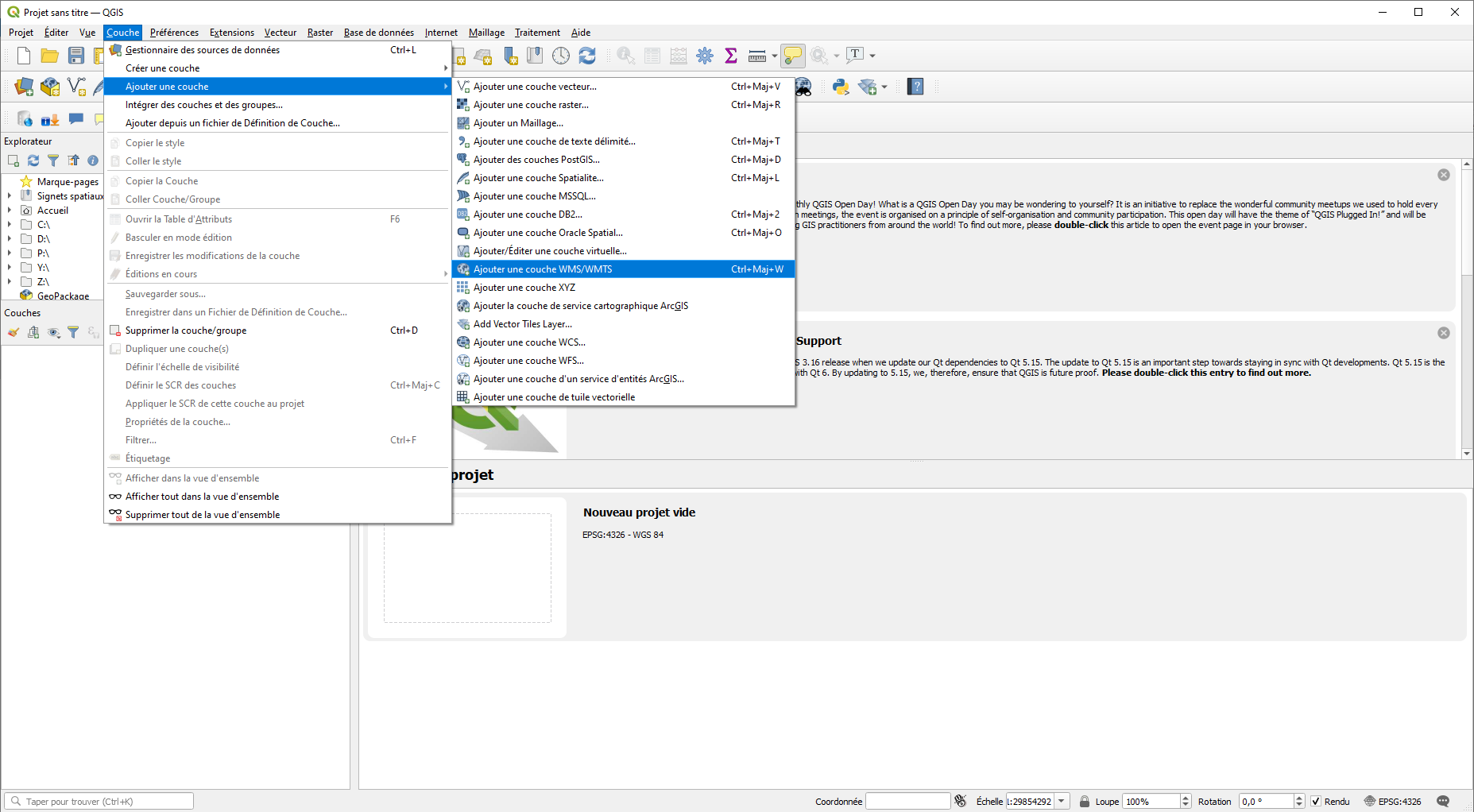
ArcGIS
Utiliser les données libres en flux WMS/WMTS #
Intégration d’un flux WMTS #
Lire la suite →
Dans le menu « Insérer », allez dans « Connexions » puis « Nouveau serveur WMTS ».
Dans la boîte de dialogue « Ajouter une connexion au serveur WMTS », renseignez le champ « URL du serveur » :
https://data.geopf.fr/wmts?SERVICE=WMTS&VERSION=1.0.0&REQUEST=GetCapabilitiesEt cliquez sur « OK ».
...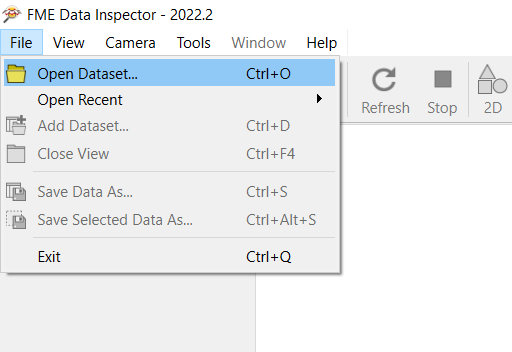
FME
Utiliser les données IGN avec FME (version 2022.2) #
Lire la suite →
Dans le menu « File », cliquez sur « Open Dataset ».
Déroulez la liste de formats pour choisir « More Formats » ou accédez à « OGC WMS (Web Map Service) » ou « OGC WMTS (Web Map Tile Service) » si vous avez déjà utilisé un tel format dans FME récemment.
Sélectionnez « OGC WMS (Web Map Service) » ou « OGC WMTS (Web Map Tile Service) » et cliquez sur « Parameters ».
Dans la partie « URL », utilisez les services libres IGN :
-
WMS-Raster :
...
Global Mapper
Introduction #
Global Mapper est une application logicielle SIG de pointe, disponible en version française et dont Géom@tique est le distributeur exclusif pour la francophonie, qui fournit aux professionnels de la géomatique, novices ou expérimentés, une gamme complète d’outils de visualisation, d’édition et d’analyse de données spatiales. Si Global Mapper prend en charge une liste inégalée de formats de données, il permet également d’utiliser les services web délivrés par la Géoplateforme (WMS, WMTS et WFS) ainsi que, dans sa version « Pro », d’exploiter les données Lire la suite →
Maputnik
Dans cet article nous allons apprendre à :
- Modifier un fichier de styles avec l’éditeur Maputnik
- Afficher un fichier de styles modifié dans la Géoplateforme
La ressource visée dans cet exemple est « Plan IGN ». Maputnik est un éditeur open-source compatible avec la spécification Mapbox GL style. Il nous permet de modifier le style des cartes tuiles vectorielles en temps réel.
...OGR
Étape 1 #
Lire la suite →
Installer OSGeo4W avec les librairies GDAL/OGR, Xerces ou Expat support, curl (les librairies manquantes seront proposées).
Étape 2 #Exécuter cette invite en ligne de commande :
C:\OSGeo4W64\OSGeo4W64.bat Étape 3 #Modifier le proxy de GDAL si vous en avez un, en entrant dans la ligne de commande :
...The Ambient Sound Map
Oto Fūkei - The Interactive Ambient Sound Map Oto fūkei (音風景) is a Japanese term meaning “soundscape” or “sound landscape”. It is the idea that places are not only defined by what they look like, but also by the sounds that shape our emotional perception of them. A narrow Tokyo alley has a very different sonic identity from a riverside park. A dense commercial district feels different from
Lire l'article complet ↗
Du 22 au 24 septembre et du 4 au 5 novembre 2026 à Lille : Formation 5 jours "Savoir utiliser les données foncières"
Publié le 27 mai 2026
Lire l'article complet ↗
Une session de formation "Savoir utiliser les Données Foncières" se tiendra du 22 au 24 septembre et du 4 au 5 novembre 2026 dans les locaux du Cerema Hauts-de-France à Lille.Cette session est à destination des bénéficiaires des fichiers données foncières (Fichiers Fonciers et DV3F) et des bureaux d'études.Vous trouverez le contenu et le coût de la formation dans la rubrique AccompagnementInscription jusqu'au 6 septembre (…)
Geotrek 2025–2026 : nouvelles fonctionnalités et grands chantiers à venir
Les années 2025 et 2026 ont été particulièrement riches en évolutions pour l’écosystème Geotrek.
Lire l'article complet ↗

Data Feminism et visualisation de données

Near real time snow cover maps in the Copernicus Browser!
Copernicus provides near real time snow cover maps at 20 m resolution (fractional snow cover, code name: FSC OG). These products have been recently reprocessed and are now available through the Copernicus Data Space Ecosystem (CDSE) API and visualization tool, the Copernicus Browser! The latter is very useful to explore the data, for example if […]
Lire l'article complet ↗
GeoSolutions: MapStore 2026.01.00 Release
You must be logged into the site to view this content.
The New World Order - Mapped
Atlas Absurdo If there is one thing we've learned in the 21st Century, it is that planet Earth is in need of some major reorganization. The first task in this global reshuffle? Reallocating the land each country owns based strictly on its population size.It is patently unfair that the most populous country - India - should be forced to squeeze into the world's 7th largest landmass. Under the "
Lire l'article complet ↗
[FR]Développer Un Plugin Qgis : Créer Un Plugin Avec Plugin Builder
Créer un plugin QGIS est beaucoup plus simple qu’il n’y paraît, surtout lorsque l’on débute en programmation. Grâce à Plugin Builder, il est possible de générer en quelques minutes la structure complète d’un plugin, sans écrire…
The post [FR]Développer Un Plugin Qgis : Créer Un Plugin Avec Plugin Builder first appeared on Blog SIG & Territoires.
Infoclimat et DataClimat, deux sites utiles pour accéder à des données météorologiques et climatiques
Infoclimat est une association fondée par des passionnés de météorologie. En plus d’accumuler une montagne de données, elle a pour objectif la mise en commun des informations, l’installation de stations météo supplémentaires, la vulgarisation scientifique et les échanges entre les différents acteurs de la météo. En mai 2026, elle a lancé, en partenariat avec Data for good, DataClimat, un portail citoyen destiné à « rendre le changement climatique visible, compréhensible et vérifiable par tous ».
1) Infoclimat.fr : un site très pédagogique
...GeoTools Team: GeoTools 34.4 released
The GeoTools team is pleased to announce the release of the latest stable version of GeoTools 34.4 : geotools-34.4-bin.zip geotools-34.4-doc.zip geotools-34.4-userguide.zip geotools-34.4-project.zip This release is also available from the OSGeo Maven Repository and is made in conjunction with
Lire l'article complet ↗
Metro Melodies
I’ve developed a slight obsession with Tokyo's train station melodies. Known as Hassha Melodies (literally 'departure melodies'), these carefully composed seven-second jingles are designed to guide commuters onto departing trains on the city's vast, sprawling transit network.Before their introduction, Japanese stations used harsh electric buzzers to signal departures. In the late 1980s, new
Lire l'article complet ↗
GeoServer Team: GeoServer 2.28.4 Release
GeoServer 2.28.4 release is now available with downloads (bin, war, windows), along with docs and extensions.
Please note, this is a stable release of GeoServer providing existing installations with minor updates and bug fixes, provided shortly before the GeoServer 3.0 release.
GeoServer 2.28.4 is made in conjunction with GeoTools 34.4, and GeoWebCache 1.28.4.
Propulsé par FreshRSS | 1484 articles au total